Research and application of information extraction technology in clinical medical records
2020-12-09FuYiChenYingMaYawen
Fu Yi, Chen Ying, Ma Ya-wen
Information Network Center, Shandong Provincial Hospital, Jinan 250021, Shandong Province, China
AbstractThis paper discusses the application of scientific research analysis of the existing clinical practical data, including how to collecting data and find the hidden medical knowledge from the data.It focuses on how to use information extraction technology to achieve the structure process of previous text-based medical records, thus supporting the secondary use of data.
Key words: clinical research; information extraction; structuration; electric medical records in text form
Introduction
With the gradual advancement of medical information construction, a series of application software systems have been built in the hospital, which effectively supports the effective development of hospital services. After years of operation, various business application systems have accumulated a large amount of valuable data resources and provides a reliable foundation for clinical research.The accumulated “big data” has been applied in medical clinical research, using information technology to explore the medical rules and experience, to achieve scientific research deriving from clinical and benefiting clinical, and to quickly achieve the accumulation of clinical experience in hospitals. Effectively integrating and utilizing data to support clinical research and knowledge discovery is a trend in hospital information construction.
Analysis of Clinical Research Problems
In the process of using historical clinical data to support scientific research, the following problems need to be solved: (1) Data is scattered. The data exists in the hospital management information system, the examination information system, the inspection information system,the surgical anesthesia system, and the electronic medical record system. These scattered data are not conducive to integration and analysis, and it is necessary to extract medical records that meet the scientific research requirements from each business system, and establish a scientific research database system; (2) Data is unstructured. Although hospitals have implemented structured electronic medical records, doctors often write medical records in texts for clinical work efficiency and to avoid the expression of clinical thinking. However, this method is insufficient to support the scientific research requirements for data granularity.
In the process of clinical scientific information construction in our hospital, we first use the electronic medical record system as the information integration platform for clinical medical treatment, integrate data from hospital management information systems, examination systems, inspection systems, and surgical anesthesia systems, achieve comprehensive and patient-centered data integration, provide a unified data environment for medical research and statistics, and avoid the “information island” of clinical research. Therefore, the medical record research institute system is used to collect and analyze the data, realize the scientific research program management, scientific research data four-dimensional axis data collection (time, symptoms and signs, treatment,examination and inspection changes), scientific research analysis logic design and other functions, and finally the medical records will be exported and transferred to SPSS software for statistical analysis.
In the above process, it is a very important link to use the electronic medical record information extraction technology, to analyze and extract the data of symptoms, signs, diagnosis and surgery in the medical record, to support the collection of clinical research medical records[1]. Information extraction is a means of structurally processing the information contained in the text and transforming the unstructured information into the structured information. Through information extraction, keywords in the medical records, such as symptoms, signs, surgery, diagnosis, and examination index are extracted. Information can be displayed directly to the user, and computer recognition is achieved, thus laying the foundation for further information processing such as data query and data mining.
Information Extraction unction Implementation
Preparation of the corpus
In the information extraction of medical records, the most critical step is the preparation of corpus. As the basic information element in the text, named entity recognition plays a key role as the first step of information extraction.In the clinical medical record, it includes the named entity category, such as time, diseases, symptoms, surgery,etiology, signs, drugs, surgery. The terminology in the medical field is very large. At present, only the standard international coding dictionary for disease diagnosis and surgery is available, but doctors often do not follow the standard dictionary when writing medical records, so obtaining these medical termbases becomes a bottleneck.
In this project, the corpus is first constructed based on the diagnostics corpus (medical termbase), which is not a simple vocabulary, but a well-designed and selected knowledge base with good object-oriented architecture and multiple abstraction levels. Secondly, the machinebased intelligent learning method is used to quickly learn the terminology of tens of thousands of real medical records. Word pairs are extracted from these medical records, and the frequency of occurrence is sorted. The extracted pairs of words are manually reviewed. When the review is performed, the machine is still assisted to identify correct descriptions or non-standardized description, as well as those caused by the typo, and to identify multiple semantically identical expressions (such as “headache” and “head pain”), and finally generates the corpus of our hospital. This corpus covers medical terms such as symptoms, signs, diagnosis, surgery, time,medicine, treatment, and prognosis.

