基于图的联合特征实体链接方法
2020-12-10朱永华张铁男邢毅雪
周 金, 朱永华, 张铁男, 邢毅雪, 张 克
(1. 上海大学上海电影学院, 上海200072;2. 上海大学计算机工程与科学学院, 上海200444)
在“信息泛滥-知识匮乏”的网络大数据情境下, 针对如何排除冗余和噪声知识以及精准挖掘目标信息, 给人们带来了极大的挑战. 而伴随着知识库的持续扩增和知识图谱的新兴发展,如何对多源异构数据进行数据融合, 丰富碎片化知识关系, 实现知识图谱的自动构建, 都成为了当下亟待解决的难题, 其中不可避免要涉及的问题就是自然语言表达的多样性与歧义性, 具体而言即是同一实体可能存在多种不同表达形式(多词一义), 而同一表达可能指代多个不同的实体(一词多义). 因此, 实体链接便成为了解决这一问题的关键.
实体链接(entity linking)是指将从网络大数据文本中获取的实体指称链接到知识库实体的过程. 例如, 给出一段文本“······把苹果削皮去核, 取果肉 ······”, 实体链接的工作是将文本中的实体指称项“苹果”与知识库中的水果“苹果”相链接, 而不是将其链接到iPhone“苹果”、歌曲“苹果”, 或者电影“苹果”. 实体链接不仅能够增强阅读体验, 帮助人们和计算机更深入地理解目标信息的含义, 而且可以形成以实体为中心的精准信息聚合体系, 推动领域知识库的发展. 实体链接在搜索引擎检索[1]、知识图谱自动构建[2]、知识融合[3]等领域都有着重要的应用前景和研究意义.
本工作提出了一种基于图的联合特征实体链接方法, 利用主题模型对主题相似的文档进行聚类, 以获取更丰富的上下文信息并实现批量处理实体指称链接; 选取核心的特征(上下文、元数据等)计算生成重启随机游走的初始边权重; 综合考虑全部实体相互之间的相关度, 利用一致性模型进行联合消歧, 以实现实体链接的目标.
1 相关工作
本工作通过对已有研究的调研与分析, 从考虑实体特征范围的角度, 将实体链接方法分为小局部链接方法、局部链接方法和全局链接方法.
小局部链接方法在属性信息丰富且没有干扰项的情况下, 只考虑实体指称与候选实体之间的名称属性相似度计算, 有借助编辑距离(edit distance)、Dice 相似性系数(Dice coefficient score)、汉明距离(Hamming distance)等的字符串相似度方法[4]和利用词典的实体语义相似度计算方法[5].
局部链接方法则在文本环境下分析单个实体指称与候选实体之间的相似度, 忽略实体指称项之间的内在联系, 有基于实体知名度的方法[6]、基于上下文相似度的方法[7]和基于概率生成模型的方法[8], 其中基于实体知名度的方法虽然是一种相对比较可靠的方法, 但是该方法将结果固定在同一个候选实体上, 对于特殊情况不是很合理; 基于上下文相似度的方法作为最普遍的方法, 在两个文本中必须出现重叠词这一严格框架下, 无法保证计算准确率; 基于概率生成模型的方法则需要大量统计数据作为支撑. 与此同时, 这些上下文相关的方法只是以实体知识库信息作为特征, 没有考虑到实体指称项之间的内在联系.
全局链接方法认为, 在同一文本中出现的实体指称之间是相互关联的. 该方法通过捕捉实体间的语义关系, 协同链接文本内所有提及的实体指称, 以实现批量实体链接效果, 有基于语义相似度的方法[9]、基于图的方法[10]、基于主题模型的方法[11]和基于深度神经网络的方法[12]等.
Han 等[13]首先提出图模型的思想, 在全部实体范围内, 同时计算上下文相似度与语义相似度, 利用随机游走排序, 从而得到目标结果; Hoffart 等[14]构建包括先验、上下文、聚类在内的加权图, 选择出一个候选实体的密集子图作为目标; 李茂林[15]则在文献[13]的基础上加入了主题信息; 高艳红等[16]提出对从维基百科抽取的上下文与内容两方面语义特征的语义相似度进行计算, 并融合到构建的图模型, 但没有实现批量处理, 且对于空链接的处理不完备; 谭咏梅等[17]在知识库部分实体的图结构中重启随机游走, 获得实体和指称的分布式表示, 甚至融入卷积神经网络[12], 聚类知识库中无对应的实体指称, 然而在指称扩充方面忽略了语义联系,但指称识别部分仍旧不理想, 融合卷积神经网络的改进方案也增加了算法复杂度.
2 实体链接框架与算法
从目标实现的角度来看, 实体链接是联合指称项和候选实体的多种特征, 通过某种方法识别出目标实体; 若对应目标实体不存在, 则返回空链接NIL. 本工作提出的基于图的联合特征实体链接方法的整体框架如图1 所示. 框架接受一个文档集合作为输入, 输出文档中的指称和对应的实体. 框架被分成了线上和离线两部分.
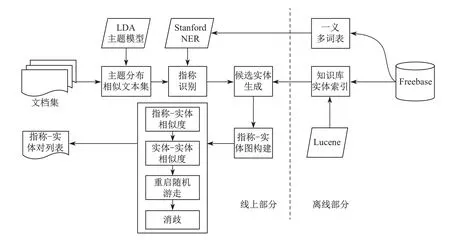
图1 基于图的联合特征实体链接方法框架图Fig.1 Framework of entity linking method based on graph with multi-feature fusion
离线部分是对知识库Freebase 作预处理: ①建立实体索引, 加速候选实体的查询, 其中Lucene 是一款高性能的检索工具; ②构建一义多词表, 扩充分词器的词库. 在自然语言文本中很多实体常常以别名等形式出现, 分词器很难把这些别名都识别出来, 因此本工作从Freebase提供的实体信息中抽取这些别名信息.
线上部分首先利用LDA 主题模型对文档集进行聚类, 将相似主题分布的文档归为一类.①一篇文档中的指称对应的实体相互之间有较大的关联度; ②两篇主题分布相似的文档中的指称对应的实体之间也会有较大的相关性. 链接算法以主题分布形式的文本集作为输入, 实体链接过程分为以下6 个部分: 指称识别、候选实体生成、图构建、边权重计算、重启随机游走和联合链接.
2.1 指称识别
本工作采用Stanford NER 汉语分词系统, 依据词性标注结果识别出主题分布相似的文本集D 中的实体指称项. 对于指称的别名等问题, 将离线部分生成的一义多词表输入分词系统的词库中, 提高识别率, 记分词系统最终识别出的指称集合为 M ={m1,m2,··· ,mn}.
2.2 候选实体生成
在离线部分, 知识库的实体已经通过Lucene 建立了索引. 本工作直接使用Lucene 来检索指称的候选实体. 记指称集合 M 对应的候选实体集合为 Em= {Em1,Em2,··· ,Emn}, 其中Emi是指称mi的候选实体集合, 由此可以得到m-Em映射表, 如表1 所示.

