区域政务微博知识图谱构建及可视化研究
2020-12-17高晨翔黄新荣
高晨翔 黄新荣


收稿日期:2020-04-23
基金项目:国家社会科学基金项目“社交媒体文件的归档与管理标准体系研究”(项目编号:16BTQ093)。
作者简介:高晨翔(1994-),男,博士研究生,研究方向:数字信息资源管理、数字记忆。黄新荣(1967-),男,教授,博士,硕士生导师,研究方向:信息资源管理、电子文件管理。
摘 要:[目的/意义]借助知识图谱对区域政务微博内容进行知识组织与可视化展示,能够提升用户的知识阅读及获取效率。[方法/过程]首先,基于LDA模型对区域政务微博进行主题建模,通过依存句法分析对微博内容进行语义三元组抽取。其次,构建了区域政务微博知识模型,形成了知识图谱的语义架构。最后,借助图数据库Neo4j及D3.js插件实现了区域政务微博的知识图谱可视化及关联化保存。[结果/结论]经理论构型与实际验证,本研究构建了基于主题划分的区域政务微博知识图谱,为社交媒体内容的知识图谱构建提供了一定的思路及方法。
关键词:区域政务微博;知识图谱;知识组织;知识可视化
DOI:10.3969/j.issn.1008-0821.2020.12.010
〔中图分类号〕D035-39 〔文献标识码〕A 〔文章编号〕1008-0821(2020)12-0090-10
Knowledge Graph Construction and Visualization of
Regional Government Microblog
Gao Chenxiang1 Huang Xinrong2
(1.School of Information Resource Management,Renmin University of China,Beijing 100872,China;
2.School of Public Management,Northwest University,Xian 710127,China)
Abstract:[Purpose/Significance]Regional government microblog can record and reveal some hot events closely related to the public.This paper builds the knowledge graph of regional government microblog to improve users knowledge acquisition efficiency.[Method/Process]First,this paper captured contents of government microblogs and built a topic modeling using LDA.At the same time,we extracted the semantic triples from aforementioned contents by LTP.Second,the applied ontology of regional government microblog wes built to form the semantic structure of knowledge graph.Ultimately,Neo4j and D3.js were used to constructing,preserving and visualizing the knowledge graph.[Result/Conclusion]Based on the theoretical and practical research,we built knowledge graphs of regional government microblog,combing the semantic relations between organizations,figures and terms in microblogs contents.This paper provides thoughts and methods for the construction of knowledge graph in social media field.
