基于改进教学式方法的可解释信用风险评价模型构建
2021-01-04董路安
董路安,叶 鑫
(大连理工大学经济管理学院,辽宁 大连 116024)
1 引言
全球金融危机爆发以来,银行和金融机构的风险控制问题受到了广泛的关注。信用风险评价作为风险防控的主要工具之一,为银行和金融机构有效衡量贷款风险,降低潜在信贷违约风险,并制定决策提供了保障[1]。随着人工智能浪潮的来袭,基于机器学习的信用风险评价模型以其精确的预测结果受到银行等金融机构的青睐,正逐步取代以信用评分卡和回归为主的传统信用风险评价[2-5]。但与传统信用风险评价方法相比,机器学习模型是一个黑箱模型,对投资者而言缺乏必要的可解释性[6]。由于投资者缺乏有效的机制了解机器学习模型内部决策过程,导致投资者无法完全信任其预测结果[7-8]。同时为保证申请人具有平等的贷款机会,欧盟在《一般数据保护条例》(General Data Protection Regulation, GDPR)中要求银行所使用的信用风险评价模型能够为其预测结果提供必要的解释[9]。这也限制了其在信用风险评价中的应用及推广[10]。因此,提高基于机器学习的信用风险评价模型可解释性,构建兼顾准确性与可解释性的信用风险评价模型,成为信用风险评价的关键。
为实现模型的准确性与可解释性间的有效权衡,Craven等[11-12]提出了TREPAN算法,该方法利用神经网络对数据集进行重新标注,新标记的数据集(伪数据集)被用于决策树的训练,并通过局部和全局约束准则控制决策树的可解释性,实验表明所生成的决策树更易于决策者理解。Baesens等[6]将TREPAN算法应用于信用风险评价研究,并通过实验验证了该方法在信用风险评价上的可靠性。但TREPAN算法所生成的决策树是基于M-of-N形式规则的,单个规则不利于决策者理解[13]。针对TREPAN算法的局限性,Schmitz等[14]以CART决策树为基础提出了ANN-DT方法,并通过控制决策树最大深度使生成的决策树更具有可解释性。Wu等[15]提出树正则化概念,通过树正则化对黑箱模型进行约束,使黑箱模型指导生成的决策树具有更好的可解释性和准确性。Huysmans等[16]将上述方法归纳为教学式方法(Pedagogical method)。该类方法参照人类教学过程,利用决策树(学生)学习和模拟机器学习模型(教师)的功能,所生成的决策树既保留了机器学习模型预测精准的优点,又能发挥决策树易于决策者理解的优势。由于教学式方法在解决模型的准确性与可解释性权衡问题上的良好表现,引起了国内外学者的关注。
