基于数据驱动的风电功率预测误差解耦评价方法
2021-01-09江长明
江长明,杨 健,柳 玉,,崔 阳
(1. 国家电网华北电力调控分中心,北京市100053;2. 华北电力科学研究院有限责任公司,北京市100045)
0 引言
风电装机容量持续多年的快速增长、风电出力的高占比和随机波动特性[1]等因素,使风电预测准确性在电网运行中的影响日益明显[2]:一方面,电力系统调度中的备用容量留取和发电计划安排等环节需要考虑风电功率预测的不确定性[3-4];另一方面,现有电网多以火电等常规电源为主,高比例风电接入后,现有电网的灵活调整电源不足[5],风电预测出力偏差会严重影响出力平衡和机炉启停安排[6]。因此,电网生产运行越来越倚重风电等新能源预测的准确程度[7]。
风电功率预测作为高比例新能源电力系统关键调控技术的重要组成[8],其中,0~168 h 中短期功率预测是日前电力平衡安排的重要参考,数值天气预报(numerical weather prediction,NWP)作为定量化描述未来大气各气象要素变化的预报结果,是预测模型中必要且最重要的输入;0~4 h 超短期功率预测本质上是基于风能利用的持续特性,利用统计学方法进行时序外推[9],分为风速外推与功率外推2 类,也有学者引入NWP 对超短期预测模型进行优化[10-11]。
现有研究多针对功率预测中的某类场景或某个环节进行优化,但受限于NWP 对大气运动过程的不完美描述和统计学模型对物理随机过程匹配的局限性,预测误差难以完全避免[12]。因此,如何有效开展误差多维评价与深入分析,是指导功率预测精度进一步提升的关键问题,具有重要的实际应用价值。文献[13]分析了风电功率预测误差的表现形式和产生原因,总结了典型的误差评价指标和考核评价指标。文献[14]从误差分析入手,分析了风速和风电功率特性、预测模型算法及输入变量对预测误差的影响,并根据误差评价结果给出模型修正方法。文献[15]从机理上分析风速与功率预测误差概率分布的时变特性规律,并引入高阶Volterra 级数预测模型,辨识了预测误差关于预测时长的函数关系。文献[16]通过数据统计方法评价影响预测误差的主要因素为:功率幅值、波动性、预测方法和周期。文献[17]分析了功率预测误差的存在形式,提出了包含纵向误差、横向误差、相关因子与极端误差在内的综合评价方法。文献[18]将评价指标进一步扩展至包含重点时段误差和长期统计误差等的多维评价指标,并给出一种基于离差最大化和灰色关联分析的综合评价指标,解决了多评价指标的权重分配问题。
上述研究多聚焦于功率预测最终误差结果的评价,尚未实现对功率预测的全过程时序评价,缺少从业务链条角度对风电功率预测的实现过程进行解构。特别是功率预测各环节的误差占比始终无法定量化评价,原因包括:①功率预测过程尚未根据业务流程实现解构,且各环节导致的误差成因缺乏解耦评价方法,误差评价不精细;②各环节分析对象不同,量纲也不同,误差分析不直观。为解决上述问题,本文提出了基于数据驱动的风电功率预测误差解耦评价方法,定量分析预测各关键环节的误差成因,高效、精准定位问题场站及预测薄弱环节,实例表明该方法可实现功率预测短板高效查找与精准提升,具有较强的工程应用价值。
1 风电功率预测关键环节解析
经过多年研究与实践,风电功率预测的技术路线已明确固化。按业务流程依次为NWP 环节、Model 环节(风资源-电力转换模型)、校正环节(预测结果校正)。
