基于案例库的管制指令偏差识别与匹配方法*
2020-12-29毛继志叶海生汤新民郭鸿滨
毛继志 叶海生,2 吴 磊 汤新民 郭鸿滨
(1. 中国航空无线电电子研究所 上海200241;2. 南京航空航天大学民航学院 南京211100;3. 中国民用航空局空中交通管理局 北京100022)
0 引 言
对于民用航空业来说,航空器的飞行状态是基于管制员发出的管制指令进行调整的,当管制指令偏差出错导致产生飞行冲突时,需要及时采取调整措施。而通过对历史案例进行风险特征挖掘分析,为管制人员做出辅助决策,便具有了重要的研究意义。随着大数据技术的不断发展,航空不安全案例数据量快速增加,如何合理构建案例库并提高案例匹配的准确度将逐渐成为研究热点。
民航领域的不安全事件多是采用航空不安全事故报告的文本记录形式[1-3]、王宏伟[4],吴伋等[5]分别利用关联规则和R语音解决了文本挖掘中无法识别专业生僻术语的问题。且只考虑文本特征词汇并不能系统表示整个事件的风险规律,于是,学者们考虑将风险特征词汇以框架的形式构建成案例库,且案例库的结构和知识需要准确提取整个风险事件的风险规律。陈铭[6]、Gilboa[7]、Ayres[8]、Patterson[9]等都在各自的领域探讨了基于本体、专家先验知识等不同案例库的构建方法;最后,研究重点是如何通过有效的案例匹配算法,准确匹配出与当前风险态势最相似的历史案例。Assali 等[10]在案例检索流程中使用了相似区域概念;Chazara 等[11]提出一种抽象化、推理化的机制来选取源案例;裴艳香[12]以模糊理论为基础,采用最近邻匹配算法计算案例之间的相似度。但以上研究多是集中在如何运用专家经验或基于本体领域知识来构建案例库,未考虑事件本身的潜在风险致因因素,而对于案例匹配也多是考虑基于传统的距离函数去度量案例之间的相似程度,并不能更大程度上保证匹配的效率和精确性。
本文针对管制指令偏差案例识别与匹配问题进行研究,在此基础上,通过文本挖掘从案例本身属性去分析案例特征,以构建风险模式案例库,并提出了基于粗糙集理论的加权欧式距离进行案例相似度匹配,通过模拟案例对该算法进行了对比分析。
1 基于文本挖掘的风险模式案例库构建
本文选取2008—2018 年的航空不安全事件报告,报告中详细记载了不正常事件的起因、经过和结果,并且包含专家对不正常事件的定性分析评价与相应建议措施。以其中管制指令偏差事件作为本文数据挖掘的语料,构建管制指令偏差案例库。
1.1 文本挖掘的风险特征提取
1.1.1 文本分词
