国内某电厂基于包络分析的煤质掺配模型
2021-01-01孙光玉
孙光玉

摘要:“碳达峰、碳中和”政策下,煤质掺配越来越受到火力发电企业的重视。本文结合电厂历史煤质掺配数据,根据模式匹配和数据包络分析,给出了煤质掺配及采购的优化建议。由于掺配建议是基于历史运行方案的择优选取,因此能很好地满足锅炉系统的安全运行边界条件。实例数据表明,掺配建议对煤质掺配和采购都有很好的指导意义。
关键词:煤质掺配;模式匹配;包络分析
1研究背景
节能是我国的基本国策,是实现二氧化碳大幅下降的最主要途径之一。作为能源消耗和二氧化碳排放的大户,电力行业节能水平直接影响“碳达峰”的进程。据不完全统计,电力行业2015年温室气体排放量占当年全国温室气体排放总量的40%左右。随着环保政策的不断收紧,现存燃煤机组及增量机组均面临十分严峻的挑战。“十四五”时期,是实现新达峰目标和“碳中和”愿景的关键时期,电力发展被赋予新使命,火电节能工作亦被赋予新任务。
通常,火力發电厂降低碳排放主要有两种途径。一是通过技术升级。然而,火力发电技术经过多年的技术发展,已经基本稳定,投入低、效果好、见效快的节能改造已经完成。另一种方法就是利用碳捕集技术。但是碳捕集技术不仅出投资较大,也会大大提高供电煤耗,目前更多的示范阶段,距离商业应用还有很长的距离。
因此,我们从系统运行的角度,提出了利用煤质掺烧的优化管理来实现节能降碳的目标。动力配煤掺烧是一种洁净煤技术,能够在一定程度上解决电厂燃用非设计煤种所带来的污染物超标、炉膛结渣、煤耗增加及水冷壁高温腐蚀等问题,该技术现已在国内电力行业中广泛应用。
包络分析于1978年首次提出并迅速被不断改进修正,现已应用于商业分析等多个领域。本文采用包络分析的方法对每天的煤质掺配进行效率评估,从而得出优化建议方案。包络分析也被大量用于从多角度分析燃煤电厂的效率。
2研究方法
2.1效率评估模型
数据包络分析(Data envelopment analysis,DEA)是运筹学和研究经济生产边界的一种方法。该方法一般被用来测量一些决策部门的生产效率。为了更详细地了解DEA,以下几个基本概念有必要了解一下。
