融合多层相似度与信任机制的协同过滤算法
2020-12-28郑小楠
孔 麟,黄 俊,马 浩,郑小楠
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
协同过滤算法作为当前大数据背景下处理“信息过载”的有效技术手段,使其成为当下使用最为广泛的推荐技术之一[1]。但随着研究的深入,发现传统的协同过滤算法仍存在较多有待改进的问题[2]。数据稀疏性问题作为最显著的问题之一,为此,众多专家学者提出了许多算法改进的方法,文献[3,4]引入相关性权重系数提升了算法有效性;文献[5]将Jaccard相似性系数结合评分修正公式减少了项目非相关性的影响;文献[6,7]提出通过挖掘评分用户之间潜在关系,使得推荐结果更加可靠;文献[8]引入了项目相关性系数,根据项目类型和评分计算用户相似度;文献[9]在计算用户偏好时,在评分相似度的基础上引入时间权重函数;文献[10]通过综合分析用户历史行为和物品标签信息,实现了在不依赖用户项目评分的基础上对标签概率进行推荐;文献[11]利用置信度函数将用户隐性反馈映射为置信概率,基于随机梯度下降提出了异构置信度优化算法。以上算法虽然对算法的有效性做了一定的优化,但存在数据稀疏性情况下算法准确度仍有待提高、用户相似度衡量因素较为简单以及用户之间潜在关系挖掘不够深入等问题。针对以上问题,本文提出了融合多层相似度与信任机制的协同过滤算法。
1 相关定义
传统协同过滤算法利用相似度大小的计算,构建出与目标用户最为相似的邻居集合,并根据邻居集合产生推荐结果,其算法流程如下:
(1)首先分析用户的历史评分数据,生成项目-评分矩阵Rm×n,记录了m个用户对n个物品所产生过的历史评分数据。其中的Ric,代表用户i对物品c的评分,对未有过历史评分的项目记为0
(1)
(2)利用用户间的历史评分信息计算这n个用户中两两用户之间的相似度,并将用户之间相似度计算结果按由大到小顺序排列,取出前k个相似度最高的用户组成邻居集合。传统协同过滤算法的公式如下
(2)
(3)
(4)
其中,sim(i,j)cos表示余弦相似度,sim(i,j)Adcos表示修正余弦相似度,sim(i,j)Pcc表示皮尔逊相似度。关于上述传统协同过滤算法的定义请参见文献[6]。
(3)根据求得的邻居集合,计算得到目标用户的项目预测评分
(5)
式中:Pi,c表示目标用户i对项目c的预测评分,j表示邻居集合中的任意用户。
2 本文的算法
2.1 修正评分相似度
在推荐系统中,项目的评分在一定程度上反映了用户对该项目的偏好度,此时偏好度的衡量由用户评分值决定,但评分形式并不能准确表现用户的喜爱程度。例如,某电影评分为5分制,假设用户i给出的评分为4分,此时用户对于电影的偏好程度就不能以数值形式准确地量化,只能粗略地预测用户i喜欢该电影的概率较高。为解决此情况下偏好程度的度量问题,本文采用模糊逻辑法[12],对单一数值评分进行数值丰富化处理,从而得到用户偏好度的数值量化。
定义1 设U是一个论域,给定一个映射关系:μA:U→[0,1],x→μA(x)∈[0,1],其中,映射μA称为模糊集A的隶属函数,μA表示x对模糊集A的隶属度。根据以上定义,评分三角模糊集隶属函数定义如图1所示。

图1 评分三角模糊集隶属函数
(6)
μbad(x)=(5-x)/4; 1≤x≤5
(7)
例如,对某5分制的电影,某用户对该电影的评分为4分,利用式(6)、式(7)对评分数据进行丰富化处理,得到该用户对该项目的模糊偏好度为(0.75,0.25),其中,0.75和0.25分别表示用户对项目喜好程度和不喜好程度的数值量化,其计算过程如下
μgood=(4-1)/4=0.75
(8)
μbad=(5-4)/4=0.25
(9)
任意两个用户之间偏好差异度的计算依赖于二者对于共同评分项目的评分差异,评分差异越大,则说明他们之间所存在的偏好差异程度也越大,偏好差异度可通过式(6)、式(7)计算得到。基于此推论,对于任意两个用户采用公共项目计算得到的偏好相似度用Ps(i,j)来表示,可由式(10)~式(12)计算得到
(10)
(11)

(12)

