具有缺失数据混合泊松分布参数的估计①
2020-12-28杨艳秋于新龙
杨 航, 杨艳秋, 于新龙
(吉林师范大学数学学院,吉林 四平 136000)
0 引 言
数据缺失情况下的统计推断问题一直是热点问题.有关一些常见的连续分布,文献[1]研究两个幂分布在部分数据缺失情况下的参数估计及检验问题.文献[2]研究具有部分缺失数据的混合指数分布的参数估计及假设检验问题.由于泊松分布是最常见到的非连续分布,因此对于泊松分布的统计推断问题一直是统计学家关心的热点研究问题.文献[3]研究两个泊松分布总体参数的估计及检验.文献[4]给出含部分缺失数据的泊松分布参数的贝叶斯估计.文献[5]阐述了泊松分布的由来及发展.文献[6]给出泊松分布以及复合泊松分布的性质.2016年何朝兵、杜保建等人[7]通过EM算法得到了在不完全信息随机截尾试验下的混合泊松分布参数的点估计.2019年隋崴等[8]得到了双变量泊松分布参数的极大似然估计.文中进一步研究混合泊松分布在部分数据缺失情况下的参数估计问题,计算混合泊松分布总体未知参数的矩估计,证明其性质,并进行随机模拟以示其可行性.
1 参数矩估计及其性质
混合泊松分布的密度函数为
f(x,q,λ1,λ2)=
其中λi>0(i=1.2)是第一个总体的参数,在对总体分布进行n次独立观测下,每个样本的观测值以1-p的概率被缺失,以p的概率被观测,用(Xi,δi),i=1,2,...,n去表示总体的第一个观测值,这里Xi表示第一个混合泊松分布总体的第i个样本观测值,若第i个观测值丢失,记δi=0,否则记δi=1.
下面用矩估计对两个未知参数λ1,λ2进行估计,建立如下矩估计方程:
其中EX=qλ1+(1-q)λ2,E(X2)=qλ1(λ1+1)+(1-q)λ2(λ2+1).
解得
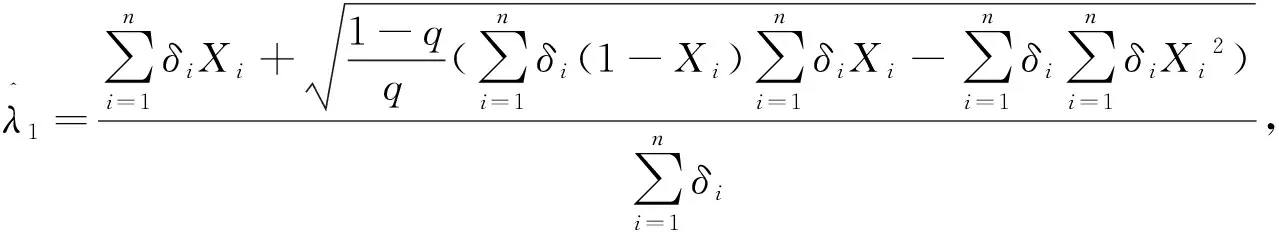
下面证明:对于上述参数λi(i=1,2)的矩估计的渐近正态性以及相合性.
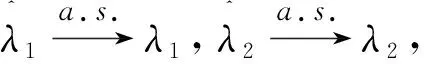
证明:{Xiδi,1≤i≤n}是独立同分布的随机变量序列,由强大数定律可知
这里
E(X1δ1)=E(X1)E(δ1)=p(qλ1+(1-q)λ2).
同理可知
(1-q)λ2(λ2+1)),
进而有


其中
定理2在上述记号下有
证明:令Wi=(δi,δiXi,δiXi2),(Wi,i≥1)是独立同分布的随机变量序列,且
E(W1)=(p,p(qλ1+(1-q)λ2),
p(qλ1(λ1+1)+(1-q)λ2(λ2+1))).
令∑=E(W1-EW1)(W1-EW1)T,则由多元中心极限定理可知
记
其中
a11=p(1-p),
a12=a21=p(1-p)(qλ1+(1-q)λ2),
a13=a31=p(1-p)(qλ1(λ1+1)+(1-q)λ2(λ2+1)),
a22=p(qλ1(λ1+1)+(1-q)λ2(λ2+1))-
p2(qλ1+(1-q)λ2)2,
a23=a32=p(1-p)(qλ1(λ1+1)+
(1-q)λ2(λ2+1))(qλ1+(1-q)λ2),
a33=p(1-p)
(qλ1(λ1+1)+(1-q)λ2(λ2+1))2,
令
α1=p,
α2=p(qλ1+(1-q)λ2),
α3=p(qλ1(λ1+1)+(1-q)λ2(λ2+1)),
所以
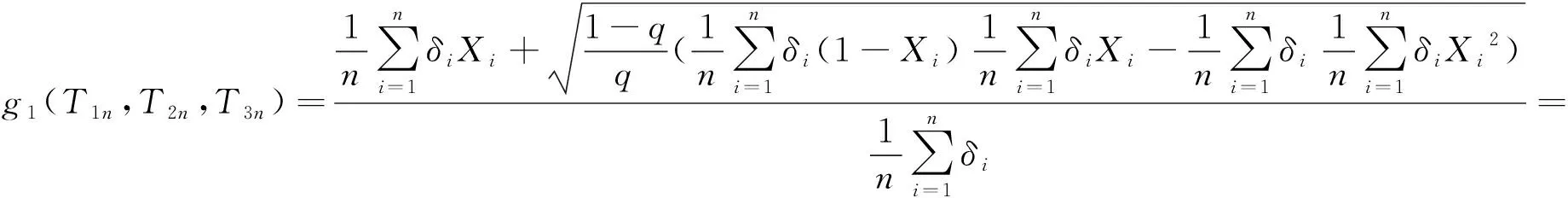
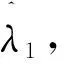
由引理1知
而且
同理令
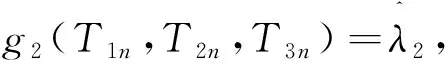
由引理1可知
其中
2 随机模拟
下面利用随机模拟说明所给出的方法的可行性,表1分别给定样本容量为n=50,n=100,n=300,缺失概率1-p=0.10,混合概率q=0.7和q=0.9时的模拟研究结果。模拟计算了不同参数λ1,λ2下1000次估计的均方误差,括号中第一个数字是参数λ1的均方误差,第二个数字是λ2均方误差.