2.1.1决策单元
一个经济系统通常可以看成是一个“公司”,通过投入一定数量的生产要素并产出一定数量的“产品”,尽管这种活动的具体内容各不相同,但其目的都是尽可能地使这一活动取得最大的“效益”。由于从“投入”到“产出”需要经过一系列决策才能实现,或者说,由于“产出”是决策的结果,所以这样的“公司”被称为决策单元(decision making u-nit,DMU)。所以,可以认为,每个决策单元都代表一定的经济意义,它的基本特点是具有一定的输入和输出,并且将输入转化成输出的过程中,努力实现自身的决策目标。
2.1.2生产可能集
我们用X={x,x,…,x}来表示每个决策单元生产过程的投入向量,维度为n,代表有n种类型的投入变量;用Y={y,y…y}来表示每个决策单元生产过程的产出向量,维度为s,代表有s种类型的产出变量。则简写之,我们可以使用(X,Y)来表示DMU的整个生产活动。
定义:集合T=(X,Y)代表投入为X,产出为Y的所有可能的生产活动的集合。
生产可能集最重要的一条性质是:无效性,表述如下:(X,Y)∈T,且X′≥X,则(X′,Y)∈T。
同理,如果(X,Y)∈T,且Y′≤Y,则(X,y′)∈T。
通俗的理解无效性,就是,允许生产中存在浪费现象。
2.1.3有效生产(前沿)
对于生产可能集,(X,Y)∈T,如果不存在Y′≥Y,(X,Y′)∈T,则称(X,Y)为有效生产活动,此投入产出对应一个前沿,由众多“有效生产”构成的凸包即为前沿。
效率评估采用包络分析构建模型。包络分析是一种基于历史数据的分析方法,数据决定了分析结果的准确性。我们针对一个典型的火电厂进行研究,收集了电厂一年的每日生产报表中的数据,将每天的参数数据作为一个决策单元(DMU)。
影响机组效率的因素主要包括劳动力成本、燃料成本、发电量等。由于我们的决策单元为每日数据,所以劳动力成本都是相同的,因此不作为主要研究对象。评价参数主要是每日的燃料量、供电量、及二氧化碳排放量。决策单元( DMU),投入成本为燃料成本及二氧化碳排放量成本,产出为发电量。