Figure 1 Machine intelligent learning word pairs from the medical record to enrich the corpus
The corpus is automatically extracted from massive medical records, then the manual proofreading is performed, and the proofreading results are fed back to the system for memory and learning. The more memory learning is associated with the richer corpus and the higher accuracy of the information extraction based on the corpus.
Constructing information extraction template
A template for information extraction is established,and the granularity and architecture of the template are designed according to the needs of scientific research.Later, when the medical record information is extracted,the program will recognize various grammatical structures in the text according to the predefined template, and complete various types of entity recognition tasks,such as symptoms, signs, and diagnosis. According to the requirements of the extraction task, the extraction mode is used to identify the relationship between the entities in the text, and the corresponding information is extracted to complete the relationship extraction task.The corresponding template is automatically generated according to the extracted information, and is filled according to the previously extracted information to form a complete information description, complete the template filling task, and organize into a tree structure.
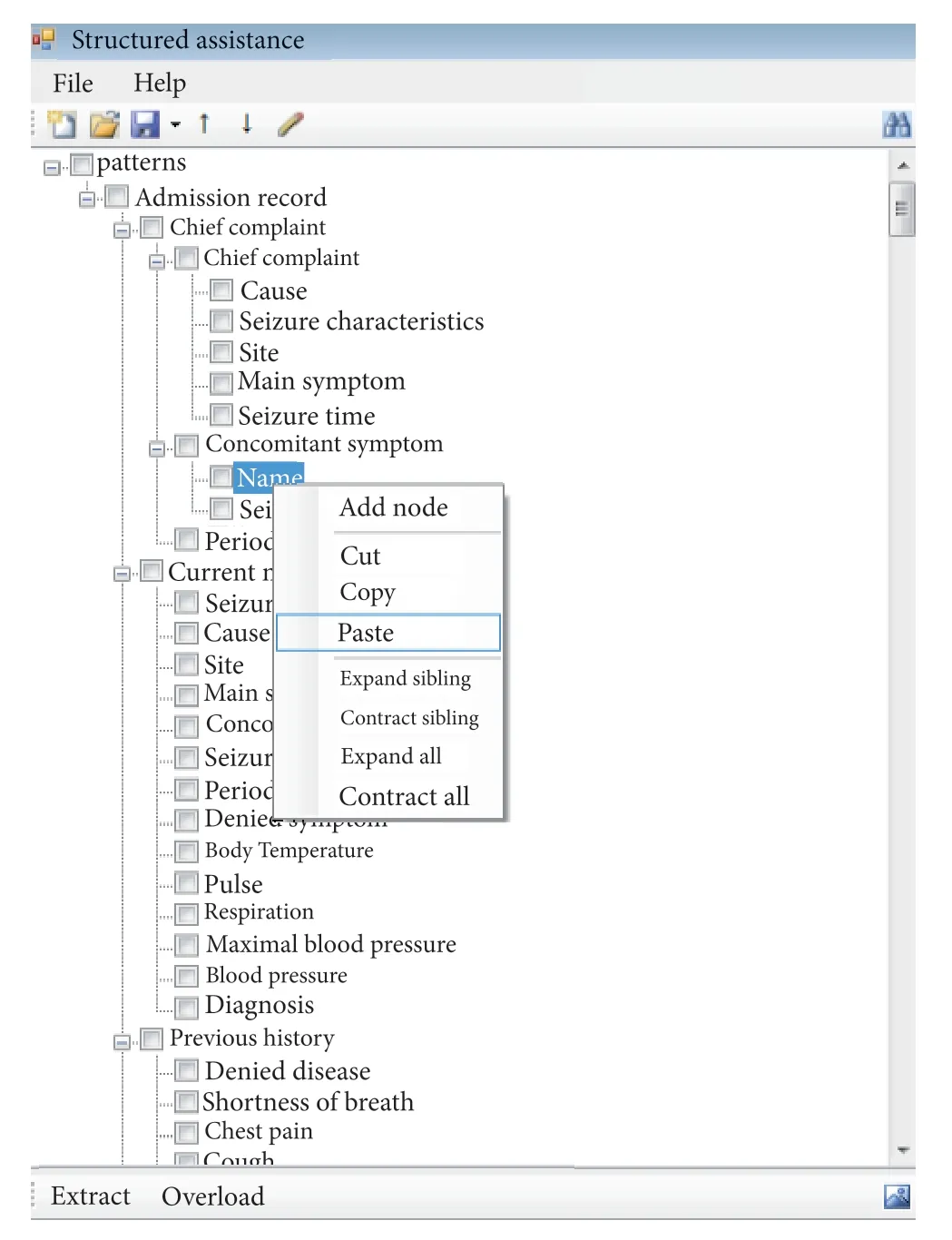
Figure 2 Structured extraction template predefinition
Information extraction not only needs to summarize and extract information from the text, but also organizes and represents structured data in an appropriate way. It also needs to consider how to effectively store and manage. In the information extraction process, what kind of structure is used to organize various target information involves the template design problem. The template studied in this paper adopts a tree structure design, and uses node and branch nodes to organize the structured information reasonably. XML (Extensible Markup Language) can be used as a data storage language. XML language is a metatag language with good extensibility. The meta-tags can be cascaded and accurately describe the correlation between nodes, because the information result is finally extracted and output to an XML file.
