基于 CNN 深度学习的径流预判方法及应用
2021-01-04唐海华黄瓅瑶
唐海华,李 琪,黄瓅瑶,周 超
(长江勘测规划设计研究有限责任公司,湖北 武汉 430010)
0 引言
洪水预报是极其重要的流域管理非工程措施,主要根据流域的水文气象特征、下垫面条件、干支流水系分布、遥测站网布设、降雨径流实测资料等相关信息,分析流域的水循环机理及降雨径流规律,编制水情预报方案,最后结合雨水情监测信息预测预见期内可能发生的径流过程,为开展流域的河道径流推演、防洪调度决策、供水调度计划编制、水力发电计划编制、水资源调配、水工程泄洪设施控制方式制定等提供确定性来水预报服务。
洪水预报的核心任务是构建流域水文模型并结合实测数据率定模型参数。据不完全统计,目前全世界已有 70 多个流域水文模型得到了广泛应用[1-3],较为经典的主要有国内的新安江、陕北和 API 等模型;美国的 Stanford,SWAT 和 SAC 等模型;英国的 TOPMODEL 和 IHDM 等模型;丹麦的 MIKE系列模型,以及日本的 Tank 模型,德国的 SWIM模型等。20 世纪 80 年代以来,以人工神经网络(ANN)[4]、支持向量机 SVM[5-6]等为代表的机器学习技术逐渐应用于洪水预报领域,多年实践已取得了一定成果。近年来,深度学习方法也开始应用于中小河流洪水预报[7-8]。
这些洪水预报业务过程极为复杂,建模工作要求较高,参数率定工作量巨大,且方案参数需定期人工修编。为此,将洪水预报过程简化为径流预判,以便快速定性预判目标站点在预见期内可能遭遇的来水流量等级,为来水形势分析、洪旱灾害风险防控、防汛抗旱会商等提供实时研判支撑。
同时,借鉴卷积神经网络(CNN)在计算机图像识别领域取得的突破性进展[9],探索基于 CNN 深度学习的径流预判模型搭建技术,以寻找一种便捷易用、响应快速、专业依赖性弱、实用性强、具备自主学习更新能力的径流预判方法,并结合某水库的来水等级预测实例进行分析验证。
1 径流预判任务
针对给定目标站点,结合其水文特征及径流特性,假定来水流量可从小到大依次划分为R个临界流量q:

对应可构成R+1 个径流等级区间Y:

则径流预判的任务本质上就是结合目标站点的实测雨水情及其他相关资料,快速分析出预见期内平均来水流量所处的径流等级区间。
若采用传统流域水文模型方法,首先需按预报时间计算目标站点预见期内的流量过程预测结果,然后对照式 (2) 统计得到最终径流预判等级。该方法主要存在以下局限:1)业务过程极为复杂,需要大量人工干预,具有很强的专业性和经验性,必须具备丰富的水文行业背景知识才能完成;2)水文建模过程中通常存在不同程度的模型参数、输入条件和边界约束的概化,不可避免地会忽略部分影响预报结果的关联因素;3)水文模型对降雨径流数据的依赖性非常强,必须具备齐全的多年连续序列资料才能充分发挥模型作用,取得较高的预测精度;4)水文模型参数通过历史数据率定获得,存在时效性,随着时间推移其代表性会受到影响,必须人工定期将最新资料纳入样本进行参数复核和更新;5)由于丰枯期产汇流特性差异较大,同一流域不同时期通常需构建不同的水文模型进行参数率定和计算,增加了应用难度和复杂度。
为解决上述问题,利用 CNN 深度学习思想权值少、复杂度低,能对输入数据自动进行分层特征提取等特点,通过自动学习挖掘输入数据的时空分布规律,将其应用于径流预判任务。
2 CNN 模型搭建方案
针对径流预判任务,结合相关实验给出 CNN 深度学习模型的具体搭建方案。
2.1 输入输出定义
选择与径流潜在相关的影响因子作为输入集合,具体数据类型包括:当前时间所在旬号,用于表示年内 36 个旬的周期季节特征;控制流域前期要素影响时长(假定为gh)内p个雨量站的降雨量、e个蒸发站的蒸发量、s个墒情站的土壤含水量和a个气象分区的温度过程;预见期(假定为fh)内a个气象分区的预报降雨量和预测温度过程;站点自身及其控制流域内c个控制站的当前流量和水位。这些不同物理涵义的数据序列构成一个完整的输入集。将各类数据序列按顺序依次排列为一个m×n的矩阵X,公式如下:

式中:m和n可根据输入集的总长度自由定义,但必须满足:
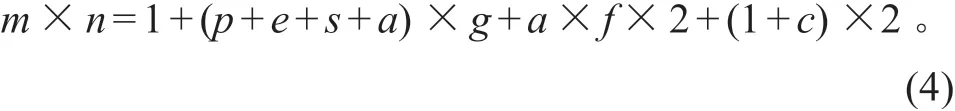
任一输入矩阵X,都对应式 (2) 流量等级区间Y中唯一的一个等级区间。
2.2 样本分类构建与数据转换处理
样本集按用途分为以下样本类型:
1)训练样本。用于在训练阶段学习和调整各类网络权值。
2)测试样本。用于测试训练过程中对训练样本中未出现过的数据的分类性能,并根据测试结果对网络结构或训练循环次数等进行调整。
3)检验样本。用于网络结构确定后,对通过训练学习获得的参数集进行预测的准确度检验。
本研究模型是一种基于数据驱动的预测方法,虽然能适用于任意大小的数据集,但用于训练的数据集要尽可能覆盖问题域中所有已知可能出现的情况,且必须具备足够的容量才能保障训练结果的有效性。因此,根据输入输出定义和样本划分方式,首先尽可能多地收集历史资料信息,并以时间轴为刻度,按输入矩阵X和输出等级区间Y的数据格式与对应关系构成输入输出的原始数据集;然后剔除含有各类无效信息的数据集,再按“7∶2∶1”原则筛选出其中的 70% 作为训练样本,20% 作为测试样本,10% 作为检验样本。每类样本均包含一一对应的输入和输出数据集。
将样本集中的所有原始数据输入数据集,按照数据的不同物理涵义分类进行标准差标准化。具体处理方式如下:首先汇集样本集内每个原始输入矩阵X中的第k类数据,然后分别求出该类型数据的平均值xk和标准差Sk,最后针对每个原始输入矩阵X中的实际值xk,i按下式进行处理得其对应的标准化值x'k,i:

标准化处理的目的在于消除各类数据的量纲和自身变异的影响。处理后,输入样本中的各类数据都被标准化成了无量纲的纯数据序列,正负大约各占一半,平均值为 0,标准差为 1。
2.3 多层卷积网络搭建
搭建多层卷积神经网络,具体层数通过后续网络性能测试结果确定。现以初始化 8 层网络为例,各层的详细描述如下:
1)卷积层C1。样本X的输入矩阵大小为m×n,为提取样本的多种不同特征,定义N个大小为j×j的卷积核W(W={W1,W2,…,WN})作为网络权值,对应偏移量为b(b={b1,b2,…,bN}),对X中的每个元素执行卷积操作,公式如下:

固定卷积操作的移动步长为 1,卷积完成后,采用 ReLU 函数的 max 函数作为激活函数,对卷积输出结果进行非线性映射。每个样本在本层可生成N个大小为 (m-j+ 1) ×(n-j+ 1) 的特征图,需要训练的参数共 (j×j+ 1) ×N个,对应的网络连接数为(m-j+ 1) ×(n-j+ 1)×(j×j+ 1) ×N个。
2)池化层S2。固定池化规模为d×d,针对C1层生成的N个特征图,将每个特征图中完全相邻的d×d个元素按最大池化法依次池化为 1 个元素,从而产生N个缩小了d×d倍的特征映射图,大小为m'×n',其中m'= (m-j+ 1) /d,n'= (n-j+ 1) /d。若不能整除,需要对边缘进行处理,将特征图用 0填充为d的倍数后再池化。
3)卷积层C3。定义N'个新的j'×j'卷积核,按C1层的方法对S2层的N个特征映射图进行卷积和激活,得到N'个新的特征图。本层的特征图需要全面反映上一层提取到的不同特征,因此,每个特征图应分别连接到S2中的所有N个或其中某几个特征映射图进行多种不同组合。
4)池化层S4。与S2层类似,采用最大池化技术将C3层特征图进行下采样处理,产生N'个大小为m''×n''的特征映射图。
5)卷积层C5。定义N''个新的j''×j''卷积核,其尺寸须小于或等于S4层特征图尺寸,然后按C3层的方法对S4层的N'个特征映射图进行卷积和激活。卷积层是否继续增加取决于是否还有特征需要抽象提取。
6)池化层S6。与S2层类似,采用最大池化技术将C5层特征图进行下采样处理,产生N''个大小为m'''×n'''的特征映射图。
7)全连接层F7。将S6层的二维特征图变为一维特征向量,定义全连接层节点个数,实现与一维特征向量节点的全连接映射。
8)输出层O8。根据式 (2) 的径流等级划分设计输出层节点数目,与全连接层互连。
2.4 损失函数及预测准确率定义
以均方误差最小化作为损失函数,公式如下:

式中:L为所有训练样本的总损失;I为训练样本总长度;yi为第i个训练样本的计算输出;ŷi为第i个训练样本的对应真值。
给定输入样本和网络模型各层参数后,按多层卷积网络搭建步骤逐层计算,输出层O8的预测准确率公式如下:

式中:a为预测准确率;I为输入样本总数;A为计算结果能正确映射样本真值的统计数。
2.5 参数训练
参数训练包括以下 2 个阶段:1)向前传播阶段。首先初始化C1,C3,C5及F7层的W和b参数,然后以样本分类构建与数据转换处理生成的训练样本中的输入矩阵为基础,逐层完成网络模型计算,得到相应的计算输出。2)向后传播阶段。首先按式 (7) 计算所有训练样本的总损失L,然后以总损失极小化为目标反向传播调整各层W和b参数,直到L无法下降或循环次数达预设上限为止。
对于训练过程中发现的异常值,可在输入网络训练前提前进行预处理修复,去除异常元素,尽量保证流量等级在合理数值范围内。一般来说,CNN网络学习的是大部分数据的空间模式特征,对于极少数无法识别的异常点,表明网络存在过拟合现象,即过度拟合了训练数据中的噪音而忽视了数据的整体规律,在网络训练中须采取一些正则化技术尽量避免。修正后依然存在的异常点,最终会体现为网络输出结果与真实值的差异,偏差大的数据点集反馈了 CNN 没有识别到某类异常值特征,此类偏差全部归集为模型预测的整体拟合误差。
2.6 网络性能测试
以样本分类构建与数据转换处理生成的测试样本和参数训练所得的各层W和b参数为基础,按多层卷积网络搭建步骤逐层计算,并按式 (8) 统计所有测试样本的预测准确率at。
假设网络性能达标的预测准确率下限为ad,当at<ad时,需对多层卷积网络搭建步骤中的网络结构进行调整(包括网络层数、各层卷积核大小及数量、循环次数上限等),然后重新执行参数训练得到新模型的各层参数,再次测试网络性能。依此循环,直到at≥ad,测试结束,记录当前网络结构与模型参数作为最终训练成果。若始终无法达到预期,则可适当下调预期成效。
2.7 预测精度检验
以样本分类构建与数据转换处理生成的检验样本为基础,按网络性能测试确定的网络模型及各层W和b参数逐层完成模型计算,最后按式 (8) 统计所有检验样本的预测准确率ac作为模型参数检验精度。
2.8 滚动学习训练
随着目标站点的数据资料不断积累增多,假定学习训练的滚动周期为T,则每过一个时间周期间隔就依次执行 2.2—2.6 节方案,进行模型参数的滚动学习训练。通过不断增补新样本参与模型训练,可保障模型参数的时效性。
2.9 知识自动更新
对于网络结构和模型参数的学习训练成果,采用知识库进行保存与管理。该知识库由增量库和实时库两部分构成,增量库用于累积存储每轮学习训练所得的网络结构和模型参数,随着时间推移会不断增多;实时库有且仅有 1 条知识记录,用于开展流量等级预测计算,根据学习训练滚动更新。因此,当每轮训练结束后,一方面会在增量库中自动保存本轮的学习训练成果,另一方面还会自动更新实时库的知识记录。
2.10 流量等级预测
针对任意给定时间(如当前或某历史时间),首先提取所有影响因子的对应数值,按式 (2) 和 (3) 构建输入向量,并按式 (5) 进行标准化处理;然后调用知识库中的实时库知识记录(对应唯一的网络结构和模型参数)进行网络模型计算,得出最终的流量等级,即为径流预判结果。
径流预判 CNN 模型搭建方案的总体流程如图 1所示。