CCR模型为:
其中:e—效率;G一发电量,kwh;P—上网电价,元/kwh;Coal—燃煤量,t;PC—煤单价,元/t;C—二氧化碳排放量,吨;Pcb—碳排放量价格,元/吨。此价格=电厂年总碳排放成本/年总排放量。n—煤种类型,r—上网电价类型。
从上式可以看出效率是发电收益与燃料成本与碳排放成本之和的比值。此处考虑了碳排放的成本,将全年的总排放成本根据发电量分摊到每天的碳排放当中。
2.2模型匹配
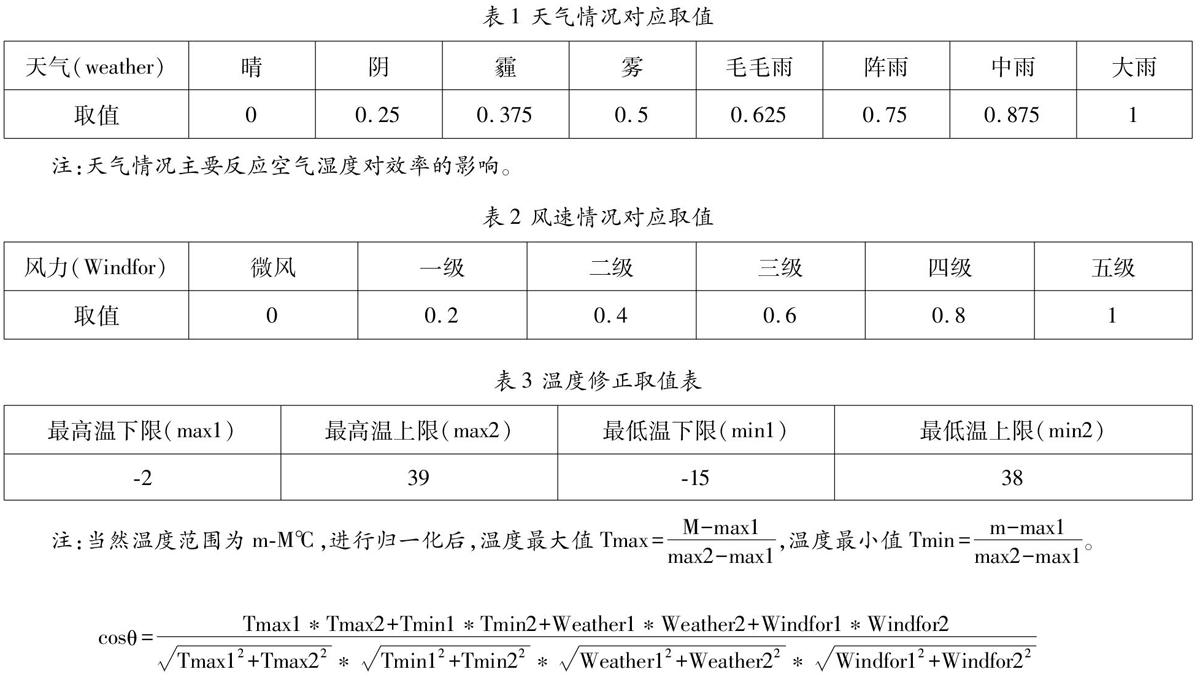
影响发电效率的外部因素主要是气象因素。不同的气象条件下,历史数据中的最优掺配模型可能有所区别。因此需要进行未来天气和历史运行数据的气象参数的匹配,找出历史数据中和未来的气象最接近的部分运行记录,再按效率评估模型选择出效率最优的那一天,将这一天的掺配方案作为最优方案。我们筛选出了可能影响发电效率的主要气象参数:最高温度、最低温度、天气状况、风速。各参数的取值标准如下:
我们可以将每天的历史运行数据参数,看着一个向量。此向量包含效率评估模型需要的参数如煤质掺配方法、发电量、二氧化碳排放量,以及影响发电效率的外部因素,如上述列举的归一化的气象参数。如果需要给出未来某天的煤质掺配方案,则先需要进行天气参数的模式匹配。假设未来需要进行煤质掺配建议的当天的气象参数向量为(Tmax1,Tmin1,Weather1,Windfor1),历史数据中某天的气象参数向量为Tmax2,Tmin2,Weather2,Windfor2),我们通过下式来定义两个向量的相似度:
可设定相似度阈值,当超过某个阈值时,认为这两天的天气数据匹配,这天的煤质掺配历史运行数据都可以作为择优的备选方案,然后根据效率评估模型,选择出效率最优的方法。
2.3应用实例
