在微控制器芯片实现神经网络的方法
2020-12-07刘明曹银杰耿相珍胡卫生
刘明 曹银杰 耿相珍 胡卫生


摘 要: 针对微控制器芯片尚未存在使用神经网络处理时序信号的现状,提出一种可以在微控制器上进行神经网络训练、预测时序信号的方法。 该方法不基于操作系统运行神经网络程序,无法由操作系统进行栈区空间大小的调整以及内存的分配问题,为了解决这个问题,更改了初始化栈区空间的大小,增加了外部扩展SDRAM芯片,使之达到适合神经网络程序运行的大小。在微控制器芯片实现神经网络的方法包括定义了实现神经网络需要的矩阵运算,使用C语言编写并封装LSTM循环神经网络前向传播函数,反向传播函数,以及LSTM循环神经网络的权重更新函数。调用封装好的LSTM循环神经网络函数进行实验,以时序信号sin x函数为例,预测信号变化。故使用该方法,可不依赖操作系统在微控制器芯片建立神经网络,具备了稳定、实时可靠的优点。
关键词: 微控制器芯片; 神经网络; LSTM; 栈区空间; 内存分配; 时序信号处理
中图分类号: TN711?34; TP39 文献标识码: A 文章编号: 1004?373X(2020)22?0001?05
Abstract: In allusion to the fact that there is no current situation of using neural network to process timing signals on microcontroller chips, a method of neural network training and predicting timing signals on microcontroller is proposed. In this method, the neural network program is not operated based on the operating system, and the adjustment of the size of the stack space and the memory allocation cannot be performed by the operating system. On this basis, the size of the initial stack area is changed, and the external extended SDRAM chip is added, so as to make the microcontroller chips suitable for the size of the neural network program to run. The method of implementing neural network on microcontroller chip includes the definition of the matrix operation needed to realize the neural network, writing and packaging LSTM (Long Short?Term Memory) recurrent neural network forward propagation function, back propagation function, and weight update