图 1 径流预判 CNN 模型搭建方案流程图
3 应用案例分析
以某水库 2008 年 1 月 1 日至 2017 年 12 月 31 日共 10 a 的逐小时历史实际运行数据为例,采用本研究方法进行入库径流等级预判试验分析。该水库的前期要素影响时长和预见期均为 6 h,库区控制流域内有 130 个雨量站、16 个蒸发站、15 个墒情站和3 个气象分区,库区上游存在 2 个上边界控制站。其任意时间对应的输入数据序列依次为:旬号、各雨量站过去 6 h 的逐小时降雨量、各蒸发站过去 6 h的逐小时蒸发量、各墒情站过去 6 h 的逐小时土壤含水量、各气象分区过去 6 h 的逐小时实测温度、气象分区未来 6 h 的逐小时预报降雨与预测温度、水库坝址入库流量,以及各上边界控制站的实测流量。该数据序列长度为:1 + (130 + 16 + 15 + 3 + 3 + 3)×6 + 1 + 2 = 1 024,可构建 32×32 矩阵。
该水库入库径流分别以 8 000,10 000,14 300,18 300,25 000,30 000,35 000,56 700,80 000为临界值,可划分 10 个流量区间。
该水库的历史运行数据资料须提前进行合理性检验处理。水库坝址入库流量是按水量平衡公式反算所得的,流量序列存在“锯齿”跳变现象,甚至部分时段为负数,与天然流量涨落的客观规律不符。本研究采用七点滑动平均法对入库流量序列进行平滑处理,大幅削减其跳变程度。若平滑后仍存在负数,则视为异常样本,须找出其前后相邻最近的非负流量按线性插值方式处理。其余雨量、蒸发、墒情、温度均为传感器测量所得,可直接视为真值,但除温度外,须全部进行非负判断,若为负则按 0 处理。
经检验处理后的 10 a 历史序列长度均为(365×10 + 3)×24 = 87 672。由于水库存在 6 h 前期影响时长和预见期,实际可生成的样本长度为 87 672 -6 - 6 = 87 660。按时间顺序进行样本分组,则训练、测试和检验等样本的长度分别为 61 362,17 532,8 766。
按照 CNN 模型搭建方案,搭建的 8 层径流预判模型如下:
1)C1层各输入矩阵大小为 32 × 32,定义 9 个大小为 5 × 5 的卷积核作为网络权值,固定移动步长为 1,执行卷积操作并激活后,可生成 9 个28 × 28 的特征图;
2)S2层采用 2 × 2 规模对C1层生成的特征图进行池化,产生 9 个 14 × 14 的特征映射图;
3)C3层再定义 27 个 5 × 5 卷积核,分别连接到S2中的所有特征映射图进行多种不同组合,卷积和激活可生成 27 个 10 × 10 的特征图;
4)S4层继续采用 2 × 2 规模对C3层生成的特征图进行池化,产生 27 个 5 × 5 的特征映射图;
5)C5层定义 81 个 4 × 4 的卷积核(须小于或等于S4层输出的特征映射图大小),对S4层的 27 个特征映射图进行卷积和激活,生成 81 个 2 × 2 的特征图;
6)S6层采用 2 × 2 规模按最大池化法对C5层生成的特征图进行下采样,得到 81 个 1 × 1 的特征映射图;
7)F7层定义 81 个全连接层节点数,与S6层生成的 81 个一维特征向量节点进行全连接映射;
8)O8层根据 10 个流量等级区间形成 10 个输出节点与F7层互连。
模型搭建完成后,设置最大循环次数为 1 000 次,期望准确率为 80%,采用训练和测试样本进行迭代训练,采用检验样本统计检验精度。为便于比较,同步采用传统水文预报的新安江和 API 模型对本例进行预报计算(过程略),其中训练和测试样本全部用于模型参数率定,检验样本相同。各方案对比如表 1 所示。

表 1 不同预报模型检验合格率对比
可见,3 种方法的入库径流等级预判检验精度均较高。因流量等级侧重于定性预测流量范围,故预测精度整体高于常规的定量洪水过程预报。基于 CNN深度学习的径流预判方法与传统水文模型方法相比,预测结果极为接近,满足预测期望。然而,本研究方法对历史数据资料的依赖程度较高,且弱化了物理成因机制,因此,对于数据资料不足或水文机理较为复杂的区域,基于 CNN 深度学习的径流预判方法的适用性及预测精度还有待进一步研究验证。
4 结语
基于 CNN 深度学习提出的径流预判方法,是最新人工智能技术在水文预报领域的融合应用,实例结果表明:该方法行之有效,预判结果可信度高,与传统水文模型的预测精度极为接近。本研究方法一方面将预测任务从复杂的专业逻辑中剥离出来,把分析重心转移到数据本身,而不再去探究各类数据的物理含义和成因关系,最大程度地降低对水文学科知识和模型应用经验的依赖;另一方面,直接将与预测目标存在潜在关联性的庞大信息群体作为输入集合进行建模、学习、训练和分析,扩大影响因子范围,减少人为概化,尽可能降低影响因子的丢失风险。此外,不需单独针对洪水和枯水建模,可直接根据学习训练所获知识进行径流等级预测,并能通过不间断地滚动自主学习训练对预测知识进行更新。未来,随着对输出层进一步细化分解,还可尝试直接用于预测预见期内的定量径流过程,具有很强的拓展意义和推广应用价值。
