姿态估计算法在视频监控中的应用
2020-12-29沈刚袁鹏泰
沈刚 袁鹏泰


摘 要: 为了满足厨房智能监控的需求,保证食品卫生安全,开发了一个基于姿态估计算法的厨房智能监控系统。该系统将深度神经网络与视频监控技术相融合,实现人脸识别以及衣帽识别等功能,采用Openpose姿态估计算法对人体部位进行有效定位,并针对Openpose算法会出现误判人体关键点的问题进行了改进。实验表明,改进后的姿态估算法能够有效地避免误判问题。
关键词: 深度学习; 姿态估计; 目标检测; 视频监控
中图分类号:TP391.41 文献标识码:A 文章编号:1006-8228(2020)12-33-05
Abstract: In order to meet the needs of kitchen intelligent monitoring and ensure food safety, a kitchen intelligent monitoring system using pose estimation algorithm is developed in this paper. The system combines with the deep neural network and video monitoring technologies to realize the functions of face recognition and clothing recognition. The Openpose pose estimation algorithm is used to locate the parts of human body effectively, and the improvement is made to solve the problem that the openpose algorithm may misjudge the key points of human body. Experimental results show that the improved pose estimation algorithm can effectively avoid the misjudgment.
Key words: deep learning; pose estimation; object recognition; video monitoring
1 相关工作
本文将姿态估计算法应用在对厨房的智能监控中,通过监控食堂后厨,以确保食品的健康安全。该系统包含人脸识别、衣帽识别以及物品识别等功能。人脸识别功能需要对人脸进行识别,而衣帽识别功能则需要对人体的头部位置以及身体位置进行识别,这需要算法能够有效的对人体部位进行定位,本文选用了姿态估计算法对人体部位进行定位。
近年来,国内外学者提出了诸多的姿态估计算法。根据算法的结构,姿态估计算法可以划分成自顶向下的姿态估计算法和自底向上的姿态估计算法。
1.1 自顶向下姿态估计算法
自顶向下估计算法的工作原理是首先确定图像中的各个人的位置,之后对各个人的关键点确定,并以此来复原各个人的姿态(即姿态估计)。
Papandreou团队[1]采用这种方式并将其命名为G-RMI,先利用faster-rcnn目标检测算法[2]对图像中的人进行边框检测;然后通过一个全卷积残差网络(fully convolutional resnet)[3-4]预测出每一个检测框内的人的稠密热图(dense heatmap)和偏置(offset),将两者融合以定位出关键点的位置。