Key words:regional government microblog;knowledge graph;knowledge organization;knowledge visualization
社交媒體(Social Media)已成为新一代互联网服务体系中最具发展潜力和增长空间的服务模式之一[1]。利用社交媒体实现社会信息的发布、接收与传播,已经成为各类社会组织和个人在工作与生活中的常态行为。在我国,政务微博是国家机关利用社交媒体创新政务信息服务的重要形式,是我国公民在线获取政务信息资源的关键渠道。据《2019年上半年人民日报·政务指数微博影响力报告》显示,截至2019年6月,我国经新浪官方平台认证的政务机构微博数量已达173 569个[2],通过政务微博发布或转发权威信息、处理相关业务、倾听社情民意是政务微博的核心功能。政务微博信息源于微博管理者在特定的社会关系框架下对某一事件的理性判断与直接记录,这一过程赋予了政务微博信息的基本价值。
然而,社交媒体带来的信息过载问题也给政务机构、社会公民的信息活动造成了困扰。一方面,政务微博的更新发布频率和信息叠加速度与微博用户的线性浏览能力形成了矛盾,影响了用户阅读、吸收信息的效率;另一方面,受政务机构的科层模式与职能分工影响,政务微博的信息发布往往具有地域性、重复性和分散性特征[3]。内容相近却又相互孤立的碎片化政务微博信息对政务信息资源管理、开发及利用均造成负面影响。因此,实现政务微博的知识组织,确保用户高效地吸收外界政务信息资源,是政务微博信息资源开发利用的核心要务。
当前,知识图谱已成为图书情报学界的研究热点,并在历史资料、文学名著以及其他人文资料的组织、检索与知化方面得到了有效应用[4]。本研究立足于特定的行政区域,借助知识组织与知识可视化技术,实现区域政务微博的知识图谱构建,挖掘海量政务微博信息的知识内涵,促进政务微博的知识显化,为特定区域内政务微博的知识组织、知识发现与知识可视化研究提供一定的参考。
1 研究基础
1.1 概念界定
区域政务微博是本文的核心研究对象,涉及区域政务微博账号及微博文本内容两部分。从节点视角看,区域政务微博账号是区域内某一具体的政务机构存在于微博平台上固定的身份表征,其在微博平台上的信息发布、评论、转发、关注及点赞等活动可以视为是机构意志的具体体现。从内容视角看,“区域”概念是促使政务微博主题集聚的原因之一,区域内的政务机构以各自职能为基础,利用微博发布的信息带有明确的“区域性”特征。
在我国的区域政务微博体系中,某区域最受关注的综合性政务微博“××发布”在区域政务微博网络中居于核心地位,环绕其周围的各类职能机构政务微博则重点发布诸如城市旅游、社会安全、气候环境等专门性信息,二者相结合形成区域内模块化的网络结构。微博平台内的主题组织功能则在客观上为区域内政务微博提供了信息集聚的空间,不同的政务微博借助特定区域所发生事件的主题标签发布、转发或评论有关同一事件主题的信息内容,这些内容因事由而相互关联,均是从不同侧面对区域内发生事件基本情况的反映。主体与内容相统一的“区域政务微博”概念为政务微博的知识组织与知识图谱构建提供了可行的概念基础与操作范围。
1.2 相关研究
