重庆三峡医药高等专科学校站群数据监测系统分析与实现
2020-12-09彭雷曾岗袁志军郭振勇张耘坚
◆彭雷 曾岗 袁志军 郭振勇 张耘坚
(重庆三峡医药高等专科学校科技处重庆 404120)
1 背景与意义
重庆三峡医药高等专科学校官方网站作为学校的门户,承担着信息发布、展示的任务,一旦被黑客入侵,页面被攻击,将会产生不良的影响。目前我校在这一方面的数据监测工作上,通常设置专人来对数据进行监控,发现问题及时处理,然而每个子页面都有内部嵌套、跳转的链接,随着信息数量级的增加,人工分析难免有些吃力。通过网络爬虫获取这些信息进行有效自动分析,可以有效减少监控人员的工作量,因而是一个亟待解决的问题。
2 国内外研究现状
胡尊玉等人[1]通过分析高校网站群的网络安全问题,提出一种在大数据时代背景下对网站群安全监测设计方案,提高网站群工作模式的可靠性。郭剑锋等人[2]通过嵌入式监控模式解决监控平台使用特征码比对方法的高误报率问题。Nafiseh Hosseini等人[3]利用机器学习技术提出了一个有效的基于倾向性行为的恶意爬虫监测模型,改模型与支持向量机、贝叶斯网络、决策树三种算法对比,表现出了较好的效果。Nguyen Duc Thai等人[4]提出了一个网络安全评估框架,该框架将不同的扫描工具集成到一起。在实际使用中,该框架还可以添加工具并生成扫描报告。方芳等人[5]使用 Scrapy框架爬取了京东网上笔记本计算机的评论信息,通过模糊匹配方法提取数据,并进行去重、分词和停用词过滤等处理,绘制词云图并给出情感分析结果。周燕等人[6]根据医院网站入侵威胁现状,分析存在的信息安全问题,并提出解决方案。崔颖等人[7]对政府网站网络的安全性做了分析并提供了网络安全的解决对策建议。黄家常等人[8]在分析高校网站群系统的安全风险后给出了应对的具体策略。柳强等人[9]分析了高校二级网站存在的各种安全隐患,并在技术层面和管理层面提出了高校二级网站安全隐患的有效防御对策。
3 系统分析与设计
本系统针对的是重庆三峡医药高等专科学校站群数据,目的是给站群数据监测者提供辅助性帮助。本系统将用户分为两类角色:普通用户角色和系统管理员角色。普通用户可以进行扫描与敏感词过滤,管理员在普通用户的基础上添加了管理功能。总的来说,整个系统的功能有以下模块:登录模块、用户信息管理模块、扫描模块、过滤模块、字典模块、管理员管理模块。
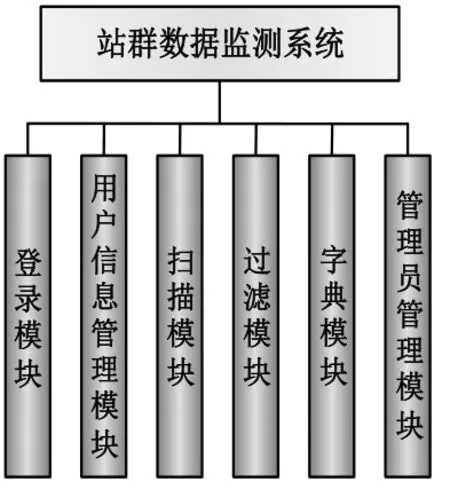
图1 系统功能模块
(1)登录模块:登录模块可以将普通用户与管理员分开,无须给管理员另外的登录界面,管理员进入系统后可以选择普通用户视角,也可以选择管理视角对整个系统进行管理。
(2)用户信息管理模块:包含用户信息的注册,用户信息的查看与修改。