在对用户评分相似度sim(i,j)a的计算时,将引入模糊映射关系修正后的用户偏好与修正评分Jaccard相似度[5]结合,以平衡用户对项目量纲和用户间公共评分项目占比关系,最后基于用户修正余弦相似度,计算出用户的评分相似度
sima(i,j) =sim(i,j)Adcos×Ps(i,j)×Jaccard
(13)
Jaccard=|Ii∩Ij|/|Ii∪Ij|
(14)
其中,Ii和Ij表示用户i和j的评分项目集合。
2.2 用户兴趣相似度
传统的协同过滤算法只考虑了用户的项目评分值,忽略了对用户针对不同项目类型的兴趣相似度,而往往用户的兴趣相似度在很大程度上影响了项目的推荐精度。在数据较为稀疏的情况下,用户之间公共评分项较少,甚至为零,此时,基于项目类型所评估的用户兴趣相似度即可很大程度上弥补数据稀疏带来的影响。
用户的兴趣度计算受到不同项目类型评分值以及数量占比关系的影响。例如,通过分析计算某用户的电影观看历史记录,得知该用户对喜剧和爱情类的电影感兴趣,那么当出现某部相关类型的电影时,则可以推测该用户有较大可能性喜欢这部电影。基于以上推论,对用户兴趣向量interesti,j的定义为:用户对不同类型项目的偏好程度,兴趣向量的组成包括各个项目类型的评分值的占比和评分数量的占比
(15)
(16)
其中,avgi(t)表示某类型项目的评分均值,Ri,c表示对某类型项目的评分,It表示对该类项目评分次数,T表示所有类型项目的集合,Nt表示t类型项目的评分统计次数,N表示所有评分的数量,α表示兴趣权重。
例如,根据以上公式分析计算某用户的历史评分记录,对计算得到的兴趣向量进行归一化处理,得到用户对动作、冒险、爱情、科幻类等电影的兴趣权重占比为25%、20%、15%、13%……,由此可以看出,该用户对动作类和冒险类电影比较偏爱。同时,利用用户的兴趣向量结合余弦相似度计算公式,对于任意两个用户i、j而言,可以计算得到用户兴趣相似度
(17)
式中:T表示所有项目类型的集合。
2.3 用户混合相似度
综上所述,将二者所得到的相似度进行融合,得到用户混合相似度。考虑到两种相似度的计算受到数据稀疏性影响的程度不同:在公共评分数量较少时,评分尺度的度量易受评分峰值的影响,导致计算结果存在较大误差,相对而言,基于项目类型得到的兴趣相似度受评分峰值影响较小,故此时应提高后者权重;当公共评分项数量较多时,基于用户评分计算得到的推荐结果精度更高,故此时应增大评分相似度占比。故而通过设定公共评分数量阀值d1,根据d1大小调整二者在不同数据稀疏性情况下的平衡分布权重,确保算法的精度和灵活度。计算公式如下
(18)
式中:simt(i,j)表示用户混合相似度,count表示用户评分数量,β为融合因子。
2.4 用户间的信任度
分析发现,用户间的信任关系在日常生活中占据着至关重要的作用,涉及到方方面面。但关于信任的描述是一个相对模糊的概念,对其的认知包括了主观性、不对称性、动态性等。传统推荐算法仅从评分角度考虑,但在现实生活中,仅以此得到的推荐精度难以保证,例如,存在一些商家为了使自己的产品得到更多推荐而伪造评分数据的情况。为了降低推荐结果对评分数据准确性问题带来的影响,本文引入用户间的信任机制,当用户间的可信度越高,那么由他所产生的推荐数据可靠性也相对更高。
推荐系统中两两用户之间的信任度受用户间交互关系的影响,所经历过共同的历史行为越多,那么所累积的信任度也越高。用户间每发生过一次相同项目的评分行为则认为产生过一次交互,根据交互次数与自身历史评分次数的占比关系,得到用户间的交互关系
IT(i,j)=|Ii∩Ij|/|Ii|
(19)
式中:Ii和Ij分别表示用户i和j的评分项目集合,|Ii|、|Ij|表示集合的势。
用户之间的信任度受交互关系影响的同时,也受交互状态的影响,成功的交互状态必然会加强用户间的信任度,同样,失败的交互状态也会削弱用户之间的信任度。将用户满意度状态作为衡量交互成功与否的标准:如果两个用户同时表现出对某项目的满意或者不满意,那么认为二者的交互状态是成功的,如果两个用户对共同评价的项目持不同的满意度,那么认为二者的交互状态是失败的。满意度的计算通过比较两个用户共同项目的评分与各自的平均评分,评分高于自身平均分即代表满意,反之则代表不满意。
综上所述,用户之间的交互状态如下