function of LSTM recurrent neural network. The encapsulated LSTM recurrent neural network function is called to perform experiments, and the timing signal sin x function is taken as an example to predict the signal changes. In this method, the neural network can be established in the microcontroller chip without operating system, which has the advantages of stability, real?time reliability.
Keywords: microcontroller chip; neural network; LSTM; stack area; memory allocation; timing signal processing
0 引言
在2018年中国国际嵌入式大会上,何积丰院士提出,人工智能存在向嵌入式系统迁移的趋势[1]。在嵌入式系统上玩转人工智能,是这个智能化时代前沿的研究。目前嵌入式系统人工智能主要使用Cortex?A系列微处理器芯片,A系列微处理器芯片主要面向手機、平板电脑等民用商品,属于消费类电子,实现人工智能需要依赖操作系统,不具备稳定性,不适合应用在军事、工业、信号处理等领域。Cortex?C系列微控制器芯片是单一功能的、更加专业的芯片,具备低功耗、低成本、实时、稳定可靠的特性,被广泛应用在军事、工业、信号处理等方面,但目前还未发现在微控制器芯片上建立神经网络,做人工智能的研究。
循环神经网络算法是神经网络算法的一种,常用来学习、识别、预测时序信号,若能在Cortex?C系列微控制器芯片上搭建循环神经网络,只需要输入信号,用理想输出作为监督学习,多次训练后,即可进行信号智能处理、信号智能识别、信号智能预测等工作。使用Cortex?C系列微控制器芯片搭建循环神经网络,处理时序信号,更加智能、稳定可靠。搭建循环神经网络需要进行一系列矩阵运算,Cortex?M系列微控制器芯片已经具备DSP指令,所有的DSP指令都可在一个机器周期内完成,提高了矩阵运算速度。本文结合当前的研究现状提出一种针对Cortex?M系列微控制器芯片建立的循环神经网络方法,使用循环神经网络对时序信号进行学习,并预测未来的信号。
1 LSTM循环神经网络
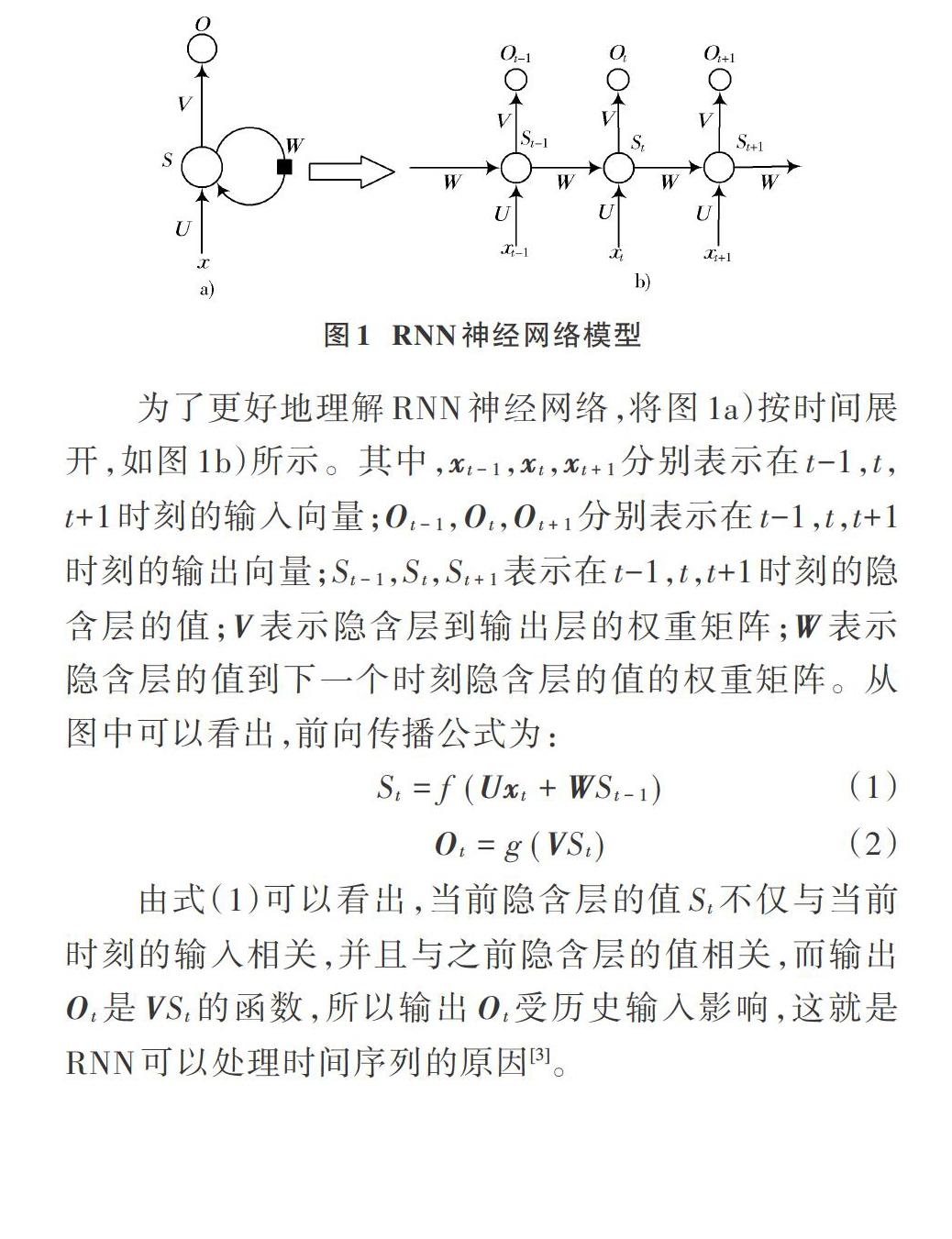
对于时间信号的预测,常常使用循环神经网络(Recurrent Neural Network),简称RNN神经网络。一个简单的RNN神经网络可以表示为图1a)的形式。图1a)中,[x]表示输入向量;[O]表示输出向量;[U]表示输入层到隐含层的权重矩阵;[V]表示隐含层到输出层的权重矩阵;[S]表示隐含层的值;[W]表示隐含层的值到下一个时刻隐含层的值的权重矩阵[2]。
为了更好地理解RNN神经网络,将图1a)按时间展开,如图1b)所示。其中,[xt-1],[xt],[xt+1]分别表示在t-1,t,t+1时刻的输入向量;[Ot-1],[Ot],[Ot+1]分别表示在t-1,t,t+1时刻的输出向量;[St-1],[St],[St+1]表示在t-1,t,t+1时刻的隐含层的值;[V]表示隐含层到输出层的权重矩阵;[W]表示隐含层的值到下一个时刻隐含层的值的权重矩阵。从图中可以看出,前向传播公式为:
由式(1)可以看出,当前隐含层的值[St]不仅与当前时刻的输入相关,并且与之前隐含层的值相关,而输出[Ot]是[VSt]的函数,所以输出[Ot]受历史输入影响,这就是RNN可以处理时间序列的原因[3]。
RNN神经网络在处理长时间的信号序列时会产生梯度消失或梯度爆炸,为了克服这个缺点,将RNN进行改进,在RNN的基础上,加入长期状态C,用来保存长期状态,从而达到解决RNN梯度消失和梯度爆炸的缺陷,改进后的RNN神经网络被称作LSTM(Long Short?Term Memory)神经网络[4]。LSTM中主要使用3个门,分别是遗忘门、输入门、输出门以及即时状态来控制长期状态。遗忘门负责决定之前的长期状态对当前的长期状态影响程度;输入门与即时状态共同负责决定当前输入对长期状态的影响程度;输出门决定当前长期状态对输出的影响程度[5]。LSTM神经元如图2所示。
前向传播过程需要计算遗忘门输出[ft],输入门输出[it],即时状态输出[C′t]以及输出门输出[Ot]。长期状态[Ct]由遗忘门输出[ft]、输入门输出[Ot]、即时状态输出[C′t]和上一时刻的长期状态[Ct-1]共同决定。
2 实现LSTM循环神经网络
Cortex?M系列芯片具有稳定可靠、实时、低成本、低功耗的优点,被广泛应在工业控制、军事、信号处理等领域。由于Cortex?M系列微控制器芯片在建立神经网络时,不能由操作系统自动分配内存以及栈区空间,为了确保神经网络程序能够正常运行,需要人为扩展内存及扩大栈区空间。
Cortex?M系列芯片一直被定位在低性能端,但是仍然比许多传统处理器性能强大很多,例如Cortex?M7处理器,最高时钟频率可以达到400 MHz。Cortex?M7处理器是针对数据处理密集的高性能处理器,具备面向数字信号处理(DSP)的指令集,支持双精度浮点运算,并且具备扩展存储器的功能,使用搭载Cortex?M7处理器的芯片,实现机器学习、人工智能,具备低功耗、低成本、稳定可靠的优点。
选择以搭载Cortex?M7处理器的STM32F767IGT6芯片为例实现LSTM循环神经网络,STM32F7使用Cortex?M7内核,在数字信号处理上增加了DSP指令集,大大提升了芯片的计算速度。ARM公司提供了DSP算法的库(CMSIS_DSP),具备了部分矩阵运算的功能,减少了开发的时间以及难度,并使运算速度有了进一步的提升[6]。
2.1 ARM芯片中的矩阵运算
在STM32上实现LSTM,要解决矩阵、向量运算的问题。进行矩阵、向量运算,需要的内存空间比较大,所以需要对芯片进行内存扩展。LSTM的权重矩阵需要进行存储,权重矩阵的维数直接关系到神经网络的学习能力,通过内存扩展可以确保权重矩阵维数满足需求,不会使神经网络的学习能力过低。在实现LSTM的过程中,用到很多矩阵运算和向量运算,使用ARM公司提供的CMSIS_DSP库中的矩阵处理函数,可以解决部分矩阵运算,提高运算速度。CMSIS_DSP库中,用结构体arm_matrix_instance_f32表示矩阵,结构体的元素numRows表示矩阵的行,numCols表示矩阵的列,pData指向矩阵数组,矩阵元素为32位无符号float类型,可以满足数据精度要求。