(3)扫描模块:对指定URL进行扫描爬取,将爬取到的页面进行分析,如果页面内包含链接,则对链接继续爬取,依次递归下去。对于URL要设定爬取的边界,禁止爬虫爬到外网。
(4)过滤模块:将扫描模块爬取到的内容按照设定好的积极词与消极词敏感词典进行过滤,如果有网页被过滤出敏感词,那么就将该网页的URL展示出来,再将包含敏感词的整个句子都展示出来,并且标记处敏感词的位置。过滤的时候先替换积极词,后过滤消极词。
(5)字典模块:对于某些积极词汇,比如“反对台独”,会因为“台独”二字而被过滤出来,将“反对台独”加入积极词典,这样先替换“反对台独”为特殊字符,再过滤“台独”时就不会出现敏感词匹配的现象。因此,界面上要有加入积极词典的功能按钮。总的来说,正是由于有了字典模块,才使得整个系统具有学习与更新能力。
(6)管理员管理模块:管理员进入管理界面后,可以对新申请的用户进行审核,通过审核的用户才可以登录。如果有大量用户注册,还可以进行搜索。对于每一个用户,管理员可以查看、修改用户的基本信息,可以重置用户的密码,还可以删除用户。管理员还有查看最近30天扫描行为日志的功能。对于日志,可以按日期或用户名搜索,还可以将日志输出。
4 系统实现
整个系统的界面与业务逻辑,全部使用Python编程语言实现,版本为3.7。编程环境为Pycharm社区版,其中使用的编译器以及各种类库通过 Anaconda来实现。数据库使用 MySQL,网络连接使用宽带网络或者4G通信网络。计算机系统配置为:Windows10 64位,志强E-2697处理器,DDR3 32G内存。
4.1 界面实现
Python的界面编程库有Tkinter,wxPython,OpenGL,PYQT5等,其中PYQT5可以作为工具加载到编程环境里,而且PYQT5的界面编程具有可拖拽控件的优势,UI文件与Python文件也可以相互转换,综上所述本文选用PYQT5作为界面开发工具。
PYQT5在线程编程时无法使用Python原生的threading,而是必须继承PYQT5专用的线程类QThread作为父类,也即class MyThread(QThread)。在设置线程间通信的时候,要使用PYQT5的信号与槽函数机制,先定义triger = pyqtSignal(),然后连接需要被激活的函数triger.connect(someClass.scan),在需要发射信号的时候triger.emit(),这个时候someClass.scan()函数就会接收到信号进而执行。如果是鼠标点击触发本界面信号,可以直接使用已定义好的函数来连接槽函数,例如:self.closeWinBtn.clicked.connect(Form.close)来关闭本界面。