(20)
式中:sus表示成功交互的统计次数,每交互成功一次记sus+1;fal表示失败交互的统计次数,每交互失败一次记fal+1。结合式(19)计算用户间的交互关系,得到用户信任度
(21)
在上式中,对交互的成功与否,都认为两者对信任度的影响程度相同,但实际情况有所不同。在交互失败时两个用户的评分差值远大于交互成功时的评分差值,则说明此时两个用户对公共评分项的满意度存在较大分歧,因此可以认为失败交互所带来的负面影响更大。在对信任度进行修正时,加入评分差值作为影响交互平衡的惩罚权重,以加强失败交互带来的消极影响,改进后的用户间信任度如下

(22)
式中:IDP(i,j)表示用户i对用户j的信任度,Isus表示交互成功的集合,Ifal表示交互失败的集合,ric和rjc分别表示用户i和用户j对项目c的评分,式(22)满足信任度的不对称原则,即IDP(i,j)≠IDP(j,i)。
3 UPTCF算法描述
将上述所建立的修正评分相似度、用户兴趣相似度以及用户间的信任度进行动态融合,得到融合多层相似度与信任机制的协同过滤算法UPTCF,UPTCF的具体描述如下:
步骤1 根据用户项目-评分矩阵Rm×n,将矩阵中所有用户、项目以及评分数据进行标记提取;
步骤2 通过引入模糊逻辑法,对用户间的评分差值进行丰富化处理得到用户的模糊偏好,再基于模糊偏好差异对评分相似度进行修正,结合Jaccard相似性系数得到用户修正评分相似度sima(i,j);
步骤3 通过分别计算各种类型项目的评分均值与所有项目评分均值之和的占比关系,以及各类项目评分次数与项目总评分次数比值,计算二者之和,得到用户的兴趣向量,结合余弦相似度,计算出用户兴趣相似度simb(i,j);
步骤4 将步骤2和步骤3基于不同因素计算得到的相似度,结合式(18)进行权值融合,得到混合相似度simt(i,j)。考虑到仅利用simt(i,j)产生的预测评分进行项目推荐可能会导致推荐因素单一、推荐精度较差的问题,故在此基础上引入用户间的信任度关系。若目标用户i与目标用户j之间的混合相似度越高,同时i觉得j值得信任,那么i就更可能采纳j的建议。因此,在建立邻居用户集合Us时,将混合相似度以及信任度按照取值大小倒序排列,取出综合值最高的前k个用户建立邻居用户集合,并生成预测评分Pi,c
(23)
式中:δ的取值采用自适应模型[13]确定,δ取值范围为[0,1]
(24)
步骤5 将得到的预测评分Pi,c进行降序排列,针对目标用户未评分的项目,将预测评分最高的前N个项目推荐给目标用户。
4 实验与结果分析
4.1 实验数据
实验数据集为MovieLen(ml-100k)公用数据集,数据集中包含了943个用户对1682部电影的100 000个评分信息。将该数据集按照8∶2随机进行划分,将80%的评分信息作为训练集,将20%的评分信息作为测试集,前者用于构造推荐模型,并将产生的预测评分与后者的真实评分进行差值比较,训练集和测试集的数据稀疏性都为93.6%,根据对数据集中用户评分次数进行统计分析,评分次数小于15的用户数量与评分次数大于15的用户数量差值最大,此时在计算用户混合相似度的过程中,两种相似度的计算精度受到数据稀疏性差异的影响最大,故本文取d1=15进行以下实验,完成未知参数的取值。
4.2 评价标准
对推荐系统的准确度的评价指标分为很多种,本文采用MAE(mean absolute error)作为算法准确度的评估指标,平均绝对误差的计算公式如下
(25)
式中:reali表示实际评分,prei表示预测评分,n表示预测评分数量。
4.3 实验结果与分析
本文实验利用IDEA完成算法的运行实现以及实验结果的统计分析,IDEA全称IntelliJ IDEA,是编程语言开发的集成环境。实验一完成未知参数α和β的确定,采用十折交叉法,在MAE值最小时完成参数值的确定;实验二采用对照实验验证本文算法的有效性。
实验一:未知参数的确定
(1)兴趣向量权重α的确定
项目类型偏好权重α主要用于调节对基于不同类型项目与总评分值的比值,以及不同类型项目数量与总评分项目数量的比值,通过调节二者占比,得到不同的兴趣向量interesti,j,再根据兴趣向量结合式(17)计算用户之间的兴趣相似度simb(i,j)。实验过程中α以0.1为步长递增,取值范围为[0,1],邻居集合k以10为步长,取值范围为[10,60]。根据计算生成多组预测评分,得到对应的真实评分与预测评分的MAE,统计结果如图2所示。
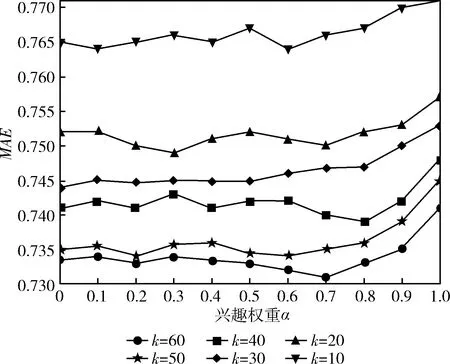
图2 偏好权重α的确定
从图2中可以看出,MAE随着邻居集合数量的增加呈下降趋势,说明推荐精度受到数据稀疏性的影响较为明显。观察图2可知,在k=60,α=0.7时,此时预测评分与真实评分的平均绝对误差最小,达到最优值,故未知参数α的取值为0.7。
(2)融合因子β的确定
动态融合因子β的作用是针对根据数据稀疏性的不同,动态调整两种相似度算法在混合相似度中的占比关系。实验通过对邻居集合数量k以及融合因子β采取步长均匀变化取值的方法,计算出多组预测评分及其MAE的变化曲线,实验结果如图3所示。