Shaoli Huang等人[5]提出了一种粗糙-精细化神经网络结构CFN(Coarse-Fine Network),利用多层级监督来实现关键点定位功能;在姿态估计前进行目标检测,会出现边框定位偏差和反复检测等问题,针对此难题,上海交大的卢策吾等[6]提出了RMPE(Regional Multi-Person Pose Estimation)方法,使用空间变换网络(STN)将属于同一个人的不同候选区域都转化成一个比较好的候选区域,如果人体处在候选区域的正中央,那么对于同一个人就不会产生不同的关键点检测结果,此方法采用SSD[7]目标检测算法;何凯明[8]提出的Mask R-CNN网络虽然是用于目标检测的结构,但其泛化能力很强,可以广泛用于多种任务,人体姿态估计就是其中一种应用;Yilun与Chen等人[9]提出了级联金字塔网络CPN,此方法主要结合精炼网络(RefineNet)與全局网络(GlobalNet),其中全局网络的主要工作是对简单的关键点进行检测并提供上下文信息,精炼网络通过对全局网络得到的所有级别的特征进行整合,以便定位较难识别的关键点。
1.2 自底向上姿态估计算法
自底向上姿态估计算法的主要思想是先检测图像中所有关键点,之后,将检测到的关键点做聚类,也就是将关键点和图像中的人进行对应。
InsafutdinovEldar等人的DeepCut[10]和DeeperCut[11]首先利用卷积神经网络进行所有关键点的检测工作并将这些关键点组成一幅图,之后再对图中的这些关键点进行聚类,将关键点的聚类问题转化成了优化问题。Zhe Cao[12]等人提出Openpose算法,包括两个分支协调工作,一个分支利用置信度图预判关键点,而另一个对其关键点的相关性进行预判,最后建立起关键点的图并进行分析;Xia, Fangting等人[13]的Part Segmentation方法,首先拆分人身体的不同位置,然后根据关键点之间的关系完成建模;Newell,Alejandro及其团队[14]提出了一种单阶段关键点检测的方法,把检测关键点和分组一同进行,是一种端到端(end-to-end)的方法;Papandreou,George等人[15]则通过直接回归两个关键点之间的偏差来对这两个关键点之间的关系进行建模,但是这种方法只可以用于两个关键点周围较小范围内的偏差。
2 Openpose姿態估计算法
姿态估计算法中,自底向上结构的算法运行效率不会因图像中的人数而改变,而自顶向下结构算法的运行效率则会随视频中人数的增加而降低,因此我们选择自底向上结构的姿态估计算法。
自底向上的姿态估计的算法有很多种,其中最典型的是Openpose,该方法采用置信度图(confidence map)来检测关键点,利用部分亲和字段(PAF)连接身体关节点。作者使用分支网络结构来同时获取人体的关键点与亲和区域。算法的检测流程为:首先将完整的图像作为输入,通过一个二分支网络同时检测出人体的关节点置信度图和人体部分亲和字段,然后将人体关节点的连接问题转换为一个二部图匹配问题,最后将图像中所有人人体骨骼关键点输出。
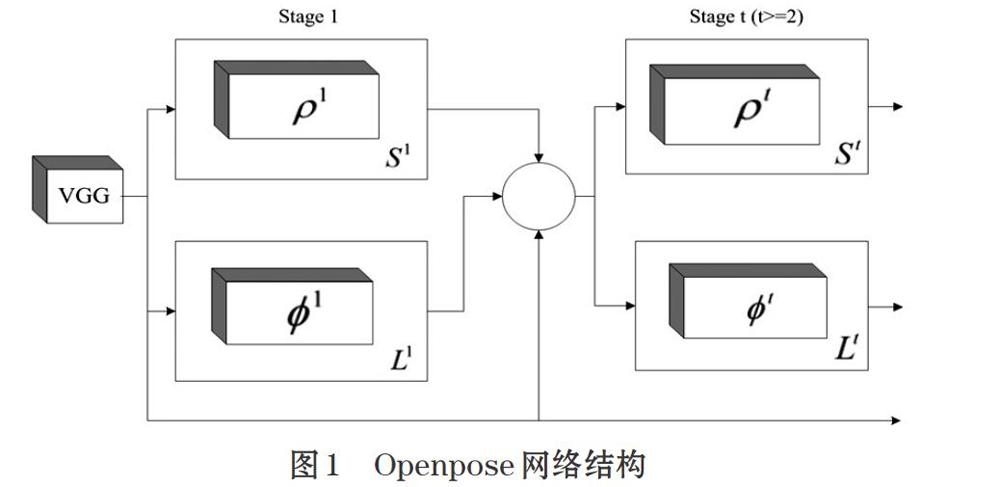
Openpose网络先利用VGGNet[16]对图像进行特征提取,然后把这些特征输入到二分支网格做预测工作。其中一个分支负责预测人体关节点的置信度图,另一个则负责预测人体部分亲和字段。两个分支都设置了迭代级联机制,第一级的输入是VGGNet提取的特征,其后的每一级的输入都是上一级的输出加上第一级的输入。具体实行结构如图1所示。由于输入图像具备固定尺寸,所以很难对细节预测,若将输入图像的尺寸加大又会增加参数的数量,而进行迭代的级联机制可以对前面的预测结果不断的进行精炼,会有力的提升系统对细节的识别度。
图1中上方的分支用于预测人体关键点的置信度图S(confidence map),下方分支的工作是对人体的部分亲和字段[L](PAF)进行预测,[ρ]是置信度图S进行检测的卷积神经网络,[?]的工作是对部分亲和字段[L]进行检测工作的卷积神经网络。