用arm_matrix_instance_f32结构体定义结构体数组,用来存放张量(由数组构成的数组),使用张量,来存储历史时刻门的输出值[7]。
CMSIS_DSP库中有矩阵的基本运算,如矩阵的加法、转置、乘法等,在LSTM神经网络算法中需要用到对矩阵元素的操作,例如矩阵按元素相乘,可以选择使用for循环遍历整个矩阵的方式访问到每一个矩阵元素。
定义生成随机矩阵的函数,输入值为要生成矩阵的行NumRows,列NumCols,以及这个矩阵是否被作为偏置矩阵使用。若生成权重矩阵,则使用C语言中的随机数函数rand(),遍历矩阵赋值随机数;若生成偏置矩阵,则将矩阵所有元素初始化为0。
无论是前向传播还是反向传播时,都会用到矩阵按元素相乘,但CMSIS_DSP库中并没有矩阵按元素相乘的函数,所以需要定义。定义矩阵按元素相乘的函数为mul2,它有两个输入,即两个按元素相乘的矩阵,先判断这2个矩阵的维数是否相同。因为按元素相乘,要求2个矩阵必须维数一样,才能进行运算。使用for遍历矩阵中的每一个值,让2个矩阵对应位置上的元素进行相乘,并返回相乘后的新矩阵。此时新矩阵的维数应该和输入矩阵的维数相同。
使用两个矩阵按元素相乘函数mul2,去构造3个矩阵按元素相乘的函数mul3。mul3有3个输入,首先经前2个输入送到mul2中进行按元素相乘,再将结果与第3个输入放到mul2中进行计算,这样可以获得连续3个矩阵按元素相乘,同理可以获得mul4,mul5。
2.2 LSTM循环神经网络的函数封装
LSTM中用到两个激活函数Sigmoid()和tanh(),以及它们各自的导数,由于CMSIS_DSP中没有按元素操作的函数,所以这里只能选择使用for循环遍历矩阵中的每一个数组。定义函数SigmoidActivator,它有两个输入,输入矩阵,以及模式选择,将输入的矩阵按元素进行计算,若mod为0,则输出[sigmoid(x)=11-e-x],若mod为1,输出[y′=sigmoid(x)′=y(1-y)]。同样,定义函数TanhActivator,若mod为0,则输出[tanh(x)=ex-e-xex+e-x],若mod为1,输出[y′=tanh′(x)=1-y2]。
将遗忘门、输入门、输出门以及即时状态的计算,封装为一个函数calc_gate,这个函数有6个输入,分别为输入向量[x],权重矩阵[Wx],[Wh],偏置矩阵[b],使用sigmoid激活函数或tanh激活函数的标志,以及使用激活函数本身或使用激活函数的导数标志。函数的输出为门的输出或者即时状态,公式如下:
按照LSTM循环神经网络计算,在前向传播、反向传播过程中,使用由矩阵组成的张量进行表示,并将这些张量定义为全局变量,用来存储历史时刻的各个门的值,这需要较大内存空间。由于芯片内存空间有限,不能由操作系统调整内存,这里的张量存储门历史时刻的值,不能设置为无限大小,根据自己内存大小,定义最多保存N个历史时刻的值。若存储时刻数量已经大于N,则将最早的数据删除。在这里删除最早时刻的历史值对最后的输出并不会产生较大的影响,因为最早时刻的值产生的影响,已经通过影响之后的时刻,保存了下来。为了确保保存历史时刻的值不会太少,需要增加内存大小。
2.3 实现LSTM神经网络的前向传播
利用封装好的LSTM循环神经网络函数,实现前向传播。前向传播流程如图3所示。
定义orward函数,输入为输入向量,为了记录前向传播的次数,使用全局变量times来记录前向传播的次数,也就是时刻times。根据LSTM门的计算理论公式,编写程序计算遗忘门、输入门、输出门以及即时状态的输出,并将输出的结果保存到相对应的结构体数组中的times位置。使用计算所得的遗忘门、输出门、即时状态的输出以及上一时刻的长期状态,计算当前时刻的长期状态:
式中,“[?]”表示按元素相乘。此处使用之前定义好的矩阵,按元素相乘函数mul2,将[Ot],[tanh(C)]输入mul2,输出结构赋值给[ht]。将LSTM神经元的输出[ht]保存在h_list[]中,存放位置为times,即h_list[times]。合理设置权重矩阵大小,達到既能满足使用需求,又不超过产生过拟合的效果[8]。
至此,在微控制器芯片上已经实现LSTM循环神经网络的前向传播[9]。
2.4 实现LSTM神经网络的反向传播
实现反向传播之前,定义误差函数Error_fun,LSTM反向传播使用BPTT(Back Propagation Through Time)算法,属于监督学习,故误差函数有两个输入,一个是LSTM神经元的输出,另一个是理想值。CMSIS_DSP库中有矩阵减法arm_mat_sub_f32,可以实现[y-y] 矩阵相减,arm_mat_scale_f32常数与矩阵的乘法函数可以实现[12] 与矩阵相乘。这里还需要矩阵按元素相乘,所以选择使用for循环遍历的方法。定义误差函数的返回值为:
反向传播过程中,计算量较大。程序中,由函数调用函数的情况比较多,临时变量在函数进行调用时,需要暂存到栈区中,起始文件默认初始化的1 KB的栈区大小不能满足使用,程序运行时,会触发异常,导致程序不能正常运行。将起始文件中栈区的大小进行调整,使栈区的大小足够满足程序运行的需要,可解决这个问题。
3 实验与分析
在STM32F7开发板进行实验,STM32F767IGT6本身自带512 KB的SRAM,为满足LSTM循环神经网络程序的正常运行,开发板上外部扩展32 MB的SDRAM芯片W9825G6KH,以及在启动文件中进行修改,将Stack_Size EQU 0x00000400,更改为Stack_Size EQU 0x00050000,使栈区空间扩大为5 MB。
以预测sin x函数为例,在STM32F7芯片上建立LSTM循环神经网络。
1) 建立样本集合,设置时间间隔为[Δt=π5 000],即一个周期内取10 000个数据,将连续10个点的数据作为输入向量[x],使用10个点的数据预测第11个点的值。
2) 将输入向量输入到循环神经网络中进行前向传播,因使用的BPTT反向传播算法为监督学习,故用sin x函数的第11个点作为监督,与神经网络输出值进行比对,将误差传入LSTM循环神经网络反向传播进行计算,并更新权重值。
3) 将实验结果显示在LCD显示屏幕上,见图4。
根据表1部分误差点数据显示,预测值与实际值之间存在误差,误差较大的点主要集中在sin x函数的极点附近。由于使用float数据类型,只能保留7位有效数字,训练时最高精确到小数点后6位,所以预测结果存在误差。经过多次实验得出,提高训练次数,可降低误差[12]。
4 结 论
本文对于如何在Cortex?M系列微控制芯片上搭建LSTM神经网络进行了介绍,并且以搭载Cortex?M7处理器的STM32F767IGT6芯片为例,实现了对于时间序列sin x函数的预测,预测的sin x函数与实际的sin x函数重合,由于使用的数据类型为float,有效数字最多为7位,最高精确到小数点后6位,实验时存在误差,可以提高训练次数,尽可能减小误差,但误差不可完全消除。