在设置菜单栏的时候,需要先定义MenuBar,其中每个菜单是一个menu,例如:self.menubar = QtWidgets.QMenuBar(self.form)self.systemMenu = self.menubar.addMenu("选项"),在菜单下的二级菜单是Action,使用的时候也是先定义Action,再添加到上面的Menu,例如:self.startScanAction = QAction("开始扫描",self.form)self.systemMenu.addAction(self.startScanAction)。在管理员审核界面,用户信息的展示用到的是QListWidget,本文对该模块设置了右击功能,也即对于每一个显示的用户,右击之后可以出现相应的选项。在设置右键功能的时候使用的语句如下:先增加右击功能:setContextMenuPolicy(Qt.CustomContextMenu),再连接对应的函数:customContextMenuRequested[QtCore.QPoint].connect(self.rightMenuShow)。

图2 程序架构
整个程序的架构如图2所示,BusinessLogic里是与界面相关的业务逻辑,包括程序入口以及与数据库的连接等。Scan里是与扫描过滤有关的业务逻辑,在实际中会被BusinessLogic调用执行。UI里面是PYQT5生成的界面文件,与BusinessLogic是相互调用的关系。
4.2 爬虫实现
本文使用了目前比较流行的爬虫技术BeautifulSoup4,它是一个Python库,能分析已下载的HTML或XML文件,也可直接通过链接来分析远程网页数据。
在爬取网页的时候,还要安装requests库和lxml库来配合使用,使用过程如下:html = requests.get(url) bsObj = BeautifulSoup(html.content, 'lxml'),通过上述语句得到BeautifulSoup对象,然后再通过对标签<a>的过滤,就能得到该url所有的内含链接:allLinks= bsObj.findAll("a"),得到的allLinks是一个链接组成的列表。在爬取的时候为了防止爬到外面的网络,要设置过滤条件,例如可以这样设置:if ("sxyyc" in url) or ("school" in url)。抓取的页面数据,最终以字典{url:content}的形式存储于本地文件中。
4.3 过滤实现
本文使用敏感词直接匹配的方法来进行过滤。考虑到下面的情况:“反对台独”会因为敏感词“台独”而被过滤出来,本文设计了两个词库:一个积极词库,一个消极词库。首先对积极词库进行匹配与替换特殊符号,这样再通过消极词库过滤时就不会被过滤出来。本文替换的特殊符号设置为4个““过号。