表 1 m-Em 映射表Table 1 m-Em matching
2.3 指称-实体图构建
本工作借鉴文献[15]的思想, 采用重启随机游走的方法计算指称和实体之间的相关度. 在随机游走之前, 需要构建一个连通图(指称-实体图), 即图中的任意两个节点之间是可达的. 第一步, 在指称和对应的候选实体之间加上边(见图2 中①线); 第二步, 将知识库中有连接关系的候选实体之间加上边(见图2 中②线); 第三步, 由于随机游走必须保证每个实体之间是互通的, 所以选择知识库中至少同时连接两个候选实体的实体添加到指称-实体图中(见图2 中③线), 新加入的实体称作“扩充实体”. 本工作简化了知识库中实体之间的联系, 将有向边视为无向边.

图2 指称-候选实体-扩充实体图结构Fig.2 Mention-candidate entity-augmented entity graph structure
2.4 边权重计算
指称-实体图构建完成后, 需要求出相应的转移矩阵. 图2 中存在两类节点: 指称节点和实体节点. 因此, 边的类型可以分成指称-实体边(即图2 中①线)和实体-实体边(即图2 中②, ③线). 本工作使用节点之间的联合关联度来描述两类边的权重, 即指称-实体关联度S(m,e)和实体-实体关联度S(ei,ej), 采用的计算方法如表2 所示.

