基于生成对抗网络的多目标行人跟踪算法
2020-12-18徐楚翘刁兆富李伯群
魏 颖,徐楚翘,刁兆富,李伯群
(1. 东北大学 信息科学与工程学院,辽宁 沈阳 110819; 2. 辽宁科技大学 电子与信息工程学院,辽宁 鞍山 114051)
在计算机视觉研究领域里,目标跟踪[1]是主要的方向之一,有单目标跟踪和多目标跟踪两种类型.其中,多目标跟踪需要在给定的视频序列中同时标记数个目标,从而获得它们的运动轨迹.多目标跟踪在机器人导航、智能视频监控、自动驾驶等范围都有着极为普遍的运用.行人目标作为一种典型的非刚体目标,跟踪难度较大,是实际应用中最常见的一种.
近年来,基于神经网络的深度学习技术取得极大的发展,具有代表性的检测算法包括Fast R-CNN[2],SSD[3]和YOLO[4]算法等.随着目标检测技术的进步,基于检测的多目标跟踪算法(tracking-by-detection) 占据主要地位.算法在每一帧中检测出目标,然后与已有的跟踪轨迹进行匹配.对于当前帧中的新目标,需要形成新的轨迹;对于离开当前帧中视野的目标,需要终止目标的轨迹.
多目标跟踪场景比较复杂,需要处理目标的光照、变形、遮挡等问题.跟踪过程中背景与目标之间会发生相互交互,因此应用高性能的检测算法在多目标跟踪中极为重要.在跟踪任务中,通常用卡尔曼滤波来进行跟踪目标的轨迹预测,但目标发生姿态变化时不能达到很好的跟踪效果.在跟踪目标与检测目标进行数据关联计算时,一般通过匈牙利算法进行边界框重叠 (IOU)[5]的关联度量,这种关联度量在状态估计不确定性高时,容易出现身份交换和跳变的问题.
为了更好地应对上述多目标跟踪问题中的难题,许多学者基于深度学习理论提出了不同措施,以提高算法的性能.Wang等[6]率先将深度学习应用到多目标跟踪中,使用了自动编码器网络,优化提取到的视觉特征,并采用支持向量机来处理关联问题.Wojke等[7]提出Deep Sort算法,运用一个残差网络结构来提取目标的外观信息,用匈牙利算法将外观特征向量的余弦距离与运动信息关联起来.Sadeghian等[8]引入循环神经网络,将 LSTM提取的特征相融合,获得相似度得分.自从生成对抗网络模型[9]被首次提出以来,文献[10]运用生成对抗网络进行数据增强,将其应用到行人重识别领域.文献[11-12]在有关预测行人运动轨迹的工作中,通过结合生成对抗网络和LSTM来帮助提高预测效果.
针对上述观察,本文提出了一个多目标跟踪算法的框架,基于YOLO的人体人脸关联算法进行目标检测,可以解决在密集场所中人体和人脸匹配困难问题,提高行人目标检测的准确度;在特征提取模块和路径预测模块均引入了生成对抗网络,对目标形状颜色等外观特征进行有效表达,可以应对目标复杂多变的运动轨迹;优化了跟踪与检测的数据关联算法,在匹配时融合了外观信息和运动信息,提高了整个模型的鲁棒性.
1 算法框架
本文提出的整体算法框架由4个模块组成,分别是检测模块、特征提取模块、预测模块和匹配模块.如图1所示,首先对被跟踪视频序列的当前帧图像进行检测操作,获取所有目标的位置信息,即相互关联的人体检测框和人脸检测框,人脸框的存在可以使人体框较为粗略的特征有所补充.特征提取模块包含两种提取特征的网络,Net1为基于生成对抗的行人特征提取网络,Net2为常见的人脸识别网络,两个特征拼接形成最终的特征.同时使用基于生成对抗的行人多目标轨迹预测网络对每个目标的运动轨迹进行状态估计.将以上信息送入最后的匹配模块,进行轨迹更新,以达到对每个目标的持续跟踪.
1.1 基于YOLO的人体人脸关联检测算法
本文提出了一种基于YOLO的人体人脸相关联的目标检测算法,主要解决密集场所中行人目标检测困难问题.在目标人体的外观相似时,增加了人脸特征以增加外观特征的区分度.本文将YOLO的网络进行改进,网络结构图如图2所示.首先将检测图片送入网络中,输出层包括3个不同尺度的特征图,保证了模型对各种尺度物体的检测能力.将包含特征的向量根据置信度进行降序排序,先将top 1置信度的框的位置信息(bounding box,简称bbox)遍历其他bbox进行IOU计算.如果值大于阈值,则认为该bbox为重复框,将其剔除.然后再从剔除后剩余的bbox取出top 2的bbox重复以上的操作,直至遍历结束,最终得到精简的检测结果.