文本挖掘需要将文本数据通过向量模型转化为结构化的数值数据,即由词汇或短语组成的向量,通过对文本语料进行分词处理之前,需要将语料进行规范化处理,剔除掉冗余词汇(如:虚词,标点符号,英文字符等)。本文利用Pyhton平台的jieba分词工具[13],可以有效的过滤掉这些冗余词汇,为防止专业领域词汇被切分,再向jieba 分词包中导入民航领域词典,如:民航业词库、民航飞行系统词库等,有效保证了民航领域专业词汇切分的准确性。
1.1.2 基于概念模型的文本特征提取
文本特征提取的方法通常是采用TF-IDF算法[14],其算法原理如下。
TF(词频)的具体公式为

式中:k 为关键字;n 为某文档的总词数,nk为该文档内关键字k 出现的次数;TF 为关键字在某文档内出现的次数,与该文档总词数之间的比值。
IDF(逆向文件词频)的计算公式为

式中:N 为所有处理文档的数目;Nk为含有关键词k 的文档数目。
最后TF - IDF 这一评估值等于TF 和IDF 的乘积,为
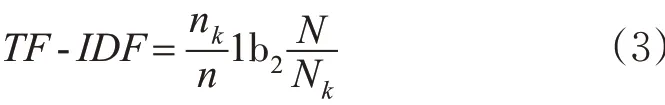
笔者在处理分词结果的过程中发现,由于文本报告语料并没有统一、规范的记载格式,出现大量词汇不同但词义相同或相近的情况,仅仅通过构建向量模型去提取文本特征,会导致特征词汇冗杂,向量维度过大。因此,考虑将概念模型引入到文本向量模型中,即通过构建民航领域概念词典[14],将语料库中表达含义相近的词汇放在同一概念形式下,这样可以使特征词汇更准确,区别度更大,减少冗余特征的出现,见表1和表2。

表1 部分民航领域概念词典Tab. 1 Someconcept dictionaries in the fieldofCivilAviation
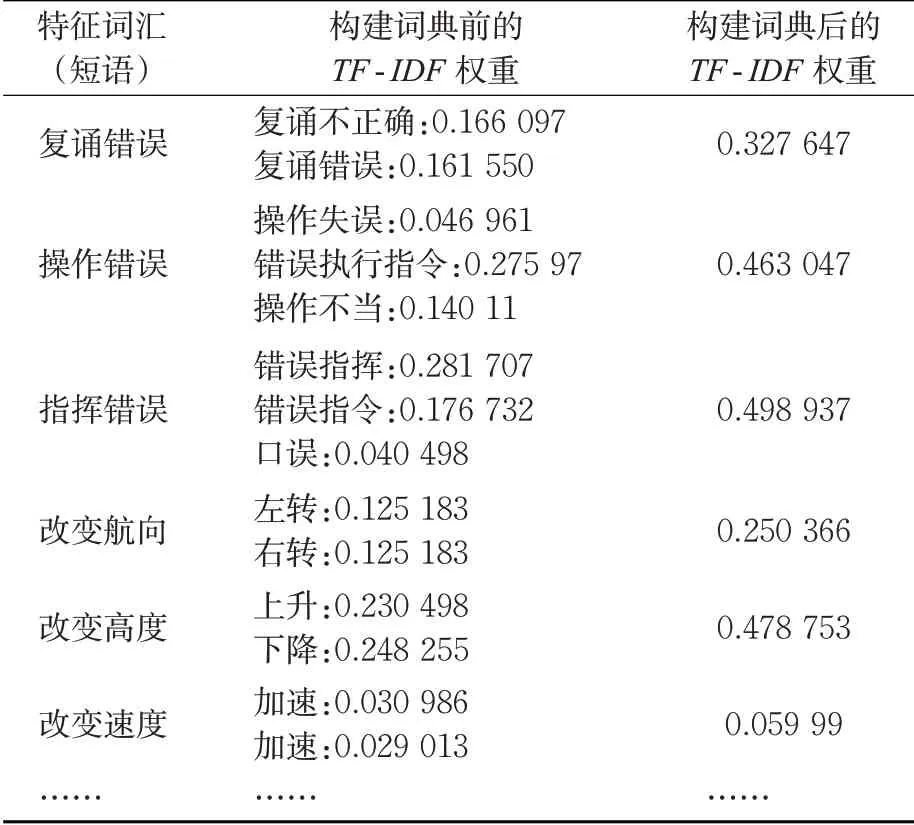
表2 构建概念词典前后的部分特征词汇权重对比Tab. 2 Comparison of the weight of some feature words before and after the construction of concept dictionary
1.2 风险特征属性值分析
1.2.1 确定数值型风险特征属性
将文本挖掘出来的特征词汇或短语放在同1个风险属性集下。其中,出现的某些风险属性是由确定的特征子属性值组成,也即1个风险事件的发生,是由其包含的子属性集的1种或多种共同组成,见表3。

表3 确定数值型特征属性Tab. 3 Determination of numerical characteristic attributes
1.2.2 模糊数值型风险特征属性