总体来看,教学式方法在信用风险评价领域已进行了一些探索性的尝试,但现有的研究并未对机器学习模型功能的正确性和可信度进行衡量,模型中错误的或可信度低的功能会降低决策树的预测精度,影响其在信用风险评价中的效果。同时在决策树构建过程中,现有的方法对于生成决策树的准确性、可解释性以及其与机器学习模型的一致性三者间缺乏有效地权衡,影响整体效果。基于此,本文提出了一种基于改进教学式方法的信用风险评价模型构建方法。(1)为提高所生成决策树在信用风险评价中的预测精度,该方法对机器学习模型功能的正确性和可信度进行了有效的衡量,决策树仅学习和模拟机器学习模型中正确且可信度高的功能。(2)为更好的实现决策树在各评价指标间的有效权衡,提出了一种新的决策树剪枝方法。在实证分析中,利用3个真实信用风险评价数据集对本文方法进行了验证,并取得了较好的应用效果。
2 面向信用风险评价的改进教学式方法
信用风险评价本质是一种信用分析工具,其核心是预测贷款结果,并辅助投资者进行决策。本节将结合信用风险评价问题对教学式方法进行简要的介绍,分析其存在的局限,并提出改进的教学式方法。
2.1 教学式方法及局限
教学式方法模拟人类教学过程,将机器学习模型和决策树分别视为教师和学生。机器学习模型(教师)被用来指导决策树(学生)的构建与训练,其目标是所生成的决策树能够近似模拟机器学习模型功能,在信用风险评价中做出准确预测,且模型及其预测结果易于决策者的理解。教学式方法的流程框架如图1所示。
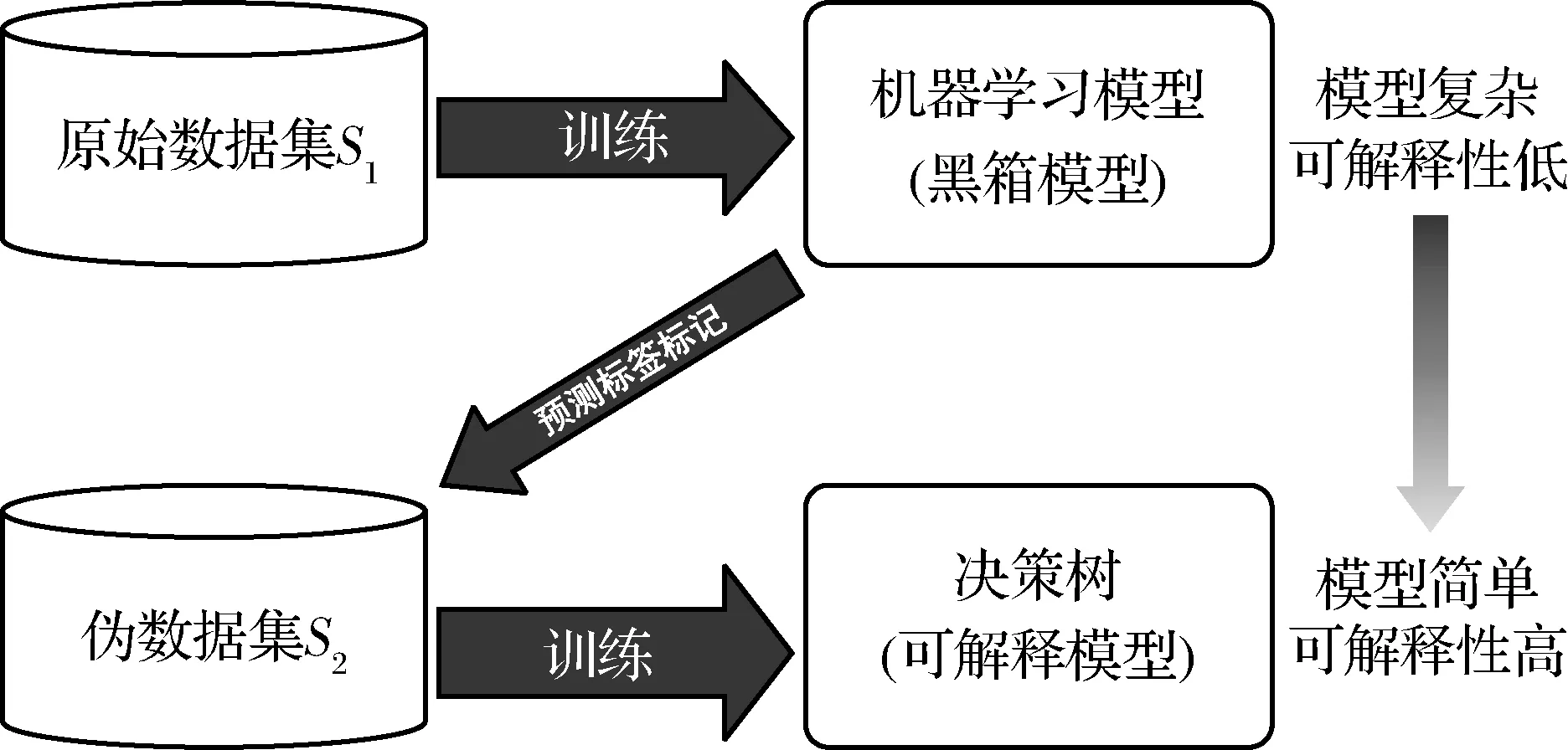
图1 教学式方法流程框架
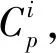
(1)
决策树通过学习和模拟机器学习模型的功能,继承了机器学习模型预测精准的优势,且决策树结构简单,决策过程和预测结果易于决策者理解。但现有的方法仍存在以下局限:
(1)现有的方法对于机器学习模型功能的正确性和可信度缺乏有效的识别,机器学习模型所包含的错误的或可信度低的功能,会导致模型在信用风险评价时做出错误预测,影响投资者的决策。决策树在学习和模拟机器学习模型过程中,应避免对于错误的或可信度低的功能的学习,而应更关注对于正确且可信度高的功能的学习与模拟,以提高其在信用风险评价中的预测精度;
(2)在决策树生成过程中,决策树剪枝可以有效地提高模型的可解释性。但现有方法对于准确性、可解释性以及所生成决策树与机器学习模型的一致性三者间缺乏有效地权衡,往往只考虑单一方面,而忽略其他方面,影响整体效果。
2.2 改进的教学式方法