在对Openpose算法进行更加深入的研究过程中,我们也发现了Openpose算法的一个缺陷:Openpose算法有时会在无人存在之处检测出关节点。这就会干扰后续人脸识别和衣帽识别的准确度,为了解决这一问题我们对Openpose算法进行了改进。
3 改进的Openpose姿态估计算法
为解决Openpose算法存在的问题,我们决定在姿态估计前对图像内容进行一个筛选过滤,将确定存在人体的图像传入到Openpose姿态估计算法中。
这样,我们便将改进的Openpose姿态估计算法分成了三个步骤:人体检测、人体区域融合和姿态估计。人体检测是定位出图像中人体所在的位置;人体区域融合是为了将相互靠的较近的人体区域进行融合,由于我们后续采用了一个自底向上的姿态估计算法,因此不需要在图像中精确定位到每一个人的位置,而将人体区域进行融合还能够提高改进的姿态估计算法的识别效率。
3.1 人体检测
本文采用的是自底向上的结构进行人体姿态估计,检测过程中多个人允许共同使用一个检测框,因此人体检测算法的检测效率便成了一个很重要的参考标准,综上选择yolo[17]算法来作为本文的人体检测算法,其具有较高的检测速度和较高的检测精度。
Yolo算法首先把图像缩放至448×448以方便后续处理。随后把缩放的图像分为[S×S]个网格(cell),某个目标的实际中心处于某一个cell上的时候,这个cell就负责对这个目标进行预测。每个cell对B个边界框(bounding box)及其置信度(confidence scores)进行预测,此外,还要预测C个类别的条件概率P。每个边界框都含有5个值,分别是表示位置的[x,y,w,h]和置信度[C],[x,y]为边界框中心相对于网格左上角坐标的偏移值,[w,h]表示边界框的高和宽,这里的置信度指的是预测的边界框和实际的边界框(ground truth)位置IOU值。其中S取7,B取2,C取20。yolo的预测过程如图2所示。
3.2 人体区域融合
通过执行上一步中介绍的人体检测算法,我们已经获得了人体在图像中所处的区域的位置。当预测到的人体检测框偏大时,算法会有较高的容错能力,但当人体检测框偏小而无法截取整个人体时,会影响后续姿态估计的结果,因此,对前一步的人体检测框进行放大,其公式如下:
3.3 实验结果展示
识别结果的对比图展示,图3为改进前姿态估计的结果,图4为改进后的姿态估计结果。我们将两张图中差异的地方用椭圆框标注。从图中可以看出图3中在椭圆标注处存在误检的情况,而图4在对应的位置则没有这一情况出现。由此可见本文提出的改进的Openpose算法有效的解决了这一问题。
4 姿态估计算法在视频监控中的应用
本文所提算法在视频监控中主要用于对人体头部、身体等部位进行定位并将对应部位的图像切割出来,以便其他功能模块做进一步的处理。
利用姿态估算法可以获得图像中人体关键点位置。获得关键点后,以这些关键点为依据进行人体部位的切割。在进行切割时,依据的人体关键点是人体的右耳、左耳、右肩、左肩、右髋和左髋。
我们将人体头部的切割宽度与高度定义如下:
5 结束语
本文对Openpose姿态估计算法进行了改进,通过将人体检测以及人体区域融合算法相结合,解决了Openpose算法在某些情况下在无人区域误检出关键点的问题。之后我们在视频监控系统中使用改进的Openpose算法,并通过改进的Openpose算法获得人体的关键点位置,然后根据关键点的位置对人体的身体部位进行切割,为视频监控的人脸识别模块和衣帽识别模块提供了准确的人体头部和身体部位图像。
参考文献(References):
[1] PAPANDREOU G, ZHU T, KANAZAWA N, et al.Towards Accurate Multi-Person Pose Estimation in the Wild[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii: IEEE,2017:4903-4911