对于某些特征属性难以用确定的值去进行度量,或用确定的值度量对案例推理并不能起到有效的帮助,如:风险发生时间段和发生地点。发生地点,在案例中多以“航路交叉点附近”或“扇区移交点附近”这样含义模糊的词汇所描述;而风险发生时间,在某一时间点的描述并不具有规律特征,因此,通过构建隶属函数,用隶属度来近似表示案例的地点、时间的模糊特征。
隶属函数的定义。给定论域U 上的1个模糊子集A 是指:对于任意的u ∈U,都指定1 个数μA(u)∈[0,1],叫做u 对A 的隶属函数或隶属度[15-16]。
对于风险发生地点,将案例里出现的“管制移交点”等点定义为中心点,设到中心点的距离为d ,最大距离为dmax=100 km,超过dmax,则认为隶属度为0;事故发生地点距离中心点越近,那么隶属度越接近1,而当距离为0~100 km 之间,其隶属度符合高斯分布,见图1。
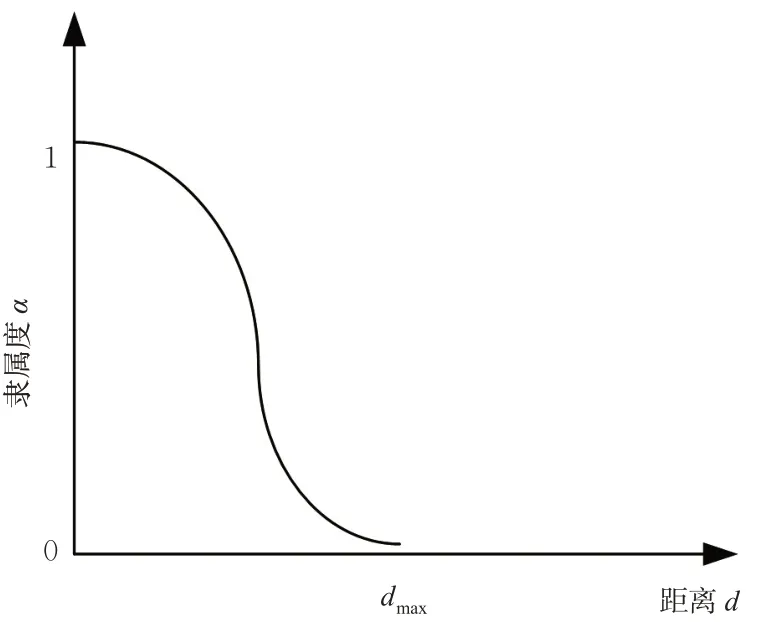
图1 距中心点距离的隶属度函数Fig. 1 Membership function of distance from center
最终得到距离的隶属函数为
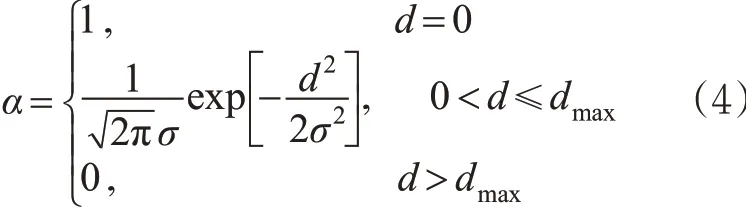
式中:σ 的取值由3σ 准则确定。
根据航空事故发生时间规律分布,可将时间段划分为:高峰期、平峰期和低谷期。其中高峰期时段为11:00—13:00,15:00—17:00;平峰期时段为7:00—11:00,13:00—15:00,17:00—21:00;低谷期时段为00:00—07:00,21:00—24:00。定义每个时间区段为[tmin,tmax] ,当t ∈[tmin,tmax] ,其隶属度也遵循高斯分布,见图2。
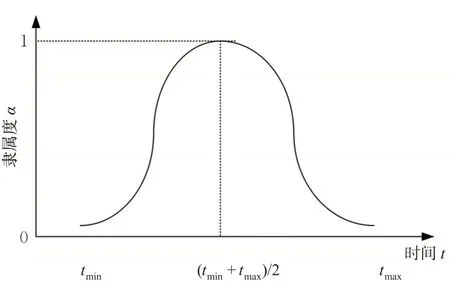
图2 风险时间区段的隶属度函数Fig. 2 Membership function of risk time section
当t <tmin,t >tmax时,其隶属度为0,最终得到时间的隶属度函数为
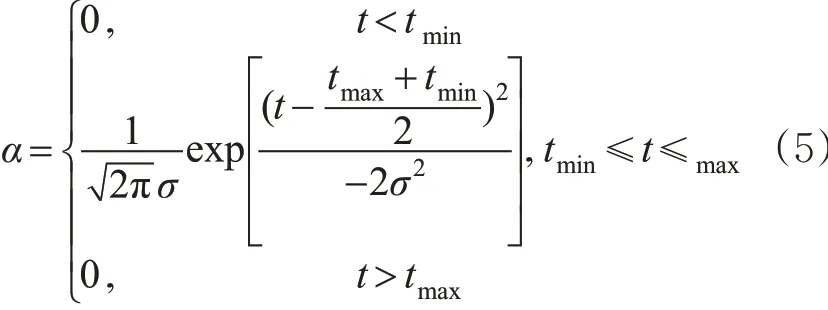
式中:σ 的取值由3σ 准则确定,见表4。

表4 模糊数值型特征属性Tab. 4 Fuzzy numerical characteristic attributes
1.2.3 风险模式案例库的框架表示
1个案例框架由若干个槽值表示,各槽值由若干侧面来表达,侧面值是个侧面的具体赋值[17]。对于本文来说,槽值就是各属性特征值,不安全案例以固定的结构被详细的表示出来。下面是框架表示案例的1个简例。
槽1:标识属性。