全网功率预测结果可通过场站预测[19]加和、调度直接预测2 种方式获取。场站加和方式是电网调度机构对场站端中短期预测功率进行加和后,按照断面约束等边界条件进行修正,得到全网预测功率结果,具体流程如图1 所示。
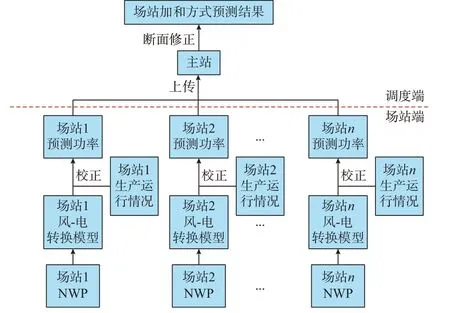
图1 基于场站预测加和方式的全网风电功率预测流程Fig.1 Flow chart of wind power prediction for whole grid based on method of wind farm prediction addition
1.1 NWP 环节
风电场采用的NWP[20]属于站点精细化预报。首先,从权威气象机构下载全球气象预报场。然后,将全球大气预报场数据进行格式标准化处理,使其具备驱动中尺度NWP 模式软件运行的条件,完成模式运行前的所有准备工作。最后,功率预测服务商根据其详细地理坐标的预测需求,运行中尺度数值天气模式软件,完成局部目标区域的降尺度计算,最终获得风电场所处地理区域在未来不同时刻的大气状态。
1.2 Model 环节
Model 环节中的风-电转换模型是描述风资源气象要素与风电有功功率之间关系的数学模型[12]。在实际生产中,由于受到天气条件、机组发电性能等因素的影响,风速与电力往往呈现复杂的映射关系,为了保证功率预测准确性,通常需要考虑复杂多变的机组运行工况开展精细化建模,从而获得较强适用性的风-电转换模型。统计模型是目前工程应用领域中普遍使用的建模方法。其本质是利用统计学方法匹配系统的输入(包括NWP、历史数据等)和预测功率之间的物理因果关系。
1.3 校正环节
校正环节中的预测结果校正是指风电场根据计划开机容量,对风-电转换模型计算出的预测功率进行修正,得到最终预测结果[21]。预测结果校正是与人工经验密切相关的管理环节,主要由风电场运行工程师完成:①将风电功率预测与计划检修工作联动,根据拟开工检修工作涉及的机组数量,在功率预测系统中通过人工录入方式合理订正开机容量、开机时间以及预测出力;②考虑冻雨、覆冰、大风等极端气候可能引起风电机组的停运容量,通过人工输入的方式,对预测结果进行经验校正。
2 风电场功率预测误差解耦评价
风电场功率预测运行主要由上述3 个时序环节组成,解耦评价各环节对误差结果影响的基本思路为:将NWP 环节的预测风资源和实测风资源分别输入风-电转换模型,将输出的功率结果分别与实际功率进行比对;再考虑实际开机容量与计划开机容量的偏差,最终将各环节对误差结果的影响归一化到功率单位上进行评价。
2.1 数据准备
在预测误差解耦评价建模过程中,除传统功率预测评价外,还需引入与功率预测运行中间过程相关的多源信息,以区分评价功率预测运行各环节对最终预测结果的影响。所需的数据包括风电场运行信息、场站功率预测信息、机组运行信息、NWP 信息和运行日志信息等,见附录A 表A1。
数据驱动方式的实际应用效果与数据质量关系密切,上述相关信息的数据质量统计指标主要包括正确率A、缺数率F1、死数率F2和错数率F3,4 个指标之和为100%,即
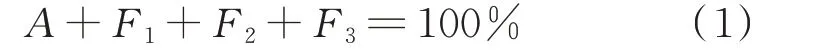
1)缺数率
定义缺数率F1为每个风电场数据缺失点数Nlost占所有数据点数Ntotal的比例,即

