艺术类高校人才自主选拔模型设想与实现
2021-01-04中国美术学院浙江杭州310024
陈 效(中国美术学院,浙江 杭州 310024)
一、背景介绍
中国美术学院于2010 年开始进行本科招生改革,由原来的专业招生更改为现在的大类招生。改革的目的是为了配合学院 “两段式” 的教学模式,同时能让学生有 “二次” 选专业的机会,从而在完善本科教学的人才培养模式。
所谓大类招生,即在考生报考我院时,按造型艺术类、设计艺术类、图像与媒体艺术类、中国画类和艺术理论类进行录取。考生被录取后,一年级统一进入专业教学基础部、中国画系和艺术理论基础部进行基础学习。于一年级下半学期末进行专业分流,二年级进入相应的专业或专业方向学习(每年因专业建设需要,部分专业会停招,也会有部分新专业进行招生)。
依据《中国美术学院本科生专业分流方案(试行)》(以下简称《方案》),基础教学部制定分流工作实施细则和具体日程安排,并在教务处的指导下,分动员准备、模拟分流、正式分流三个阶段进行。
第一阶段作为准备期,告知并让学生确认第一学期成绩和学年各门课程学分;张榜公布各分部按照加权平均分成绩排序的全体学生名单以及各大类专业招生的学生计划数;让学生了解学院分流方案办法和具体流程。
第二阶段作为试分流期,通过模拟分流让学生对分流工作有进一步了解,也让具体实施的工作人员有一个适应的过程,及时掌握学生的志愿意向。
第三阶段作为分流的正式阶段分三轮进行。第一轮,公布各教学单位接收人数70% 的名额,学生填写平行志愿,按照加权平均分排名依次选择专业方向;第二轮,在学生完成第一轮选择后,剩余各专业30% 的名额,由教学单位组织选拔,第二轮教学单位选拔顺序以抽签的方式来依次进行,被教学单位选中,而不愿意者,直接进入第三轮;第三轮,在前两轮仍未分流到专业方向的学生,在有剩余名额的专业方向中填写参考志愿,由学院统一安排进入各专业方向。
二、问题的提出
从分流工作的程序中,我们可以看到在目前的教学评价方法下,学生在一年级的学习成绩(包括各门专业必修课和公共必修课)对于分流是关键。因此,学生在填报分流志愿前对于各项直接影响到成绩的因素格外关注。加上艺术类院校学生对于成绩的感性认识使得他们无法平衡专业必修课与公共必修课之间的关系。换言之,对于大部分成绩一般或者专业文化不平衡的学生,在填报专业分流志愿时带来了极大的困惑和压力。而对于教学管理部门来说,倘若以传统的仅统计专业必修课和公共必修课的加权平均分来寻找其中的规律从而指导学生填报志愿的话,势必显得不够全面和详细。因此,如何借助更为科学和严谨的数据分析方法,并将其作为工具使用到实际分流工作中,是本文的研究内容。
三、数据挖掘原理
数据挖掘,是指从大量数据中提取或者挖掘有效的、新颖的、潜在有用模式的非平凡过程。广义上讲,数据挖掘是从存放在数据库、数据仓库或其他信息库中的大量数据中挖掘有趣知识的过程。简单的说,就是从数据中找出有用的部分,舍去无用的部分。