<事件案例编号X >:X11
槽2:风险偏差条件属性。
<风险发生地点C1>:航路交叉点附近,0.9
<风险发生时间C2>:高峰期,0.6
<环境因素C3>:危险气象
<人为因素偏差C4>: 管制员指令错误
<风险指令模式C5>:高度改变指令
<航空器运行模式C6>:爬升—下降
<持续时间C7>:157
槽3:风险决策属性。
<事件类型V1>:小于规定垂直间隔
因此,案例库的任一案例可以用这样的框架槽值表示,再转化为向量形式,为
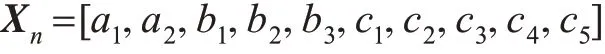
式中:(a1,a2) 和(b1,b2,b3) 分别为风险发生时间和地点的3个子属性值的隶属度大小;(c1,c2,c3,c4,c5) 为确定数值型的特征属性值。
2 管制指令模式的偏差识别
管制指令模式主要分为3类:高度改变指令、航向改变指令,以及速度改变指令。通过分析实时态势的管制指令模式,结合航空器的运动方程,对航空器轨迹进行偏差识别,当轨迹偏差导致航空器之间小于规定间隔飞行,便认定产生飞行冲突。
2.1 高度偏差识别
当管制员对航空器1 下达改变高度偏差指令后,计算航空器1 飞越到航空器2 所在高度层时间,记为偏差持续时间T 。则有
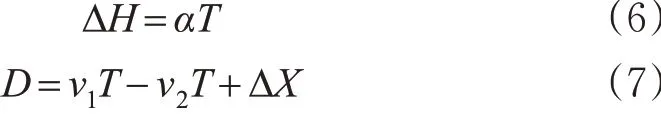
式中:ΔH 为航空器1 和2 之间的高度差;α 为爬升率;v1,v2分别为航空器1和2的速度;D 为到达航空器2高度差的1和2的间隔;ΔX 为起始水平间隔。
判断航空器1与航空器2在时间T 后是否小于规定间隔ΔD ,若是,则认定该指令是高度指令偏差,见图3。
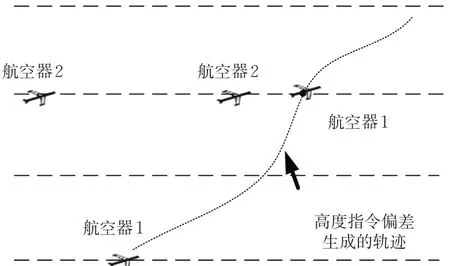
图3 高度指令偏差导致的航迹冲突Fig. 3 Track conflict caused by altitude command deviation
2.2 航向指令偏差识别
当管制员对航空器1 下达航向改变指令后,计算航空器1接近航空器2,直至刚好小于规定水平间隔ΔD 的时间,记为T 。设转向角为θ ,则有
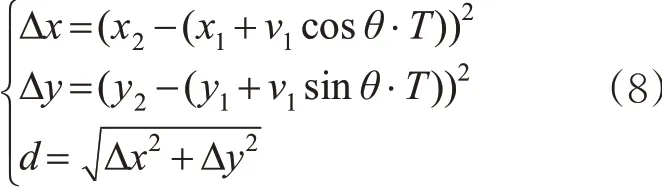
若该方程有解,计算时间T ,则认定该指令是航向指令偏差。见图4。
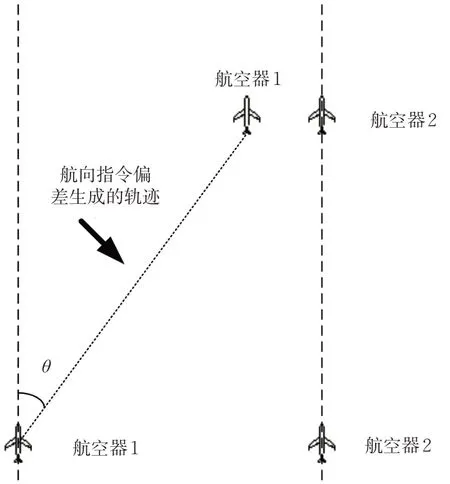
图4 航向指令偏差导致的航迹冲突Fig. 4 Track conflict caused by heading command deviation
2.3 速度偏差识别