2)死数率
定义死数率F2为数据不刷新的数据点数Nsame占所有数据点数的比例,即

其中,不刷新的数据的判断规则为:①风速数据不刷新,风速连续0.5 h 不刷新,则除第1 个点以外标记为不刷新;②功率数据不刷新,在自校验阶段,有功功率连续0.5 h 不变,则除第1 个点以外标记为不刷新。
在状态有功功率互校验时,对于计划停运、非计划停运、调度停运(含调度限电)、通信中断、场内受累停运、场外受累停运6 种状态相应有功数据被标记为不刷新的情况,需取消其不刷新标记;对于待风状态相应有功数据被标记为不刷新的情况,需判断死数是否为0,如果是0,则取消其不刷新标记,进行修正;如果不是0,则不需要任何处理。
3)错数率
定义错数率F3为错误的数据点数Nfalse占所有数据点数的比例,即

以风速和有功功率为例,错数的判断规则为:风速越限范围为风速大于50 m/s 或小于0 m/s;数据跃变为1 h 平均风速超过6 m/s,1 h 平均气温变化超过5 ℃,3 h 平均气压变化超过1 kPa;有功越限为单机或场站有功功率大于1.1 倍装机容量或者小于-10%的装机容量。
2.2 预测误差解耦评价模型
首先,在功率预测中定义评价3 个主要环节对预测结果误差影响程度的指标。具体地,定义变量En表征由NWP 环节导致的预测功率误差,定义变量Em表征由Model 环节导致的预测功率误差,定义变量Er表征由校正环节导致的预测功率误差。三者共同组成整体预测功率误差Et,i,即风电场预测功率与实际功率的差值,如式(5)所示。
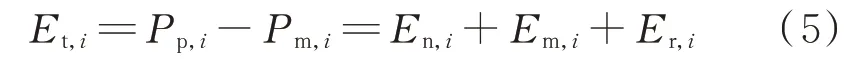
式中:Pp,i为风电场在i 时刻的预测功率;Pm,i为风电场在i 时刻的实际功率;En,i,Em,i,Er,i分别为i 时刻由NWP 环节、Model 环节、校正环节导致的预测功率误差。
其次,引入发电开机方式和气象预测/观测信息,求解等效预测功率值。通过获取风电场计划开机容量和实际开机容量,计算在准确开机容量条件下的等效功率预测值,即
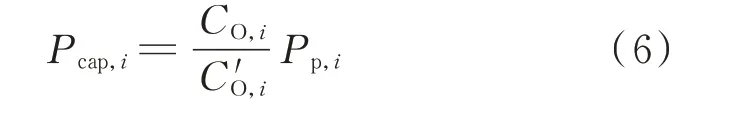
式中:Pcap,i为i 时刻准确开机容量条件下的等效功率预测值;CO,i和C′O,i分别为i 时刻风电场实际开机容量和计划开机容量。
通过获取风电场气象预测/观测信息,计算在准确风资源条件下的等效功率预测值为:
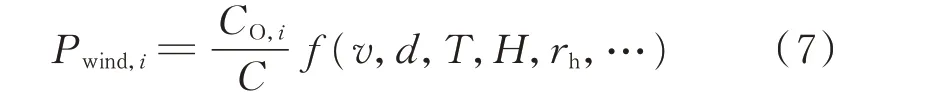
式中:Pwind,i为i 时刻准确风资源条件下的等效功率预测值;f (⋅)为风电场功率预测中应用的风-电转换模型;v,d,T,H,rh分别为观测的风速、风向、气温、气压、相对湿度;C 为风电场装机容量。
预测功率Pp,i与实际功率Pm,i之差为En,i,Em,i,Er,i这3 个环节误差之和;预测功率Pp,i与等效预测功率Pwind,i之差为NWP 环节误差En,i;预测功率Pp,i与等效预测功率Pcap,i之差为校正环节误差Er,i;建立联立方程组(式(8)),求解可得i 时刻En,i,Em,i和Er,i的值,方法示意图如图2 所示。


图2 预测误差解耦评价方法示意图(场站侧)Fig.2 Schematic diagram of decoupling evaluation method for prediction error (wind farm side)
将3 个主要环节误差进行归一化处理,得到每个环节的误差贡献率,分别为Rn,i,Rm,i,Rr,i,计算公式如式(9)—式(11)所示。

3 调度侧功率预测误差解耦评价模型
第2 章已经给出风电场侧功率预测误差的解耦评价模型,理论上,该评价模型亦可部署于电网调度侧,但在实际应用中,受限于模型多样性、部署难度、维护效率等限制,调度侧功率预测误差的解耦评价模型需要重新设计通用的风-电转换简化模型,以满足自动、高效的批量评估需求。
3.1 风-电转换简化模型
基于风电机组的能量转换原理,风电场从风资源中获取的机械功率Pm[22-23]为:

式中:ρ 为空气密度;S 为风轮扫掠面积;Cp为功率利用 系 数;v0为 偏 航 风 速;θ 为 偏 航 偏 差;d0为 偏 航 风向;e 为轮毂高度处的水汽压。
由式(12)—式(14)可知,风电有功功率与风速的立方呈正比例关系,与空气密度呈正比例关系,空气密度由气温、气压和相对湿度共同决定。
综上,风-电转换简化模型的输入变量为轮毂高度的风速、风向、气温、气压、相对湿度,输出变量为风电场在正常工况下的有功功率。建模主要分为建模数据筛选和统计模型训练2 个部分。
1)建模数据筛选
功率预测中的风-电转换模型只用于表征风电场在正常运行工况下的风资源与发电功率的映射关系,无法覆盖电网限电降额/停运、机组故障停运和检修停运等其他特殊工况,因此,用于统计建模的历史运行数据应先进行工况筛选。
概率密度估计是通过样本估计总体的概率密度函数,通常分为参数和非参数形式的概率密度估计。核密度估计[24-25]是常用且有效的非参数概率密度估计方法,其表达式如下。

式中:n 为样本数;h 为带宽;xm为变量x 的第m 个样本;K(⋅)为核函数。
本文采用高斯核函数,其表达式如下。

核密度估计带宽的选取影响估计精度。带宽较小时,概率密度曲线偏尖锐,结果波动较大;带宽较大时,概率密度曲线过于平滑,数据的真实性可能被掩盖,本文选用最优带宽求取方法。
基于核密度估计的风电场运行异常工况数据识别过程如附录A 图A1 所示,具体步骤如下。
步骤1:工况筛选。对于原始数据包含对应的运行工况,剔除开机容量小于95%的额定装机容量、电网调峰/网架原因限电、机组主动限功率等特殊工况样本。
步骤2:将功率数据从0 至额定功率等间隔划分为多个区间,并将机组实际功率及风速数据对应至各功率区间。
步骤3:通过核密度估计确定各区间内风速数据的概率密度估计结果。以功率区间[ P1,P2]为例,假设该区间内风速数据的核密度估计结果:风速序列为{v1,v2,…,vn}(v1<v2<…<vn),对应概率密度为{ p1,p2,…,pn}。
步骤4:异常数据筛选。以功率区间[P1,P2]为例,确定风速数据核密度估计概率密度的最大值pk及其对应风速vk。从风速vk开始,沿核密度估计风速序列增大的方向,即vk→vn方向,判断t=k 时式(17)是否成立,若成立,继续判断t=k+1 时式(17)是否成立,以此类推,直到不满足判断条件为止,设此时的风速为vmax。从风速vk开始,沿核密度估计风速序列减小的方向,即vk→v1方向,判断t=k时式(17)是否成立,若成立,继续判断t=k-1 时式(17)是否成立,以此类推,直到不满足判断条件为止,设此时的风速为vmin。该功率区间内,介于vmin至vmax间的风速及对应功率数据为正常数据,其余数据为需要剔除的异常数据。
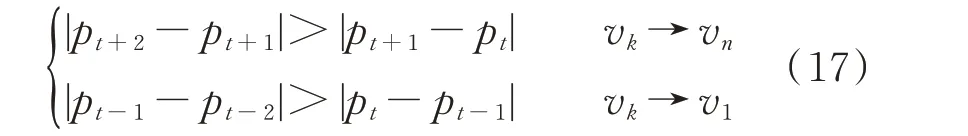
步骤5:对于步骤2 所划分的全部功率区间,通过步骤4 筛选并剔除异常数据,即可得到全功率段的正常数据。
以某风电场风速-功率的运行数据为例,图3 为原始的全部运行数据散点采用本文所提方法进行工况数据筛选后的结果。本文所提核密度估计法能够有效地批量提取正常工况的风-电建模数据,相对于传统四分位法,对异常数据的筛选剔除结果更优,避免出现筛除过多有用数据的问题。
2)统计模型训练
风-电转换模型的输入和输出具有非线性关系,应用在调度侧的风电场预测误差解耦评价模型中,风-电转换简化模型采用反向传播(BP)神经网络结构[26]。BP 神经网络是一种非线性优化,它按照误差BP 来调整神经网络的参数,以实现非线性系统映射关系的最优表达。模型采用3 层BP 神经网络结构,如附录A 图A2 所示,输入节点数为4,分别为风速、风向、气温、气压;单节点输出为风电场有功功率,隐含层节点数为7。模型训练样本为经数据筛选后的风电场正常运行工况数据。

