热镀锌钢卷力学性能GBDT预报模型
2020-12-23匡祯辉谢少捷白振华
王 伟,匡祯辉,谢少捷,白振华
(1. 福州大学机械工程及自动化学院,福建 福州 350108; 2. 燕山大学机械工程学院,河北 秦皇岛 066004)
0 引言
热镀锌钢卷广泛应用于汽车、 建筑和桥梁等许多领域,力学性能是其重要质量指标之一[1]. 热镀锌生产工艺涵盖炼钢、 热轧、 冷轧、 退火、 镀锌和平整等多道工序,包含众多对力学性能有影响的工艺参数. 这些工艺参数共同控制钢材组织演变并最终影响力学性能. 热镀钢卷力学性能预报是钢卷力学性能质量控制的重要基础,准确的力学性能预报模型为钢种优化、 生产工艺设计提供依据,同时还可减少力学性能抽检带来的人力和物力的耗损,从而有效提高产品质量并降低生产成本[2]. 传统的预报建模是通过成分和工艺先建立组织模型,再根据组织模型建立力学性能预报模型的[3]. 但冶金生产流程长,工艺参数多, 导致机理模型建模过程复杂,稳定性差. 随着工业大数据时代的到来,基于数据驱动的智能建模方法越来越多地应用于镀锌钢卷力学性能预报建模[4].
BP神经网络模型是过去10年应用最广泛的热镀产品力学性能非线性预报模型. 贺俊光等[5]以化学成分、 温度参数和冷轧压下率等属性作为输入,建立可行的镀锌板抗拉强度BP神经网络预报模型. 吴思炜等[6]利用Bayes神经网络建立了多种牌号C-Mn钢力学性能的预测模型. Ordieres等[7]采用主成分分析法进行降维聚类,根据聚类分析结果将产品数据细分成不同的工艺模式,进而建立多工艺模式的神经网络预报模型. Sanz-Garcia A等[8]采用集成学习方法建立高精度的镀锌产品力学性能集成神经网络模型,从而增加预报模型的鲁棒性. 神经网络模型表现出较好的预报精度,但模型的可解释性不强,建模时神经元个数和隐含层层数等模型结构参数的选择尚无科学依据,需要从实践中总结经验,使得模型开发时间相对较长,模型调优困难.
机器学习中的其他非线性模型,如随机森林(random forest,RF)、 自适应提升AdaBoost(adaptive boosting, AdaBoost)[9]和梯度提升树(gradient boosting decision tree,GBDT)[10]是以决策树为基模型的集成学习模型,精度高,可解释性强[11]. 