面向USB PD3.0协议的新型BMC解码电路设计
2021-01-11方侃飞蔺智挺赵建中毕立强
方侃飞,蔺智挺,赵建中,李 智,毕立强
1.安徽大学 电子信息工程学院,合肥230601
2.中国科学院微电子研究所 智能感知中心,北京100029
随着智能手机的快速发展,目前主流的快速充电协议有华为SCP、Qualcomm QC、Samsung AFC、OPPO VOOC、USB BC1.2[1-2]。为了统一快速充电技术规范,USB-IF 协会定义了USB PD3.0 协议[3-4],此规范不但解决了设备与充电器从一对一变成多对一的问题,而且降低了消费者的消费成本。目前,各大芯片厂商越来越重视USBPD 快速充电芯片的设计,纷纷投入基于USB PD 协议的研究,目的是为了尽快地抢夺快速充电设备市场[5-7]。USB PD协议中的核心技术之一是BMC编解码,其中BMC 编码是将时钟和数据包含在数据流中,在传递数据信息的同时,也将时钟同步信息传给对方,加上每次编码中至少有一次电平翻转,不存在直流分量,因此具有同步性与一定的抗干扰能力。接收方利用BMC 编码的同步性,锁定自己的时钟频率,从而高效精准地通信。编码规则如图1 所示,数据0 电平不翻转,数据1电平翻转,因此四分之三UI(Unit Interval)作为判断接收到数据0 还是数据1 的标准。BMC 解码分为前导码解码和数据解码,前导码数据是64 bit 的0101……,只有当前导码准确无误后才能进行数据解码。若前导码解码性能过差,会造成数据解码出错。因此本文在分析传统解码电路中面积大、功耗高、抗干扰能力弱等缺点,提出高性能的新型解码电路系统。
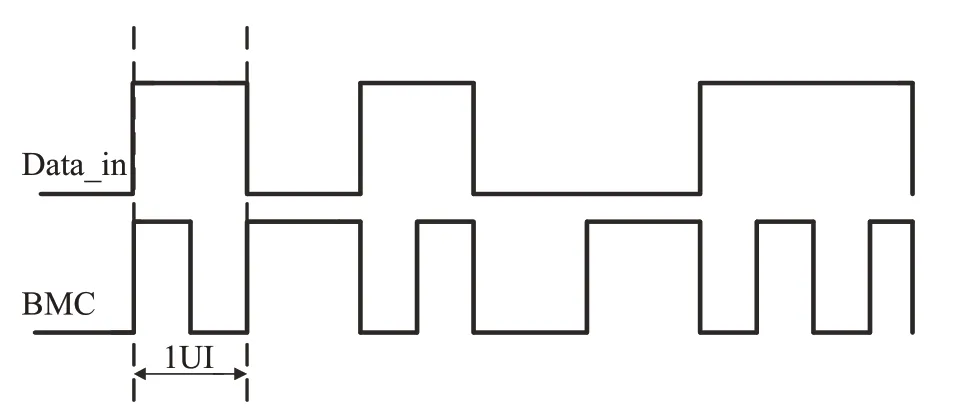
图1 BMC编码规则
1 传统的BMC解码系统
传统的BMC 解码系统的结构框图如图2 所示,由滤波模块、边沿检测模块、解码模块、输出模块组成。

图2 传统的BMC解码结构框图
文献[8]提出了一种传统的BMC 解码电路系统,该电路利用高速时钟对64 bit 的前导码进行过采样,采样的计数值计为Counter_total。通过算数平均算法解出解码阈值Th,如公式(1)所示,如果在Th之内检测到数据边沿(上升沿或下降沿)到来则说明解出的码为1,如果在Th之内没有检测到边沿则说明解出的码是0。若此时的前导码长度低于64 bit,此算法会将有效数据误认为前导码,从而导致电路的鲁棒性不高,抗干扰能力差。另外,对64 bit 进行过采样不仅增加了电路计算负担,而且增加了电路的面积与功耗[9-10]。

