基于变分自编码器的日线损率异常检测研究
2020-12-07张国芳刘通宇温丽丽郭果周忠新袁培森
张国芳 刘通宇 温丽丽 郭果 周忠新 袁培森
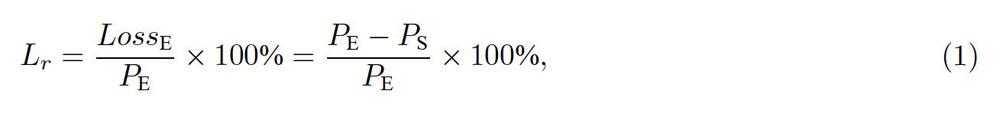

摘要:采用一种基于自编码器的异常检测算法,实现大规模日线损率数据的异常检测。变分自编码器是一种利用反向传播算法使得输出值近似等于输入值的神经网络,使用自编码器将原始日线损率时间序列编码,在重建过程中记录每个时间点的重建概率,当重建概率大于指定阈值时就判定其为异常数据。本文利用真实日线损数据进行实验,试验结果表明,基于自编码器的日线损率异常检测算法具有较好的检测效果。
关键词:自编码器:异常检测:日线损率
中图分类号:TP391 文献标志码:A DOI:10.3969/j.issn。1000-5641.202091013
0引言
随着电力智能化建设,“智能电网”这一概念的不断深入研究,我国电网企业的数据服务水平得到了较大提高。目前电力企业普遍建立了数据中台,构建了统一的、可复用的大数据平台对海量电能量数据进行管理和分析,形成了将数据变成资产并服务于业务的良性机制。为了深化数据中台对于电力企业智能化建设的作用,需要对不同时间、不同地点采集到的电能量数据进行统一的标准化和异常值检测,以提高数据整体的应用价值。
目前,电能量数据呈现出规模海量、多源异构、多时空尺度、多维度等大数据特征,数字孪生作为实现物理世界和信息世界智能互联与交互融合的一种潜在的有效途径,近年来被有关学者和电力企业高度关注。为了满足和适应智能化、服务化、绿色化的电能企业服务需求,数字孪生对于制造物理世界和信息世界的交互共融具有指导意义。电能损耗作为电力企业经济效益的重要指标,是电力企业数据中台的重要业务数据。电能损耗数据又以日线损率为代表,这是数字孪生技术重要的应用领域。通过对线损数据进行连续采集和智能分析,可以预测维护工作的最佳时间点,为维护周期的制定提供参考依据,也可以提供故障点和故障概率的参考。综上所述,对于日线损率的异常检测方法的研究对于构建电力企业数据中台和推动数字孪生的发展具有一定意义和指导作用。
当前,基于数据的线损异常检测主要有以下几种常用的方法:基于人工神经网络的异常检测、基于聚类的异常检测、基于无监督学习的异常检测。基于人工神经网络的异常检测主要包括基于BP神经网络的异常值检测,其思想是利用BP神经网络的预测值与线损数据进行比较,如果差值大于阈值则认定为异常样本点;基于聚类的异常检测,以基于DBSCAN聚类的异常检测为代表,其思想是通过聚类得到聚类簇,认定离群点作为异常样本点;基于无监督学习的异常检测,以基于孤立森林的异常值检测为代表其思想是构建孤立森林的数据结构,通过这种二叉树结构可以快速判断样本点与周围样本点的差异程度,给定异常值评分以确定异常样本点。
自编码器fAuto-Encoder)是一类在半监督学习和非监督学习中使用的人工神经网络,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习。自编码器应用广泛,近年来被广泛应用于特征提取和图像修复等领域。自编码器按学习范式,可以被分为收缩自编码器、正则自编码器和变分自编码器(variational Auto-Encoder,VAE)。其中变分自编码器由于其对于噪声具有鲁棒性且重建误差小等优点,被广泛应用于电能领域,如宋辉等人将变分自编码器用于局部放电数据的匹配。变分自编码器同时也可以用于异常值检测,其基本原理是使用数据集训练得到编码器和解码器的默认参数,利用训练得到的编解码器计算待检测数据集的重建误差,如果重建误差过大,则说明该样本点包含噪声成分显著,有较大可能是异常样本点。