图1 多目标跟踪算法架构

图2 基于 YOLO的人体人脸检测网络结构图
改进后的输出层在原来的基础上增加了4维用于存放于人体框相关联的人脸框的位置信息,分别为相对人体框的人脸框的横向位置,纵向位置,宽度和高度信息.

(1)
(2)
(3)
(4)
(5)
(6)

1.2 基于生成对抗的特征提取算法
在特征提取模块中,本文采用了基于生成对抗的算法提取行人特征.相比于一般的深度学习特征提取方法,通过生成对抗生成新的数据,使特征提取的网络在最大程度上减小相同ID图像间的类内特征变化和区分不同ID的图像间的类间特征.本文使用编码器作为识别学习的骨干网络,并利用不同条件下生成的图像,学习到目标的主要特征以及精细特征.


图3 特征以及判别模型

(7)
(8)
(9)

Ladv=E[logD(xi)+log(1-D(G(ai,sj)))].
(10)
使用同一身份ID的任意两个图像之间进行图像的重构,如图5所示,以减少类内特征变化.给定图像xi,生成模块首先学习如何从自身重构xi.此外,生成器应该能够通过具有相同标识yi=yt的图像xt来重构xi,使用ID损失来区分不同的标识ID:
(11)
(12)
(13)
其中p(yi|xi)是图像外观编码属于真实标签类别的预测概率.

(14)

图4 不同ID生成图像示意图

图5 相同ID生成图像示意图
本文提供另一种方法来替代生成分支,通过模拟图像中行人目标的服装变化,来代替使用生成的数据,进行主要特征的学习,当对以这种方式进行训练时,判别模块能够学习与服装无关的细微的ID相关属性.把不同结构编码和外观编码组合生成的图像,视为提供结构编码的真实图像的同一类.对这个实现图像细微特征挖掘判别模块,使用标识ID 损失进行训练:
(15)
为了优化总的目标,使用以下损失的加权和,对外观编码器、结构编码器、解码器和判别器共同训练:
(16)

使用数据集生成的图像如图6所示,其中第1行为原始图像,第2行为使用两个同一身份ID图像重构的图像,同时保留了目标的外观和结构特征.其他为由两个不同ID的图像生成的图像,生成的图像出现服装配饰等方面的外观变化,保留目标自身的结构特征.

图6 Market-1501数据集生成图像示例
1.3 基于生成对抗模型的多目标路径预测算法
多目标跟踪的实际场景中,行人多目标的轨迹预测时需要考虑运动的实际情况,周围人的活动也会影响目标的行走路径.本文采用了基于生成对抗模型的多目标路径预测算法,应对复杂的人类交互,预测未来轨迹.算法基于生成对抗的编码器-解码器结构,并提出一种池化模块来模拟行人之间的相互作用.将目标与周围数个干扰目标的相对位置作为模块的输入,经过MLP和Max-Pooling处理,最终得到一个汇集了目标行人与周围行人位置信息的向量,以此模拟目标与周围人的交互.
本文的路径预测模型如图7所示,整体由3个主要部分构成:生成器、池化模块和判别器.生成器基于编码以及解码的LSTM框架,采用池化模块对编码和解码的隐藏状态进行连接.最后送入判别器进行判定轨迹是否为真.
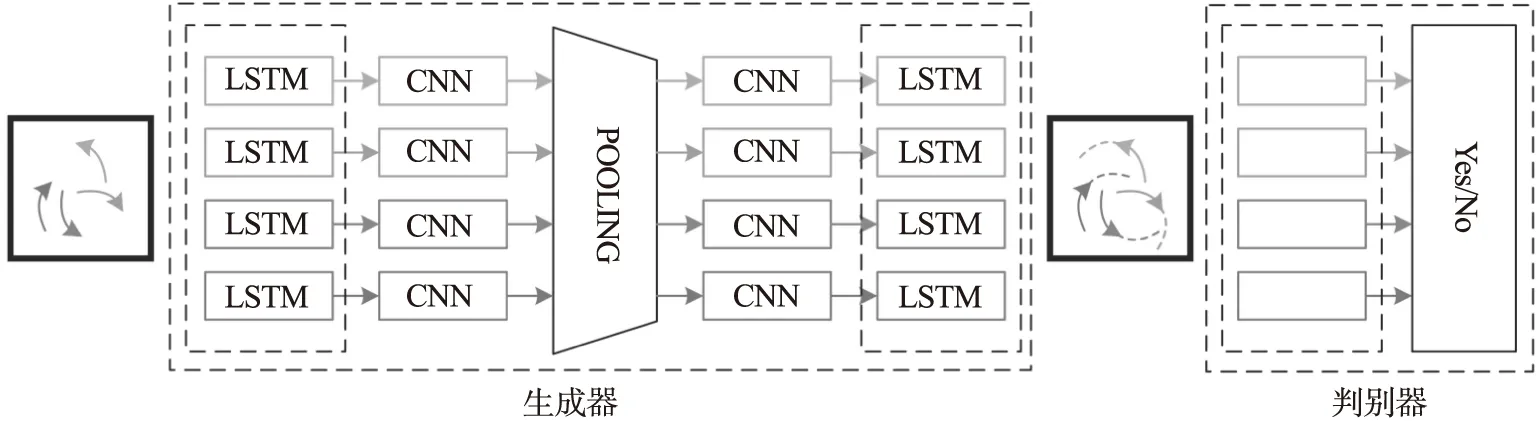
图7 基于生成对抗多目标路径预测