传统的BMC 解码设计的流程图如图3 所示,对Type-C接口的CC线上的信号进行滤波,消除信号上的毛刺,接着对64 bit前导码进行过采样并得到计数总数,进而算出解码阈值。一旦64 bit前导码过采样完成后将会对前导码64 bit 后的数据进行过采样,并根据解码阈值解出前导码后的数据。

图3 传统的BMC解码设计的流程图
2 新型BMC解码系统
所提出的新型BMC 解码结构如图4 所示,由滤波模块、BMC解码模块、预期解码模块、校正模块、输出模块组成。其基本原理如下:滤波模块滤除Type-C 接口的CC线上的毛刺,保证输入数据稳定,随后将稳定的数据传递至BMC 解码模块,通过此模块的算法将输入数据解出并传至校正模块,同时判断前导码2 bit属于哪种类型(判断方法如图9 所示)。接着将解出的1 bit 有效数据传至预期的解码模块,预期的解码模块收到有效数据后将会预测下一个数据并存于当前寄存器中,同时将上次预测的数据传至校正模块,此时校正模块判断解出的数据与预测的数据进行比较,若比较结果一致,将解码数据传送至发送模块,若不一致,电路将会发生复位。

图4 新型BMC解码结构框图
新型的BMC解码结构流程图如图5所示,对CC线上的数据信号进行滤波,消除数据信号上的毛刺,通过前导码中2 bit 判断出属于哪种形式,并得出解码阈值(判断方法如图9 电路所示),一旦2 bit 类型判断出来,可以根据前导码中0和1交替变化的规则即可推测出下一bit 的预测值为0 还是为1。前导码中2 bit 类型判断后,将会对2 bit后的每8 bit分为一组,进行解码,过程如下:根据前导码2 bit得出的解码阈值对前导码中2 bit后的第一组8 bit 前导码进行解码,并得出新的解码阈值,同时将第一组解出的前导码与预测值进行比较,如果一致,则说明解码正确,此时组数加1,若组数小于等于4,新的解码阈值对第二组8 bit 前导码进行解码并且过采样,再次更新解码阈值,此时第二组的解码结果与预测值进行比较,如果一致则组数加1,不一致,电路复位并重新检测电路前导码前2 bit属于哪种形式,重新开始上述流程。一旦正确解出4组8 bit前导码,则表示电路已经稳定,可以采用最后的解码阈值对后面前导码或者数据进行解码。在对4组8 bit后的前导码进行解码的过程中,只需要对0.75 UI进行过采样,在过采样过程中,若发现在0.75 UI的范围内检测到边沿变化则表示检测到1,否则检测到0。一旦检测到1 或者0,剩下的0.25 UI 不需要进行过采样,直接解码下一bit 前导码的值。对下一个前导码进行解码,同样也是在0.75 UI 范围内进行过采样,并检测有无边沿变化,从而检测到0 或者1,剩下的0.25 UI 就不需要过采样,直接跳转至下面的前导码进行检测,以此类推。另外新型的BMC 解码比起传统的方法具有自动校正功能,使得电路在解码异常情况下即刻复位,保障了电路的可靠性,在面积和功耗上新型的解码比传统的解码低。现对新型BMC解码结构框图中的各模块介绍如下。

图5 新型的BMC解码结构流程图
滤波模块对Type-C 接口的CC 线上的输入数据进行FIR滤波,FIR滤波器基本结构如图6所示[11-12]。由于Type-C 接口的数据会带有毛刺,因而采用FIR 滤波器方案将毛刺滤除。FIR滤波器的公式如式(2)所示。该滤波器抽头系数为1/8,滤波器阶数为7。每隔7组即可判断出CC 线上是真实数据还是毛刺,从而提高解码的精度。


