一种新的分布式云工作流调度算法
2020-12-09何中秋


摘要:云计算环境中当解决大数据相关应用问题时,服务之间面临数据传输的高延迟以及不必要的网络带宽消耗。尤其是当数据量大并且同时数据分散时,这些问题更加特别突出。本研究提出一种新的分布式云工作流调度算法。该算法允许将工作流移向提供数据的服务,以获得最佳性能。该算法将工作流程分解为较小的工作流流程以并行执行,并确定这些工作流程部署到最合适的网络位置上并执行。
关键词:面向服务的工作流;工作流切分;工作流部署
中图分类号:TP301.6 文献标识码:A 文章编号:1007-9416(2020)10-0000-00
0引言
服务工作流表示服务的自动化,在此过程中,数据在服务之间的传递以进行处理,通常,工作流是基于集中式设计模型来编排的,该模型提供对工作流的控制,支持流程自动化,并将工作流逻辑封装在执行它的中央位置。有几种用于描述服务工作流的语言,例如已被接受为标准服务编排的业务流程执行语言(BPEL),BPEL是一种描述业务流程、计算机可执行的标准语言,它把若干个现有的服务按照一定的业务逻辑组合起来形成业务流程,然后部署到执行引擎中,由执行引擎对流程进行解析和编译,逐步调用外部服务,完成整个业务流程的功能。[1]云工作流调度一直是工作流领域研究的热点问题。多数工作通过设计目标函数进行优化。一个良好的调度算法可以提高效率,节约成本。本文提出一种新的分布式云工作流调度算法。服务组合在大数据环境下的应用,同时构思了一种适用于大数据环境下的服务组合系统,能有效的收集和整理海量的服务数据,满足用户的个性化需求。[2]
1国内外研究现状
随着互联网技术、虚拟化技术的发展和成熟,云计算成为一种新的社会基础设施。云计算作为一种弹性高效的计算模式,则为构建大数据服务提供了强大的技术支撑[3]。互联网、物联网、云计算、大数据的迅猛发展,计算服务化的趋势日益明显,“万物皆服务(EaaS)”从内涵到环境都在发生着巨大的变化.物理世界与数字世界相互融合构成了物理信息空间(CPS),网络世界内外线上线下(O2O)的服务系统通过互联网构成了服务网络世界,“务联网(Internet of Services,IoS)”应运而生.务联网的进一步发展,形成了“大服务(big service)。[4]云服务已经成为当前主要互联网服务模式。云计算环境下工作流的调度是一个NP完全问题,针对此问题提出许多算法,包括基于元启发式算法来解决NP问题,如粒子群算法(PSO)、禁忌搜索(TS)、模拟退火(SA)、遗传算法(GA)等。本文的调度算法是,先选择目标VM,然后将工作流图进行切分,部署到合适的VM上,经验证本文提出的方法对于与工作流的执行效率有显著提高。本文的主要贡献是一种分解工作流的方法,该方法允许将将工作流分解为较小的自工作流,以便在云上并行执行。他确定这些自工作流传输并随后执行的最适合的位置。与依赖数据放置的现有方法不同,我们的方法允许将工作流计算移近提供数据的服务。通过采用这种方法,分布式引擎可以一起协作以执行整个工作流。
2方法
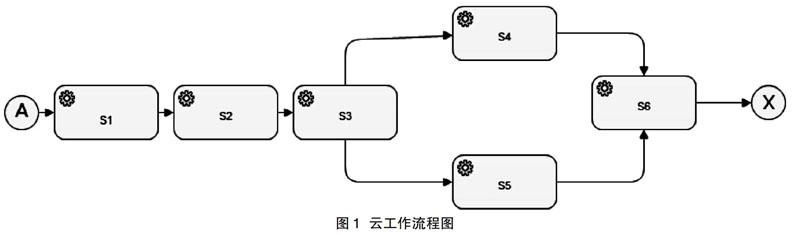
工作流引擎将工作流程逻辑与其执行分开。本节提供了一个简单的工作流示例,将使用该示例来说明我们的方法。图1显示了他的结构,其中输入A用于调用服务S1,该输出用于调用S2,然后将其输出传递到S3,S3的输出用于调用S4和S4,S4和S5的输出用作S6的输入,从而产生最终的工作流输出X。
通过递归下降编译器来分析工作流程规范,以确保其正确性。他不会从工作流程中生成机器代码表示,而是构造一个可执行图的数据结构,该结构由表示服务调用的定点组成,他们之间的边作为数据依赖项。该数据结构的组件可以分不到任意网络位置的远程工作流引擎。这樣可以在运行时处于优化的目的对其进行重构。
算法概述
我们的算法包括三个阶段,包括工作流分解、放置分析和工作流的组合。为了实现我们的方法,我们创建了一个完全分布式的业务流程架构。与现有的编排技术不同,现有的编排技术由控制工作流的决策逻辑的集中引擎来代表控制位置,我们的体系结构中不存在单个控制位置的概念。在工作流程执行期间,我们可以在一个或几个引擎上找到决策逻辑。
(1)工作流分解:通过创建一个流程遍历器,将工作流程图分解为代表子工作流流程的较小数据结构。通过该方法可以了解并检测工作流程图的复杂并行部分,并且通过该方法可以获取有关工作流的输入、输出、服务调用和关联类型的信息,而且同时还能够获取最小子工作流程的最大数量。工作流分解结果如图2所示。
