结合卷积神经网络与哈希编码的图像检索方法
2020-12-07吴振宇邱奕敏周纤
吴振宇 邱奕敏 周纤


摘 要: 为了提高图像检索的精度与速度,提出一种卷积神经网络与哈希方法结合的图像检索算法。该方法在深度残差网络的基础上构建了一个网络模型,将随机选取成对的图像(相似/不相似)作为训练输入,使用曼哈顿距离作为损失函数,并添加了一个二值约束正则项,促使训练好的网络输出为类二值码,再将类二值码阈值化为二值码,最后用于图像检索。在Caltech256数据集和MNIST数据集上的实验结果显示,文中方法的检索性能优于其他现有方法。
关键词: 图像检索; 卷积神经网络; 哈希编码; 网络模型; 图片对生成; 网络训练
中图分类号: TN911.7?34; TP391 文獻标识码: A 文章编号: 1004?373X(2020)21?0021?06
Image retrieval method combining convolution neural network and Hash coding
WU Zhenyu, QIU Yimin, ZHOU Qian
(School of Information Science and Engineering, Wuhan University of Science and Technology, Wuhan 430081, China)
Abstract:In order to improve the precision and speed of image retrieval, an image retrieval algorithm combining convolutional neural network and Hash method is proposed in this paper. On the basis of the depth residual network, a network model is built with the proposed method, which can select pairs of images (similar/dissimilar) randomly as a training input. The Manhattan distance is taken as a loss function, and a binary constraint regularization is added to prompt the trained network output as approximate binary code. Then the approximate binary code threshold is converted into binary code for image retrieval. The results of experimental on Caltech256 data set and MNIST data set show that the retrieval performance of this method is better than other existing methods.
Keywords: image retrieval; convolutional neural network; Hash coding; network model; image pair generation; network training
0 引 言
随着网络多媒体的发展,互联网上的图片越来越多,这使得根据不同用户要求查找相似图片变得极其困难。而图像检索是从数据库中找到与所查询图像相似的图像,目前常用的方法是基于内容的图像检索(Content?Based Image Retrieval,CBIR)[1]。CBIR通过提取查询图像的特征,并将其与数据库中的图像特征相比较,然后将图像按照相似度从高到低排序并返回给用户。图像相似度是指人类对图像内容理解的差异,这种差异难以通过图像的低层视觉特征反映出来。因此,基于深度学习的哈希检索方法被学者们广泛研究[2]。
深度学习(Deep Learning)是一种利用含有多个隐层的深度神经网络实现学习任务的机器学习(Machine Learning)方法[3]。随着深度学习的研究与发展,研究人员发现,经过大量带标签样本训练与学习后的卷积神经网络(Convolutional Neural Network,CNN),有能力抽象出高层的语义特征[4]。然而,传统的卷积神经网络的训练准则是针对图像分类任务设计的,直接用于图像检索任务难以取得好的效果[5]。因此,针对图像检索任务设计特有的训练准则,是提高检索准确率的一种有效途径。
虽然CNN能够提取图像的高层语义,但是其提取出的特征维度往往高达几千维,直接计算这些高维特征的相似度进行图像检索需要耗费大量时间。因此,学者们提出了利用哈希方法[6?7]进行图像检索。哈希方法将图像特征映射成紧凑的二进制代码,近似地保留原始空间中的数据结构。由于图像使用二进制代码而不是实值特征来表示,因此可以大大减少搜索的时间和内存开销。但是,哈希方法直接对图像特征进行特征编码,然后对特征编码排序检索,并没有将相似图像检索的结果反馈到网络参数的学习之中[8]。因此,如何将CNN提取特征的方法与哈希方法相结合,即在提高检索精度的同时减少检索时间,也是图像检索研究的一个关键问题。