图3 功率运行数据散点筛选图Fig.3 Diagram of operation power data filtering
3.2 误差解耦模型
基于2.2 节功率预测误差解耦评价的思想,在调度侧的误差评价应用中引入风-电转换简化模型,如图4 所示。
引入调度侧的风-电转换简化模型,求解等效预测功率值。通过获取风电场气象观测信息和预测信息,计算等效功率预测值,即

式中:Pwind,sm,j为第j 个风电场在准确风资源和简化模型条件下的等效功率预测值;Pp,sm,j为第j 个风电场在采用风-电转换简化模型条件下的等效功率预测值;gj(⋅)为调度侧用于预测误差评价第j 个风电场的风-电转换简化模型;v′,d′,T′,H′分别为风速、风向、气温、气压的NWP 预测值;CO,j为第j 个风电场的实际开机容量;Cj为第j 个风电场的装机容量。

图4 预测误差解耦评价方法示意图(调度侧)Fig.4 Schematic diagram of decoupling evaluation method for prediction error (dispatch side)
第j 个风电场的预测功率Pp,j与实际功率Pm,j之差为En,j,Em,j,Er,j这3 个环节误差之和;第j 个风电场的预测功率Pp,j与等效预测功率Pcap,j之差为校正环节误差Er,j;第j 个风电场的等效预测功率Pwind,sm,j与等效预测功率Pp,sm,j之差约为NWP 环节误差,建立联立方程组(式(20)),求解可得第j 个风电场各环节的预测误差值。
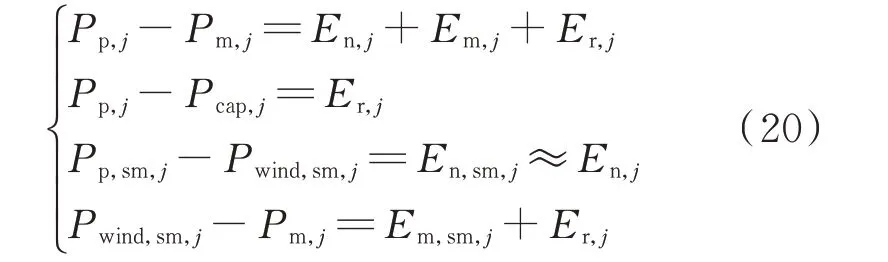
式中:En,j,Em,j,Er,j分别为第j 个风电场由NWP 环节、Model 环节、校正环节导致的预测功率误差;Pp,sm,j为第j 个风电场在风-电转换简化模型下的等效预测功率;Pwind,sm,j为第j 个风电场在准确风资源输入和风-电转换简化模型条件下的等效预测功率;En,sm,j为风-电转换简化模型条件下的NWP 环节等效误差;Em,sm,j为风-电转换简化模型条件下的Model 环节等效误差。
3.3 调度侧评价模型准确性分析
在调度侧引入风-电转换简化模型后,由于误差测算过程中存在近似化,各环节等效误差的估算可能产生偏差。对3 座典型风电场的误差解耦评价指标进行测算,分析调度侧对风电场预测误差评价的准确性。表1 为调度侧与场站侧的预测误差评价对比,场站侧和调度侧校正环节评价误差结果相同,场站侧NWP 环节的误差占比比调度侧的高1.1%,场站侧Model 环节的误差占比比调度侧的低1.1%,调度侧评价的最大误差为风电场C,与场站侧NWP环节和Model 环节评价误差为1.4%。结果表明,调度侧模型可以较准确地评价风电场功率预测各环节的误差贡献占比。