(17)
(18)
其中:t是序列;i是目标;φ()是具备ReLU非线性的嵌入函数;Wee是嵌入权重;Wencoder是LSTM的权重.
本文使用池化模块来模拟来往行人之间的交互作用,在可观测时刻之后,将场景中所有人的隐藏状态汇合起来,每个人获得一个合并的张量.通过初始化解码器的隐藏状态来调节输出轨迹的生成:
(19)
(20)
其中:γ()是包含ReLU非线性的多层感知器(MLP);Wc是嵌入权重,后续预测情况如下:
(21)
(22)
(23)
(24)
其中:φ()是具备ReLU非线性的嵌入函数;Wed是嵌入权重.
(25)
1.4 匹配模块
本文中采用的匹配模块首先对目标运动信息进行匹配,具体的做法为计算轨迹预测模块的结果与检测结果之间的马氏距离:
(26)
其中:d为第j个检测结果的位置;yi为第i个跟踪器对跟踪目标的预测位置;Si为检测位置和平均跟踪位置的协方差矩阵.设定阈值t(1),当此次关联的马氏距离小于它时,运动状态关联成功,关联度量为
(27)
在运动不确定度较高时,如长时间跟踪或出现长时间遮挡的情况,引入外观特征进行匹配.外观特征即人体框人脸框的联合特征.通过将每一个跟踪的目标的历史特征构造成一个特征库,存储最近成功关联的帧的特征,计算待匹配的特征与特征库特征之间的余弦距离最小值进行匹配:
(28)
如果最小距离小于设定阈值,则关联成功.使用两种度量的方式进行加权得到.运用组合距离阈值判断不等式,作为判断第i个目标跟踪结果和第j个目标检测结果之间是否关联的总公式:
c(i,j)=λd(1)(i,j)+(1-λ)d(2)(i,j),
(29)
(30)
可以看出,只有当c(i,j)同时满足两个度量的阈值的要求,才设定为完成了正确的关联.马氏距离度量对短时跟踪效果较好,外观特征度量对长时跟踪或长时间遮挡的情况更有效.可以针对不同的任务设定不同的λ进行适应.
2 实 验
2.1 与当前主流算法进行比较
本文使用MOT16[13]基准测试数据集评估了所提出的跟踪算法的性能,并与Deep Sort[7]、Sort[14]等先进算法进行了各项指标的对比.MOT16数据集具备多种多样的数据类型,具有在不同的视线角度、相机运动方式以及不同天气状况下拍摄的画面.根据MOT16的评估标准,实验结果如表1所示,多目标跟踪准确度(MOTA)指标位于第2名,多目标跟踪精确度(MOTP)最高,比第2名高了0.25%,比同类的基于深度学习的Deep Sort提高了1.64%.准确度(MOTA)与身份跳变数目(IDS)对比如图8所示,在不影响跟踪准确度的条件下,本文提出的算法身份交换和跳变明显少于其他算法.如图9所示,虚警数(FP)、漏警数(FN)明显降低.