当管制员对航空器1 下达加速指令(或对航空器2下达减速指令)时,会造成后机速度大于前机速度,当航空器1和2之间的水平间隔小于规定水平间隔ΔD 时,便会形成飞行冲突。
管制指令中,管制员发出的指令一般为“加(减)速到XXX”,本文考虑以航空器的从速度v1变化到v2的时间为T ,加速度a 取航空器的平均加速度。则有
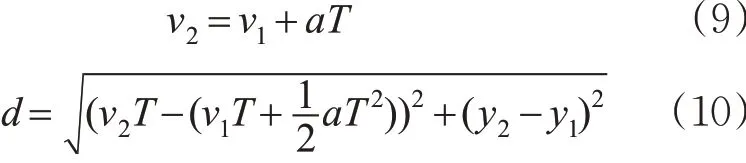
若该方程有解,计算时间T ,则认定该指令是速度指令偏差。见图5。
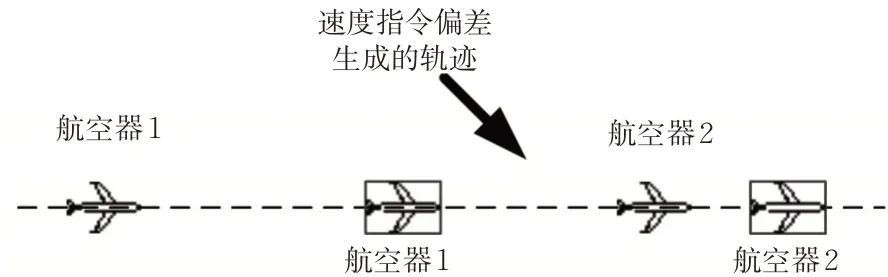
图5 速度指令偏差导致的航迹冲突Fig. 5 Track conflict caused by speed command deviation
3 指令偏差历史相似案例匹配
3.1 基于欧式距离的传统相似匹配算法
3.1.1 欧式距离相似度计算
案例的相似度即案例之间相似程度的数值度量,而案例库作为1个多维数据空间向量结构,欧氏距离是测量2个向量空间距离的1种方法,向量空间距离越小,案例相似度越高。传统的欧式距离计算方法如下。
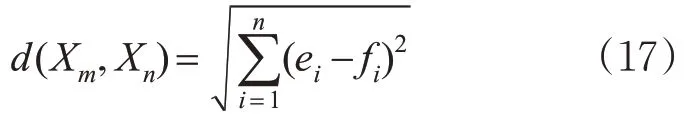
式中:Xm,Xn为2 个不同风险案例;ei,fi分别为Xm,Xn的第i 个风险属性值,且有i = 1,2,…,n 。
3.1.2 弊端分析
传统的欧式距离标准将每个维度的向量放在同一个距离量纲下进行计算,并没有考虑每个案例属性之间差异的影响,而对于文本案例来说,特征属性差异大,指标衡量标准也不相同,若不对属性进行差异化分析,便达不到案例区分的作用。
因此,需要考虑每个属性对案例的贡献权重,对每个属性的贡献赋权来修改公式,由于案例中的属性类型和量纲都不同,且属性权重的计算不宜采用专家打分等类似的主观评价方法,而是基于案例本身所包含的信息量来确定属性权重的一种客观赋权方法。案例特征属性权重大小直接影响案例相似度的计算结果,需要选择一个好的权重计算方法,以提高案例匹配的准确性。
3.2 基于粗糙集理论的加权欧式距离算法
针对指令偏差案例属性差异大导致属性权重无法确定的问题,本文提出基于粗糙集理论的加权欧式距离算法,粗糙集不需要任何先验知识,就能够挖掘出数据中隐藏的规律,利用粗糙集可以比较客观地确定案例特征属性的权重。该算法主要分为2个步骤。
步骤1。基于粗糙集理论的属性权重计算。对于整个管制语音指令偏差知识系统,给定K =(U,R),对每个子集X ⊆U 和等价关系R[18],定义
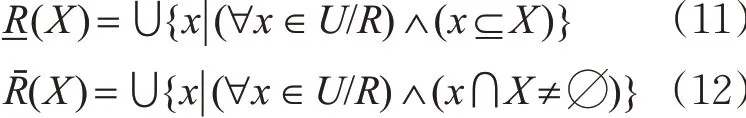