数据挖掘是知识发现的一个特定的步骤,所谓的知识发现(KDD:Knowledge Discovery in Database)是指从数据中发现有用知识的整个过程。而数据挖掘是知识发现中用专门算法从数据中抽取模式的过程。知识发现KDD 过程主要由以下7 个步骤组成:① 数据清理,② 数据集成,③ 数据选择, ④ 数据变换,⑤ 数据挖掘,⑥ 模式评估,⑦ 知识表示。
使有价值的知识、规则或高层次的信息可以从数据库的相关数据集中抽取出来,使大型的数据库作为一个丰富可靠的资源为决策服务。数据挖掘有以下几个特点:
(1)处理的数据规模十分庞大,否则简单地使用统计方法处理就可以了。
(2)用户查询的要求往往是不精确的,需要数据挖掘技术帮用户查找他们可能感兴趣的东西。
(3)数据挖掘既要担负发现潜在规则的任务,还要管理和维护规则。
(4)数据挖掘中,规则的发现基于大样本的统计规律,当置信度达到某一阀值时,就可以认为规则成立。
四、数据模型的指导思想及流程
数据模型的指导思想为:根据考生的基本信息(即各项文化课和专业课成绩),依据学校管理部门对于文化课和专业课的赋权,结合数据挖掘算法,对历史数据进行聚类,从而得出该学生的专业分流评估值,最后给出评估值最高的一个或两个专业作为参考。本文将以造型分部专业分流据说为例。
根据模型的指导思想,可以得到专业推荐模型的流程(图1)所示。
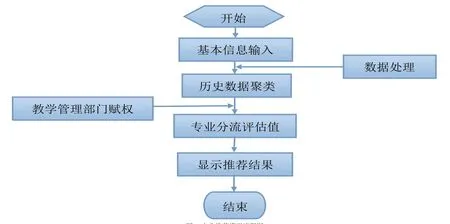
图 1 专业推荐模型流程图
五、专业指标体系
在填报专业志愿时,学生考虑的因素较多,但就目前政策而言有以下二十四个指标:大学计算机基础、大学英语1、纲要、解剖、外国文学、艺术概论1、大学英语2、基础、体育1、透视、艺术概论2、中国文学、传统书画基础1、色彩1、素描1、形式基础1、传统书画基础2、色彩2、素描2、形式基础2、专业所在院系高级职称数、专业作品获奖次数(不同比赛层次的折算分值不同)、奖学金覆盖率和就业率。
其中,根据目前现行《中国美术学院专业评价体系》和《中国美术学院本科招生分流方案》文件精神,将上端院系高级职称数、专业作品获奖次数、奖学金覆盖率和就业率等指标体系统一作为专业评价体系来执行,学校每4 年对现有专业进行评估,从而得出最终专业分值。
因此,可将学生分流中考虑因素总体指标体系定为3 个,分别是个人文化课成绩、个人专业课成绩和专业评估值三项。
六、实验分析
1. 数据准备
本文通过正方教务管理系统,利用教学任务平台、学生成绩平台中的相关数据,抽取特定学生成绩统计排名的数据作为样本数据进行试验。
(1)数据提取
中国美术学院一年级专业分流的重要客观依据便是学生一整年的学习成绩数据,包括各门公共必修课和专业必修课。管理部门根据每个学生所有必修课成绩的加权平均分进行统计排名,由高到低进行专业选择。本系统可根据图4-3 进行设置,界面中 “补考、重修及格后取60 分” 意思为学生若通过补考或者重修及格后,排名时将以总评分60 分记,若仍然不及格将以正考、补考(或重修)中最高成绩记;“平均分小数点位数” 最多为6 位,以降低平均分相同情况;若还是产生平均分相同情况,可选择 “专业必修课” 进行 “总评均分相同时二次排名”。最终,生成年级学年成绩统计排名情况。