表1 多目标跟踪算法跟踪结果
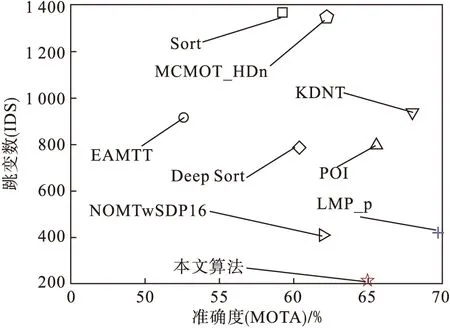
图8 准确度与身份跳变数对比

图9 漏警数与虚警数对比
2.2 实施细节
本文算法框架中的目标检测模块、特征提取模块、路径预测模块在目标检测数据集ImageNet、行人重识别数据集 Market-1501、行人视频数据集Eth中分别进行训练,得到最优的权重后再融入到整体的框架中.目标检测模块中lossw_h采用均方差误差,其他的损失为交叉熵损失,并采用L1正则化.
在特征提取模块的整个训练过程中固定权重λimg=5,λid=0.5.用作区分特征学习损失Lprim和Lfine,直到生成器稳定下来.本文模型在Market-1501上进行30 000次迭代后,再将两个损失求和,随后的4 000次迭代中把λprim从0线性增加到2,并设定λfine=0.2λprim.
在跨身份(不同ID)图像生成中,在生成图像之前训练Ea,Es和G,在生成图像之后训练Ea,Es和D.实验发现匹配模块中马氏距离匹配阈值取9.487 7最佳.外观特征采用人体框人脸框的联合特征,其中人体框特征包含人体的主要特征和细微特征,人脸特征作为补充进行融合.将每一个跟踪目标的历史特征构造成一个特征库,将最近100个成功关联的帧的特征进行存储,计算待匹配的特征与特征库特征之间的余弦距离最小值进行匹配.
2.3 消融实验
为进一步分析所提方法各部分的有效性,在基于普通人体特征和卡尔曼滤波跟踪器的基础上,设计了消融实验来对算法框架中的各个部分进行对比分析,结果如表2所示.
通过对比准确度与身份跳变指标,在检测跟踪过程中增加了人脸特征之后,跟踪器的准确度有所提升,身份交换和跳变情况有了明显的缓解.进一步应用通过生成对抗网络提取的增强人体特征代替普通人体特征,多目标跟踪的准确度基本不变,但是身份交换和跳变数目降低了23%.最后再用基于生成对抗网络的路径预测模块代替传统的卡尔曼滤波算法,可以看出本文改进的算法在身份交换和跳变数目上进一步降低26%,达到最低.

表2 消融实验结果
本文算法通过增加人脸特征,提高了检测的准确性;通过引入主要特征和细微特征结合的增强人体特征,增强了图像特征的表现力;应用基于生成对抗网络的路径预测算法生成目标轨迹,得到目标更准确的位置序列.有效解决了现存算法中,检测结果与跟踪路径不匹配,身份变换频繁的问题.
2.4 定性分析
图10为本文算法在MOT数据集中一段视频序列上跟踪的实验结果.图10所示的序列中,行人目标背景较为复杂,目标数量较多,目标间存在着频繁的交互.目标运动过程中发生了由远及近和由近及远的变化,使目标尺度发生改变.目标还出现了遮挡现象,以及随后消失又重现的情况.如图10所示,本文取得了良好的跟踪效果.在背景复杂、目标遮挡、尺度姿态变化的应用场景中,有极大的抗干扰能力,有效解决了跟踪偏移和匹配错误的问题,实现目标平稳跟踪.

图10 MOT序列跟踪结果
3 结 论
本文针对多目标跟踪中背景复杂、目标遮挡、目标尺度和姿态变化情况下,容易出现目标丢失、身份交换和跳变的问题,提出了一种基于生成对抗网络的多目标跟踪算法.通过使用基于YOLO的人体人脸关联算法,对当前帧待检目标进行检测,提出了基于生成对抗网络的特征提取模型,且引入了人脸特征,使对目标的特征表示更加鲁棒.再使用生成对抗网络生成复杂交互下更准确的多目标的运动轨迹,在匹配模块中结合目标的运动信息和外观信息,得到最终的目标跟踪结果.实验结果表明,在出现背景复杂、目标遮挡、尺度变化等干扰情况时,本文算法都能平稳且准确地对目标进行跟踪,且大幅度减少了目标身份跳变情况的发生,具有较高的精确度.