图6 FIR滤波器的基本结构
BMC 解码模块框图如图7 所示,采用18M 时钟对所述滤波信号中的同步头信号进行过采样,并确定解码阈值,从而解出数据。其中BMC 解码模块细划了3 个模块,分别为前导码的起始检测模块、解码阈值模块、解码模块,现对各模块电路说明如下所示。
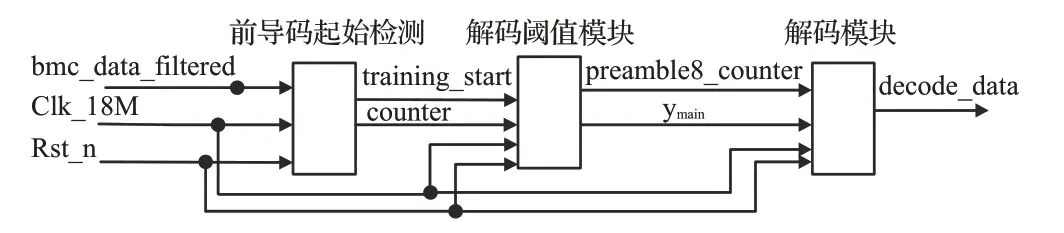
图7 BMC解码模块框图
前导码起始检测电路如图8所示,bmc_data_filtered是滤波模块对CC 线上的毛刺进行滤除后的信号,该电路主要判断前导码中2 bit属于哪种形式,总共有3种形式,如图9所示。由于采用Clk_18M时钟去做边沿检测后的计数值有大有小。如图9(a)计数值a小于c,b小于c表示0、1起始,图9(b)计数值a大于b,a大于c表示1、0 起始,9(c)计数值b大于c,b大于a表示缺失1起始。这种处理方式避免了只在前导码开头处才能进行解码的缺点,大大增加了电路的可靠性和电路的鲁棒性。其中bmc_data_filtered信号打两拍后进行或运算后得到bmc_data_filtered信号的上升沿和下降沿信号,Equal1 是对bmc_data_filtered信号的高低进行判断,如高将触发Add1 加法器,如低则将触发Add0 加法器,并将加法器的值存于寄存器中,Equal2为判断前导码2 bit属于哪种形式,并输出training_start信号,同时将2 bit的计数值除以2的结果输出,此时的counter为1UI的值。

图8 前导码起始检测电路
解码阈值模块电路如图10 所示:ymain信号表示0.75 UI,reamble8_counter信号表示第几组8 bit的数据。前导码中2 bit检测完成后开始解码,此时开始解码的标志信号training_start拉高。通过前导码中的前2 bit 数据可以确定高低电平的长度,算出1UI的counter值并以此为基准来解出第一组8 bit数据。同时用18M时钟对CC线上的第一组8 bit信号进行采样并对数据的高低电平进行计数,对高电平计数的计数值存于h_temp寄存器中,对低电平计数的计数值存于l_temp寄存器中,可以得出Counter_First8。用前导码中的前2 bit数据解出1UI的counter值,将counter乘以3/4的结果供解码模块进行解数。等8 bit数据解出来了后,解码阈值模块要更新UI的计数值,采用的是公式(3)滑动平均滤波算法[13],就是将上一组8 bit 的高低电平计数值加起来然后与前导码中的前2 bit 算的的1UI 值乘以8,最后将结果除以16,算得的结果才是新的UI的计数值,而0.75 UI的值才是解码阈值ymain,ymain的值是解码第二组数据的基础,ymain的算法如公式(4)所示。

接着以ymain值为基准解第二组8 bit 数据,同时将第二组高低电平的计数值存于Counter_Second8寄存器中,接着更新UI的计数值和ymain的值,为解第三组数据做准备,算法如公式(5)所示,以此类推可以确定第三组、第四组的解码阈值。其中Equal2 对bmc_data_filtered信号的边沿进行计数并判断,满12 时表明检测到一组8 bit 数据,此时reamble8_counter计数器加1,Equal3 对reamble8_counter进行判断,如为2 选通乘法器倍数为1/16 的通路,如为3 选通乘法器倍数为2/3 的通路,如为4选通乘法器倍数为1/2的通路,可以发现乘法器倍数为1/16 是一个复用逻辑。这种方法不仅使面积减少了而且可以降低电路功耗,降低制造成本,提高电路性能。

