基于遗传算法的网络风险评估模型研究
2021-01-08廖菲菲
廖菲菲
(西华师范大学 计算机学院,四川 南充 637000)
0 引言
近日、中国互联网络信息中心(CN NIC)发布了第45次《中国互联网络发展状况统计报告》(以下简称“报告”),《报告》显示,截至2020年3月,我国网民规模为9.04亿,互联网普及率高达64.5%[1]。随着互联网的普及,越来越多的网络应用应运而生。网络购物、在线支付、即时通信、短视频、直播等应用逐步占领网民们的闲暇时间;而受新冠肺炎疫情影响,在线教育、电子政务等应用在疫情期间也发挥了举足轻重的作用。
《报告》显示:截至2020年3月,我国在线教育用户规模达4.23亿人,占网民整体的46.8%,在线政务用户规模达6.94亿人,占网民整体的76.8%。在此背景下,网络攻击也逐步由针对个人的小规模攻击衍生至针对教育、政务等公共事务的大规模攻击。
《信息安全技术网络安全等级保护基本要求(第二版)》的发布实施意味着国家对网络安全的重视程度与日俱增,文件要求网络运营者和关键信息基础设施运营商必须满足等保合规要求,否则将面临不同程度的处罚措施。而等级保护制度中,风险评估是基础,全面且正确的风险评估结果对企业用户的建设整改起到决定性的作用。
1 风险分析模型
信息安全风险,是指人为或自然的威胁利用信息系统及其管理体系中存在的脆弱性导致安全时间的发生及其对组织造成的影响。风险的构成包括5个方面:威胁源、威胁行为、脆弱性、资产和影响。其中,资产是与企业用户关系最为密切的属性。资产是指用户所拥有的一切对组织有价值的值得保护的对象。网络攻击会引起资产不同程度的损失,因此信息安全风险即体现在对资产的价值的损害上[2]。
根据资产的分类及自身价值的不同,其被损害之后的损失程度也不同,建立合理的风险模型有助于在建设部署信息安全防护时能有效利用有限资源保护最有价值的资产。目前常用的风险模型主要分为定性模型和定量模型两种类型。
1.1 定性模型
定性模型是指在风险评价时,通过分析者的经验或直觉,或者根据业界的标准等,人为的对风险的大小和损失后果进行定性。风险定性有可能性度量和影响性度量。
可能性度量是指该资产遭受攻击的频率及损失发生的概率,分为A—E共5个等级,依次描述概率从高到低分布的情况[3]。可能性度量的意义在于对资产的保护优先级进行排序,对遭受攻击的可能性较高的资产优先防护,对几乎不可能发生的攻击适当延后处理,有助于企业用户节省成本。
影响性度量是指资产遭受攻击时损失的程度及对其他资产造成的连锁影响,资产被攻击后遭受的损失分为1—5共5个等级,依次描述损失由低到高分布的情况。影响性度量的意义同样在于对资产的保护优先级排序,对遭受攻击之后损失较大的资产优先保护,对可以忽略影响的资产暂时不保护。
根据风险的可能性度量和影响性度量,可以在资产排查过程中建立资产风险矩阵,
矩阵值为资产被攻击概率和攻击之后遭受的损失确定风险等级。定性度量矩阵可以综合考虑可能性度量和影响性度量,为资产防护提供方向指导。
定性度量的风险因子均由网络安全人员通过经验或规则主观认定,因此适用于不同的企业用户,但其定性等级不够明确。假设资产A的可能性度量为几乎肯定且影响性度量为较小时,属于高风险资产,资产B的可能性风险为罕见且影响性度量为较大时,也处于高风险资产,如果基于成本考虑,须在资产A和B中选择其一进行安全防护时,定性度量矩阵就失去了作用。
1.2 定量模型
定量风险分析模型是指将各项资产的真实价值进行量化,从财务数字上对安全风险进行评估,与定性风险分析相比,定量分析更具客观性。
常用的定量风险分析模型以年度预期损失法为主,其建模流程如下:
1.2.1 单次损失SLE
单次损失是指,当资产总值遭受一次攻击时,损失的资产价值,由资产价值AV和暴露系数EF决定。计算公式如下:

其中,AV表示资产价值,EF表示暴露系数,即影响性度量。
1.2.2 风险年度发生率ARO
将风险的可能性度量量化为年度发生率,年度发生率的含义是指资产在一年内可能发生风险的次数。此次数可以由人为设置,也可以根据统计结果计算得出。
1.2.3 年度预期损失ALE
年度预期损失是通过资产单次损失值与风险年度发生率计算得出,计算公式如下:

1.2.4 控制成本SLE
控制成本是指针对存在风险的资产进行安全维护所耗费的成本,一般由企业财务预算确定。
1.2.5 安全投资收益RLE
安全投资收益由安全维护项目实施前后与控制成本决定,计算公式如下:

定量风险分析模型的核心参数即为安全投资收益RLE,该参数主要为企业提供安全维护优先级指导,某个资产的投资收益越高,则认为对该资产的安全维护越重要,反之则可以适当延后处理。
1.3 存在的问题
定性风险分析模型操作简单、易于达成一致性意见。更适合非专业人员参与建模,但重要风险之间的区分度不够且描述不够直观;定量风险评估模型对资产价值、损失大小、风险频率等参数进行量化计算,因此表述明确且易于存储数据。模型建立前期需要准备工作较多,实施时相对复杂。
以上两种风险模型均存在一个问题,即将资产或设备单独计算,未考虑到信息安全是一个系统的工程,其中的各种设备均具备一定的内在联系。为解决该问题,下面将提出一种基于遗传算法的风险分析模型。
2 基于遗传算法的风险分析模型
2.1 遗传算法的概念
遗传算法(Genetic Algorithm, GA)是模拟生物进化和遗传学的生理机理进行演变的计算模型,其特点是隐并行性和全局寻优性。算法初始状态下以个体为对象,利用随机的方式进行搜索,核心是选择、交叉和变异[4]。
2.2 基于遗传算法的风险评估模型
2.2.1 编码
在实际应用中,由于资产的多样性,不能直接存储在计算机中进行计算,因此需要对资产进行编码,在本算法中,对资产的价值和风险程度性度量进行编码,用F表示,每一个编码都表示一个资产,在遗传空间中称为染色体或者个体。编码函数如下:
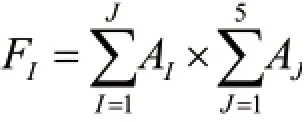
2.2.2 适应度函数
遗传算法中的适应度是指个体对环境的适应能力及繁殖后代的能力,在风险分析模型中,用资产的可能性度量来表示资产的适应能力,用资产与其他资产的连接度来表示繁殖后代的能力,具体计算公式如下:

上式中,fA表示资产A的适应度函数,ARO表示资产的年度可能性度量,Cx,y表示与资产A相关联的其他资产数。
2.2.3 选择
该模型中,初始群体随机产生,设置进化代数计数器,设置最大进化代数T。本模型中的选择算子采用模拟风险思想,当资产遭受损失时,会引起其他关联资产清除该风险资产的连接度,形成下一代染色体,重新计算其适应度函数。计算公式如下:上式中,A′表示资产A的繁殖后代,其适应度函数由资产A及其关联度决定。
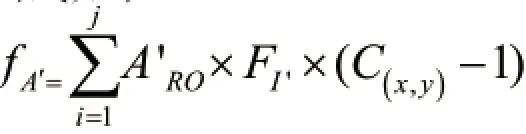
2.2.4 交叉运算
交叉运算是指把后代的两个父代个体的部分结构加以替换重组而生成新的个体的操作。在本模型中,假设有互相关联的资产A和B,因其中任一资产损失引起关联资产值变化生成下一代资产。通过交叉操作,可以将资产A和B编码中的风险性程度替换重组并重新计算下一代适应度。交叉概率通常采用轮盘赌算法进行交叉运算,计算方法如下:

2.2.5 变异运算
在繁殖过程中,新产生的染色体中的基因会以一定的概率出错,变异发生的概率用Pm表示,变异操作主要是一种局部搜索,防止出现未成熟收敛。
2.2.6 终止条件
当设置的个体适应度达到给定阈值,或者是个体最优解不再提高时,或者进化计数器达到最大进化代数时,算法终止。
3 结语
在本风险评估模型中,个体的适应度函数代表了资产的安全维护优先级,对企业安全投资起指导作用。与传统定性模型和定量模型相比,基于遗传算法的风险分析模型具有定量模型的直观性和易存储性,对风险等级的区分度高;同时也具有定性分析的一致性。在此基础上,基于遗传算法的风险分析模型还综合考虑了实际应用场景中网络的复杂性和连通性,将企业资产综合分析,具有较高的指导价值。