本文基于变分自编码器的原理,针对电力领域日线损率的异常检测问题,提出一种基于自编码器的日线损率异常检测方法,实现对海量日线损数据的异常检测。首先对日线损率的异常检测问题进行论述,接着说明基于自编码器的日线损率异常检测方法的具体实现,最后使用真实的电力集团的线损数据进行实验,与基于DBSCAN的异常值检测和基于孤立森林的异常值检测方法进行对比,结果表明本方法具有较好的异常值检测效果。
1异常数据的检测
1.1线损率的计算
电力网在输送和分配电能的过程中所产生的全部电能损耗,称为线损。线损包括技术线损和管理线损。技术线损是指经由输变配售设施所产生的损耗,可通过理论计算来获得;管理线损,是指在输变配售过程中由于计量、抄表、窃电及其他管理不善造成的电能损失。线损率的计算如式(1)所示。其中,LossE为线损电量,pr为供电量,ps为售电量。供电量=电厂上网电量+电网输入电量-电网输出电量。
日线损率数据形成时序序列,用于描述线损率随时间变化的情况。当时间序列数据在某一时刻发生突变时,该数据点则有很大可能是异常值。图1是2019年6月到2019年12月的日线损率时序曲线,可以看到在2019年10月下旬某一天日线损率数据发生突变,所以该日线损率很大概率是此时序数据中的异常值。
1.2时间序列异常检测
异常检测俐研究的是在不符合预期行为的数据中寻找模式的问题,这些不一致的模式被称为异常。异常值检测(Anomalies Detection)是数据挖掘中的核心问题和基础问题。在电能数据的分析中,由于电能量采集设备的故障或者其他人为原因会导致采集到的电能量数据产生异常。对于采集到的日线损数据,通过异常值检测发现异常样本点,有助于发现异常的用电行为和设备故障情况,对提高电能利用效率和降低线路线损具有指导意义。
1.3线损率异常
线损率常用来考核电力系统运行的经济性。本文的数据集来自某一电力企业所提供的2018年1月到2020年4月的日線损率数据,通过基于自编码器的异常检测算法找出存在异常的线损率数据。但值得注意的是,需要区分错误数据和异常数据的区别,日线损率应当是一个0-1的值,如果超出1则是一个错误数据,但并不是异常数据,应当在预处理的过程去除这些错误数据。得到预处理后的数据之后再对数据进行异常检测。
2基于自编码器的日线损率异常检测
自编码器(Auto-Encoder,AE)是一种通过无监督学习训练的神经网络,其训练目标是接近原始数据的重建。自编码器通常由编码器和解码器两部分组成。自编码器常用于数据压缩,编码器将一个数据x有损编码为低维的隐向量五解码器又可以将隐向量重建为数据X。
基于自编码器能够实现特征降维和重建的特性,自编码器可以应用于异常值检测。将原始数据送人自编码器进行处理,能够得到原始数据的低维嵌入,其中异常数据和正常数据预期能够彼此分离,得到那些较低维度的嵌入之后,经过重建被带回到原始数据空间。通过使用低维表示重建数据,期望獲得数据的真实性质,而能够产生异常的特征和噪声将会被忽略。因此对于样本的重建误差(原始数据点与重建数据的误差)可以反映一个样本点的异常程度,可以用作异常检测的异常分数。基于自编码器的异常值检测原理如图2所示。