杨威等[12]采用随机森林实现高精度预报钢材抗拉强度,并筛选重要性高的属性集合对模型进行解释. 三种集成学习方法中,RF模型关注降低预测结果的方差,注重模型的稳定性,GBDT和AdaBoost关注降低预测值与实际值偏差,更注重模型的精度[13]. AdaBoost和GBDT两者区别在于boosting策略不同,AdaBoost通过不断改变样本权重提升模型性能,而GBDT则是通过不断拟合上一颗树残差来提升性能[14].
结合工厂数据集研究基于GBDT的力学性能预报问题,以屈服强度预报为例介绍基于互信息差算法(mutual information difference,MID)的属性选择、 交叉验证数据集切分以及模型建立的关键步骤,并对GBDT、 RF、 AdaBoost和BP四种模型力学性能预报结果进行比较.
1 基于GBDT理论的热镀锌钢卷力学性能预报方法
1.1 热镀锌钢卷力学性能预报过程
热镀锌钢卷力学性能预报流程如图1所示. 首先对工厂采集的数据进行清洗、 去噪,确定条件属性集和目标属性. 采用互信息差法筛选条件属性,建立完备数据集. 通过基于随机同分布数据划分方法划分建模数据集和测试集,利用网格搜索法确定最优GBDT模型参数. 以五折交叉验证技术充分利用建模数据训练模型,然后以相同的流程建立对比模型. 根据GBDT模型和对比模型在训练数据和测试数据上的预测结果,进行分析评价.
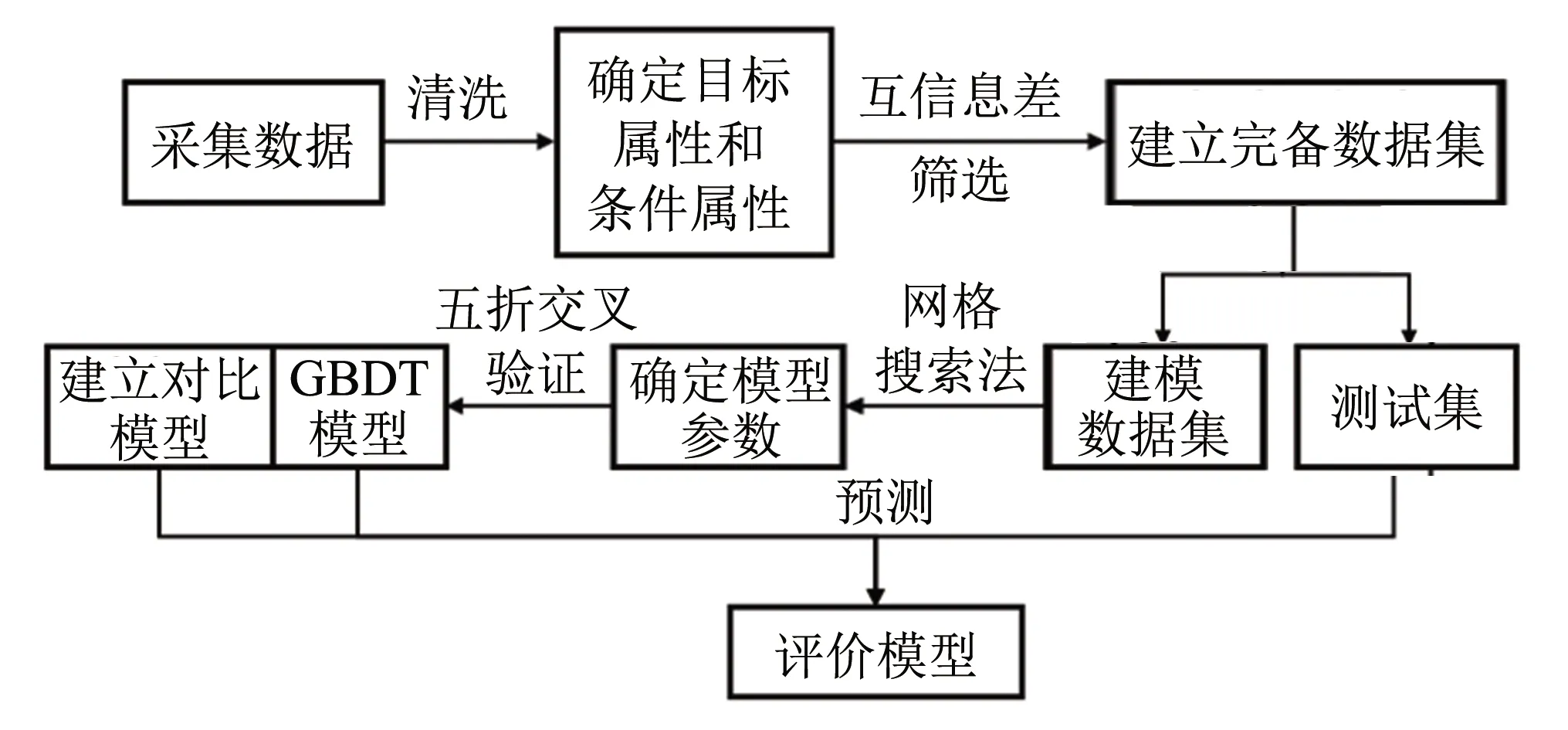
图1 热镀锌钢卷力学性能预报流程图Fig.1 Prediction process of mechanical properties of hot-dip galvanized steel coils
1.2 梯度提升树算法
GBDT是以分类回归树(classification and regression tree, CART)为基模型的集成学习算法. GBDT基于Boosting迭代的思想,除了第1棵决策树采用原始预测指标生成外,每一轮迭代中的目标都是拟合当前模型的残差. 令当前学习器的损失函数最小化,通过不断迭代使最终残差趋近于0,将所有树的结果累加起来便可得到最终的预测结果[15].
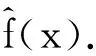
1) 初始化估计使损失函数极小化的常数值,它是只有一个根结点的树:

(1)
式中:f0(x)为只有一个根节点的树;L(yi,c)为损失函数,其中yi为第i个训练数据,c为使损失函数最小化的常数.
2) 令迭代次数为m=1, 2, … ,M,
a) 对样本i=1, 2, …,N, 计算损失函数的负梯度在当前模型的值,将它作为残差的估计:

(2)
b) 估计回归树叶结点区域,以拟合残差的近似值,对rmj拟合一个回归树,得到第m棵树的叶结点区域Rmj,j=1, 2, …,J;
c) 对j=1, 2, …,J,利用线性搜索估计叶结点区域的值,使损失函数极小化:

(3)
d) 更新学习器fm(x):

(4)
3) 将所有学习器得到的cmj值在相同的叶结点区域累加,得到最终回归树为:
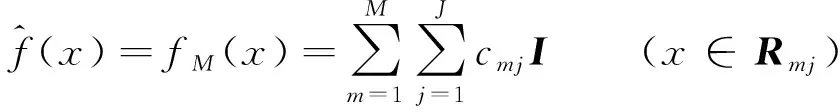
(5)
1.3 基于五折交叉验证的模型数据集划分
在模型训练与评估开始前要进行各阶段数据集准备,采用随机同分布与五折交叉验证理论划分训练集、 验证集和测试集. 首先将完备数据集以7∶3的比例随机同分布划分出建模数据集和测试集; 其次采用交叉验证法对用于模型训练的建模数据集进行划分,将建模数据集划分成5个大小相似,分布一致的互斥子集,每次使用其中4个子集的并集作为训练集,余下的一个子集作为验证集,利用划分好的5份建模数据集,分别建立5个模型,最后将5个模型在测试集样本上预测结果的平均值作为模型输出. 如图2所示,五折交叉验证训练模型的验证集依次为D5,D4,D3,D2,D1,等价于采用全部建模数据用于监督模型训练,使数据利用率达100%.

图2 五折交叉验证技术Fig.2 Five-fold cross-validation technology
2 基于互信息差的力学性能预报模型条件属性筛选
2.1 筛选方法
互信息作为评价条件属性对目标属性贡献的信息量,是衡量信息相关性的一种方法[16],不仅可用来评估属性之间的线性关系,而且能很好地评估属性间的非线性关系. 其计算公式为:

(6)

(7)

(8)
式中:熵H(X)为X不确定性的度量,熵越大表示随机属性的随机性越大;I(X,Y)表示熵值的减少量;H(X|Y)为X对Y的条件信息熵,其中X包括随机属性所有可能的取值;p(x)为某个值x出现的次数;p(x,y)为两个随机属性(X,Y)的联合概率密度函数;p(x|y)为给定Y时X的条件概率.
互信息法可以在待选条件属性中选出与目标属性具有最大相关性的条件属性,但却忽略了已选条件属性之间存在的信息冗余. 而互信息差算法将信息冗余作为惩罚项引入评价函数,降低了已选属性之间的信息冗余. MID算法的公式为:

(9)