针对上述问题,本节提出一种改进的教学式方法,以构建准确且可解释的信用风险评价模型。相较于传统教学式方法,为提高决策树的预测精度,本方法在伪数据集生成阶段,对机器学习模型功能的正确性和可信度进行度量,并提出了基于Weight-SMOTE的伪数据集生成方法,来提高正确且可信度高的样本在伪数据集中的比例,以此提高决策树对于机器学习模型中正确且可信度高的功能的学习能力。其次,为实现决策树在准确性、可解释性及其与机器学习模型一致性间的有效权衡,在决策树生成过程中,提出了一种新的决策树剪枝方法,以提升决策树的整体效果。此外,针对保真度评价指标的局限性,提出了真保真度评价方法,以更有效地衡量决策树与机器学习模型正确功能的近似程度。
2.2.1 基于Weight-SMOTE的伪数据集生成方法
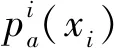
(2)
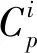
算法1:基于Weight-SMOTE的伪数据集抽样算法
步骤1伪样本集中逾期贷款数据抽样

步骤1.2 根据伪样本被选择的概率,采用轮盘赌方法从集合T0中选择伪样本xi;
步骤1.3 根据式(3),计算xi与集合T0中剩余伪样本的欧几里得距离,距离T0最近的h个伪样本被选择
(3)
其中,n为伪样本包含的属性数量,xiu和xju为伪样本xi和xj的第u个属性的取值;
步骤1.4 从h个近邻中随机选择一个伪样本xj,与伪样本xi构建新的伪样本xnew,并将新生成的伪样本添加至T0,构造公式为:
xnew=xi+rand(0,1)×(xj-xi)
(4)
其中rand(0,1)表示区间(0,1)内的一个随机数;
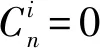


2.2.2 决策树剪枝方法
决策树剪枝能够有效提高决策树的可解释性,利于投资者理解决策树的决策过程。在决策树生成阶段,决策树剪枝需要综合考虑以下三个方面:1)决策树的准确性,即决策树的预测标签应与实际标签一致;2)决策树的可解释性,即决策树应尽可能的简洁,利于投资者的理解;3)决策树与机器学习模型的一致性,即决策树能够近似模拟机器学习模型。为了实现决策树在以上三方面间的有效权衡,本文在决策树预剪枝过程中采用了一种新的决策树评价方法,该评价方法如式(5)所示。
E=∑(yn-y)2+∑(yn-ym)2+λ1φ1+λ2φ2
(5)