表2 边权重计算方法Table 2 Method for calculating edge weights
2.4.1 指称-实体关联度
指称-实体关联度表示实体指称m 与候选实体e 之间的关联程度. 本工作在文献[16-17]的基础上, 利用文本的字符串特征、上下文特征来计算字符串文本相似度SED(m,e)和上下文-元数据相似度CSM(m,e), 然后线性联合这两个相似度来衡量m 和e 之间的指称-实体关联度.
(1) SED(m,e).
使用编辑距离(edit distance, ED)计算字符串文本相似度. 编辑距离指两个字串由一个转成另一个所需的最少编辑操作(替换、插入、删除)次数. 一般来说, 编辑距离越短, 两个字符串的相似度越大. 为了衡量关联度, 要将编辑距离归一化,

式中: a 和b 是两个字符串; ED(a,b)是两个字符串之间的编辑距离. 编辑距离和字符串相似度之间呈负相关, 字符串文本相似度

式中: SED(m,e)表示指称m 和实体e 之间的相似度, 值越大的两个字符串被认为在编辑距离意义上越靠近, 反之则越不相似.
(2) CSM(m,e).
指称-实体图中的指称节点和实体节点都有相应的上下文文本信息. 为了计算上下文之间的相似度, 首先利用预训练的Word2Vec 模型来获取上下文句子中每个词的向量表示. 该模型是在Google News 数据集(含有1 000 亿个词)上训练而来的. 记指称m 的上下文词集合为Lm= {wm,1,wm,2,··· ,wm,n}, 其中 wm,i= (xi,1,xi,2,··· ,xi,k), k 是向量的维度. 同理, 记实体 e 的上下文词集合为 Le= {we,1,we,2,··· ,we,l}, 其中 we,j= (yj,1,yj,2,··· ,yj,k). 将上下文中的词向量进行求和平均, 得到指称和实体的上下文向量,

记 Cm=(x1,x2,··· ,xk), Ce=(y1,y2,··· ,yk). 使用 cosine 相似度计算指称和实体之间的相似度,
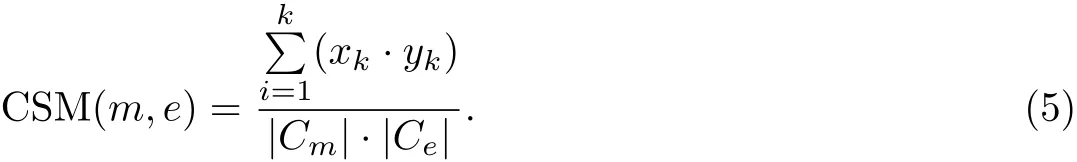
(3) S(m,e).
综合以上两种相似度特征, 将式(2)和(5)线性组合得到指称和实体的关联度,

设定 α =0.36, β =0.64.
2.4.2 实体-实体关联度
实体-实体关联度是实体(ei,ej)之间的相似度, 采用的方法包括上下文相似度和元数据相似度. 同样地, 线性组合两个相似度来计算实体-实体关联度S(ei,ej).
(1) CSM(ei,ej).
计算CSM(ei,ej)的方法和2.4.1 节中的上下文相似度的方法是一致的. 两个实体ei和ej的上下文相似度为

(2) MSM(ei,ej).
Freebase 知识库中提供了实体和维基百科页面的映射关系. 常见的实体在维基百科页面中都有一个infobox(见图3(a)), 称这部分数据为实体的元数据. 本工作使用Kalender 等[18]提出的元数据相似度来衡量实体之间的关联度. 首先, 将知识库中所有实体的infobox 中的信息抽取出来, 用词袋模型(bag-of-words)构成一个词汇表, 即图3(b)的第2 张表. 词汇表的规模直接决定每个词向量的维度. 高维的向量不仅需要更大的内存开销, 而且还存在稀疏性的问题.因此, Kalender 等[18]进一步引入了hashing 算法处理原有的词典, 转换成图3(b)第3 张表所示的词典. 该方法为每个词添加起止标志(如#harvard#), 然后将词分割成2-grams 的字母组合(如#h, ha), 重新构成一个词汇表. 每个词可以表示成字母组合的向量. 实体的向量同样是通过其对应infobox 中每个词的向量的求和平均计算而来. 两个实体ei和ej的元数据相似度依然通过 cosine 相似度来计算, 记为 MSM(ei,ej).

