通过细粒度的语义特征与Transformer丰富图像描述
2020-12-07王俊豪罗轶凤
王俊豪 罗轶凤


摘要:传统的图像描述模型通常基于使用卷积神经网络(convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)的编码器一解码器结构,面临着遗失大量图像细节信息以及训练时间成本过高的问题,提出了一个新颖的模型,该模型包含紧凑的双线性编码器(compact BilinearEncoder)和紧凑的多模态解码器(compact Multi-modM Decoder),可通过细粒度的区域目标实体特征来改善图像描述,在编码器中,紧凑的双线性池化(compaet Bilinear Pooling,CBP)用于編码细粒度的语义图像区域特征,该模块使用多层Transformer编码图像全局语义特征,并将所有编码的特征通过门结构融合在一起,作为图像的整体编码特征,在解码器中,从细粒度的区域目标实体特征和目标实体类别特征中提取多模态特征,并将其与整体编码后的特征融合用于解码语义信息生成描述,该模型在MicrosoftCOCO公开数据集上进行了广泛的实验,实验结果显示,与现有的模型相比,该模型取得了更好的图像描述效果。
0引言
图像描述的主要任务是为图像生成自然语言描述,并利用所生成的描述帮助应用程序理解图像视觉场景中表达的语义,例如,图像描述可以将图像检索转换为文本检索,用于对图像进行分类并改善图像检索结果,人们通常只需快速浏览一下即可描述图像视觉场景的细节,但对计算机而言,自动为图像添加描述则是一项全面而艰巨的任务,需要将图像中包含的复杂信息转换为自然语言描述,与普通的计算机视觉任务相比,图像描述不仅需要从图像中识别目标实体,还需要将识别出的目标实体与自然语义相关联以使用自然语言进行描述,因此,图像描述需要人们提取图像的深层特征,与语义特征关联并进行转换以生成描述。
早期图像描述方法大多基于传统机器学习,倾向于从图像中提取目标实体和属性,然后将获得的目标实体和属性填充到预定义的句子模板中,随着深度学习的普及,近些年的图像描述方法主要遵循编码器一解码器体系结构,这种体系结构通常将CNN作为特征提取的编码器,将RNN作为生成描述的解码器,编码器一解码器体系结构可以生成超出预定义模板的描述语句,大大提高了所生成语句的多样性。
传统的编码器一解码器图像描述模型通常基于图像中提取的全局特征来生成图像描述,后续的研究或将注意机制与编码器一解码器体系结构结合在一起,或从全局特征中提取感兴趣区域特征以关注图像感兴趣区域,用于提高图像描述的质量,但是这些现有研究仍然在自然语言生成过程中损失了图像视觉场景中的大量详细信息,因而,具有注意力机制的编码器一解码器模型面临以下两个挑战:①当图像中包含复杂目标实体和属性时,从全局图像特征图中提取的区域特征不能很好地表示图像实体的语义;②由于RNN的固有顺序性质,基于RNN的模型难以执行并行优化计算,导致模型训练的时间成本过高。
本文提出了一种新颖的编码器一解码器模型,通过提取检测到的目标实体的细粒度区域特征丰富图像特征,利用Transformer对图像中包含的语义信息进行编码和解码,以生成图像描述,从而提高图像描述的效果,具体来说,使用预先训练的深度残差网络罔(Deep Residual Network,ResNet)来提取图像中检测到的目标实体的区域特征图;然后,在编码器中使用Compact Bilinear Pooling对图像的区域特征图中的细粒度语义特征进行编码,使用多层Transformer encoder对图像的语义特征编码,将两部分特征进行融合,并将所有层次的编码特征与门结构融合,形成图像整体编码特征,在解码器中,从细粒度的区域目标实体图像特征和区域目标实体类别特征中提取多模态特征,并将它们与编码器输出特征融合,以解码语义信息从而进行描述生成,图1展示了添加细粒度特征后的描述效果:LSTM-C(Long Short-Term Memory-C)模型生成的描述效果;本文模型(0urs)生成的描述效果;GTfGround Truth)为数据集中真实标注的描述。