变分自编码器(Variational Auto-Encoder,VAE)是自编码器的一种,其特点如下:
(1)变分自编码器的对象实际上是输入变量的样本均值和方差,是将输入变量编码成隐变量的分布,再从隐变量分布采样,将隐变量分布解码成输出变量的分布;
(2)变分自编码器的有2个编码器,分别用于对输人数据的均值和方差进行编码,其目的在于希望通过编码得到的分布具有均值为0、方差为1的标准正态分布;
(3)变分自编码器是在自编码器的基础上对编码器的结果加上了高斯噪声,使得解码器对于噪声具有鲁棒性;
(4)由于变分自编码器是对输人数据的统计描述进行编码和解码,因此编解码得到的重建误差是概率,称之为重建概率。
变分自编码器的编码器和解码器的神经网络示意图如图3所示,变分自编码器的原理示意图如图4所示。
将变分自编码器用于异常值检测,是根据上文所述的重建概率进行的,将重建概率作为每一个样本点的异常分数。由于重建概率与具体的量纲无关,因此使用变分自编码器进行异常值检测克服了异构数据异常值检测的困难,具有可变性;同时异常分数对于不同的数据集也具有可比性,实现了一种通用的客观方法来评估样本的异常性。
基于变分自编码器,利用自编码器用于异常值检测的原理,本文构建了一种基于变分自编码器的日线损率异常值检测,具体方法归纳如下:
(1)对原始日线损率数据进行预处理:a)对日线损率取绝对值;b)令数值不在0—1之间的日线损率样本的数值变为0;
(2)选取预处理后的正常的日线损率样本数据,送人变分自编码器进行训练,得到变分自编码器的默认参数;
(3)将预处理后待检测的日线损率样本数据送入完成训练的变分自编码器,计算每一个样本点的重建概率;
(4)对于每一个样本点,计算得到的重建概率与设定阈值进行比较,如果超过阈值,则输出该样本点为异常样本点,反之,则输出该样本点为正常样本点。
基于自编码器的日线损率异常检测方法的框架如图5所示。
2.1基于日线损率的自编码器构建
根据前文变分自编码器的原理,使用正常日线损数据对变分自编码器进行训练过程的描述见算法1。
算法1是通过反向传播来训练变分自编码器的,算法过程说明如下:
(1)参数Ф,θ是上述算法的输出,分别是编码器和解码器的参数;
(2)算法的第4行和第5行是分别对标准正态分布总体和输入数据的每一个样本进行编码,目的是使得编码的结果模拟和接近标准正态分布;
(3)其中第7行的E是变分自编码器的损失函数,是一个带正则项的负对数似然函数,其中第一项是KL散度正则项,用于衡量两个分布的近似程度,第二项的求和是重建损失,目的是让生成数据和原始数据尽可能接近。
2.2基于自编码器的日线损率异常检测
根据2.1所述的算法,要实现对于日线损率的异常检测,则首先需要使用正常的数据集训练一个自编码器,得到默认参数;接着用训练得到的自编码器计算异常数据的重建误差,对于一个样本,若重建误差大于某个阀值α,则判定为异常样本点,否则判定为正常样本点。
使用变分自编码器对日线损率进行异常值检测的描述见算法2.
算法2根据训练得到的变分自编码器进行编解码,并计算得到重建概率,算法说明如下:
(1)算法的第3行是使用编码器对输人数据进行编码,得到对于输入数据的描述统计(均值和方差);