(2)放置分析:流程遍历器分解了工作流之后,将进行放置分析以确定子工作流程的最合适引擎。此阶段主要进行集群引擎的选择和确定子流程放置在合适的引擎上。对每个子流程来说,可以通过使用k-means聚类算法以及业务约束、环境约束、容量约束、系统约束外加上代表网络延迟的QoS指标将工作流引擎进行分组。每个子流程将获得其最合适的引擎。放置分析的最终的结果是选择带宽最高,延迟最低的的计算节点如图3所示。
(3)工作流组合:当所有的子流程放置到相应的引擎上之后,既第二部完成之后。将会检测每个引擎中的服务之间的关系,如果检测到他们之间又数据依赖关系则将他们组合在一起形成一个复合工作流程。这样便完成了将一个复杂工作流程分解为不同引擎上规模较小的子工作流程,通过这种方式便将工作流分布到不同的集群上了,增加执行并行的能力。如图4子工作流程组合分布图所示。
3实验
实现是基于Java,可以在任何物理或虚拟机上部署web服务包。他一来java运行时环境(JRE)和Apache Tomcat服务器。我们设计了一组实验工作流程来评估我们的方法,每个工作流程都是根据特定的数据流模式指定的。其实验结果如表1所示。
从表格可以看出这种新的分布式云工作流调度算法有了明显的时间性能的提高。随着服务数量的增加,相应的服务会找数据分布的引擎上这样便减少了数据量的传输,相比轮询算法来说更加节约时间。
4结语
随着服务的数量和工作流数量的增加,如果没有好的调度算法可能带来严重的系统可伸缩问题,这些问题包括不必要的网络消耗带宽,服务之间数据量传输的高延迟以及性能瓶颈。本文提出了一种新的分布式云工作流调度算法,将工作流程分解为较小的自工作流程,然后可以将其传输到适当的位置上。使用依赖于业务约束、环境约束、容量约束、系统约束等条件来确定自工作流的位置。在未来的工作将集中在实时分布式监视和重新部署正在执行的自工作流,以适环境中的动态变化。
参考文献
[1]江澄.大数据环境下基于QoS历史记录的服务组合推荐方法研究[D].南京:南京大学,2014.
[2]方若洁.基于BPMN/BPEL的全过程建模工具的设计与实现[D].北京:北京邮电大学,2015.
[3] 林文敏.云環境下大数据服务及其关键技术研究[D].南京:南京大学,2015.
[4] 徐晓飞,王忠杰,冯志勇.大数据环境下的大服务与应用及其影响[J].中国计算机学会通讯,2017(2):24-30.
收稿日期:2020-08-24
基金项目:北京市自然科学基金(4192020)
作者简介:何中秋(1993—),男,河北衡水人,硕士,研究方向:云计算、大数据、工作流。
A new Workflow Scheduling Algorithm
HE Zhong-qiu
(North China University of Technology Infomation Institute,BeiJing 100144)
Abstract:These problems are especially prominent when the amount of data is large and the same data is scattered.When solving big data-related issues in a cloud computing environment, services face high data transmission delays and unnecessary network bandwidth consumption. This research proposes a new distributed cloud workflow scheduling algorithm.It permits the workflow computation to be moved towards the services providing the data in order to garner optimal performance results. This is achieved by decomposing the workflow into smaller sub workflows for parallel execution, and determining the most appropriate network locations to which these sub workflows are transmitted and subsequently executed.
Keywords:Service-oriented workflows;Workflow segmentation;Workflow deployment
