基于深度学习模型的图像识别应用研究
2020-12-16张宝燕
张宝燕
(晋中学院,山西 晋中 030600)
0 引言
如今,图像识别由于其广泛的应用而成为一个重要的研究领域。对于手写分类等图像识别问题,特征提取的好坏对提取结果至关重要。针对手写体字符识别问题,Huang等人[1]从笔画中提取出字符的结构特征,并将其用于手写体字符的识别。Rui等人[2]采用形态学方法改进字符的局部特征,然后利用PCA提取字符的特征。这些方法都需要手动从图像中提取特征。模型的预测能力对建模者的先验知识有很强的依赖性。在计算机视觉领域,由于特征向量的高维性,手工特征提取非常繁琐和不切实际[3]。
近年来,大多数分类和回归机器学习方法都是浅层学习算法。复杂函数难以有效地表示,对于复杂的分类问题,其泛化能力有限[4,5]。
为了克服浅层表示和人工提取特征的问题,Hinton等人在2006年提出了深度学习[6]。深度学习的本质是通过建立多层模型并用大量的数据对其进行训练来实现自我学习。深度学习方法是一种具有多层表示的表示学习方法,通过组合简单但非线性的模块,每个模块将一个级别的表示转换为更高、更抽象的表示。有了足够多的这样的变换组合,就可以学习非常复杂的函数[7]。
1 卷积神经网络
1.1 卷积神经网络模型介绍
图1是一个简单的卷积神经网络模型。第一层是输入层,输入的图像直接输入到输入层。第二层是BN层,它主要是对卷积层提取到的特征进行归一化处理。可以改善流经网络的梯度,允许更大的学习率以及大幅提高模型的训练速度。第三层是池化层,它计算输入要素图的局部平均值或最大值,主要作用是进行特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。接下来的卷积层,BN层和池化层以相同的方式运行。最后输出层是全连接层,输出神经元的最大值是最终分类器的结果。
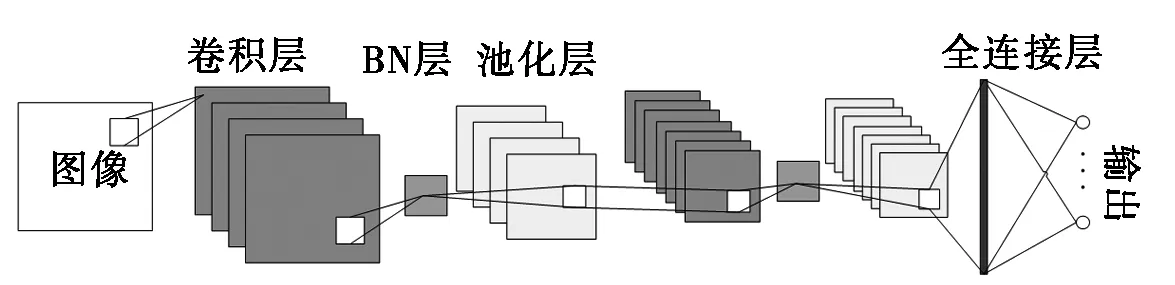
图1 卷积神经网络模型
1.2 卷积神经网络理论
卷积层使用卷积核对输入信号的局部区域执行卷积运算,从而产生相应的特性。权重共享是卷积层的最重要特征,这意味着当每个卷积窗口遍历整个图像时,卷积窗口的参数是固定的。这样可以避免因参数爆炸而导致的过拟合现象,并减少系统训练网络所需的内存。以第一层为例。如前所述,要素图中的所有单位共享相同的权重集和相同的偏差,因此它们在输入的所有可能位置上都保留相同的要素。卷积过程描述为:
(1)