(2)算法的第4行到第7行,是根据标准正态分布使用解码器对输人数据的描述统计进行重建;
(3)算法的第8行则是根据重建结果计算每一个样本点的重建概率,之后的第9行到第12行则是根据阈值进行判断,确定样本点是否为异常样本点。
3实验及结果分析
3.1实验环境
本文实验平台为Windows 10系统,8 GB内存,Intel(R)Core(TM)i5-7200U,2.5 GHz。算法采用Python 3.6.9实现。
3.2数据集和预处理
数据集采用某一电力企业提供的2018年1月1日-2020年3月30日的日线损率数据,共820条日线损率数据记录,包含电能量记录时间OCCURTIME、线损率RATE,共2个字段。
由于原始的日线损率数据可能包含无效数据,并且对于线损率的分析需要对其进行绝对值化处理,因此首先对原始的820条日线损数据记录的RATE字段进行绝对值化处理;接着由于线损率绝对值化之后应该在0-1区间内,因此RATE字段大于1的数据是无效数据,将该条数据记录的RATE值置0,以避免无效数据对自编码器的训练和异常值检测产生影响。
日线损率数据是一个时序数据,本文将上文所述的日线损率数据分割成更小的时间片段。比如2018年1月1日到2018年1月20日为第1个时间片段,2018年1月2日到2017年1月21日为第2个时间片段,2018年1月3日到2018年1月22日为第3个时间片段,以此类推,每20天为一个分割“窗口”,将上述时间段的日线损率数据每20天分割为800个更小的时间片段,将这些更小的时间片段作为训练集送人自编码器中进行编码。使用此神经网络对样本集预测得到的预测值相对于原始值存在误差,它会使得原始数据更加平滑。
3.3评价指标
异常值检测效果主要通过准确率(accuracy)、精确率(precision)、召回率(recall)以及综合评价指标n值(Fl-measure)这4个指标进行评价,设准确率为A,精确率为P,召回率为R2F1值为F,则:其中TP、TN、FP、FN分别表示异常点检测为异常、正常点检测为正常、正常点检测为异常、异常点检测为正常的样本点个数。准确率A反映了算法对异常点和非异常点识别的整体正确率,精确率P反映了算法识别得到的异常点是真实異常点的比率,召回率R反映了算法识别得到的异常点覆盖了真实异常点的比率,综合评价指标n则是综合了精确率P和召回率A得到的评价指标。
3.4实验过程和结果
在本方法中,对异常值检测效果的关键参数是THRESHOLD,由于本方法是根据每一个样本点经过自编码器的处理得到的重建概率来进行异常值检测的,因此该参数对于异常值检测的敏感度具有较大影响,需要选择一个合适的参数值以获得最佳的异常值检测效果。
使用清洗过的数据集运行本方法进行异常值检测,控制参数THRESHOLD的取值从0.1变化到0.3,步长为0.01,对于每一种取值进行5次实验并取平均,使用综合评价指标n值以评估异常值检测效果。实验结果如图6所示。
通过上述实验可以看出,当THRESHOLD取值为0.25时综合评价指标n取得极大值0.89,此时准确率A=0.9963,精确率P=1.00,召回率R=0.80,有着较好的异常值检测效果。当THRESHOLD的取值过小时,可以发现异常值检测效果急剧下降,表现为精确率大幅降低,其原因是阈值过小导致对重建概率的敏感程度过高,将日线损率的正常波动视为异常样本点;当THRESHOLD的取值过大时,也会导致异常值检测效果下降,表现为召回率下降,其原因是阈值过大导致放宽了对正常样本点重建误差的要求,进而导致忽视部分异常样本点,将该异常样本点视为正常样本点。