式(5)中,∑(yn-y)2反映了决策树的准确性,yn和y分别为决策树对于样本的预测标签和样本的实际标签。决策树预测越准确则该项值越小;∑(yn-ym)2体现了决策树与机器学习模型的一致性,其中ym为机器学习模型对于样本的预测标签,该项值越小,则说明决策树与机器学习模型预测结果越一致,决策树与机器学习模型功能的近似程度越高;λ1φ1与λ2φ2为正则化项,反映了决策树的可解释性,其中φ1和φ2分别为决策树中叶子节点数以及决策树的平均路径长度,而λ1与λ2为二者的权重,λ1φ1与λ2φ2之和越小则表明生成的决策树可解释性越高。该评价方法从准确性、可解释性以及决策树与机器学习模型一致性三个方面对决策树进行综合评价,确保三者间的有效权衡。
2.2.3 教学式方法的评价
与传统的监督学习不同,教学式方法在训练过程中使用机器学习模型作为“教师”,来指导生成一个能近似表达机器学习模型功能且易于解释的决策树。因此,教学式方法的评价除需考虑所生成决策树的准确性外,还需考虑所生成决策树的可解释性及其与机器学习模型功能的一致性。
(1)准确性
教学式方法所生成的决策树需要具备较高的准确性,才能更精准的辅助决策。现有研究中,决策树的准确性多采用决策树在测试集上的准确率来衡量。准确率越高,生成的决策树越准确,反之亦然。准确率的计算如式(6)所示。

(6)
其中,TP、TN、FP、FN分别为真正类、真负类、假正类和假负类[17]。
(2)可解释性
教学式方法所生成的决策树要易于投资者理解,即需要具备可解释性,才能够在信用风险评价中为投资者提供更好的决策支持。决策树的可解释性主要由叶子节点数、根节点至叶子节点的平均路径长度两个方面所决定。一方面,决策树所包含的叶子节点数越多,决策树所能够转化得到的规则越多,投资者解释规则所需的时间也越多,模型的可解释性越低。另一方面决策树的平均路径越长,决策树转化得到的规则所包含的约束也越多,投资者解释规则的难度增加,模型的可解释性越低。
(3)决策树与机器学习模型的一致性
决策树与机器学习模型的一致性体现了决策树与机器学习模型功能的近似程度,一致性越高,二者功能越相似。现有的研究对于决策树与机器学习模型的一致性的度量多采用保真度评价指标,如式(7)所示。
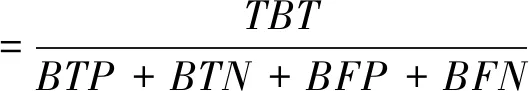
(7)
其中TBT为决策树与机器学习模型预测结果一致的样本数量,BTP、BTN、BFP、BFN分别代表了机器学习模型预测正确的非逾期样本数量、预测正确的逾期样本数量、预测错误的非逾期样本数量和预测错误的逾期样本数量。保真度通过决策树与机器学习模型预测结果的一致性来有效的衡量决策树与机器学习模型整体功能的近似程度,保真度评价指标既关注了决策树对于模型中正确功能的学习能力,也考虑了模型错误功能对于决策树预测精度的影响。