本实例研究主要基于某电厂的燃煤机组。选取了某台机组一年的运行记录。为了除排负荷率和季节对发电效率的影响。将运行数据按季节和负荷率分别分组。将季节分为3组,分别为春秋季(3月16日—5月30日,9月1日—11月14日)、冬季(11月15日一次年3月15日)、夏季(6月1日—8月31日)。将负荷率分为高负荷(75%及以上)、中负荷(50%~75%)、低负荷(50%及以下)。因此我们将数据供分为9组。在进行模型匹配时,也将严格限定在同一组中。
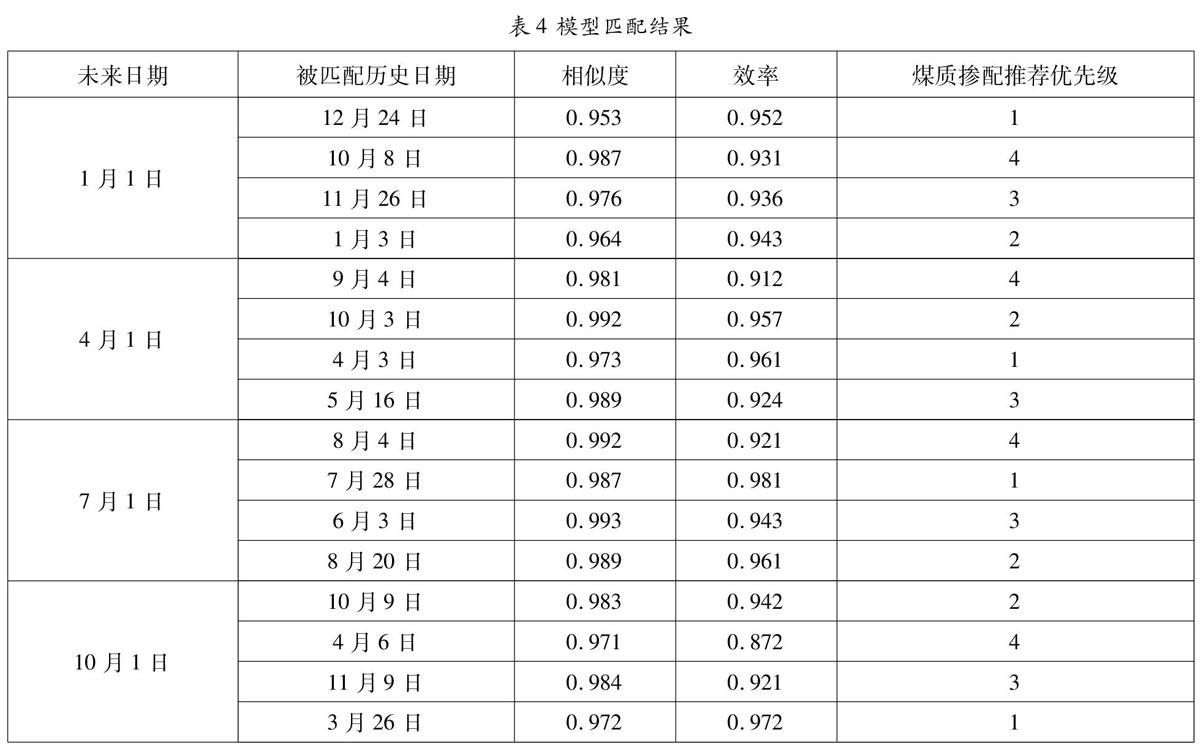
选取的一年的运行数据中,燃烧煤种共30种,掺配方案共70种,能为模型匹配提供充足的数据。煤价范围为510~1050元/吨,平均煤价821元/吨。负荷率变化范围为45%~96%,平均负荷率为72%。我们选择四个典型的日期进行模型匹配和煤质掺配策略推荐,分别为1月1日,4月1日,7月1日,10月1日,结果如下表所示:
模型匹配算法可以迅速筛选出与未来日期天气情况相似的历史运行记录,并能根据效率情况进行排序。理论上基于最高效率的煤质掺配记录将会位于最高的推进优先级。运行人员也可根据实际情况在优先级较高的煤质掺配方案中进行选择。
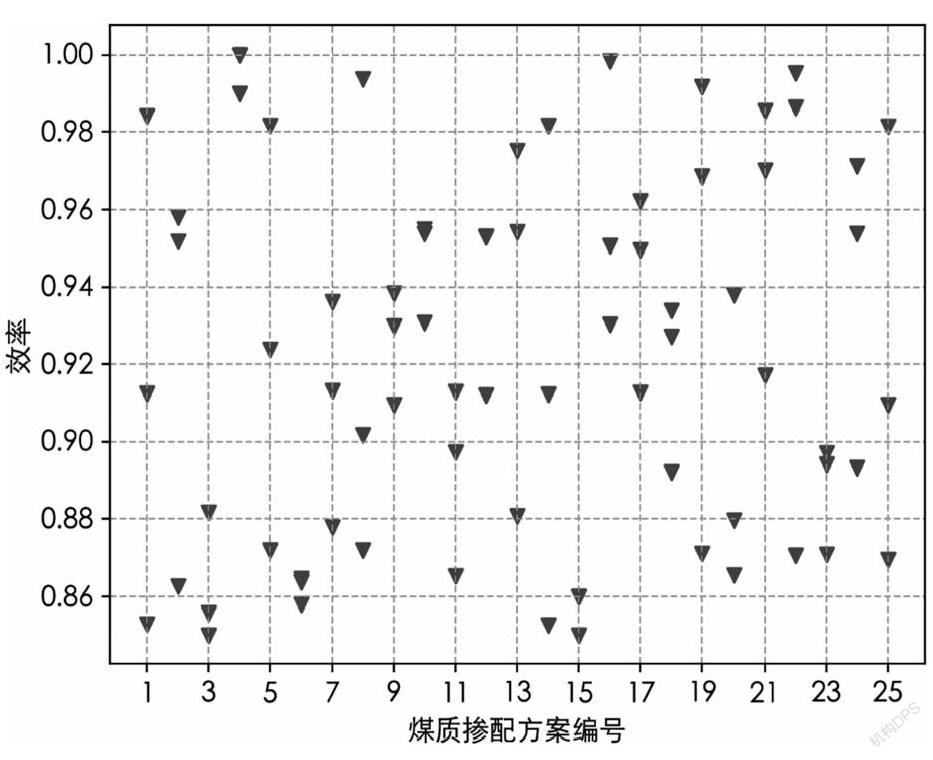
为对比不同煤质掺配下的效率差异情况,下图展示了夏季高负荷(75天)情况下,不同煤质掺配情况每天对应的效率。纵坐标代表效率,横坐标代表煤质掺配编号。
从上图可以看出第4种方案取得了最高的效率,第15种方案取得了最低的效率。第4、16种掺配方案分别在某天取得了最高的效率,这些方案可作为未来优先选择的对象。对于取得较高效率的煤质掺配方案,可统计出其中各煤种出现的频次。可根据此频率比例,制定燃料采购建议。
3总结和后续工作
本文基于包络分析,得出了煤质掺配的优化方案建议,进而也能据此提出燃料采购优化建议。与传统的基于煤质成分组合分析及多目标优化的方法相比,此种方法主要是基于历史掺配方案的择优,更加接近实际工况,对于电廠设备运行没有安全风险。同时,这种方法受燃料管理和运行水平的影响较大。
后期可对效率评估模型进行进一步优化,加入煤质中硫分作为模型参数。同时,还可将结果和多目标优化的结果进行比对验证。