综上所述,对于日线损率的异常值检测,其重建概率的阈值即参数THRESHOLD的取值为0.25比较合适。以下实验均采用该值进行,以获得最佳异常值检测效果。参数设置如表1所示。
经过数据预处理和数据清洗,原始的日线损率数据如图7所示。
为了训练自编码器,还需要获取同地区并采用相同方式采样计算得到的日线损率时序数据,从中选取100个时间上连续并且不包含异常样本点的记录,经过预处理后作为训练集,进行自编码器的训练。训练完成后,对上文所述的820个样本点进行自编码器的编码和解码以计算重建概率,每一个样本点计算得到的重建概率如图8所示。
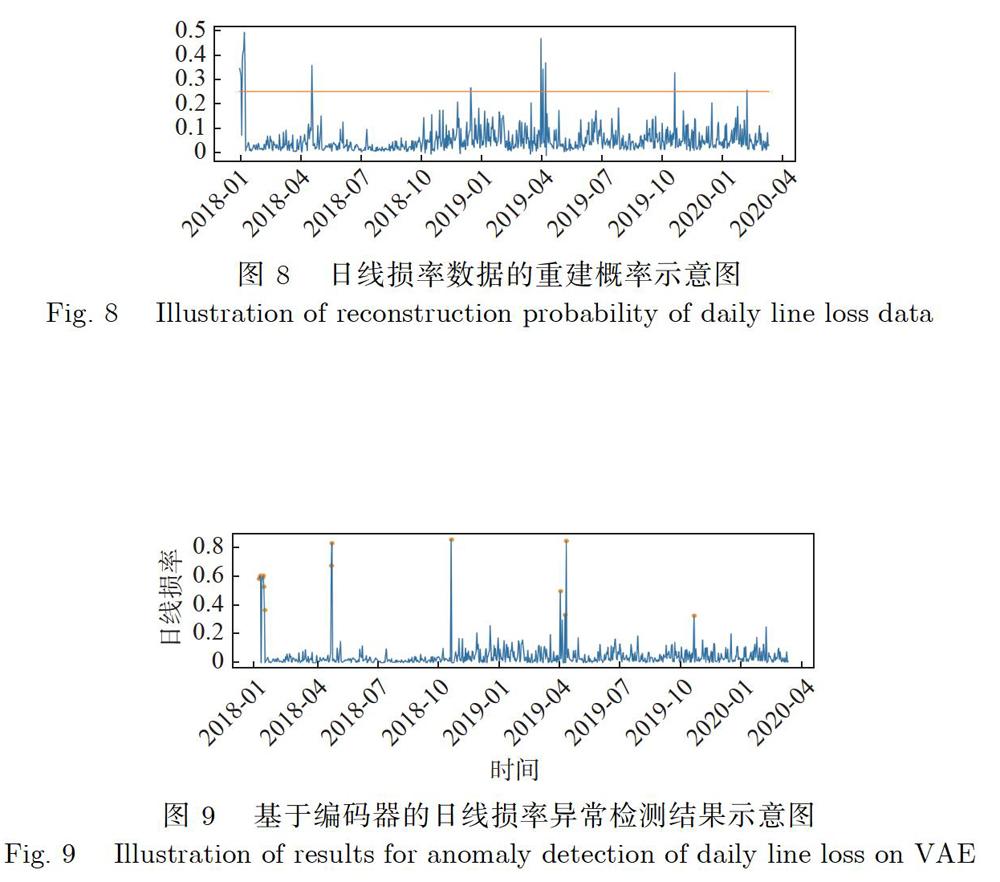
对所有样本点的重建误差进行检测,将误差超出阈值THRESHOLD的样本点进行标记,认定为异常样本点,异常值检测结果如图9所示,异常样本在图中使用黄色圆点标注,基于自编码器的异常检测算法总共找到了15个异常样本。
从异常值检测结果中可以看出,该方法对于日线损率的异常有较好的检测效果:日线损数据发生突变的部分能够进行检测,同时也能够容忍日线损数据的正常波动,不会将这类样本认定为异常样本。
下面将本方法和其他两种在电能数据异常值检测领域常用的方法:孤立森林算法和基于DBSCAN的异常值检测算法进行异常值检测效果的对比。本方法设置的参数如表1所示,孤立森林算法的参数设置为:MaxSamples=128,Trees=100,Alpha=0.02;基于DBSCAN的异常值检测算法参数设置为:MinSamples=5,Eps=0.05.实验结果如表2所示。
实验结果显示,本方法在这3种异常检测算法中准确率最高,相较于孤立森林算法和基于DBSCAN的异常值检测算法准确率分别提高了3.518%和2.049%,说明对于异常样本点和正常样本点具有很好的识别效果;同时本方法的精确率也最高,达到了100%,相较于孤立森林算法和基于DBSCAN的异常值检测算法分别提高了26.31%和20.00%,说明检测得到的异常样本全部为真实异常样本,因此本方法的异常检测结果具有很高的可信度;本方法相较于孤立森林算法,参照综合评价指标n提高了0.7023%,异常值检测的综合效果略有提高;但是召回率相较于孤立森林算法较差,孤立森林算法对于日线损率的异常检测召回率更高,本方法只能覆盖大部分异常样本点,对于一些异常样本点会将其认定为正常样本点。
对于日线损率的异常值检测,本方法对于异常样本的敏感程度适中,不会将存在正常波动的样本点识别为异常。综上所述,本方法相较于孤立森林算法和基于DBscAN的异常值检测算法,在准确率和精确率上有更加优秀的表现,有着较好的异常检测效果。
4结论
本文基于变分自编码器的原理,针对电力领域日线损率的异常检测问题,提出了一种基于自编码器的日线损率异常检测方法,实现对海量日线损数据的异常检测。首先对日线损的异常检测问题进行论述,接着说明基于自编码器的日线损率异常检测方法的具体实现,最后使用真实的电力集团的线损数据进行实验,与基于DBscAN的异常值检测方法和基于孤立森林的异常值检测方法进行对比,结果表明本方法具有较好的异常值检测效果。