表1 功率预测误差解耦评价对比Table 1 Comparision of decoupling evaluation on power prediction error
4 算例分析
4.1 长周期统计算例
选取中国华北区域9 座风电场,地形涵盖了坝上高原、坝上丘陵、复杂山地及沿海平地等,利用调度侧评价模型进行测算,风-电转换简化模型采用BP 神经网络,数据质量如附录A 图A3 所示。以风电场A 的2019 年1 月数据为例,其预测误差解耦评价时序曲线结果如图5 所示。
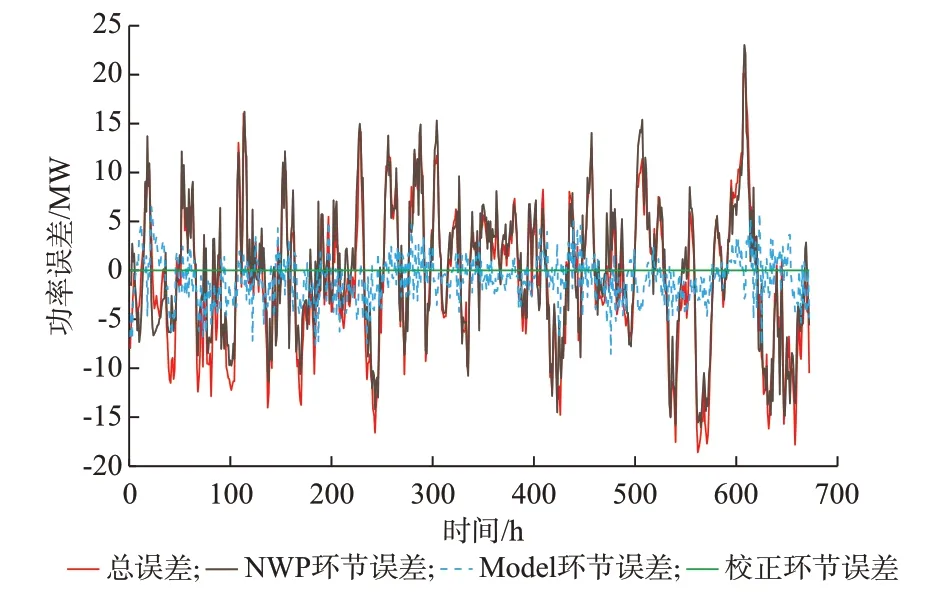
图5 风电场A 误差解耦评价曲线Fig.5 Curves of decoupling evaluation on error in wind farm A
9 座风电场2019 年1 至7 月功率预测各环节误差解耦测算结果如表2 所示,3 个预测环节误差的平均占比分别为58.8%,40.5%和0.7%,NWP 环节误差平均占比最高,为58.8%。Model 环节的误差贡献平均占比为40.5%。从长期测算结果看,NWP 环节是预测误差的主要来源,Model 环节是造成预测误差的重要来源,NWP 环节和Model 环节的误差共同构成了总误差的基本面。

表2 典型风电场功率预测各环节误差统计Table 2 Error statistics of each link for power prediction in typical wind farms
在测算的风电场中,高准确率风电场的Model环节误差占比较低,而低准确率的风电场Model 环节误差占比普遍偏高:风电场I 的预测准确率最低,其Model 环节误差占比为44.1%;风电场A 的预测准确率最高,其Model 环节的误差占比为30.8%,二者占比相差13.3%,其Model 环节预测误差分布集中在±0.2(标幺值)范围内(见附录A 图A4),其NWP 环节预测误差分布集中在±0.4(标幺值)范围内(见附录A 图A5)。综上,Model 环节误差是较低预测水平场站的普遍短板,是预测水平较差场站应重点解决的问题。
校正环节在较长统计周期中对整体误差影响较小,但个别场站的非计划停运导致部分时段出现较大误差。2019 年1~7 月,9 座测算风电场出现非计划停运事件共76 起,累计机组停运1 032 台⋅次,涉及装机容量为1 716 MW。校正环节误差的平均占比为0.3%,表明总体影响不大,各风电场均能按检修计划准确上报次日开机容量。但个别风电场非计划停运后,日前开机容量估算不准确造成了较大的预测偏差。例如,风电场A 在2019 年4 月30 日至5 月3 日期间,1 号主变压器故障检修导致28.8 MW风电机组非计划停运,由于日前开机容量未准确估算,导致校正环节误差占比分别达到34.6%,41.1%,37.6%和12.2%。此外,风电场E 和G 也出现了相似现象。校正环节误差反映了风电场功率预测工作管理及发电设备运维的水平。
NWP 环节误差通常是大预测偏差事件的主要成因。选取各场站预测准确率最低的10 天进行测算,9 座风电场NWP 环节误差平均占比为65.4%,较平均水平上升了6.6%,如表3 所示。