综上所述,本文有以下的贡献,
(1)采用提取精细化的区域目标实体特征的方法以生成具有精细语义的图像描述,本文是第一篇提出细粒度图像描述的概念,并且使用紧凑的双线性池化(cBP)模型融合编码特征以进行图像描述的文章。
(2)引入Transformer对语义特征进行编码和解码,以改善图像描述。
(3)在Microsoft COCO 2014数据集上进行实验,以评估模型在图像描述任务上的性能,实验结果表明,本文的模型达到了优异的效果,本文还将通过实验进一步验证模型中引入的各种因素的影响。
1图像描述相关工作
1.1图像描述
图像描述的任务是给定一张图像,自动生成其对应的自然语言描述,随着越来越多的应用需要理解图像的语义,人们对图像描述进行了大量的研究,图像描述模型可以分为3类:基于模板填充的模型、基于检索的模型和生成式模型。
基于模板填充的模型的流程为:首先人为地定义一系列句子模板;然后提取图像特征以检测图像中的目标实体和属性;最后用检测到的目标实体和属性填充预先定义的模板以生成描述,使用基于模板填充的模型生成的句子通常可以清楚地描述图像中包含的实体和属性,但是缺乏句子和单词的多样性。
基于检索的模型需要维护包含大量图像描述的句子集,该方法通过比较图像与包含在维护的句子集中的描述句子之间的相似度来获得候选句子集,选择最相似的句子作为图像的最终描述,基于检索的模型无法生成新图像的描述,也无法确保生成的描述的准确性。
生成式模型主要应用深度学习模型进行描述生成,Google提出了神经图像描述生成器(NeuralImage Caption Generator,NIC),引入了在机器翻译中被广泛采用的编码器一解码器结构进行图像描述,NIC模型使用基于CNN的InceptionNet来提取图像特征,并使用RNN网络作为解码器来解码CNN中提取的图像特征,其中RNN网络也可以用长短期记忆网络(LSTM)或门控循环单元(GateRecurrent Unit,GRU)代替,斯坦福大学在同一时期提出了神经对话系统,采用VGGnet[1Sl网络作为编码器提取图像特征,RNN作为解码器。
1.2注意力机制
注意力机制已被广泛应用于图像描述中,Xu等最先将注意力机制应用于图像描述,他们在解码器中利用硬注意力和软注意力这两种机制来融合从CNN层提取的特征,硬注意力机制将最关注的区域权重设置为1.其他权重设置为0.以使模型仅专注于一个区域,而软注意力机制为每个图像区域学习在0到1之间的权重,这些权重的总和等于1.可以让模型从所有区域中提取加权特征,软注意力已成为用于图像描述的标准注意力机制,Anderson等提出了bottom-up和top-down两种注意力机制用于图像描述,使用Faster R_CNNl211检测图像中的感兴趣区域(Region of Interests,RoIs),并从RoIs中提取图像特征作为bottom-up注意力特征,再使用两个LSTM层分别作为top-down注意力层和语言模型来生成图像描述,这两种注意力机制使模型在生成图像描述时能够专注于图像的实体周围区域并忽略一些次要信息。
1.3双线性池化