4.4 数据存储:
本文使用MySQL数据库来保存相关信息,一共设计了5个表,它们分别是管理员信息表 AdminLogin,管理员重置用户密码表AdminResetUserPW,普通用户(已审核)信息表UserLogin,普通用户(未审核)信息表UserNewReg,日志信息表UserScanLog。
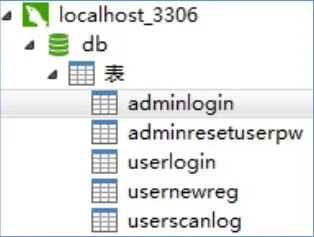
图3 数据库内的表
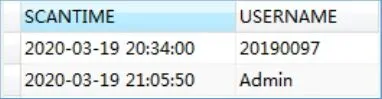
图4UserScanLog表
对于 AdminLogin表设计了两个字段:UserName(用户名)、UserPassword(用户密码)。对于AdminResetUserPW表设计了两个字段:UserToBeReset(需重置的用户)、PasswordToBeReset(需被重置的密码)。UserNewReg存放的是新注册用户的信息,设计的字段如下:UserName(用户名)、UserPassword(用户密码)、RealName(真实姓名)、Email(邮箱)、TEL(电话)、ApplyTime(注册时间)。UserLogin表里存放的是已通过审核的用户信息,因此里面多设置了一个AgreeTime(审核通过时间)字段。UserScanLog存放的是扫描的日志信息,设计了两个字段:ScanTime(执行扫描的时间)、UserName(用户名)。这里的时间都是采用数据库服务器的时间,通过语句“用户名)。这里的时间都是采用数据库服务(),CURRENT_TIME()”来获得。
4.5 界面展示
普通用户在使用本软件时需要先注册,注册时候“工号”、“密码”、“真实姓名”三项是必填项,注册的界面如图5所示。账号注册完后系统会将信息写入数据库,成为“新申请用户”,等待管理员审核。管理员审核通过,该账号就能使用,管理员审核的界面如图6所示。用户登录后的界面如图7所示,点击“扫描”按钮将会进行扫描与过滤两个步骤。由于一般站点包含页面数量都是104数量级,所以扫描耗时都会在数分钟以上,如果想再次扫描过滤,此处可以使用“直接过滤”按钮,系统将会直接使用上次扫描爬取的数据而不用重新再爬取过滤。如果想修改敏感词典,可以直接在安装目录里对敏感词典文件进行增加或删除操作。为了方便,系统在界面上也提供了对于积极词词典的添加操作。
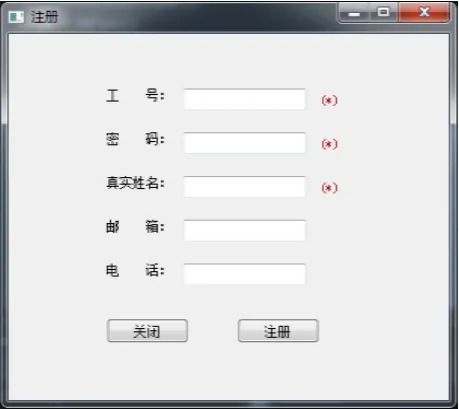
图5 注册界面