但在改进式教学方法中,通过基于Weight-SMOTE的伪数据集生成方法,保证了决策树仅能够学习机器学习模型中正确的功能,避免了决策树学习模型中错误的功能。因此决策树与机器学习模型的一致性应表现为决策树与机器学习模型中正确功能的近似程度,近似程度越高,决策树模型的价值越大。而保真度评价指标难以满足本文对于决策树与机器学习模型一致性评价的实际需求。
针对保真度评价指标的局限性,本文提出了真保真度评价指标来更客观的评价决策树与机器学习模型中正确功能的近似程度,真保真度可通过式(8)计算:
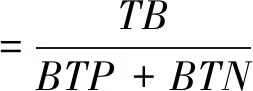
(8)
其中TB为决策树与机器学习模型均预测正确的样本数量,真保真度越大,所生成的决策树与机器学习模型正确功能的近似程度越高。
3 实验与结果分析
本研究采用随机森林作为底层机器学习模型,随机森林作为一种集成学习方法,在信用风险评价领域表现出了良好的效果[2,18]。为了验证本文所提出的改进教学式方法在提高信用风险评价机器学习模型可解释问题上的有效性,采用了3个真实的信用风险评价数据集进行实例验证研究。
3.1 样本与特征选择
本文共采用3个数据集:Australian数据集、German数据集和Lending Club数据集。Australian数据集和German数据集来自机器学习领域权威的UCI数据库。Lending Club数据集则来自美国最大P2P网贷平台——Lending Club平台上发布的2016年全部借款记录。针对本文的信用风险评价问题,本文选择了全量的标记借款状态为“Charged off”和“Default”的借款作为逾期贷款(其标签为0),而随机选择了等量的借款状态为“Fully paid”的借款记录作为非逾期借款(其标签为1)。本文参考文献[2]中所使用的Lending Club数据特征,共选择15个原始特征并进行预处理,所选特征及预处理方法如表1所示。在使用数据进行建模之前,对数据进行标准化处理,以避免不同特征取值范围对分类结果的影响[19-20]。

表1 Lending Club数据集特征及预处理方法
3.2 模型评价准则
为全面的评价所提出的方法,本文从准确性、可解释性以及决策树与机器学习模型一致性三个方面进行评价。准确性采用准确率进行衡量,计算方式如式(6)所示。可解释性主要从生成决策树包含的叶子节点数、根节点至叶子节点的平均路径长度两个方面评价。而决策树与机器学习模型一致性则采用真保真度进行评价,其计算方法如式(8)所示。