互信息差J(fi)综合反映了待选属性与目标属性以及已选属性集之间的相关关系,互信息差越大,表明待选属性对目标属性相关性大、 更重要,而与已选属性子集的相关性小、 冗余更小,从而能保证筛选出来的属性集不但对目标属性影响大,而且冗余小. 互信息差算法具体流程如下(以筛选条件属性为例):
1) 初始化已选属性集合S(初始空集); 初始化待选条件属性集合F(包含全部的n个变量).
2) 选择待选条件属性fi∈F,通过式(8)计算fi与目标属性Y之间的互信息.
3) 选择首属性:选择2)步中互信息值最大的条件属性作为首属性,并将计算出的互信息值进行排序.
4) 循环计算待选条件属性fi与已选条件属性fj之间的互信息,并且根据评价准则(9)选择互信息差J(fi)最大的待选条件属性fi作为下一属性; 更新F=F-{fi},S=S+{fi},直到所选条件属性个数达到预设变量数k,并输出条件属性集结果.
2.2 筛选结果及分析
工厂实际生产过程中,受外界环境、 钢材成分波动、 生产工艺变化的干扰,导致实际工业数据存在噪声,模型预测精度会大大降低. 因此, 根据统计学拉衣达准则和冶金知识对原始数据进行清洗、 去噪,建立完备数据集.
热镀锌钢卷屈服强度Re范围为[280, 350]MPa, 抗拉强度Rm范围为[335, 399]MPa,断后延伸率d范围为[26.5%,35.5%]. 其中屈服强度与影响因素关系更复杂,屈服强度波动范围较大,屈服强度预报及过程控制更难. 以屈服强度作为目标属性开展力学性能预报研究,相关的方法也适用于其他两个力学性能指标.
影响热镀锌钢卷力学性能的主要因素包括化学成分、 热轧工艺参数、 冷轧工艺参数、 连续退火工艺参数、 平整和拉矫工艺参数. 化学成分是力学性能的基础,碳、 锰含量变化对带钢抗拉力学性能有明显影响,屈服强度随铝质量分数的增大而减小、 有利于提高冲压性能,N含量过高会影响钢卷表面质量和加工性能,Nb、 Ti等微量合金通过细化晶粒和沉淀强化影响钢卷的力学性能. 热轧加热、 终轧以及卷取温度影响铁素体晶粒大小以及氮化铝析出物的含量. 冷轧压下率对冷轧带钢中轧制织构和后道退火工序中再结晶织构有重要影响. 带钢在连续退火炉中通过加热、 保温、 冷却,消除冷轧后的加工硬化和实现再结晶过程,从而影响力学性能. 平整通过小压下量的轧制变形,消除明显的屈服延伸,改善板形,获得所需要的带钢表面形貌. 拉矫通过对钢材拉伸弯曲矫直,改善板形、 力学性能.
将影响力学性能的主要因素作为条件属性,包括尺寸参数、 化学成分和工艺参数共50维属性. 其中尺寸参数与冷轧压下率有关,热轧、 退火、 平整和拉矫工艺参数包括每个钢卷的最大值、 最小值和平均值.
条件属性维数较大,属性之间存在一定的相互耦合,因此需要运用统计分析进行筛选. 图3为退火工艺参数皮尔逊相关系数图,图中每一个格子中的数字代表横纵坐标轴对应两条件属性的皮尔逊相关系数. 系数反映两个属性的线性相关程度,值越大代表这两个属性之间的线性相关性越高[17]. 图3中退火工艺各阶段温度变量大部分相关性在0.8以上,参数之间强线性相关,但皮尔逊相关性会忽略掉属性间的非线性关系. 下面采用互信息差进行条件属性筛选,考虑到化学成分和工艺参数维度不同,分两组独立筛选. 最终以互信息差为指标综合选出 25 维条件属性作为模型输入.

图3 退火温度皮尔逊相关性热力图Fig.3 Annealing temperature Pearson correlation heat map
对化学成分的筛选如表1所示,以互信息差MID值为指标进行降序排列. 其中,首属性Mn的互信息和互信息差具有相同的大小0.28,表明Mn含量对目标属性贡献大; 属性Nb互信息值为0.14, 但互信息差MID值却为-0.01,表明Nb元素虽然对目标属性有较大贡献, 但与已选化学元素对力学性能的作用相近,因此被剔除. 选择互信息差大于0的9个化学成分.

表1 化学成分筛选结果Tab.1 Chemical attribute selection results
工艺参数筛选结果如表2所示,以互信息差MID值为指标进行降序排列. 筛选出包括热镀机组速度、 退火直燃段温度、 退火均段热度、 退火冷却段温度、 平整延伸率、 拉矫率和热轧终轧温度, 热轧卷取温度包括最大(小)值和平均值在内的互信息差大于0的14个工艺参数. 退火冷却段温度3个统计量中,退火冷却段温度最大值的互信息差最小为0.032,但互信息差依旧排在前五位,表明退火冷却段温度统计信息十分重要, 均被保留; 热轧卷取温度均值互信息差为-0.001, 表明热轧卷取温度均值与已选属性集冗余,应剔除.