分别称它们为X 的下近似和上近似。其中posR(X)=-R(X),称为X 的R 正域。
在给定的信息系统中,属性集所确定的等价关系是唯一的,所以经常用属性集来表示其对应的等价关系。

步骤2。加权欧式距离相似性度量。由于各特征属性的度量单位不一致,因此在用计算特征权重之前,需要首先对原始数据进行归一化处理,即把指标的绝对值相对化,从而使所有特征向量具在同一长度上进行比较。案例库中的数据都是正向数据,因此本文采用min-max标准化。
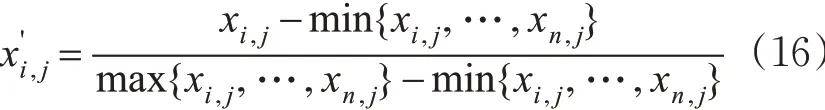
则x'i,j为第i 个案例的第j 个特征属性的数值(i = 1,2,…,n; j = 1,2,…,m)。
假 设 有 2 个 案 例 Xm=(e1,e2,…,en) 和Xn=( f1,f2,…,fn),则有
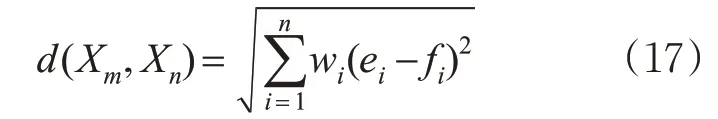
式中:n 为维数,也即特征属性个数;ei和fi分别为Xm和Xn第i 个属性值;ωi为每个特征属性的权重,
3.3 算法分析
3.3.1 算法对比
对2 种算法进行对比,本质区别在于是否考虑案例属性的权重大小。基于粗糙集的相似度匹配会优先匹配权重大的特征属性,而传统相似度匹配则不会考虑匹配的优先性。
下面结合真实案例来对比分析改进前后的案例属性权重大小。选择2008—2018 年发生的75 组历史管制指令偏差事件作为实验案例库,2018 年上半年发生的5组作为测试案例,将这2组案例同时进行属性归一化处理,最后得到的案例特征向量,具体见表5和表6。
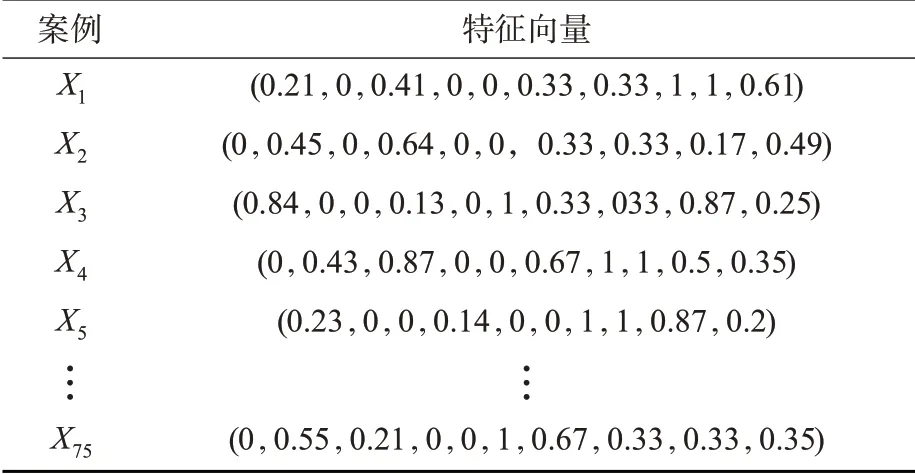
表5 实验案例库的特征向量表示Tab. 5 Feature vector representation of experimental case base
利用粗糙集公式计算得到每个特征属性的权重,结果见表7。
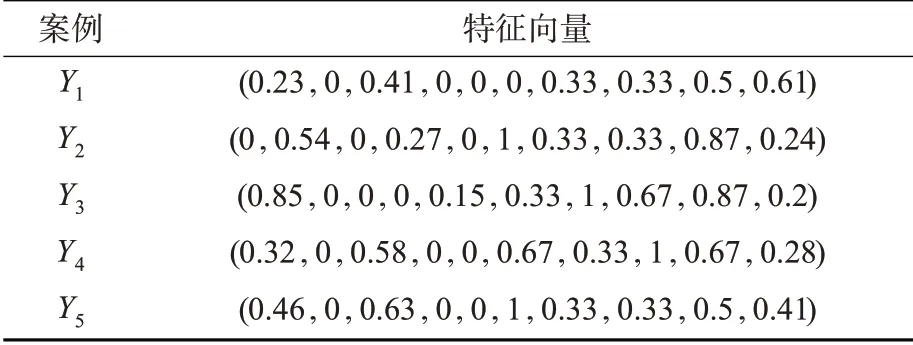
表6 测试案例的特征向量表示Tab. 6 Eigenvector representation of test cases

表7 风险特征属性的权重大小Tab. 7 Weight of risk characteristic attributes
从表7 可以看出,C4,C5表示的人为属性偏差和风险指令模式的权重最大;其次是航空器运行模式和偏差持续时间;而风险地点和时间,环境因素的权重最低。结合实际案例来看,人为属性、风险指令、模式航空器运行模式和偏差持续时间决定整个案例的风险类型及风险过程,是关键风险特征,而风险地点和时间等并不能直接导致风险事件发生,因此属性重要度较低。