Moniz N等[5]收集了葡萄牙国内19个政府机构共776位公务人员的社交媒体数据,利用社会网络分析对葡萄牙政府社会网络的基本特征进行了度量,形成了政府社交媒体知识图谱,衡量了该国政府社会网络的稳定性。Rong Y H等[6]以“参与式预算”为主题构建了中国部分地区政府机构及工作人员官方微博在事件处理与评论中组成的社交图谱,发现政务微博网络在结构方面具有小世界效应。Yarosh S等[7]构建了基于GIS和知识图谱技术的交互式网站,能够处理政府和公民的Twitter数据并进行事件识别、地理编码、关系构建等功能。Kalloubi F等[8]将图中心算法与开放关联数据相结合,探究了Twitter数据的命名实体链接与语义消歧问题,形成了基于Twitter关联数据的知识图谱。
国内方面,蹇洁等[9]主要从度、聚类系数和平均路径长度3个维度对重庆市917个政务微博账号间的关联关系进行分析,形成了微博账号间的关系图谱。崔金栋等[10]选取江苏省和吉林省的政务微博进行“核心-边缘”分析及“凝聚子群”分析,通过知识图谱构建发现我国发达和欠发达地区的政务微博均没有明显的集中趋势。杜亚军等[11]對微博知识图谱构建方法进行了综述,认为微博知识图谱应包括人物、事物、地点、事件和话题5类实体及实体间的多维语义关系。孙驰[12]基于寻径网络算法,在抓取微博热点话题的基础上构建了以人物实体为核心节点、以人物相关实体为辅助节点的知识图谱。
综上可见,国内外以政务社交媒体为对象的知识图谱构建研究多采用社会网络分析方法,形成的
图谱类型应为“知识地图”而非“知识图谱”,尚未构建反映节点与内容间语义关系的知识图谱,也没有将本体、关联数据等基于开放域的知识组织技术融入研究中,这为本文提供了一定的研究与探索空间。
2 区域政务微博知识图谱的构建方法
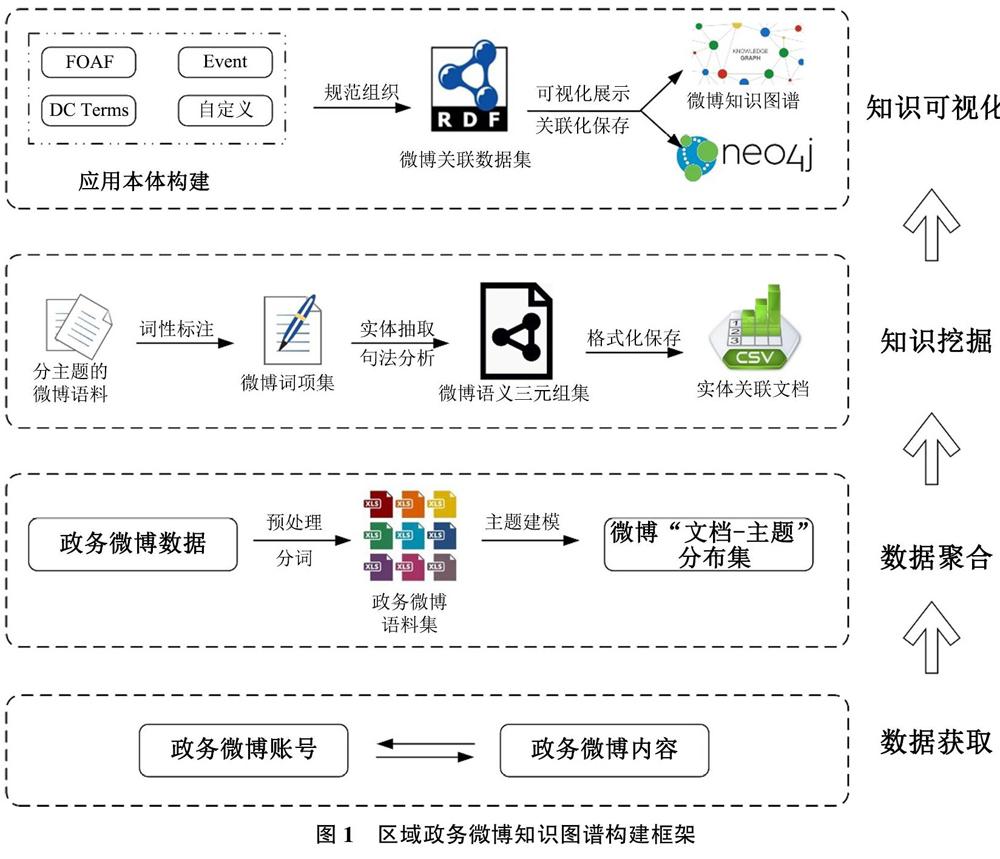
2.1 研究框架
本文提出了如图1所示自底向上的知识图谱构建框架。数据层面,本研究通过数据采集、预处理与分词得到区域政务微博语料集;借助主题建模算法形成具有“文档-主题”以及“主题-关键词”分布形式的微博聚类集合。在知识挖掘与可视化层面,实现了政务微博内容的词性标注、命名实体识别及依存句法分析并完成微博语义三元组的提取。此外,本文在复用FOAF、DC Terms及Event等本体的基础上结合自定义类目构建区域政务微博的轻量级本体,对所得的微博语义三元组进行规范关联,最终借助图数据库Neo4j及其内置的D3.js插件实现区域政务微博知识图谱的构建、保存及检索。
2.2 数据聚合:区域政务微博主题建模
2.2.1 数据准备
本文选择陕西省西安市作为区域实例,构建西安地区政务微博在特定主题下的知识图谱。为确保实证研究的科学性和完整性,本文采用了成熟的网络爬虫工具集搜客,以新浪微博话题广场为单位对区域政务微博数据进行抓取。
经过内容比较与分析,本文选取了“第三届中法文化论坛”和“创新创业在西安”两个热点话题,两个话题均带有HashTag(#),话题内文本数量较为充裕且主题特征明显。具体而言,我们共抓取了246条微博文本,其中“第三届中法文化论坛”专题共171条,“创新创业在西安”专题共75条,采集时段为2019年6月15日至6月20日。通过定题采集,能够将某一话题内各类博文的博主名、博主ID、文本内容、发布时间及源网址等核心字段依对应关系进行保存,为其后的数据分析、挖掘与可视化实验建立了数据基础。
2.2.2 基于LDA的区域政务微博主题建模
既有的领域知识图谱构建研究通常采用实体识别及模板匹配的形式[13]对所得语料直接进行实体及关系抽取,这样获得的[实体1,关系,实体2(属性)]三元组涵盖了一次实验所需的全部语料,适用于专业领域的知识图谱构建。与语料相应,本文拟构建的区域政务微博知识图谱涉及不同话题需要以主题为实现知识图谱的精细化展示,因此提出一种基于主题模型的知识图谱构建方案。