表2 工艺参数筛选结果Tab.2 Process parameters selection results
3 热镀锌钢卷力学性能预报建模结果与分析
原始数据样本经过清洗后,获取4 780组高质量数据,构成完备数据集. 以7∶3比例划分,其中3 346条数据构成建模数据集,剩余1 434条数据构成测试集. 将筛选后的条件属性作为模型输入属性,采用五折交叉验证技术将建模数据集划分为5份,每次取4份用于模型训练,剩余一份作为模型验证. 针对力学性能预报建模,以屈服强度为例进行5次GBDT建模训练,将5次模型预测结果的平均值作为输出. 同时建立AdaBoost、 RF和BP模型,在建模数据、 建模输入属性和数据划分方式不变的情况下,对模型的预测结果进行比较.
模型预测结果比较采用平均绝对误差(mean absolute error, MAE)和均方根误差(root mean squared error, RMSE)两个指标,其中,MAE反映预测值和真实值之间的偏差,RMSE代表预测值和真实值之间差值的标准差.
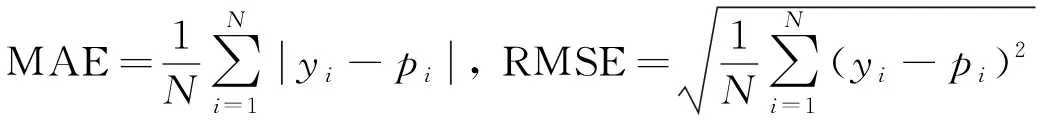
(10)
式中:N为总样本数;yi为第i条样本的真实值;pi为第i条样本的预测值.
3.1 力学性能预报建模的实现
力学性能预报建模采用Ubuntu16.04系统和Python3.6平台, 利用Python平台Scikit-Learn库和TensorFlow库实现集成学习和神经网络算法. 力学性能预报建模步骤如下:
1) 通过Pandas库导入工厂数据集并去噪,利用Scikit-Learn库实现互信息差算法对样本数据的属性筛选,同时设定GBDT的初始参数.
2) 调用Scikit-Learn库中的train_test_split函数按比例将样本随机划分为同分布的建模数据集和测试集.
3) 在建模数据集上采用网格搜索法在模型超参数空间进行搜索,优化模型参数,并记录最优模型参数.
4) 利用最优模型参数与五折交叉验证技术,建立力学性能预测模型.
3.2 预报建模结果及分析
3.2.1数据集切分及模型参数调优结果
图4为样本数据集随机分层采样切分后建模数据集和测试集屈服强度的高斯核分布,该图表明建模数据集和测试集的分布具有一致性.
图4 建模数据集和测试集的屈服强度高斯核分布Fig.4 Gauss kernel distribution of yield strength for model training set and test set
在建模数据集上划分出训练集和验证集,结合网格搜索法在建模数据集上进行4个模型的参数优化. 其中GBDT模型有1个子样本,其最优参数为决策树个数500,最大深度为7,叶节点最小样本数2,学习率0.1, 如表3所示; RF模型最优参数为决策树个数500,最大深度为6,叶节点最小样本数2; Adaboost模型最优参数为决策树个数500,学习率0.1; BP模型选用双隐层,神经元个数分别为32、 16,采用relu激活函数,优化算法为学习率自适应算法(adaptive moments, Adam).
3.2.2力学性能预报模型预报结果的比较及分析
在相同建模数据集情况下,四种预报模型五折交叉验证建模的训练集和验证集误差统计结果如表3所示. 表3中平均值和标准差为模型交叉验证且训练5次的训练集和验证集的均方根误差和平均绝对误差的统计值. 测试集样本取五折训练模型的5次预测结果平均值为最终预测结果. 四种预报模型测试集均方根误差和平均绝对误差统计结果如表4所示.