而对比传统相似匹配算法,则没有考虑属性差异性,因此每个特征属性权重均为1/7,这样便不能体现属性匹配的优先性。
3.3.2 效果分析
分别利用传统欧式距离和基于粗糙集理论的加权欧式距离对匹配案例与实验案例库进行相似度匹配,最后得到匹配结果,具体见表8和表9。
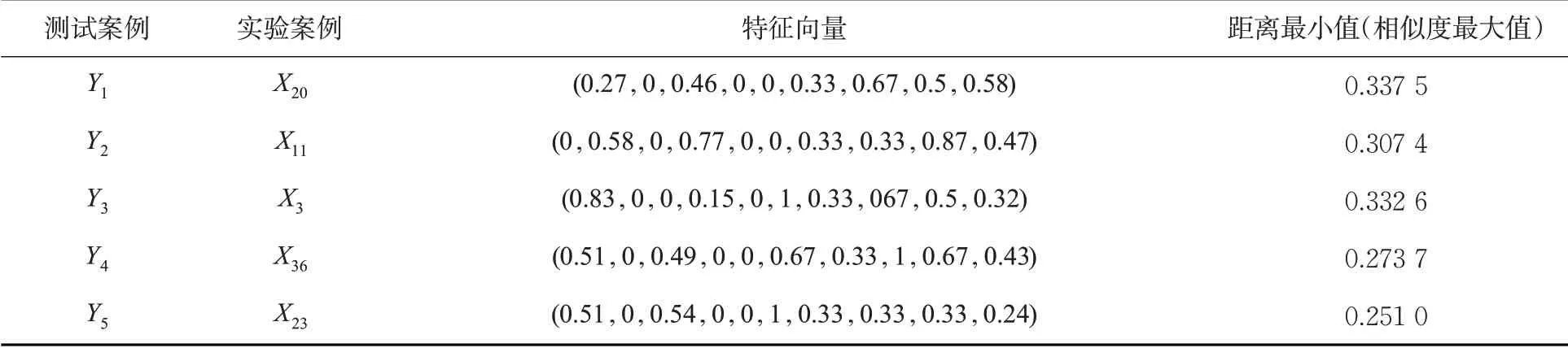
表8 基于传统欧式距离的相似度案例匹配结果Tab. 8 Similarity case matching results based on traditional Euclidean distance
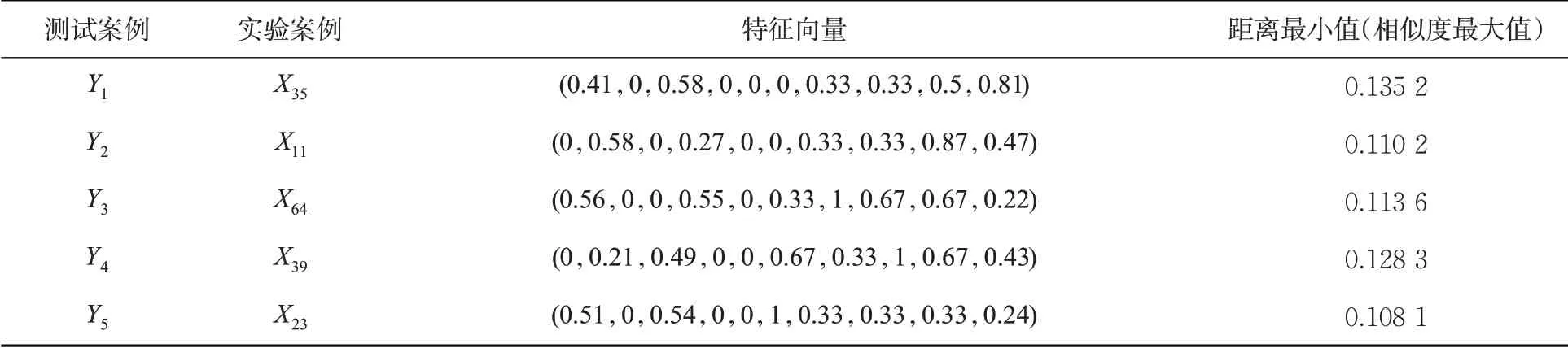
表9 基于粗糙集理论的加权欧式距离的相似度案例匹配结果Tab. 9 Similarity case matching results of weighted Euclidean distance based on Rough Set Theory
从匹配的特征属性来看,由于传统相似匹配算法并没有考虑实际案例属性的差异化,从表9 的测试案例Y1和Y3匹配结果来看,对于特征属性C5即风险指令模式,前者都为高度改变模式,后者为航向改变模式,因此,2个案例风险致因因素就不相同,前者为穿越高度层造成的偏差,后者为改变航向造成的偏差;而基于粗糙集理论的加权欧式距离则是优先匹配权重大的特征属性(即关键风险特征),从表9的匹配结果来看,则不会出现这种情况。
从匹配的距离大小(即相似程度)来看,基于传统欧式距离的范围在0.2~0.4 之间,导致案例相似度匹配程度不高,这也增加了匹配到错误案例的概率;而表9 基于改进后的方法则将范围缩小到0.1~0.2,案例相似度匹配程度提高,匹配准确度也随之提高。
3.4 案例仿真
选取发生在“2019年2月20日,浙江空管分局由于管制员指挥不当而造成的指令偏差事件”。
首先,通过研究实时管制员语音指令来判断出指令的偏差模式及预期偏差持续时间,实际陆空对话录音内容的文本报告,见表10。
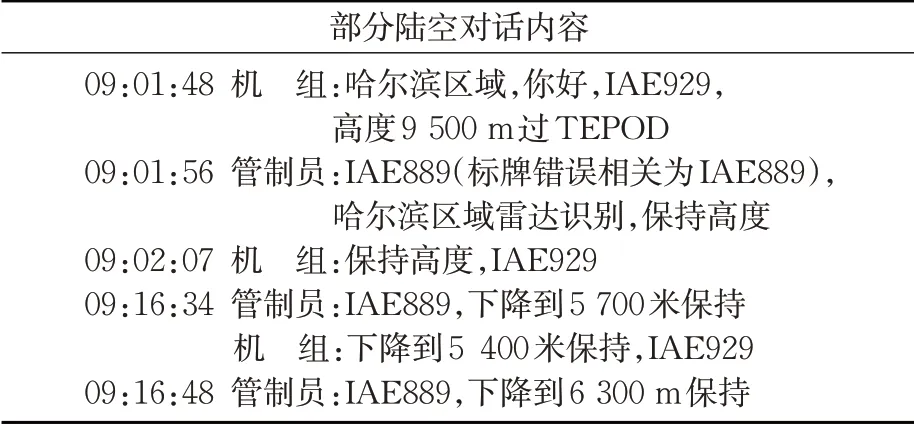
表10 陆空对话录音文本报告Tab. 10 Text report of land air communication recording
通过识别对话内容,可以判断该指令为高度改变指令,且航空器的运行模式处于下降状态。接下来,判断航空器在该指令下可能会产生的偏差。