目前,LDA模型在微博等中文短文本的主题建模与聚类任务中具有广泛应用,且效果良好[14]。LDA模型由Blei D M等学者[15]于2003年正式提出,该模型基于词袋假设(Bag of Words),其核心理念可表示为:一篇文档(Document)是由多个主题(Topic)混合而成的,而每一个主题都是词汇(Word)上的概率分布,文章中的每个词都由一个固定的主题生成,其数学表达式如下:
P(w|d)=∑tP(w|t)P(t|d)(1)
其中变量w、t、d分别代表词汇、主题及文档,即“文档-词汇”的概率分布能够表示为“文档-主题”与“主题-词汇”的联合概率分布。“文档-词汇”分布通过词频统计算法可以得出,以此为基础通过Gibbs采样算法估计d(文档中主题的概率分布)与k(主题中特征词的概率分布)两个参数。结合所得的区域政务微博语料,“第三届中法文化论坛”与“创新创业在西安”两个话题的主题建模过程及结果相对明确,但话题本身依时间推移而演化出不同的子话题,本文将其命名为“事件”,以“事件”为单位的主題建模是本文LDA模型应用的重点。
定义θ=[θ1,θ2,…,θd]为包含两个主题的文档全集,经过第一轮主题建模与划分(即主题数T=2)后,“第三届中法文化论坛”与“创新创业在西安”两个主题下的“文档-主题”采样集合分别为θi=[θi1,θi2,…,θis](1≤s θd,k=(nd,k+αk)/∑Ki=1(nd,i+αi)(2) φk,w=(nk,w+βw)/∑Ki=1(nk,i+βi)(3) 其中,θd,k表示在第k个主题与文档d形成的采样向量,体现了文档d中主题k的概率,φk,w代表主题k中特征词w的概率,K为潜在主题数,α和β均为隐含狄利克雷分布超参数。在模型参数的设置方面,本文采用专家咨询法结合困惑度判断法,设定主题数K=4,Gibbs抽样迭代次数i=500对模型进行训练,最终抽取各个主题及事件中TF-IDF值排名前10的特征词项,如表1所示。 经过LDA主题建模的区域政务微博语料以特征词项为主要表现形式,该方法将此前原始的非结构化文本转换为承载句子及语篇语义信息的词项集合。一方面,经过聚类计算得到的特征词项为区域政务微博知识图谱的主题划分与分步构建奠定了基础;另一方面,主题建模形成的特征词项能够作为命名实体以及相应的实体标志词,提升领域实体识别的准确率。 2.3 知识挖掘:区域政务微博实体及关系抽取 2.3.1 政务微博文本依存句法分析及其规则定义 依存句法分析(Dependency Parsing)旨在根据词性及词间位置特征来判断句中词语之间的语法依存关系。具有依存关系的两个词组成一个依存对,其中一个词是起支配作用的核心词;另一个是起修饰作用的从属词。图2以本研究采集的语料为例展示基于LTP的政务微博文本依存句法分析过程[17]。 图2中,“宣布”这一谓语动词被模型识别为“根词项(Root)”,其余词项间以依存弧为纽带结成了不同的语法关系。在应用依存句法分析时,通常以“键值对”的形式表现词间关系,如图2识别出的“陕西省”“省长”及“宣布”3词按照规则可分别表示为{2:‘ATT,3:‘SBV,0:‘HED}。LTP的依存句法分析模型共定义了包括“主谓关系(SBV)”“动宾关系(VOB)”等在内的14种语法关系,而“键值对”的表现形式使得本研究能够以字典为存储和管理容器、以索引和依存关系为基础实现词项定位,通过相关规则的设置抽取语义三元组,其中抽取规则如表2所示。 2.3.2 基于命名实体识别的三元组辅助抽取 基于依存句法分析的实体关系抽取规则依赖于句中存在的谓词及介词,当以谓词为代表的关系表述中含有“论元”时[18](关系表述左右两边最近的两个名词或短语),借助依存句法分析往往能够比较明确地提取出语义三元组;当关系表述中不存在论元或关系表述本身不明确时,基于依存句法分析的三元组抽取往往会遗漏相应的实体及其关系。因此,本研究通过命名实体识别辅助抽取区域政务微博三元组。 本文关注的政务微博内容以区域内热点事件为主题,其中涉及的人名、地名与机构名是构成知识图谱的基本实体。