表3 预测准确率最低10 天的各环节误差统计Table 3 Error statistics of each link in 10 days with the lowest prediction accuracy
测算结果表明发生预测较大偏差的主要原因是NWP 偏差,持续提升NWP 环节预测水平是预防大偏差事件发生的重点工作方向。
4.2 大偏差事件算例
在某电网负荷晚峰17:00—22:30,风电功率预测出现明显预测偏差,如附录A 图A6 所示。风电实际出力先降后升,变化幅度大、速度快,与日前预测结果偏差明显。
按照本文提出的功率预测误差解耦评价方法,分别提取了各风电重点汇集区10 座典型风电场的功率预测数据、NWP 数据、风资源观测数据、开机容量等数据,对功率预测各环节误差进行解耦评价,评价结果统计如表4 所示。

表4 负荷晚峰时段风电预测误差统计Table 4 Error statistics of wind power prediction during evening peak load period
根据测算结果分析此次负荷晚峰时段预测偏差的主要特点:①NWP 环节误差占比高,在晚峰时段,区域GY,KB,SY,WQ,JSL 这5 个风电汇集区域的10 座典型风电场的NWP 环节误差占比平均值为74%,显著大于Model 环节误差占比平均值(26%);②NWP 环节误差方向一致,各风电场在晚峰时段的NWP 环节误差均为正向误差,即NWP 环节预测风速均大于实际风速,进而导致NWP 环节等效功率预测误差偏大;③不存在校正环节的等效误差,各风电场当天的实际开机均按日前开机计划执行。综上,NWP 环节的正向误差是此次负荷晚峰时段风电预测偏差事件的主要原因。
5 结语
本文提出了一种风电功率预测误差解耦评价方法,利用风电实际运行信息,定量化分析0~168 h 中短期功率预测各关键环节对整体误差的影响程度,为精准优化功率预测薄弱环节提供了前提。主要结论如下。
1)基于气象、电力等多源运行数据驱动,所提功率预测各环节等效影响误差的量度方法,实现了各环节时序误差的定量化评价,精细化分析预测偏差事件成因,精准定位问题场站及薄弱环节。
2)设计了基于核密度估计的风电异常工况分区间辨识方法,并建立了典型的风资源-电力特性的简化模型,解决了多类型误差评价模型在电网调度侧统一开发部署的难题,实现了海量运行数据的高效利用。
3)长期测算结果表明,NWP 环节是预测误差的主要来源(占比为58.8%),Model 环节是造成预测误差的重要来源(占比为40.5%),NWP 环节和Model 环节的误差共同构成了总误差的基本面。
4)Model 环节误差是较低预测水平场站的普遍短板,是预测水平较差场站应重点解决的问题;NWP 环节误差通常是大预测偏差事件的主要成因;校正环节误差反映了风电场功率预测管理和设备运行维护水平。
预测误差解耦评价的核心前提是掌握风电运行、气象观测、气象预测等多元数据,评价准确性高度依赖于实际数据质量,因此本文所提方法高效落地与推广应用的关键点是,未来如何探索通过技术和管理手段保障数据质量,实现多源海量信息的自动化、批量化、智能化处理与运算。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