解码模块电路如图11所示,在ymain值之内,如果检测到边沿跳变,则说明解码到1,如果在ymain之内,没有检测到边沿变化,则解码到0。其中Equal3 判断reamble8_counter值是否为4,如为4停止更新解码阈值,并以此阈值为最终的解码阈值进行解码。其中Equal2为ymain之内,有无检测到边沿变化。
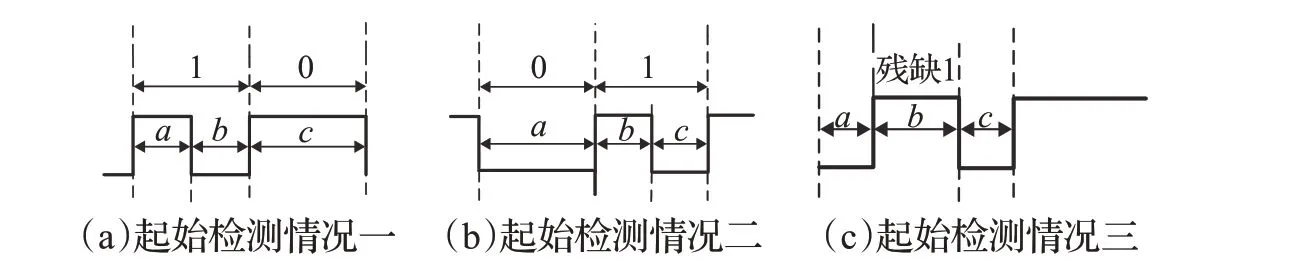
图9 前导码起始检测