为保证实验结果的客观性,所有实验均采用10折交叉验证。
3.3 相关参数设置
本文实验相关参数设置如下:
(1)随机森林可调参数设置
随机森林规模及决策树最大深度是随机森林的关键参数,对于随机森林的分类结果准确性具有较大的影响。为获得最佳的随机森林参数,本文采用网格搜索方法对随机森林参数进行调优,网格搜索相关参数如表2所示。

表2 网格搜索参数
通过网格搜索,随机森林在各数据集上的最佳参数组合如表3所示。

表3 随机森林最佳参数组合
(2)Weight-SMOTE可调参数设定
在Weight-SMOTE算法中k%的取值反映了投资者所信任的机器学习模型功能的比例,k%的取值越小,则决策树学习机器学习模型中可信度低的功能的比例越低,其对于生成决策树的效果具有显著的影响。对于不同数据集和机器学习模型,该参数不存在通用值,只能依据实际情况与投资者的需求进行设定,本文采用试凑法来确定该参数。Australian数据集、German数据集、Lending Club数据集的k值分别选取95,95和75。此外,h的取值为5。
(3)决策树剪枝可调参数设定
决策树剪枝的参数选择对决策树的性能具有影响。针对不同的问题与投资者的需求,决策树剪枝的参数选择也有所不同,因此本文选择了多组备选参数。为了保证决策树剪枝算法性能,本文针对所使用的数据集,进行了探索性实验,以确定各参数取值区间,并在区间内均匀选取多个参数值,如表4所示。

表4 决策树剪枝参数
3.4 实验结果分析
3.4.1 信用风险评价效果分析
为检验改进的教学式方法的有效性,本文首先对比了改进的教学式方法与传统的教学式方法、决策树以及随机森林(RF)在3个信用风险评价数据集上的表现,由于正则项系数λ1与λ2对于生成的决策树的效果具有影响,为了检验不同参数取值组合下方法的表现,每一数据集选取了4组具有代表性的λ1与λ2取值,实验结果如表5、表6和表7所示。
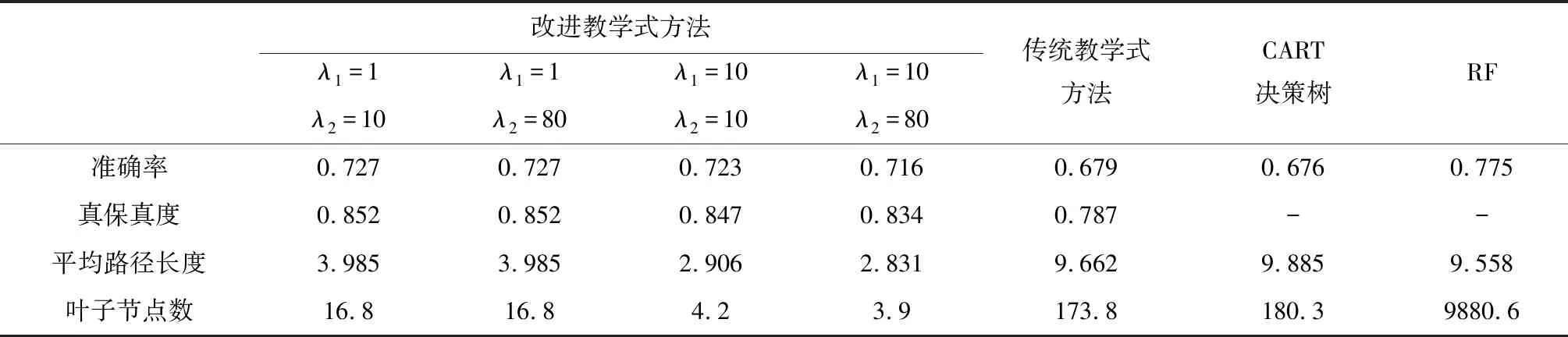
表5 本文所提方法与对照方法在German数据集上结果对比
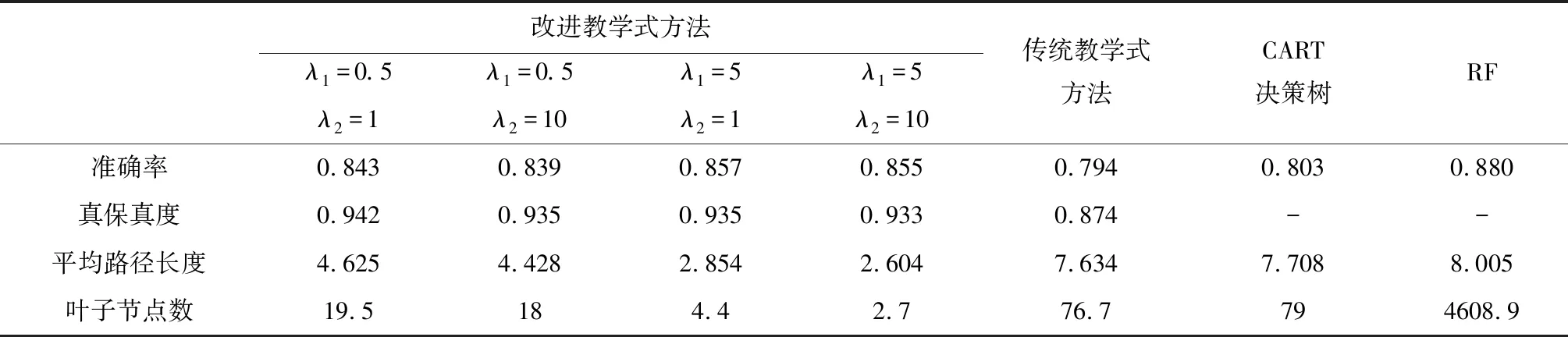
表6 本文所提方法与对照方法在Australian数据集上结果对比
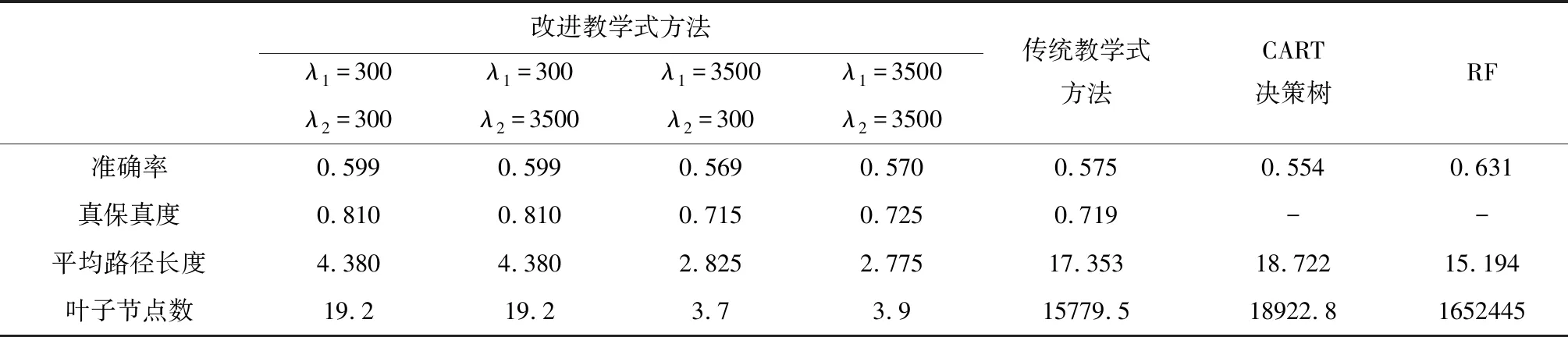
表7 本文所提方法与对照方法在Lending Club数据集上结果对比