As shown in Figure 2, the user customizes the template structure and template granularity according to scientific research requirements.
Medical record information extraction
On the basis of the mature corpus and the information extraction template, the medical records of the hospital’s historical stock including text medical records, structured medical records, and semi-structured medical records will be extracted with key words in the free-text medical records or semi-structured medical records such as:symptoms, onset time, signs and other information, and organized into a tree structure, providing a data basis for secondary use of medical records such as clinical research.
The electronic medical record contains three kinds of data:structured, semi-structured and free text. The data such as medical order, examination and inspection are existing in the database, which are all structured data. The forms in the medical record exist in the form of web pages, which belong to semi-structured data. The main complaints,current medical history, and course records are free texts.The extraction of these three kinds of data is handled by a unified extraction model.
The unified extraction model unifies the extraction and transformation, and the extraction is regarded as a special transformation, that is, only transforming the position without changing the original symbol system. In actual use, the extraction and transformation are complementary,such as: full-width/half-width of the punctuation, English capitalization, Chinese and English numbers, as well as synonyms, such as: ward round records in the medical records of the superior physicians have a variety of expressions: chief physician rounds, deputy chief physician rounds, chief physician ward round record, chief ward record, after the extraction, they should be converted to a superior physician rounds record. Obviously, if a medical record is well transformed, it also completes the structuring. Since the unified model organically combines keyword matching and natural language processing,the full-structured, semi-structured and free text can be processed in a unified manner, such as identification of diagnosis in medical records, because natural language processing method is almost impossible to identify all the possibilities and is also very complicated, while the keyword positioning is simple and efficient, highly accurate. As long as the medical record is standardized,the accuracy rate is almost 100%.
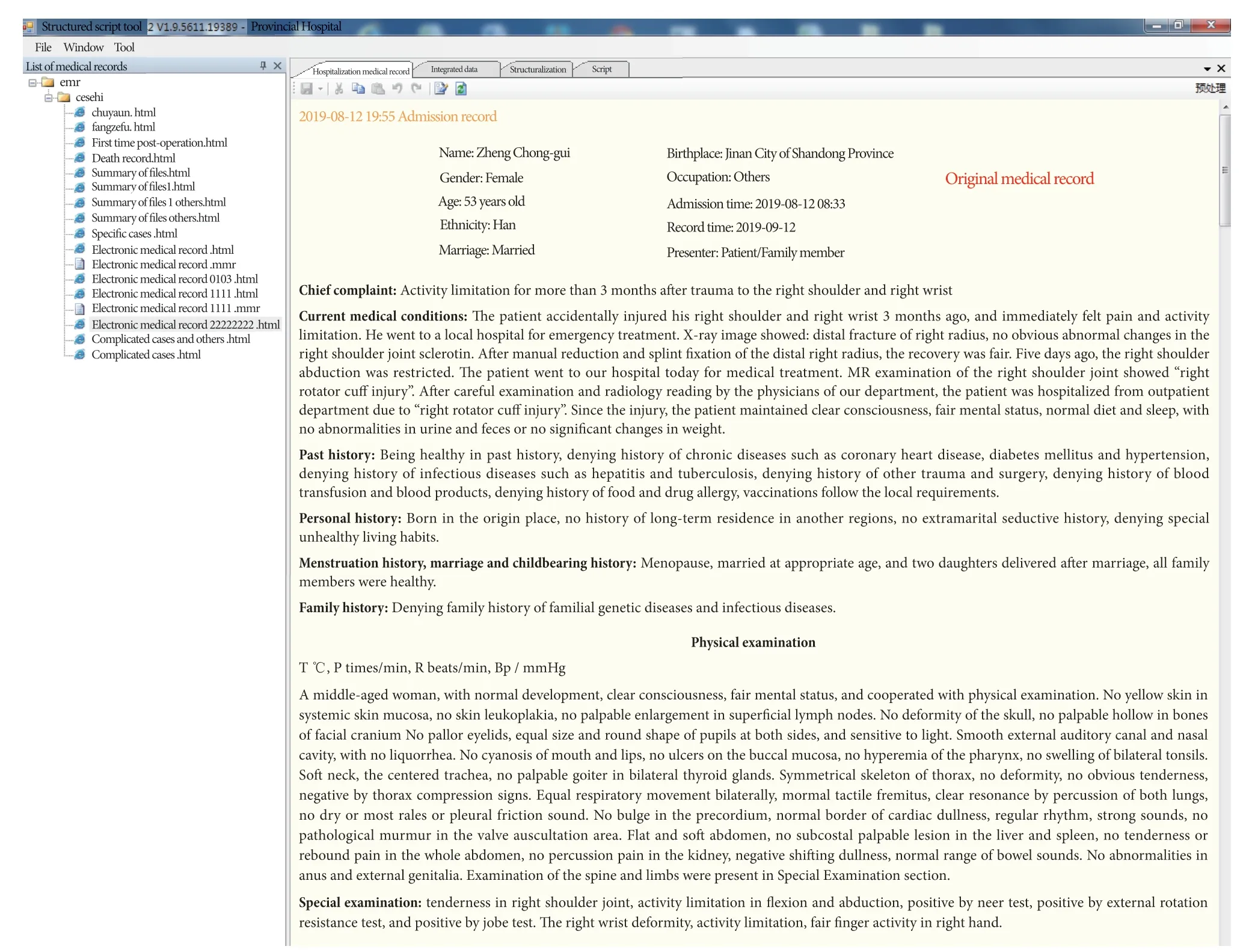
Figure 3 Original hospitalization medical record by information extraction tool
As shown in Figure 3, the left interface is the information of original medical records reserved in local database, and the right interface is the original hospitalization medical record for extraction.
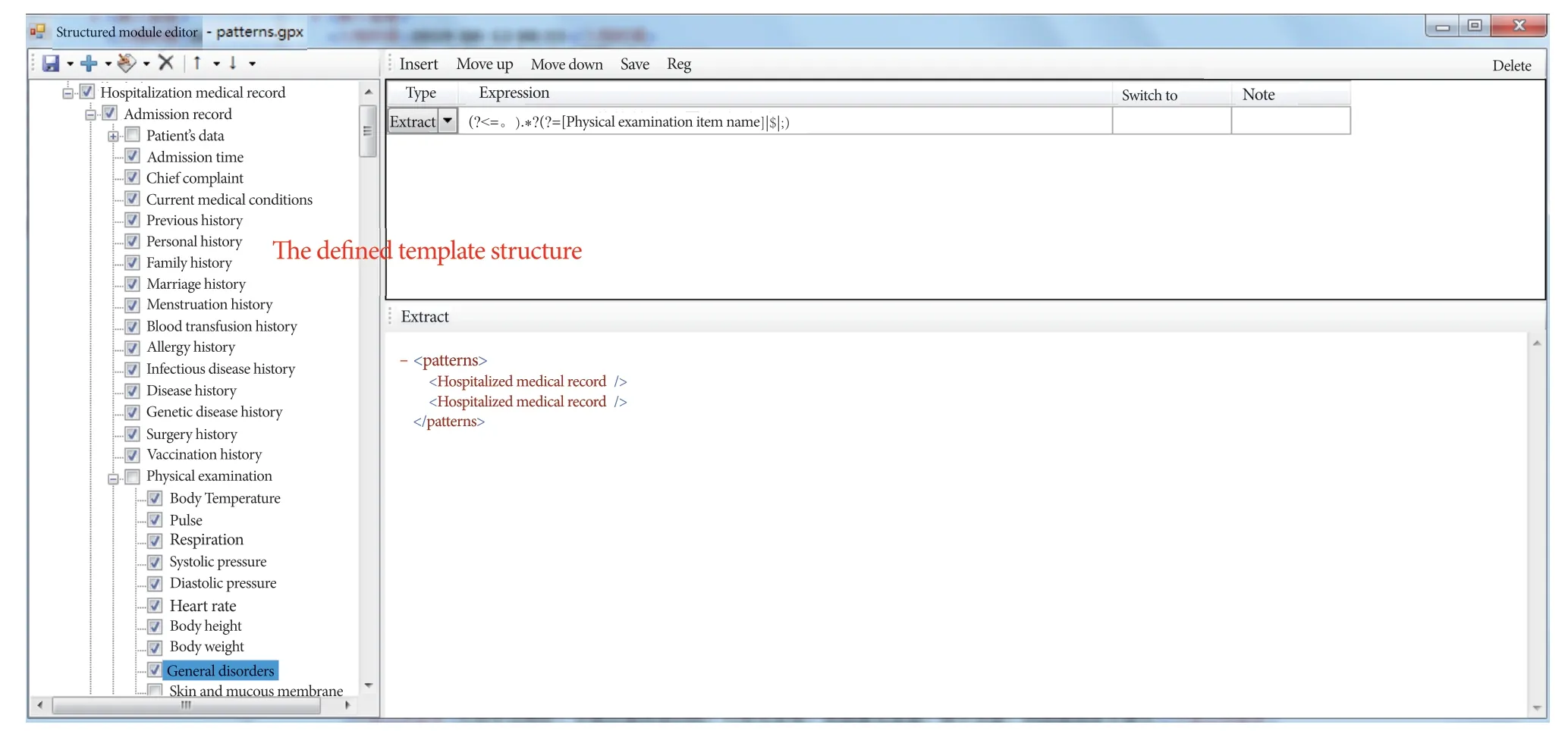
Figure 4 The template structure defined by information extraction tool
As shown in Figure 4, the left interface is the defined extraction template structure, and the right interface is the acquisition of structured medical record configured with regular expressions.