图3 元数据相似度Fig.3 Metadata similarity
(3) S(ei,ej).
综合以上两种相似度特征, 线性组合得到实体之间的关联度为

设定 γ =0.42, δ =0.58.
2.5 重启随机游走
重启随机游走是从某一个节点出发遍历图的随机过程. 该过程收敛后对应每个节点生成一个概率值, 表示起点和该点之间的亲和度(无论起点和该点是否直接相连), 记这些概率值构成的向量为P. 重启随机游走即是更新P,

式中: c 表示重启概率; Pi表示经过i 轮迭代后的概率分布值; P0表示初始向量, 即经过0 次迭代后的概率分布. 因此, P0中只有起点对应的位置值为1, 其余元素都为0. 图中每一个节点都进行重启随机游走, 就能得到图中任意两个节点之间的亲和度.
2.6 联合链接
本工作采用Globerson 等[19]提出的一致性模型进行联合实体链接. 该方法考虑指称与实体之间的相关度和候选实体之间的相关度, 相关定义如下.
(1) rm(yt)表示指称m 和实体yt之间的相关度, 即以指称m 为起点的重启随机游走生成的概率分布中实体yt对应的值.
(2) s(ya,yb)表示实体ya对实体yb的支持度, 即以实体ya为起点的重启随机游走生成的概率分布中实体yb对应的值. 一篇文档中实体的主题分布基本一致, 因此判断一个实体e 是否对应某个指称m, 不仅可以通过指称和实体之间的关联度, 还可以通过文档中其他实体和实体e 的一致性程度(支持度). 通过下式得到指称mi的链接实体, 即

式中: yi表示指称mi的候选实体; max s(yj,yi)表示指称mj的候选实体对实体yi的最大支持度.
3 实验结果
为验证基于图的联合特征实体链接算法的有效性, 本工作采用TAC 2016 年EDL 任务的实验数据, 并且使用准确率(P)、召回率(R)和F 值对链接和聚类结果进行评价. 在此基础上重现文献[16-17]的测试结果(见表3), 可见本工作所提出的基于图的联合特征实体链接算法优于其他两种算法, 表明本算法能有效完成实体链接任务.

表3 不同实体链接算法的性能比较Table 3 Performance comparison of different entity linking methods
高艳红等[16]将多特征融合到图模型时只是简单地把单个指称和对应候选实体放在一张图中, 没有协同考虑主题相似性, 而本工作利用LDA 主题模型对文档集进行聚类. 谭咏梅等[17]则仅使用维基百科页面中共现的次数作为衡量初始权重的标准, 单一地对提取的多种特征逐项排序, 没有充分考虑特征之间的关系, 而本工作采用一致性模型实现联合特征链接. 尽管这些不同方法在处理实体链接方面都有一定的改进, 但在图的构建、边权重计算、特征选择以及排序选择方面仍旧存在不足. 本工作采用重启随机游走的方式, 将多种特征融合到初始边权重计算中, 在选择特征时, 采取联合上下文与元数据的方式, 以提高链接速率; 同时, 排除知名度特征, 降低干扰度, 对于主题相似度的文本实现协同指称链接.
4 结束语
面向实体链接, 本工作提出一种基于图的联合特征实体链接方法, 有选择地抽取主题、上下文和元数据等重要特征, 并融合到重启随机游走的初始权重计算中, 达成联合实体链接的目标. 实验结果表明, 本工作提出的方法更准确地抓住了联合相似度的重点, 并且取得了较好的链接效果. 但是, 本工作对NIL 空链接没有作处理, 这将是下一步的工作方向. 目前, 实体链接还有很多技术难点, 如通用领域的中文知识库实体量巨大且实体界限模糊; 短文本缺乏足够的上下文信息, 需要挖掘实体与词语之间关系; 中文与英文的明显差异对实体链接造成的挑战等. 所以, 后续工作不仅要改进所提出的算法, 在其他方面也将作出探索.