图6是2航空器在指令刚发出所处的位置,从对话可以分析出高度改变量为3 200 m(从9 500 m下降到6 300 m),航空器的下降率为600 m/min,代入式(6),判断预期偏差持续时间为320 s。
对于事故发生地点和时段,结合隶属度计算公式可分别得到,该目标案例Y0的特征属性值,见表11。

表11 目标案例X0 的特征属性值Tab. 11 Characteristic attribute values of target case X0
对目标案例的特征属性值进行归一化处理后,Y0的特征向量可表示为
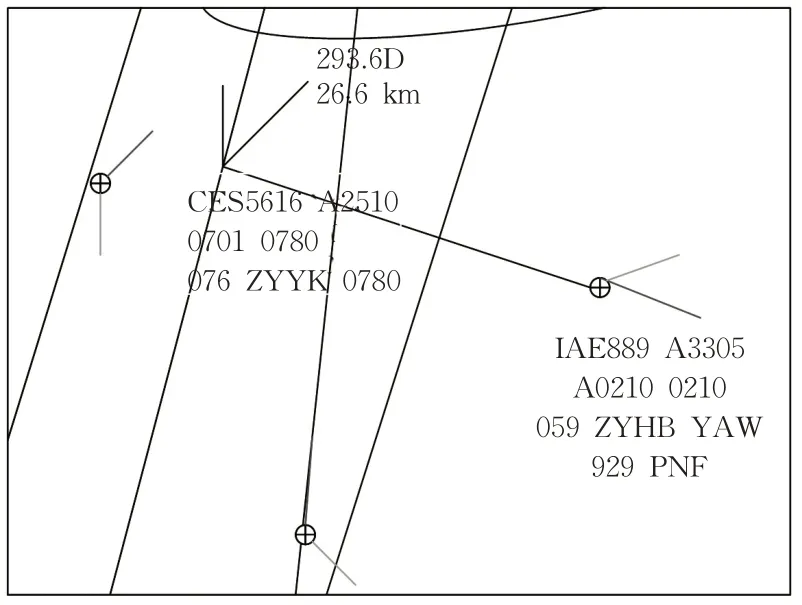
图6 航空器雷达定位截图Fig. 6 Screenshot of aircraft radar positioning
Y0=(0,0.71,0,0.94,0,0,0.33,0.33,0.83,0.88)
利用基于粗糙集权重的加权欧式距离进行案例匹配,最终得到的最相似案例,具体见表12。

表12 基于粗糙集权重的加权欧式距离匹配结果Tab. 12 Weighted Euclidean distance matching results based on rough set weight
案例X21的特征描述如下C1:发生地点为管制移交点附近(成都南扇与重庆区调的管制移交区域之间);C2:发生时间为平峰期(上午10:30 左右);C3:0(无恶劣气象或军事活动等环境影响);C4:管制员指挥失误(管制员让航空器下降7 800 m 保持);C5:改变高度(离开10 800 m、下降7 800 m保持);C6:2 航空器的飞行模式:下降—平飞;C7:偏差持续时间:301 s(上午10:30—10:35)。
通过分析可以看出:基于改进后的方法可以将人为因素偏差,指令改变模式以及航空器运行状态等关键特征完全匹配,且偏差持续时间的值也很接近,因此2 个案例都是由于管制员错误指挥下降高度,导致其穿越高度层与另1 架平飞的航空器因为纵向间隔不足产生的飞行冲突,也进一步验证了该算法的准确性。
4 结束语
依据文本挖掘算法提取历史案例的风险特征,构建出了风险模式案例库;通过管制指令模式对实时态势的偏差进行识别并提取出特征属性,提出了基于粗糙集理论的加权欧氏距离匹配算法,并与传统相似匹配算法进行对比分析,验证了前者对于属性差异化的案例匹配更加准确。最后通过案例仿真验证了笔者采用的方法可以准确区分案例的关键风险特征,并缩小案例间的距离,从而提高案例匹配的准确性,且对于属性差异化大的案例尤为适用。未来可进一步研究对实时指令的偏差识别改进算法,对航空器轨迹状态进行更准确的识别来提高实时案例的文本表征识别度。