图10 解码阈值模块电路

图11 解码模块电路
预期解码模块根据前导码数据64 bit 的0101……的规律性,即可由当前数据得出下一个前导码数据值。因而检测到0或者为1就可确定下一个解码数据是1或者0,从而预测下一个前导码解码数据。校正模块即将解出的前导码数据与预期的前导码数据进行比较。比如,当前正确的数据是0,根据协议规范下一个解码数据应为1,若此时解码解出的数据是0,电路内部会产生一个复位信号让电路复位并且重新进行解码。只有电路准确地把前导码中的前32 bit 数据解出来,才能确定电路在解码的过程中发生故障的可能性非常非常低,从而能提高解码数据的精确度。输出模块即是将解出来的数据进行寄存器输出,由于寄存器输出是时序电路,可以大大降低毛刺输出的概率,避免亚稳态的产生,从而避免了电路的瘫痪[14-15]。该算法增加了校正模块,在该模块中对BMC解码模块与预期解码模块输出数值进行相应的比较,从而提高解码精度。
3 BMC解码的仿真与验证
3.1 传统的BMC解码的仿真与验证
传统的算法只有在前导码为64 bit时才能正确地解码,如图12(a),但是若出现前导码小于64 bit时,传统的设计方案将会出现解码问题,如图12(b),前导码为50 bit情况下。其中Clk_50M信号为50M时钟,decode_data信号表示异常的解码信号,bmc_data_filtered信号表示待解码的数据信号,由图12(b)可知,bmc_data_filtered信号为0时,解出的decode_data信号为1。
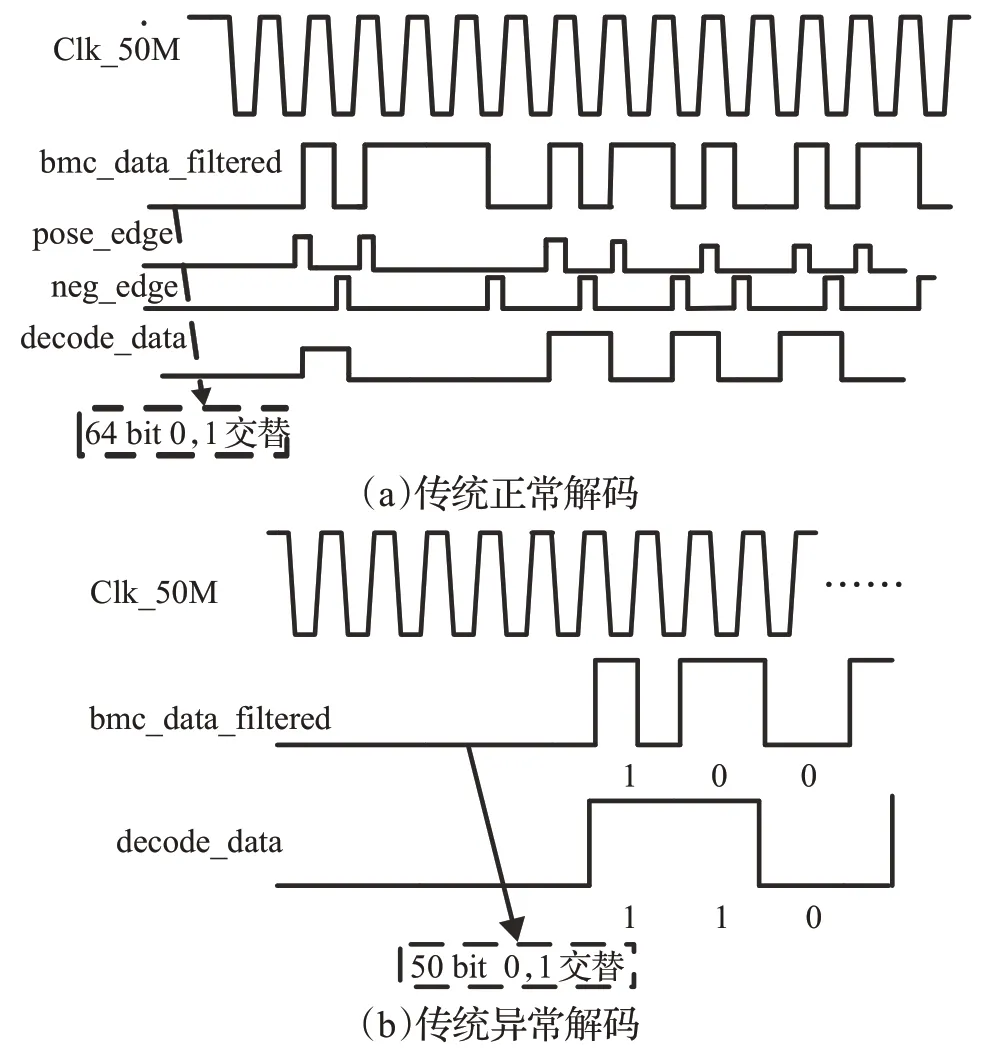
图12 传统解码
3.2 新型BMC解码的仿真与验证
计算0.75 UI 值如图13 所示,现对部分信号说明如下,bmc_data_filtered表示对CC线上的data进行滤波后的信号,training_start拉高之前的bmc_data_filtered信号就是前导码中2 bit 检测,stop_count_12edges表示检测到12 个边沿后这个信号就会产生一个脉冲,表示已经检测到了8 bit的数据,h_temp表示CC线上高电平需要多少个18M 的时钟周期,l_temp表示CC 线上低电平需要多少个18M 的时钟周期。xvalue信号表示CC 线上高低电平的计数值的叠加。xmain信号表示将上一组的高低电平计数值与本组CC 线上的高低电平计数值之和,both_edge信号表示检测到CC线上数据的上升沿和下降沿。前导码的前2 bit计数值23+25+51=99,也就是说一个UI 的计数值为99/2=49,0.75 UI=36,所以ymain的值为36。第一组8 bit高低电平计数值和为396,因为解第一组8 bit数据要将前导码的前2 bit算上,也就是以前导码中前2 bit 算的UI 为基准,解出第一组8 bit 的数据。第二组8 bit 数据的UI 的值是将第一组8 bitxmain的396 与前导码的49×8,相加,将结果除以2 得到第二组8 bit 的总计数值,并且得出一个UI 的值与0.75 UI 的值,从而解出第二组8 bit 的数据,依此类推,解出第三组、第四组等等。