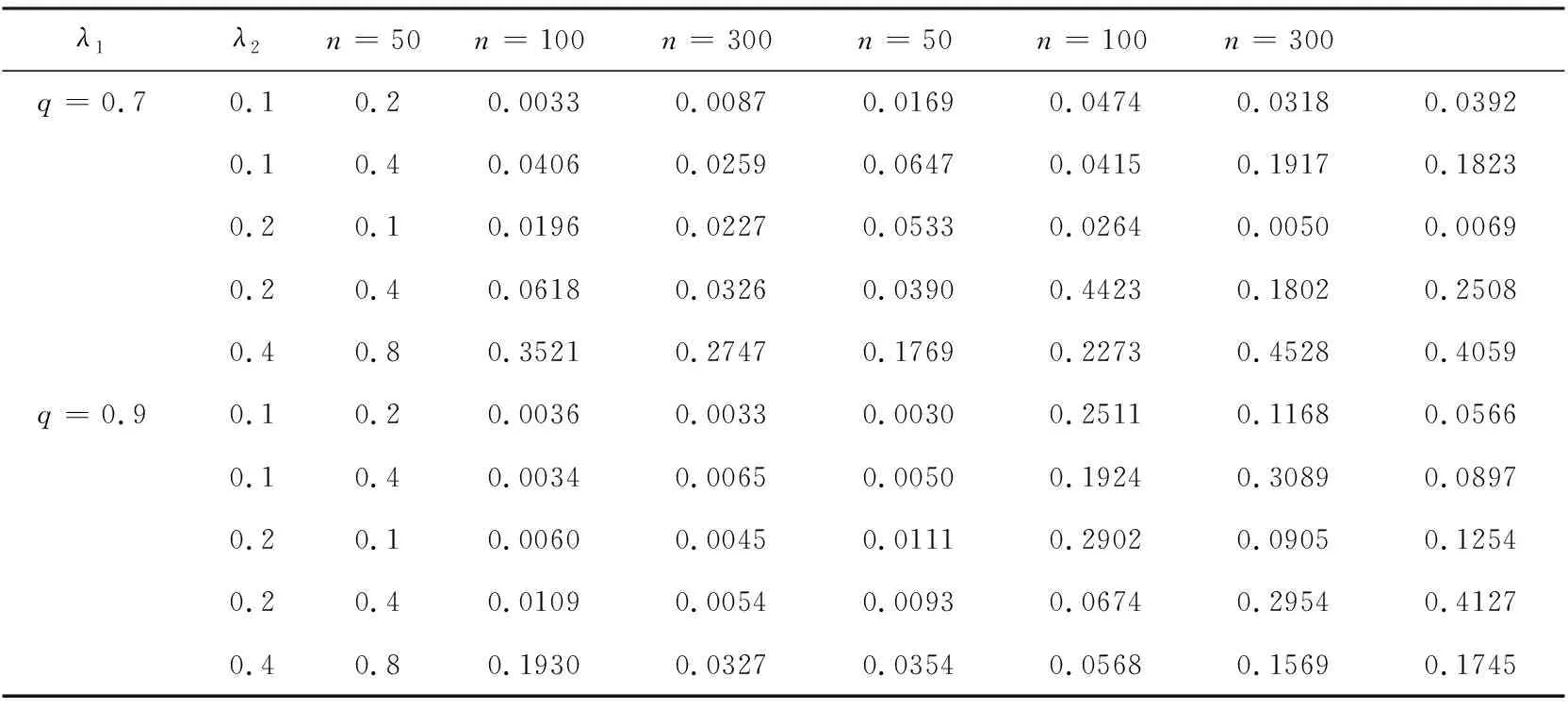
表1 模拟结果
从表1中的模拟结果可以看出,对于不同的参数以及不同的样本量,参数估计的均方误差都相对较小,并且误差也比较稳定,说明所给出的估计方法能够对未知参数给出较为精确的估计.
3 结 论
研究了具有缺失数据的混合泊松分布总体参数的估计问题。利用矩估计给出了未知参数的估计,同时考虑了估计的极限性质。也通过模拟分析计算了估计的均方误差,根据模拟结果可知,的估计有较小的均方误差,说明我们的估计方法具有可行性.