LTP平台在命名实体识别中采用了“B-I-E-S-O”标注体系,基于该体系的符号表达能够对人名(Nh)、地名(Ns)和机构名(Ni)等命名实体进行标注。在模型的训练及应用方面,本文通过人工标注的形式,将主题建模部分所得的特征词构建外部字典并嵌入LTP命名实体识别模型中,以提升命名实体识别的准确度。经过依存句法分析及命名实体识别抽取出的区域政务微博文本三元组如图3所示。 抽取所得的区域政务微博语义三元组表现为“(实体,关系,实体)”这一形式。对于抽取的三元组结果,本研究对其中表义模糊的实体进行了查找剔除,最终得到102个实体及其关联的51种语义关系,我们将所得实体及其语义关系由最初的txt格式转换保存为“(头实体,尾实体,关系)”的csv格式,以便在本体建模完成后将实例批量导入本体。 2.4 知识组织:基于本体的区域政务微博数据关联 经过抽取得到的区域政务微博语义三元组在形式与内容的规范性方面还有所不足。其一,同类或同义谓词出现次数较多,为后续的知识增量与知识融合带来不便;其二,三元组实体的对象及数据属性可以进一步扩充,以完善知识图谱的内容;其三,纯文本格式的三元组直接发布形成的知识图谱不具备较强的数据交换与复用能力,无法融入开放知识域或关联数据集。 基于此,我们构建了复合型的区域政务微博轻量级本体。本文复用了DCMI Terms[19]、FOAF[20]、CIDOC Conceptual Reference Model[21]以及Event[22]等已在图书情报学界得到广泛应用的本体,借鉴其部分概念及属性。为了在细粒度环境下阐释区域政务微博实体间的语义关系,本文还对部分概念及属性进行了自定义,最终得到的实体类目结构如表3所示。
区域政务微博本体模型包括8个类目和9个对象属性,其中“区域”(Region)及“行为言论”(Behavior & Opinion)两个实体为自定义类目。本文借助Protégé本体建模工具实现了区域政务微博本体结构的可视化,如图4所示。通过将前文得到的微博语义三元组及捕获的其他属性信息批量导入本体,使其成为实体概念的实例或属性的数值即形成了特定主题下区域政务微博的知识图谱。
3 区域政务微博知识图谱可视化
在知识可视化环节,本研究利用Neo4j数据库内置的D3.js可视化插件及Cypher查询语言实现微博知識图谱的呈现与检索,所得知识图谱能够从宏观结构及微观涵义层面综合反映特定区域内政务信息资源主体、事件及文本内容间的语义关系。
图5从宏观角度切入,展示了采集数据中包含的区域政务微博账户、主题、事件、地点等实体间的关联关系。图中红色节点分别代表“第三届中法文化论坛”与“创新创业在西安”两个区域政务微博主题,“主题-事件”之间的“包含(隶属)”关系及事件之间的“相关”关系借助相应的有向边予以表示。蓝色节点代表政务微博账户,其相互之间的“关注”及政务信息的“发布”关系均包含在图谱内。最后,灰色节点“西安”以“发生地”这一关系同既有主题及事件相连,体现了政务微博信息在经过知识化“萃取”后仍保有地域聚合特征。
微观视角下的区域政务微博知识图谱着重关注微博内容及其中包含的命名实体间的关系,尤其是以主题或事件为导向的人物及其行为关系。图6体现了“创新创业在西安”这一主题之下的各类人物及行为活动,包括行政官员的调研活动以及微博中提及的每一位创业者的具体创业事迹,从而将不同微博账户发布的离散文本聚合在同一张图谱中,集中反映某一主题或事件的核心内涵。相应地,图7对政务微博数据中的另一主题——“第三届中法文化论坛”的相关内容进行了可视化揭示,该图谱有效展示了位于不同时段、隶属不同事件但均参与了“第三届中法文化论坛”活动的相关人物及其言论。
与此同时,结合Neo4j数据库内置的Cypher语言,以图谱节点及其相应的语义关系为纽带可以实现政务微博知识图谱的查询检索。如要检索法国前总理让·皮埃尔·拉法兰在“第三届中法文化论坛”中的相关言论及活动,则输入相应的Cypher查询语句进行匹配,图8显示了拉法兰参与“第三届中法文化论坛”的所有活动及发表的言论。