图3 动态权重β的确定
从图3可以看出,随着邻居集合数的增加,MAE的差值逐渐降低,当集合数k取值为60,动态因子β的取值为0.9时,MAE取得最优值,故本文中β=0.9。
实验二:算法性能对比
(1)引入信任机制前后算法性能对比
算法性能的验证采用对比实验的方法,对比引入信任机制前后两种算法所得的MAE的值越小,说明该算法的准确性越高。根据实验一所取得的最优值α=0.7,β=0.9,基于此参数,分别采用基于用户混合相似度算法(UPCF),以及在此基础上加入信任机制的UPTCF算法,得到各自的邻居用户集合,并以10为步长,对邻居集合数k进行递增取值,计算得到两种算法所对应的两组MAE,其实验结果如图4所示。

图4 算法引入信任机制前后MAE对比
从图4分析可知,随着邻居用户数量的增多,在引入信任机制后的UPTCF算法所得到的MAE变化趋势相比于UPCF而言,下降趋势呈现出由急变缓的趋势,由此可知UPTCF算法在数据稀疏性较高时,相比于UPCF算法推荐准确度更高;伴随着邻居用户数量k的增加,引入信任机制的UPTCF算法相比于未引入信任机制的UPCF算法而言,准确度均有一定程度的提升,由此验证引入信任机制对算法性能的优化。
(2)UPTCF算法与其它几种算法准确度对比
几种算法准确度的比较同样采用对比实验的方法,对比的算法包括:传统余弦相似度(CSCF)、改进的余弦相似度(ACSCF)和文献[5]中提出的基于修正相似系数Jaccard的协同过滤算法(MKJCF),计算各种算法对应的MAE,实验结果如图5所示。

图5 不同算法的MAE值比较
通过图5分析得出,随着k值的递增,以上4种算法的MAE都呈现不同程度的下降,并最终趋于平缓,且本文所改进得到的UPTCF算法的MAE均小于其它3种算法,实验结果分析如下。
通过引入用户兴趣度以及信任机制,使得UPTCF算法相比于其它算法而言,在数据稀疏性情况下具有明显优势:在k=10时,UPTCF算法的MAE取值为0.765,相比于改进的余弦相似度算法(ACSCF)在准确度上提升了6.3%,相比于余弦相似度算法(CSCF)在精度上提升了3.8%,与改进的MKJCF算法相比,其准确度约有2.1%的提升。随着邻居用户数量的增加,各算法的推荐准确度均有不同程度的提升,在邻居集合数量k=80时,本文提出UPTCF算法的MAE取得最小值,达到了0.721,相比于余弦相似度算法(CSCF)的MAE降低了3.1%,相比于改进的余弦相似度算法(ACSCF)的MAE降低了2.9%,与改进的MKJCF算法相比,MAE降低了1.7%;综上所述,本文改进得到的UPTCF算法相比于其它几种协同过滤算法,其推荐准确度都有较为明显的提升,且在数据稀疏性情况下,推荐准确度的性能提升更为明显。
5 结束语
为了从多方面解决推荐系统中用户相似度计算精度低以及数据稀疏性的问题,本文提出并实现了的融合多层混合相似度与信任机制的协同过滤算法,该算法在一定程度上缓解了数据稀疏性带来的影响,尤其是在邻居集合数量较少的情况下;同时,相比于传统的余弦相似度算法以及部分改进算法,在推荐准确率方面均有较大的提升;但算法本身仍然存在冷启动问题,因此在未来的研究工作中,仍需对启动问题做重点研究和解决。