根据上述实验结果可以得出以下结论:1)在准确率方面,改进教学式方法整体上优于传统教学式方法和CART决策树,在信用风险评价中表现出了良好的分类性能。虽然随机森林的准确率在三个数据集上均高于改进式教学方法,但其缺乏可解释性的弊端也使其预测结果无法在实际应用中被决策者所信任;2)相比于传统教学式方法,改进教学式方法具有更高的真保真度,表明其所生成的决策树能够更好的学习和模拟随机森林中正确的功能;3)从平均路径长度与叶子节点数来看,改进教学式方法所生成的决策树包含的叶子节点数均少于20,平均路径长度均小于5,在三个数据集上均显著优于传统教学式方法、CART决策树和随机森林,表明改进式教学方法所生成的决策树具有极强的可解释性,有助于投资者的理解和掌握。4)通过分析不同正则项系数组合下方法的效果,可以看到λ1与λ2对于所生成的决策树的性能具有影响。对于不同的投资者而言,可以根据自身的决策偏好选择合适的正则项系数的组合,以生成满足自身决策需求的信用风险评价模型。
此外,许多研究表明准确率与可解释性间存在制约关系,模型可解释性的提高在一定程度上会造成模型预测精度的下降[21-23]。在上述实验中,改进教学式方法通过牺牲一定的准确率,有效的提升了生成决策树的可解释能力,该结果进一步验证了上述研究结论。
3.4.2 基于Weight-SMOTE的伪数据集生成方法对真保真度的影响分析
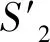

表8 基于Weight-SMOTE伪数据生成在German数据集上真保真度表现

表9 基于Weight-SMOTE伪数据生成在Australian数据集上真保真度表现

表10 基于Weight-SMOTE伪数据生成在Lending Club数据集上真保真度表现
由上述结果可以得出以下结论:采用基于Weight-SMOTE的伪样本生成方法对于提升所生成决策树的真保真度具有显著效果,有利于决策树学习和模拟机器学习模型中正确且可信度高的功能。
3.4.3 决策树剪枝方法比较
本文对比采用不同决策树剪枝方法的效果,以验证本文所提出的决策树剪枝方法能够更好的实现准确率、可解释性和真保真度三者间的有效权衡。对于每一种决策树剪枝方法,通过改变其参数可获得一组具有差异的备选决策树,投资者可以根据决策树的准确性、可解释性以及真保真度来选择符合自身决策偏好的决策树。因此,备选决策树集合可以看作是该问题的一组解,备选决策树集合整体表现越好,越能够满足不同投资者的需求。本文采用超体积指标(HV值)来评价备选决策树集合的整体表现,HV值表示解集的Pareto最优解与参考点所覆盖的体积(或面积),HV值越大则表示解集质量越高[24]。本文选择(1,1,1,1)为HV值计算的参考点,并在计算HV值之前,通过式(9)对各评价指标进行转化,使其满足以最小化为目标,且取值区间为[0,1]。