批量归一化(BN)层旨在减少内部协方差的偏移,加快深度神经网络的训练过程,提高网络训练效率并增强网络泛化能力。转换过程描述为:
(2)
式中,γl(i)和βl(i)分别是BN层的标度和偏移量,zl(i,j)是BN层的输出,ε是保证数值不为零的常数项。
在CNN体系结构中,通常在批处理规范化层之后添加池化层。神经网络操作的主要目的是降低采集层的参数,本文选择的最大池化层转换描述为:
(3)
通过反向传播算法和随机梯度下降算法训练搭建的卷积神经网络。我们假设训练样本总数为N,则CNN的损失函数可以表示为:
(4)
损失函数相对于卷积核系数和偏差的梯度为:
(5)
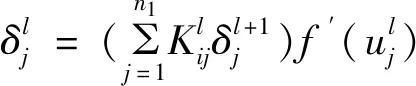
(6)
2 实验验证
2.1 实验数据
我们选择MNIST手写数字数据库来比较深度学习的性能。MNIST数据集来自美国国家标准与技术研究所,整个数据集由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局的工作人员,这说明了数据很分散,可以充分验证模型的识别能力。MNIST包含60 000个训练样本和10 000个测试样本,图像大小为28×28。一些来自MNIST手写数据库的真实样本集如图2所示。
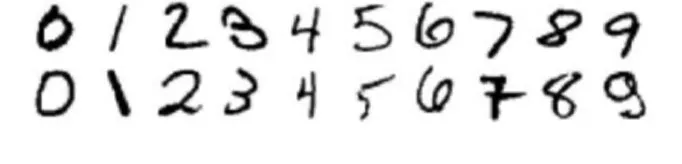
图2 MNIST数据库部分真实样本
2.2 实验结果对比
首先为了验证不同卷积核个数对卷积神经网络识别精度的影响,以及为了观察卷积内核的数量如何影响整体性能,我们选择了三种不同的卷积神经网络:784-4-12,784-8-24,784-16-48。其中784是输入数据的维数。中间的两个数字分别为第一个卷积层和第二个卷积层的内核数。三个不同卷积神经网络的识别精度如表1所示,当预测值与地面真实性之间的均方误差小于0.001时,我们假设网络达到收敛。从表1中我们可以看出,MNIST数据库上三个CNN的准确率非常的高,均达到了九十五以上。取得上述结果的原因是MNIST数据库中包含有大量的训练样本,足够卷积神经网络提取到充分的关键特征。

表1 不同卷积核数量的卷积神经网络结果对比
由表1的对比结果可知,当内核数从4、12增加到8、24再增加到16、48时,基于MNIST数据集的准确率不断增加,从最初的97.31%增加到97.48%,最后增加到97.71%。上述的对比结果表明,如果训练样本的数量能够完全满足学习方法的要求,则随着核数的增加,从CNN提取的特征数量将增加,并且CNN的识别性能会越来越好。
为了充分验证卷积神经网络的识别效果,本文选择利用人工神经网络以及深度置信网络进行对比,其中人工神经网络为浅层神经网络,深度置信网络为深度学习网络,可以充分验证所搭建卷积神经网络的图像识别能力。其中,在该组实验中,卷积神经网络的结构为784-16-48,学习率为0.01,人工神经网络的结构为784-100-10,学习率为0.05,深度置信网络的结构为784-150-100-10,学习率为0.1。实验结果对比如表2所示。图3展示了所有网络的错误率随着迭代次数的变换情况。

图3 网络的错误率随着迭代次数的变化结果

表2 所有模型的识别对比结果
实验结果表明,与浅层人工神经网络相比,CNN和DBN在MNIST数据库都具有较高的准确率。此外,深度学习可以主动学习数据的固有特征,而不是手动提取特征。但是,深度学习在实际应用中的成功取决于标记的数据。比较表2中的实验结果,我们可以了解DBN和CNN之间的主要区别:DBN属于无监督学习方法,是一种生成深度模型;而CNN属于监督学习方法,是一种歧视深度模型。DBN通常适用于一维数据建模,如语音;,而CNN更适用于二维数据建模,如图像。CNN本质上是输入和输出的映射。它可以学习很多映射关系,不需要任何精确的数学表达式,而DBN则需要建立可见和隐藏单元之间的联合概率分布,以及可见和隐藏单元的边际概率分布。从实验结果可知,在图像识别方面,CNN拥有着得天独厚的优势。
2.3 结果可视化
为了直观地理解所提出的卷积神经网络的特征学习过程,利用t分布随机邻居嵌入(t-SNE)对不同迭代步数阶段学习到的深度特征进行网络可视化。本文总共选取了最初状态、迭代十次、迭代五十次以及最终迭代得到的深度特征,如图4所示。

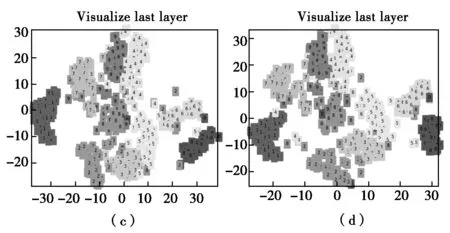
图4 可视化结果
从图4可知,原始数据的十种类别随机的混合在一起,很难清晰地将其分开。当迭代十次之后,比最初的原始数据辨识度稍微好些,但仍然很难直接将其分开。随着迭代的继续进行,当达到五十次后,十种类别的辨识度更高了,基本可以分开,当达到最终迭代效果后,所有类别都可以完全清晰地分开。这体现了卷积神经网络随着迭代的不断进行,学习到的特征也越来越有代表性。
3 结论
本文将深度学习应用于实词手写字符识别,获得了良好的图像识别性能。通过比较实验结果,分析了卷积神经网络的特征提取过程。深度学习可以通过深度非线性网络模型来近似复杂函数。它不仅避免了手动提取特征的繁重工作,而且更好地描述了数据的潜在信息。未来我们将进一步研究深度学习的优化,并将其应用于更复杂的图像识别问题。