总体而言,构建区域政务微博知识图谱能够将特定时空范围内相互关联的微博内容聚焦于简单生动的可视化图形中。从用户视角看,区域政务微博知识图谱方便用户以“遥读(Distant Reading)”形式把握所在区域的某一热点话题及事件的核心要
素,无需用户在不同政务微博账户之间不断切换,提升了用户对网络政务信息资源的知识利用效率。从政务微博管理者视角看,区域政务微博知识图谱是其发布各类政务信息的主题化、知识化凝练,较为清晰地反映了主题事件的发展与演化态势,为管理者后续的信息发布、舆论引导与关键数据保存等工作提供了一定借鉴。
4 结 语
本研究采用自底向上的知识图谱构建方案,经过数据获取、数据聚合、知识挖掘及知识可视化等过程实现了区域政务微博知识图谱,同时对图谱的呈现与检索形式进行了实证与讨论,借此对以政务微博为代表的网络政务信息资源开发利用模式进行了探索。本次研究及实验使得隶属于特定行政区域、反映区域内热点话题及事件的政务微博内容完成了以“离散化数据—结构化信息—可视化知识”为主线的上升与转变,从而将主题模糊、相关性弱的文本数据逐步转化为主题清晰、关联性强的知识内容,实现了相关主题内的知识聚合[23]。
与此同时,本研究在两个方面还存在较大的提升空间。首先,本次研究及实验利用了主题建模、依存句法分析、本体等自然语言处理及知识组织技术实现了区域政务微博知识图谱,但尚未将以上技术进行有机整合,在今后的研究中,笔者将进一步探索构建集成式的政务微博知识图谱服务平台[24];其次,本文构建的区域政务微博知识图谱仍处于探索与实验阶段,在数据量与数据类型方面尚较为单一。政务微博除文本内容之外,其附属的图像、视频以及相应的用户评论等数据内容也具有一定的信息价值。因此,本研究将进一步提升区域政务微博知识图谱的表现力、数据关联与知识定位能力,从而实现基于政务微博大数据的知识挖掘、知识推理及语义检索,提升区域政务微博知识图谱的利用价值。
参考文献
[1]Obar J A,Wildman S.Social Media Definition and the Governance Challenge:An Introduction to the Special Issue[J].Telecommunications Policy,2015,(39):745-750.
[2]人民网.2019年上半年人民日报·政务指数微博影响力报告[EB/OL].http://yuqing.people.com.cn/NMediaFile/2019/0812/MAIN201908121245000526967515030.pdf,2020-05-17.
[3]黄新平.政府网站信息资源多维语义知识融合研究[D].长春:吉林大学,2017.
[4]刘炜,叶鹰.数字人文的技术体系与理论结构探讨[J].中国图书馆学报,2017,(5):32-41.
[5]Moniz N,Louca F,Oliveira M,et al.Empirical Analysis of the Portuguese Governments Social Network[J].Social Network Analysis and Mining,2016,6(1):1-19.
[6]Rong Y H,Song J.Mining a Government Affairs Microblog Network on Sina Weibo with Social Network Analysis[C]//10th International Conference on Fuzzy Systems and Knowledge Discovery(FSKD).Yantai:IEEE,2013:515-519.