图13 计算0.75 UI值的波形
前导码中2 bit判断出来过后,接着就可以预测下面的数据,是因为USB PD3.0 协议规定数据头的形式是交替的64 bit的0和1,因而只要确定了前导码就可以预测下面的码。预测码的波形如图14所示。

图14 预测码的波形
现在对图14 部分信号进行说明,predicted_data信号是预测的信号,比如刚开始解出的数据是1,就可以预测下一个数据就是0,如果预测的数据与解出的数据一致的话,可以确定数据解码是正确的,如果解出的数据与预测的数据不一致就会发生复位,重新开始解码。依此类推,直到把32 bit 的数据完全解出来为止。如果这32 bit 数据解码都没问题就可以确定电路确实已经稳定了,后面的预测电路将不会工作,从而降低了功耗[16]。
解出的码与预测码进行比较,若两者不一致则会产生复位信号使电路复位,若两者一致则说明解出的码是正确的。复位信号波形如图15所示。
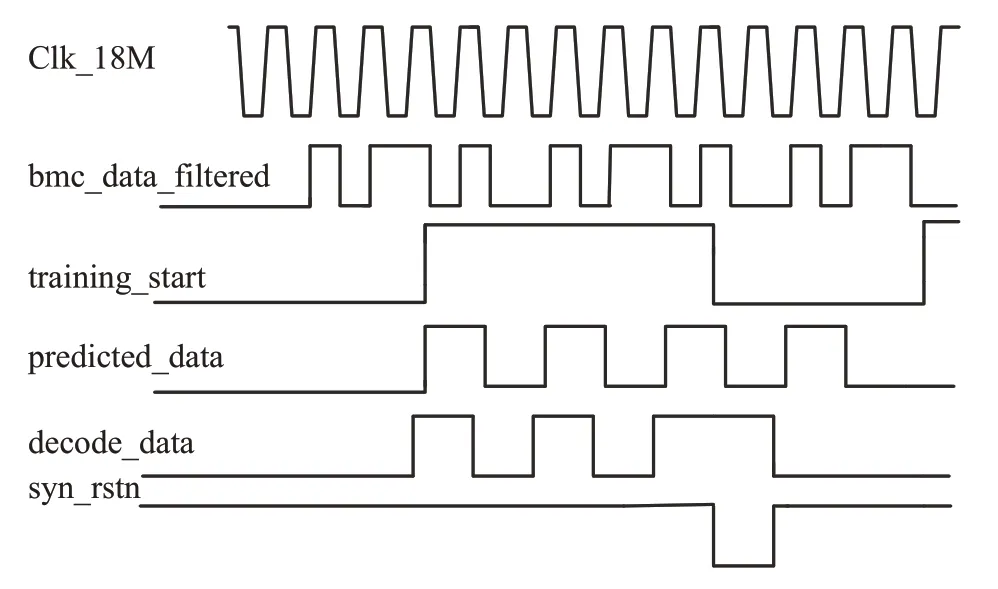
图15 复位信号波形
现对图15 信号说明如下:Clk_18M 信号即解码的主时钟,频率肯定比CC 线上的数据高60 倍,根据过采样定理,在进行模拟或数字信号的转换过程中,当采样频率fs.max大于信号中的最高频率fmax时,采样之后的数字信号完整的保留了原始信号中的信息。syn_rstn信号是预测的数据与解出的数据不一致,此信号拉低进行复位,否则一直为高电平。bmc_data_filered信号是CC线上滤波后的数据,decode_data信号是解码出的数据,predicted_data信号是预测的数据。
3.3 两种方法进行对比
在设计的过程中,要考虑到芯片的面积和功耗。在不影响性能的前提下降低芯片的面积和功耗,不仅降低芯片的制造成本,而且提高芯片的性能指标。采用DC工具分析[17],新型的BMC 解码比传统的方法面积要低2.19%,功耗上要低2.06%。两种方法比对结果如表1所示。其中DC评估的是电路实现逻辑本身的功耗(与触发器数量、时钟频率相关),与实际运行功耗有一定的差异。实际上,本设计降低的功耗比表1 中的2.06%多。上述原因分析如下,传统方法采用的是高速50M时钟对BMC信号进行解码,新型方法采用低频时钟18M;传统方法是计前导码64 bit 的高低电平,将计数值除以64,得到1UI 的值,而新型方法只需要计8 bit 的高低电平,就可以获得1UI,而这些计数值的寄存器的个数比起传统方法要小;传统方法将计数结果除以64,这会耗费大量的资源,而新型方法采用了电路复用逻辑,这大大降低面积资源,新型方法增加了校正模块与预期的解码模块,校正模块基本上是采用组合逻辑比较器,预期的解码模块采用了时序逻辑,尽管采用时序逻辑,但都是单bit 信号的时序操作,因此占用面积比较少。其中校正模块和预期的解码模块在4组前导码检测电路完成后,这部分电路将不会在继续工作,从而降低电路运行中的功耗。新型方法在4组前导码检测电路完成后,通过最终的解码阈值对后面的前导码进行过采样从而解码,在过采样中只需对0.75 UI进行过采样就可以判断出前导码是0 还是1,即新型的方法对64 bit 前导码中剩下的30 bit乘以0.25部分不需要过采样逻辑,而传统对64 bit全部需要过采样逻辑。综上所述,新型的BMC 解码比传统的方法面积小,功耗低。