Lin等提出使用双线性池化(Bilinear Pooling,BP)进行细粒度分类,对于使用CNN模型提取的图像特征,可以使用BP将两种特征双线性融合,以获得更深的隐藏信息从而进行细粒度分类,由于BP中包含大量计算,后续的研究工作集中在如何减少BP中的计算,CBP通过Random Maclaurin(RM)和Tensor Sketch(Ts)的方法来降低BP的维数,Low-rank Bilinear Pooling提出使用低秩分解近似分解矩阵以减少计算量并应用于细粒度分类,Grassmann Pooling通过对矩阵执行奇异值(singular Value Decomposition,SVD)分解,并使用由前k個左奇异向量组成的矩阵逼近原始矩阵,从而减少计算量。
2模型实现
2.1模型概览
常见的基于编码器一解码器体系的图像描述模型利用CNN提取深度特征以对图像中包含的隐藏语义进行编码,然后利用RNN从编码的深度特征中解码语义并生成图像描述,人们倾向于从图像中识别多个感兴趣的区域(RoIs),提取RoIs区域的图像特征,并将这些特征送入图像描述模型以生成描述,在实现中,可以引入诸如Faster R-CNN之类的预训练目标检测模型来检测RoIs,并且可以使用诸如ResNet之类的预训练模型来提取所识别的RoIs的区域图像特征,由于图像可能包含多个实体,并且图像中包含的实体产生的RoIs对于生成的描述可能有不同的贡献度,因此,引入注意力机制可以使图像描述模型在生成包含不同实体的描述时将注意力集中在相关的RoIs上。
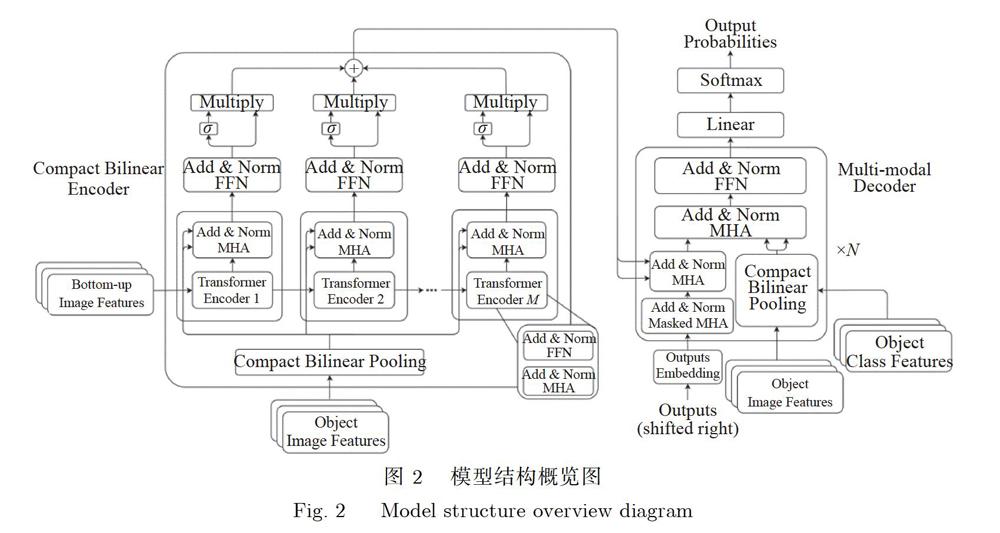
即使添加了注意力机制,现有图像描述模型依然无法生成具有足够准确细节的描述,因为现有RoIs特征主要从全局图像特征中提取;而提取全局图像特征的过程中会有大量的细节信息丢失,会使提取的区域图像特征缺乏细粒度的语义信息,由此,本文提出了一种新颖的编码器一解码器模型,通过显式提取细粒度的实体特征来丰富图像的详细语义信息,从而提高图像描述的质量,本文提出的图像描述模型由M个Compact Bilinear Encoder和Ⅳ个Compact Multi-modal Decoder组成,模型的总体架构如图2所示,在Compact Bilinear Encoder中,Compact Bilinear Pooling从实体区域特征中提取实体的细粒度特征,然后将这些细粒度特征与bottom-up特征融合在一起,以对图像的语义信息进行编码,在Compact Multi-modal Decoder中,在解码语义信息并生成图像描述时会利用多模态信息来进一步增强图像的语义,本章的剩余部分说明实体区域特征和bottom-up特征的提取方法,以及Compact Bilinear Encoder和Compact Multi-modal Decoder的实现过程。
3实验评估
3.1实验设置
本文在公开的Microsoft COCO 2014数据集上进行了广泛的实验以评估本文模型的性能,数据集中每张图像拥有5句英语描述标签,使用Karpathy提供的方法将验证集分为3个部分:5 000张图像用于验证;5 000张图像用于测试;剩余的30 504张图像以及训练集中的82 783张图像用于模型训练,将所有描述句子中的字符转换为小写字母后拆分为带有空格的单词,并丢弃数据集中少于5次的单词。
对于模型中的超参数,本文将bottom-up特征的维度Df设置为2 048.1张图片的RoIs数量k固定为50.实体图像特征维度D设置为2 048.类别名称使用BERT模型抽取,维度Ⅳ设置为1 024.1张图片检测出的目标实体数量固定为5.CBP层的输入输出维度din和dout分别设置成1 024和8 192.MHA层中的特征维度dmodel设置成1 024.MHA的k设置成8.每一个head的特征维度dk为128.全局特征编码器和解码器的个数固定为3.