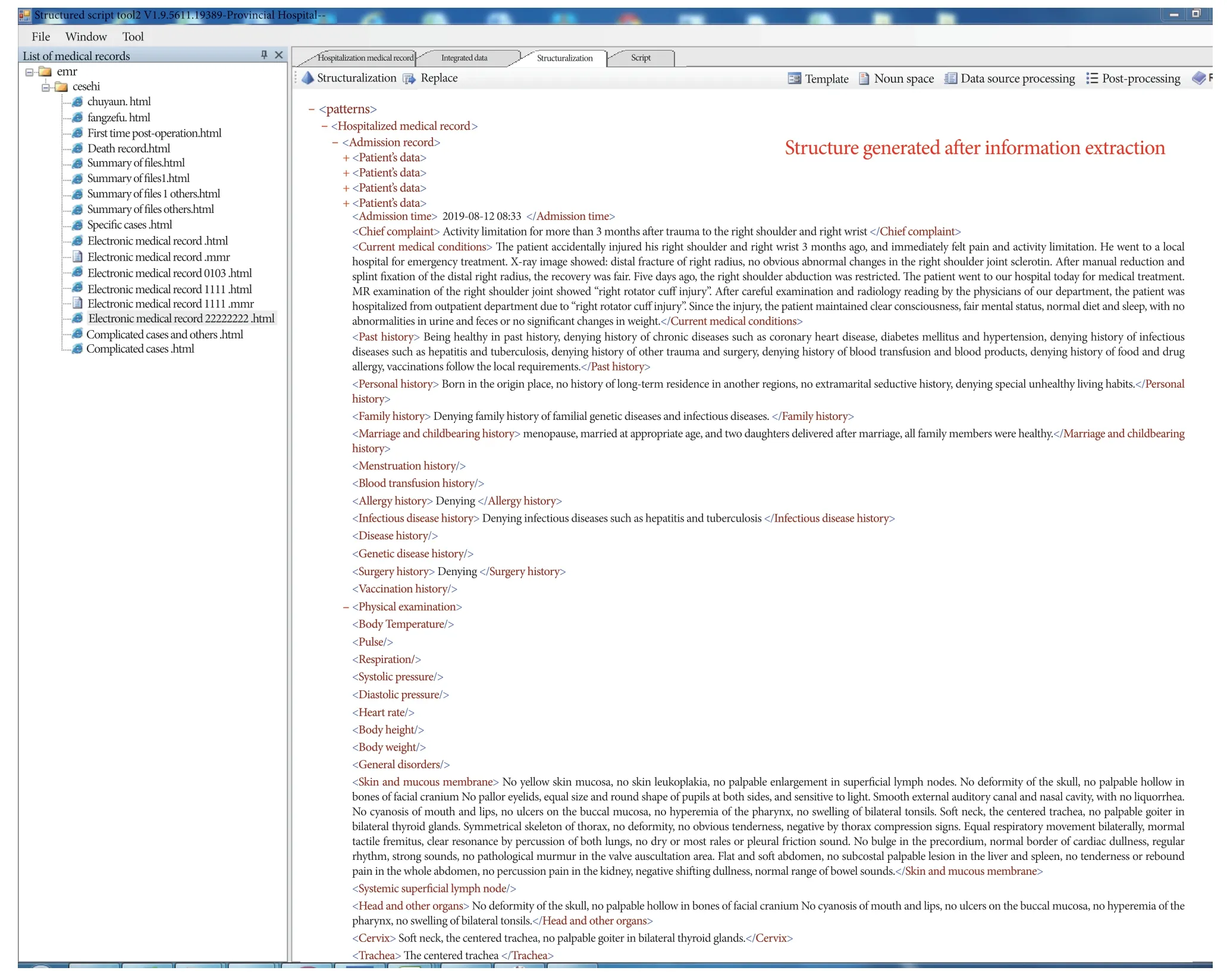
Figure 5 The structured information tree structure extracted by information extraction tool
As shown in Figure 5, the left interface is the information of original medical records reserved in local database,and the right interface is the structured information tree structure formed according to the template structure after the medical record is extracted.
Clinical Research Practice
Since the beginning of 2015, our hospital has carried out scientific research based on clinical actual data through the support of the above technologies. Each clinical department can manage their clinical research plan.According to different scientific research requirements,the case retrieval and automatic enrollment conditions are defined, the self-defined data collection form is supported,and finally exporting the case collection data. The whole process does not require the participation of R&D personnel.Our hospital has realized the retrieval and utilization of the hospital’s historical data within the past 5 years, and realized the structural extraction, scientific research data collection, analysis and utilization of 52,264 medical records, which satisfies the requirements of large-scale samples for scientific research projects. Based on the existing clinical data, our hospital collects data, designs data algorithms, finds the medical rules and knowledge hidden behind the data, and constantly improves and enriches the existing diagnosis and treatment system,improves the efficacy of diagnosis and treatment, and has achieved good application effect[2].
Conclusion
Clinical data is both a source of medical development and an evidence base for clinical efficacy validation. Collecting clinical actual data, carrying out real-world clinical research, and constantly improving the clinical efficacy“evidence chain”, carrying out clinical research based on clinical practice, realizing scientific research deriving from clinical and benefiting clinical, will finally provide better and more accurate diagnosis and treatment services for patients. Through information extraction, the key words of free-text medical records or semi-structured medical records such as symptoms, onset time, physical signs and other information are extracted and organized into a tree structure, which provides a data foundation for clinical research and solves the problem that it is difficult to develop large-scale clinical research and statistical analysis based on text medical records, and lays a technical basis for the formation of clinical research community in our hospital.
杂志排行

Global Smart Medicine的其它文章
- SWOT analysis of static data backup media
- Application based on integration platform and big data center
- Instructions for Authors Journal of Global Smart Medicine
- Practical exploration of artificial intelligence in the field of medical nursing care
- Discussion on Internet of Things communication technology and its general development trend
- Design of a dynamic health record management system of chronic patients based on regional medical consortium