表1 两种方法比对结果
新型BMC解码具有自动校正功能如图16所示,如果解码与预期的值不一致进行电路复位,重新开始解码,传统的BMC解码不具自动校正功能如图17所示。

图16 自动校正功能

图17 无自动校正功能

图18 两种方法解码对比
新型的BMC 解码在解码抗干扰性要优于传统的BMC 解码,抗干扰性对比如图18 所示。由于传统的设计方案是根据64 bit 前导码得出解码阈值,若出现前导码只有50 bit 时,传统的设计方案将会出现解码问题。图18 所示,传统算法中将数据100 误解出了110 了,如信号decode_data_old所示,而新型的算法却能将数据信号100 准确无误的恢复出来,如decode_data_new信号所示。传统方法中前导码小于64 bit会出现解码错误的原因分析如下,传统方法首先统计高低电平计数值,一旦检测到96个输入信号的边沿,表明前导码64 bit已经统计结束,因此将统计值除以64得到1UI值,而这64 bit是0与1相互交替,若前导码丢失,假设只有50 bit,传统方法将会将部分数据当成前导码,等边沿计数器计满96,此时的统计值比64 bit 前导码的统计值偏大或者偏小,因此将造成1UI 值以及解码阈值不准确,从而造成解码数据不正确。
4 结束语
本文针对传统解码电路具有功耗高、面积大、无校正功能、抗干扰性差等缺点,提出了一种鲁棒性强、低功耗、面积小,且具有自动校正功能的新型BMC 解码设计。该电路采用了滤波算法和滑动平均算法等策略,并增加了校正模块来提高电路的鲁棒性。研究表明该电路在功能上比传统的设计要完备以外,还降低了芯片面积与功耗,使得制造成本大幅度下降。该设计电路从BMC 编解码原理来说解码并不复杂,但是设计出可靠的硬件电路不是一件易事,毕竟在设计电路时不仅要考虑到安全可靠性,而且还要考虑到电路的功耗和面积。为了进一步研究,今后的工作是将此电路如何运用到USB PD芯片中。