由于此次数据分析以历年数据为基础,因此将提取2010级、2011 级和2012 级一年级课程统计排名数据作为分析基础数据。
(2)数据处理
步骤一:将课程成绩转换为加权分
集中了3 个年级一年级的分流数据后,我们将各课程成绩转成加权分。
根据目前的专业分流办法,学生是经过各课程的加权平均分排名后进行,同时各课程成绩经过加权处理后,可以正确体现不同课程对于分流影响因素的大小。
加权公式为:加权分 = 课程成绩 × 课程学分
步骤二:清楚噪点(异类数据)
由于复学后的学生在休学前所修课程可能与正常学生不同,而外国留学生、港澳台留学生存在有部分公共必修课免修,因此将此两类学生数据删除。
步骤三:计算各专业中各课程的平均加权分将历史数据中学生已分配的专业作为样本标签,统计出各专业各课程加权分的平均值后,与各专业评估值合并,作为最终数据分析的样本表。
2. 专业分类
样本数据建立后,将借助MATLAB7.0对其进行聚类实验。 根据不同的λ,获得不同的聚类效果,我们可以得到合理的聚类数为4。
当我们将结果分为2-4 类时,可以看到结果(表1)和(图2)所示。
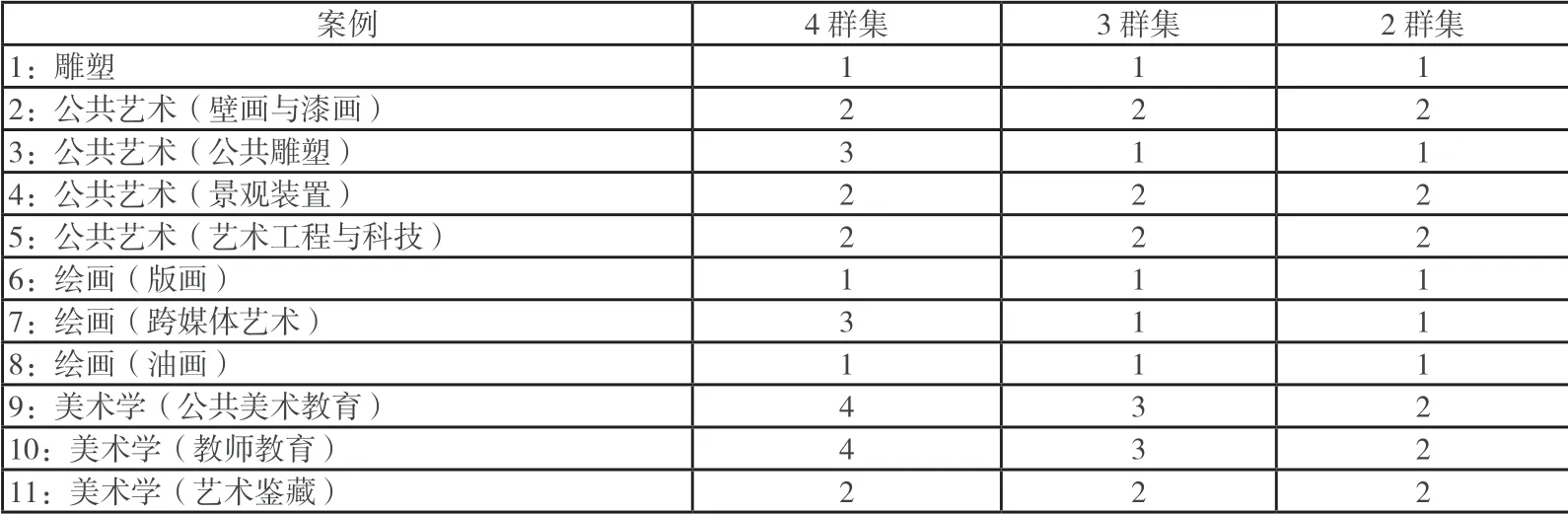
表 1 造型各专业聚类结果表
(1)结果分析
从聚类结果表和树状图中,我们得到以下结果(分成4类):
第一类:雕塑、绘画(版画)、绘画(油画);
第二类:公共艺术(壁画与漆画)、公共艺术(景观装置)、公共艺术(艺术工程与科技)、美术学(艺术鉴藏);
第三类:公共艺术(公共雕塑)、绘画(跨媒体艺术);
第四类:美术学(公共美术教育)、美术学(教师教育)
返观表3,可以看到雕塑、绘画(版画)、绘画(油画)的各门课程加权分都很高,同时教学管理部门对于它们的评估值也是很高的。也就是说此三个专业作为传统的造型类专业在学生中有着崇高的地位,成绩优秀者必然首选这三个专业。二、三类的绘画(跨媒体艺术)等新兴造型专业,也受到了学生一定程度的关注。而处于第四类的美术教育等专业,由于受到就业等因素的影响,未得到学生的充分重视。
可以说此次聚类结果比较符合中国美术学院的事实。
(2)数据模型的实现
在得到专业分类的结果后,要将符合学生条件和想法的那一类专业推荐给他,这就是推荐模块需实现的功能。
在得到专业类别的同时,也得到了各个类别的聚类中心值Vnm,n=4,m=20。
模块根据输入的学生各项指标用欧氏距离公式算出到各类别聚类中心值的距离,以结果最小值作为依据推荐给学生作为填报分流志愿的参考。
同时,模块可提供教学管理部门对于各项指标赋权的输入作为客观权重,对各专业进行重新分类,以实现更为合理的分流结果。
结语
通过实验,我们获得一个关于专业分流较为稳定的数据模型,基本实现了最初的设想。值得注意的是,该模型基于的数据仅是造型艺术类,并没有覆盖所有大类,且每个大类的评价体系和指标不尽相同;倘若需要针对不同大类建立不同数据模型,该模型也只有造型艺术类3 年的数据。可见今后深入研究的范围还很广。