在两步的训练过程中,首先根据文献[2]中提供的学习率策略设置交叉熵损失的学习率,然后在强化学习阶段将学习率固定为4×10-7,本文设置batch的大小为64.使用Adam优化器进行优化,为了评价模型质量,本文选择了BLEU(B-1、B-4)、METEOR(M)、ROUGE_L(R)和CIDEr_D分数(C)作为评价指标,并以百分比值作为结果。
3.2消融实验
本文进行了一系列的消融实验来证明本文模型MI-Transformer中的众多改进对模型有增进效果,首先将传统Transformer作为基线模型与增加了门限结构的多维度Transformer进行对比;接着将未添加CBP层、仅添加已抽取出的实体图像特征与类别特征的模型,与添加了CBP层抽取细粒度特征的模型加入对比,表1显示了对比结果,其中B-1、B-4、M、R和C分别表示模型在经过交叉熵损失训练后达到的BLEU、METEOR、ROUGE-L和CIDEr-D分数,从表1可以看到,在添加门限结构融合多层特征以及添加细粒度特征后,本文模型的指标均有所提升,其中添加了门限结构和CBP层的比未添加的在CIDEr-D得分上分别提高了1.5和1.4个百分点。
本文验证了利用不同特征提取器提取目标实体特征的效果,表2显示了实验结果,其中单视图(single-view)和多视图(multi-view)分别表示使用同一个提取器和两个不同特征提取器提取初始图像实体特征的情况,R-IOI、X-101和D-121分别表示使用ResNet-101、ResNeXt-101和DenseNet-121提取特征,当使用两个不同特征提取器时,将提取的特征通过Compact Bilinear Pooling融合以形成初始实体特征,可以看到,使用通过ResNext模型和DenseNet模型提取的single-view特征,可以使模型获得更高的BLEU得分,但是会略微降低METEOR、ROUGE和CIDEr-D分数,使用multi-view特征会使模型获得比使用single-view特征更高的BLEU得分,但是降低了CIDEr-D得分,相对关注CIDEr-D得分,本文使用single-view的ResNet模型作为特征提取器。
本文还验证了不同的固定的识别出图像实体的数量m对于模型的效果影响,表3显示了实验结果,当1张图片识别出的实体数量少于m时,使用0向量填充;当超过5时,直接截取概率最大的不同类别的前5个实体,可以看到模型参数m在到达5之前,实体數量越多,实体信息越丰富,模型效果越好,但是由于大部分图片仅包含3 5个实体,太大的参数m会导致模型效果下降,因此本文设置超参数m为5。
3.3模型整体表现
将本文模型的整体表现与以下几个基线模型进行比较,
(1)sCST,该模型将传统的基于Attention的Image Caption模型与强化学习结合。
(2)LSTM_A,该模型使用多实例学习检测图像实体属性,将实体属性添加到LSTM解码中进行描述。
(3)up-Down,该模型通过Faster-RCNN抽取图像bottom-up特征,使用两个LSTM分别作为top-down attention和语言模型进行描述。
(4)RFNet,该模型融合从不同的CNN中抽取的特征进行图像描述。
(5)GCN_LETM,该模型使用图卷积神经网络(Graph Convolutional Neural Network,RCNN)抽取图像中两个实体的关系,并将抽取到的关系作为附加特征进行图像描述。
(6)sGAE,该模型使用自编码的场景图进行图像描述。
表4显示了上述模型的最终效果,其中每个模型都是先进行交叉熵损失训练再进行强化学习训练,从表4中可以看到,在进行交叉熵损失训练后,本文模型在除BLEU-1之外的所有评估指标上均取得了最佳性能,虽然GCN-LSTM的BLEU-1得分略高于本文模型,而在CIDEr-D优化之后,本文模型在所有评估指标上的表现均优于所有基线模型,其中B-1、B-4、METEOR和ROUGEL的得分均以明显的优势领先于在基线模型上的得分,并且CIDEr-D的得分明显高于所有的基线模型,与最近的两个基线模型(GCN-LSTM和SGAE)相比,本文模型的CIDEr-D得分提高了1.5和1.3个百分点;与其他4个基准模型相比,CIDEr-D得分提高了7个百分点以上,本文模型的性能之所以领先于其他基准模型,是因为本文模型提取了图像中包含目标实体更多的细粒度特征,丰富了其语义表达,因此使用本文模型生成的描述更接近训练数据集中的真实描述。
最后测试了使用Transformer进行编码解码的训练效率,结果见表5所示,其中,1个epoch为全部训练集训练一轮,从表5可以看出,相较于使用基于传统Attention机制、CNN作为编码器、RNN作为解码器的SCST模型和使用预先抽取bottom-up特征、两层LSTM作为解码器的Up-Down模型,本文模型在训练速度和收敛速度上都有较大提升,本文模型训练1个epoch的时间较短,训练需要的epoch数(epoehes)也更少。
4总结
当前的图像描述模型主要采用编码器一解码器结构,采用CNN编码器提取深层图像特征,并使用RNN解码器基于提取的特征生成图像描述,这些模型会丢失图像中包含的大量详细信息,模型的训练时间成本也会急剧增大,本文提出了一种新颖的模型,通过使用Compact Bilinear Pooling显式提取检测目标实体的细粒度区域特征,并利用融合多层信息的Transformer对图像中包含的语义信息进行编码和解码,从而改善图像描述,此外,我们还通过融合实体图像特征和文本类别特征来获得多模态信息以增强语义解码,本文在公开的Microsoft COCO数据集上进行了广泛的实验,实验结果表明,本文的模型表现出了更优异的性能,因此,证明了利用细粒度的目标实体特征可以有效地丰富细节信息以生成图像描述。
