应用机器学习对集中供热系统进行调节
2020-12-30刘剑
刘剑
晋中市汇同供热技术服务有限公司
机器学习需要大量的供热数据来训练模型,以适应不同时间不同运行人员对供热系统的调节,机器学习可以在大量数据中寻找规律,避免在供热系统中迟豫的发生。为了提高供热系统的水利平衡性,本文将传统供热理论与机器学习结合,用机器学习模块代替传统的人工调节,对每个模型进行数学建模。本文以南海颐园供热单元二网供温预测供热量为机器模型[1]介绍。
1 方法与数据
1.1 数据准备
由于机器学习需要大量的数据,根据不同地方的不同需求,机器学习的模型分为训练模型和预测模型,以晋中市为例,数据的组成为:供热工业组态软件的采暖数据。室外温度的数据,利用python 编程从网上实时爬虫。供热公司客服系统中用户的投诉量。热用户家中的室内温度。由于数据的存储量比较大,数据库可以选择mysql,sqlserver。数据的完整性尽可能保证数据写入数据库的实时性和准确性。
1.2 数据分析
通过对数据库内的数据进行分析,把数据库内与目标值相关性比较强的数据选择出来,比较数据间的相关系数,利用图像展示直观的体现出数据间的相关性,以供热量为例,发现供热量与二网供温相关性比较强。如图1 所示,其中供热量是放大10 倍后的显示。
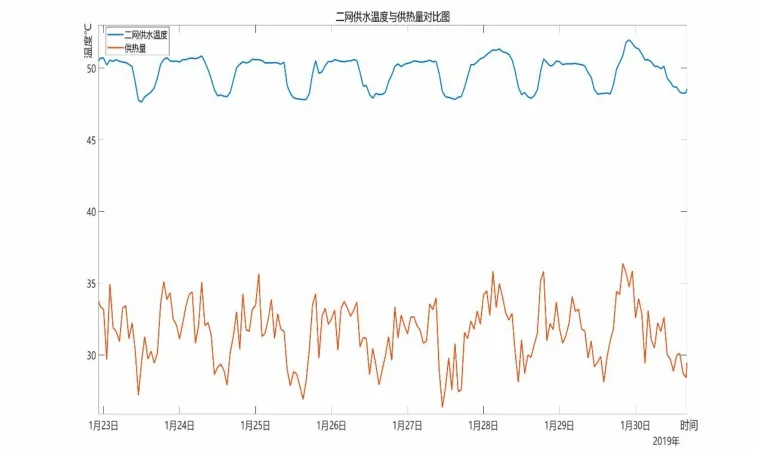
图1 二网供温与供热量相关性对比
1.3 数据整理
在数据库内众多的数据中存在以下几种情况:
1)数据值不符合实际情况。这种情况运用三倍标准差或者可以自定义标准差的值把不符合实际情况的数据值删除掉。
2)数据缺失。由于机器学习特征的选择不同,任意两个特征的数据量必须维度一致,可以通过标准时间轴拼接数据。
3)数据量不够。如果对于模型输入数据量不足的话会直接影响数据的学习能力,所以在训练模型时,可以把时间轴放大,一个采暖季的数据可以扩充到两个采暖季。
2 特征工程
在数据分析中会出现两种情况,特征多余和特征不足。特征多余的情况需要把多余的特征删除,对于特征不足,可以通过多种途径来添加特征,以晋中市为例,在训练模型时发现室外温度,风速,湿度,体感温度和太阳辐射对供热量有很大影响,所以可以利用网络爬虫和购买的方式来增加特征。在特征选取时,发现室外温度对模型的影响很大,所以就需要把室外温度添加进去,如图2 所示。