(9)
表11分别给出了不同决策树剪枝方法在三个数据集上的HV值。本文所提出的方法HV值在3个数据集上均显著优于基于决策树最大深度的剪枝算法和基于决策树最大子叶节点样本数的剪枝算法,表明该剪枝方法能够更好的实现决策树对于准确性、可解释性以及真保真度三者之间的权衡,其生成的备选决策树集合能够更好的满足实际信用风险评价的需求。
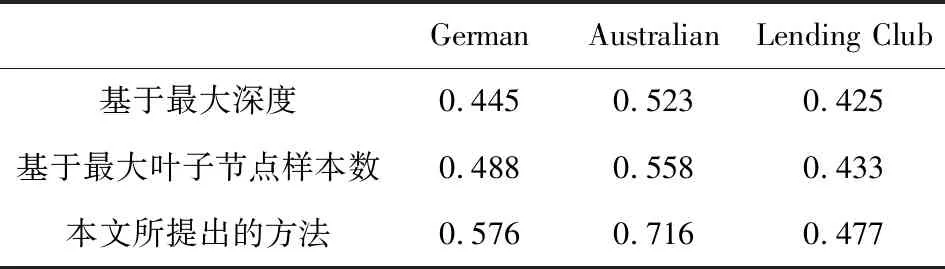
表11 不同决策树剪枝算法HV值
综合上述实验分析结果,本文所提出的改进教学式方法能够利用机器学习模型指导构建兼顾准确性和可解释性的信用风险评价模型,所生成的决策树模型能够辅助投资者有效识别具有潜在违约风险的贷款申请。同时,与机器学习模型相比,决策树模型可解释性更高,其决策过程与预测结果更易于投资者理解。
4 结语
准确的信用风险评价,可为金融机构决策制定提供支持,也有利于保障投资者的收益。机器学习等黑箱模型的广泛使用,大幅度提高了信用风险评价模型的准确性,但是机器学习模型缺乏可解释性的弊端使其无法完全被决策者所信任。教学式方法通过模拟人类教学过程,利用机器学习模型指导决策树的构建与训练,所生成的决策树能够近似机器学习模型的功能,满足信用风险评价预测需求,且易于决策者的理解。本文针对教学式方法的局限性,提出了改进的教学式方法,该方法能够提高决策树与机器学习模型中正确且可信度高的功能的近似程度,同时采用一种新的决策树剪枝方法,使生成的决策树能够实现准确率、可解释性和真保真度三者间的权衡。此外,针对保真度评价指标的局限性,本文提出了真保真度评价指标,以有效衡量决策树与机器学习模型正确功能的近似程度。为了验证所提出方法在实际使用中的效果,本文利用 2个UCI信用风险评价数据集和Lending Club数据集进行实验验证,实验结果表明本文所提出的改进的教学式方法在进行信用风险评价时是行之有效的,能够根据决策者的不同决策偏好与实际需求提供相对准确且可解释的信用风险评价模型。与基于机器学习的信用风险评价模型相比,该方法所生成的决策树能够更好的为决策者提供决策支持。此外,考虑到决策者从众多决策树中选择符合其决策偏好的决策树需要花费大量的时间与精力,本研究未来的工作将进一步研究满足决策者决策偏好的最优决策树选择方法,从而辅助决策者选择最优的决策树。同时,为了便于决策者在实际中的应用,动态自适应的模型参数选择方法也将是未来研究的重点之一。