表3 预报模型训练集和验证集误差统计Tab.3 Training set and validation set errors of the prediction model

表4 四种预报模型测试集误差统计Tab.4 Test set errors of four yield strength prediction model
表3中训练集的均方根误差和平均绝对误差的平均值反映模型训练的精度,标准差反映模型训练结果的稳定性. 表4中测试集均方根误差和平均绝对误差既反映测试集预测精度,也反映了模型的泛化能力. 从表3、 4四种模型预测结果的对比,可得到如下结论.
1) 从表3模型训练集精度来看,无论是均方根误差均值还是平均绝对误差均值,集成学习模型的误差都小于BP模型误差,这表明在小样本情况下集成学习表现出更强的数据拟合能力. RF和AdaBoost两个模型误差接近,而GBDT模型的训练集和验证集的均方根误差均值分别为7.52、 9.28 MPa,明显小于其他两个集成学习模型,表明GBDT模型训练精度最高. GBDT模型的基模型采用残差拟合的方法进行训练,相比于其他模型精度更高,对数据的拟合能力更强.
2) 从表3模型训练集结果的稳定性来看,BP模型的均方根误差标准差和平均绝对误差平均值最大,远高于集成学习模型,表明BP模型训练结果稳定性小于集成学习模型. 五折训练时每次的训练集样本存在一定的分布差异,而BP属于单模型训练对数据分布差异更为敏感,造成五折交叉验证训练的模型性能差异. 集成学习属于多模型,能够一定程度上消解由于数据分布差异造成的训练结果的差异性,从而提高模型训练的稳定性. 三种集成学习模型中,RF模型五折训练均方根误差的标准差最小为0.05 MPa,表明RF的稳定性最好. RF模型通过重采样训练多个相互独立的基模型,再对预测结果求平均,降低了模型总体方差,五折训练的标准差最小.
3) 从表3各模型五折训练总时长来看,训练时间均小于13 s,满足工业上在线训练的需求. 其中GBDT模型训练总时长为9 s,RF模型训练总时长最短为6 s. 模型训练过程中,GBDT模型串行生成基学习器,而RF的基学习器采用并行生成方法,训练速度更快.
4) 从表4模型泛化性能来看,GBDT模型测试集均方根误差和平均绝对误差分别为9.64、 7.32 MPa,同时模型测试集误差与验证集误差接近,这表明GBDT模型在未知数据上依旧能表现出较好的预测性能,具有一定的泛化能力.
3.2.3GBDT模型预测结果的统计及分析
GBDT模型无论是训练精度还是泛化能力都具有较好的性能. GBDT模型测试集预测值和真实值的详细统计结果如表5所示,统计量包括最大(小)值、 平均值、 方差、 中位数和90%分位数. 从数据分布来看,屈服强度真值与预测值的平均值和方差相接近,表明模型学习到正确的规律. 从绝对误差来看,90%的数据样本预报误差的绝对误差小于14.24 MPa. 图5展示了GBDT模型预测值与实测值的对比,图中预测值和真实值相对误差在6%以内的样本数据比例为94.6%.

表5 GBDT屈服强度测试集预报结果统计分析Tab.5 Statistical analysis of forecast results of yield strength test set of GBDT model (MPa)

图5 GBDT模型屈服强度预测值和真实值对比Fig.5 Comparison of predicted and measured yield strength of GBDT model
4 结语
针对热镀建模数据多维度、 存在数据噪声以及属性之间的冗余问题,通过互信息法筛选获取高信息量条件属性集,可大幅缩减模型输入属性子集维度, 减少训练时间, 提升模型的稳定性. 通过建模数据集和测试数据集的同分布数据切分,以及建模数据集五折交叉训练进行基于GBDT的热镀力学性能建模,模型验证集精度和测试集精度一致,表明建模方法在保证模型泛化能力的同时,避免了模型过度拟合.
热镀力学性能预报模型预报结果比较表明,GBDT、 RF、 AdaBoost 三种集成学习模型在训练效率、 预报精度以及在测试数据上的泛化能力优于 BP 模型; 三种集成学习模型中,GBDT 预报精度和泛化能力最好,在热镀力学性能预报建模中有明显优势.