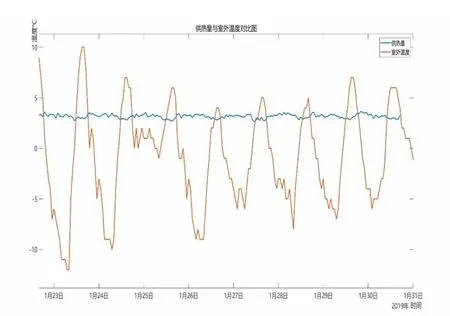
图2 供热量与室外温度的相关性
3 模型建立
以晋中市为例,模型的最终输出为供热量,对于连续值的预测选择标准xgboost 模型[2],也可以通过自定义xgboost 模型来预测供热量,由于对不同的时间段内供热措施不同,在模型的建立过程中根据时间维度可以进行不同程度的惩罚。
4 模型训练
模型的输入是多个特征值,以晋中市为例,模型的输入为,一个采暖季的二网供温和室外温度,模型的输出为供热量[3]。
5 模型评估
模型的评估以RMSE 值为基础,通过交叉验证来验证模型。
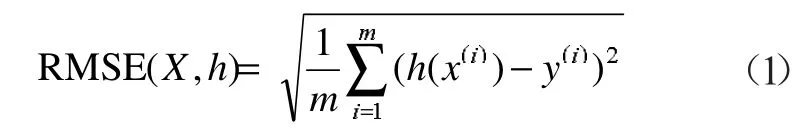
Python 操作代码为:
RMSE:np.sqr(metrics.mean_squared_error(y_origin,y_predict)
RSME 是均方根误差(Root Mean Square Error),是观测值与真值偏差的平方和与观测次数m 比值的平方根。式(1)中,h(x)表示观测者,y 表示真值,m 为观测次数。
RMSE 分数越低说明模型预测得越准确。
6 模型预测
由于供热量的时间粒度为小时,模型的预测为每小时预测一次,根据室外温度的预测维度是24 h,所以供热量预测维度是24 h 的值,如图3 所示。从图像中可以看出,实际值和预测值的拟合度比较高,通过2016-2017,2017-2018 两年的供热数据进行训练值,2018-2019 的供热季作为预测值,由于实际供热情况中现场热量计表的波动误差,会显示数据的不稳定波动,所以预测的供热数据会比实际的供热数据的波动较小。
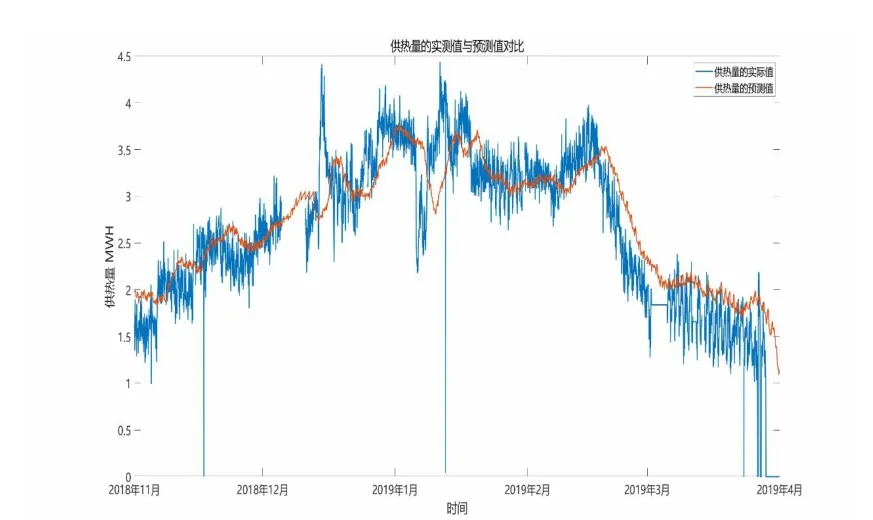
图3 供热量的预测值和实测值对比
7 总结
通过实验得出,机器学习可以根据供热系统的实际数据分析出运行人员的实际操作,并预测出每个供热单元的供热量,有效地减小迟豫的发生。