管理员可以对用户信息进行查询、修改、删除操作,还可以对其密码进行重置。如果用户较多,系统还提供了查询功能,输入账号就可以定位到要查询的用户。系统还为管理员提供了日志查询功能,当点击“查看日志”按钮后管理员可以查看近三十天的扫描日志,了解都有哪些用户在什么时间对目标URL进行了扫描,查看日志界面如图所示。这里也提供搜索功能,可以按时间或用户名来搜索。如果点击“输出日志”按钮,就可以将上述的日志进行输出,输出日志的界面如图所示。
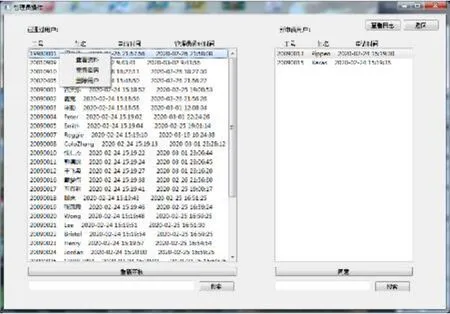
图6 管理员审核界面
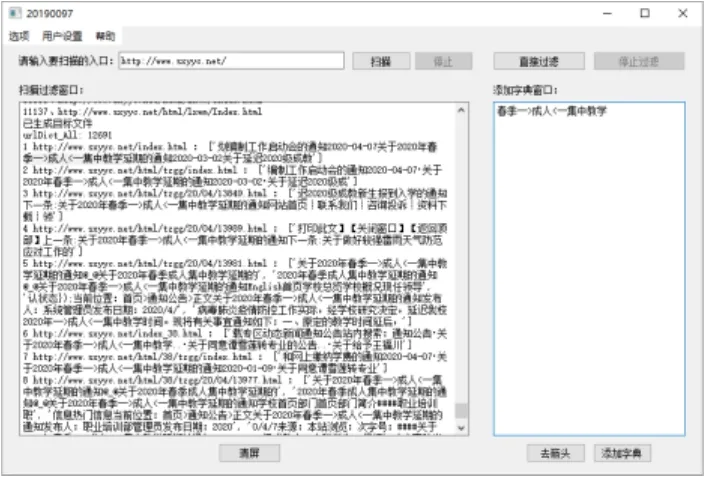
图7 用户扫描与过滤界面
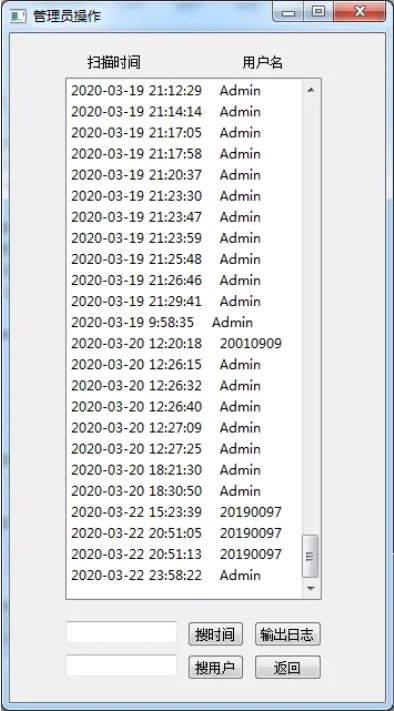
图8 管理员查看日志功能
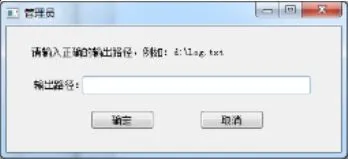
图9 日志输出功能
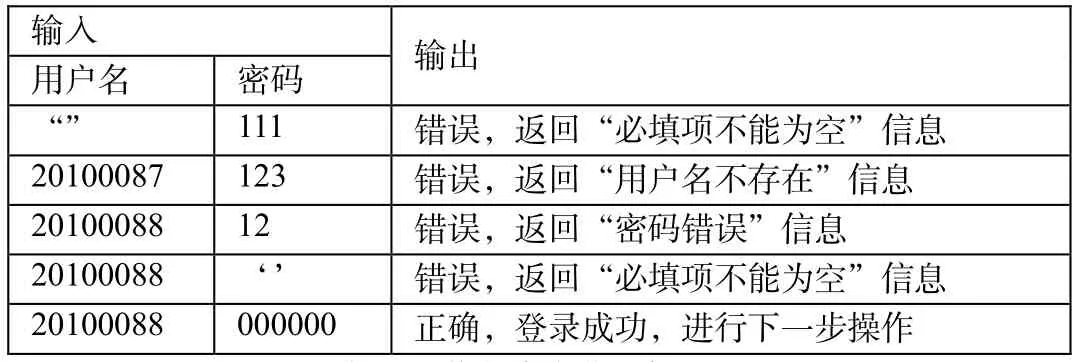
表1 用户登录用例测试
4.6 测试
下面对用户登录、网络状态变化、数据库管理、敏感词过滤功能进行测试,测试过程以及结果如表1-4所示。

表2 网络状态变化用例测试

表3 数据库用例测试
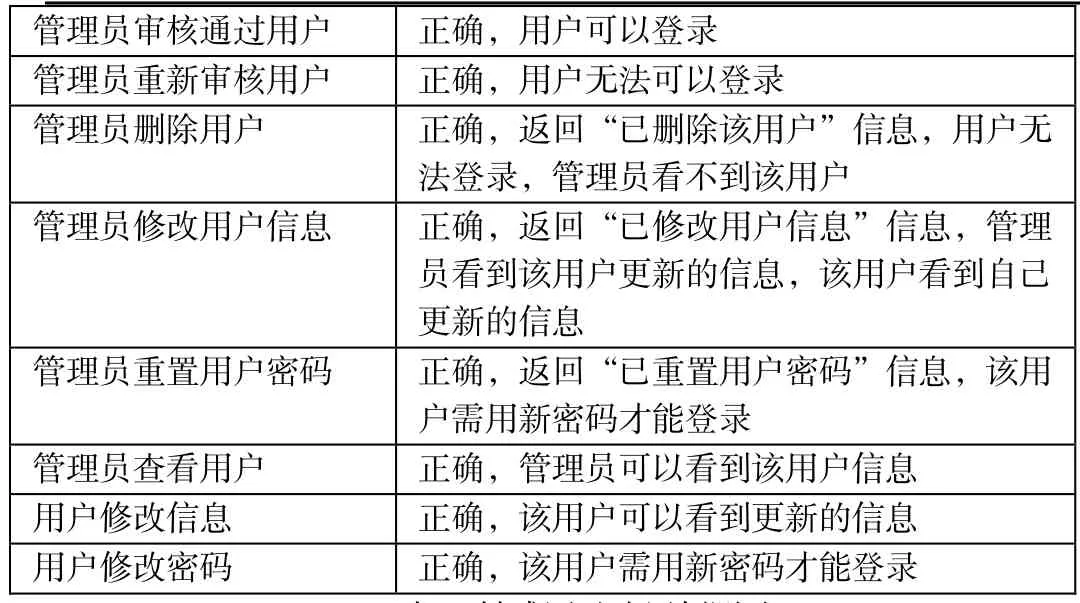
管理员审核通过用户 正确,用户可以登录管理员重新审核用户 正确,用户无法可以登录管理员删除用户 正确,返回“已删除该用户”信息,用户无法登录,管理员看不到该用户管理员修改用户信息 正确,返回“已修改用户信息”信息,管理员看到该用户更新的信息,该用户看到自己更新的信息管理员重置用户密码 正确,返回“已重置用户密码”信息,该用户需用新密码才能登录管理员查看用户 正确,管理员可以看到该用户信息用户修改信息 正确,该用户可以看到更新的信息用户修改密码 正确,该用户需用新密码才能登录
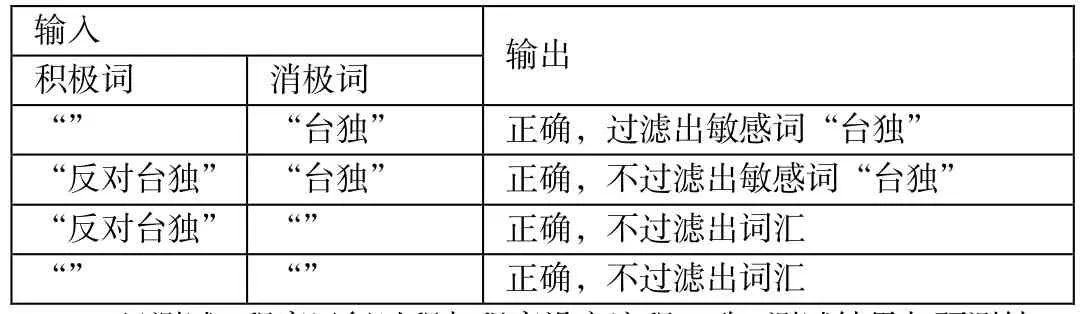
表4 敏感词过滤用例测试
经测试,程序运行过程与程序设定流程一致,测试结果与预测结果一致。分别在宽带网络与4G通信网络环境下,响应、缓冲、存储耗费的时间都在毫秒级别,能满足用户需求。系统中登录模块、用户信息管理模块、扫描模块、过滤模块、字典模块、管理员管理模块功能测试和性能测试都达到了需求中的规定和预期效果。
5 结论
在网络安全越来越凸显重要的时代背景下,针对重庆三峡医药高等专科学校的网站群数据监测,提出一种基于敏感词过滤的站群数据监测系统。系统共设计五个模块,提供普通用户与管理员用户两种视角,数据监测人员可以方便的使用该系统来减轻自己的工作量。
由于对敏感词直接过滤,因此在实际应用中会出现一个词的结尾汉字与另一个词的开头恰好组成一个“敏感词”的情况,这是系统在后续工作中需要改进的地方。