为了解决传统的卷积神经网络直接应用于图像检索任务易导致检索准确率低的问题,本文提出了一种结合深度残差网络(Deep Residual Network,ResNet)与哈希方法的图像检索算法——Residual Network Hashing(RNH)。本文在ResNet网络模型的基础上,通过改进损失函数和添加哈希层,设计了一个新的网络模型ResNetH36。训练时网络输入是成对的图片,图片对是否相似作为输入的标签,输出是类二值码。改进的损失函数采用曼哈顿距离,训练集采用随机选取的图片对,以期能缩短网络的训练时间。为了能够将网络的输出直接用于图像检索,在利用CNN特征提高检索精度的同时能够减少检索时间,本文方法给该损失函数加上一个二值约束正则项约束网络输出的范围,以便将输出阈值化为二值码。
1 相关工作
传统的图像检索算法[6?7]一般是将SIFT,GIST等人工特征通过哈希函数编译成二值码。这些哈希方法虽然取得了一定的效果,但是由于使用的是人工特征,这些特征只能反映图像的底层视觉特征,无法捕获真实数据中外观剧烈变化时的高层语义特征,从而限制了得到的二值码的检索精度。
为了有效的进行图像检索,一些基于CNN的哈希方法被提出。文献[9]提出了一种CNN与哈希方法相结合的算法CNNH,CNNH先通过对相似矩阵分解,得到图像的二值码,将其作为图像的标签训练网络,利用网络拟合二值码用于图像检索。虽然利用了卷积神经网络,但是该方法没有实现端到端的训练。文献[10]在CNNH方法上做出改进,提出了CNNH+方法,CNNH+用一张样本图片,一张相似图片,一张不相似图片共三张构成三元组训练网络,能够同时学习哈希函数和图像特征,但是三元组的选取质量直接影响最终网络的性能,且利用三元组训练网络的过程比较麻烦。文獻[11]提出一种可以同时学习哈希函数和图像特征的算法DSLH,DSLH将图像原本的标签作为监督信息。不需要进行三元组的挑选,减少了工作量。但是该方法量化时采用的是sigmoid函数,虽然能将网络的输出压缩为类二值码,但是会增加量化误差。文献[12]也提出一种利用深度卷积网络框架同时学习特征和哈希函数的算法DSH,该方法利用图片对作为输入,将两张图片是否相似作为标签,很好地描述了网络所需要拟合的特征空间,使得最终的二值码能够保持原始图像的相似性,避免了挑选三元组的过程,但是该方法的损失函数采用的是欧氏距离,且所用的在线生成图片对方法将所有的样本两两组合生成图片对,使得网络的训练时间较长。
针对现有方法使用欧氏距离作为损失函数,同时训练时用到了所有的图片对,会使网络训练时间较长,且量化时采用sigmoid,tanh等约束函数会使量化误差较大,导致检索精度不高,本文提出了结合深度残差网络与哈希方法的图像检索算法RNH。首先,该方法的损失函数采用曼哈顿距离(Manhattan Distance),同时参考原始数据集的样本数量随机选取图片对,减少了训练网络需要的时间。其次,通过给该损失函数加上一个二值约束正则项,使网络输出为类二值码以便阈值化为二值码,减少了量化带来的误差,提升了检索精度。
2 本文方法
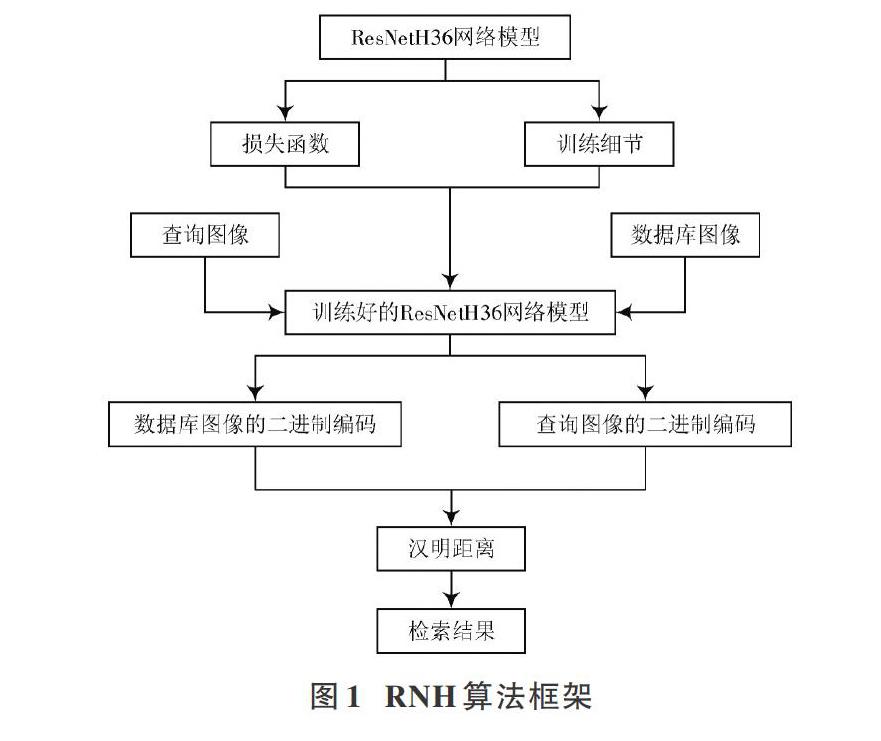
为了提高卷积神经网络应用于图像检索问题时的检索精度,本文提出了一种结合深度残差网络与哈希方法的图像检索算法RNH。由于曼哈顿距离计算简单,且用于图像检索问题时衡量特征数据之间相似性效果较好,所以本文损失函数采用曼哈顿距离。同时参考原始数据集数量随机选取图片对,以期能加快网络的训练速度。然后通过为损失函数添加二值约束正则项,减少量化误差,提高检索精度。本文方法RNH构建的图像检索模型如图1所示。
首先将图像输入到通过本文方法训练好的ResNetH36网络模型中,图像经过ResNet网络得到其特征向量,然后经过哈希层得到类二值码,最后阈值化得到最终的二值码。当输入任意一张查询图像时,经过上述步骤,能得到图像的二值码。然后计算该二值码与数据库中图像的二值码之间的汉明距离。距离按照从小到大排列返回图像,距离越近代表该图像与查询图像越相似。
2.1 ResNetH36网络模型
网络深度对深度学习的性能有显著影响,但是当网络深度加深时网络会变得难以训练,产生退化问题,针对这个问题,文献[13]提出了ResNet。如图2所示通过恒等映射(Identity Mapping)连接的残差模块(Residual Block)结构是ResNet的主要特点,该结构将原本网络所需要拟合的映射[H(x)]转换成[F(x)+x]。虽然两种映射表达效果一样,但是对[F(x)]进行拟合要比对[H(x)]进行拟合简单得多。通过捷径连接(Short Connection)将网络的输入和输出叠加,就可以构成残差模块,通过捷径连接叠加的卷积层不会为网络带来额外的参数和计算量,并且可以解决网络层数加深时导致的退化问题,这就是ResNet比以往的网络更深的原因。为了将ResNet的优点应用到图像检索任务中,本文在ResNet34的基础上添加了一个哈希层和阈值化层,作为本文方法的网络模型,用以提取图像的深层特征并生成图像检索需要的二值码,网络结构如图3所示。
图3中从上至下省略号处分别省略了4层、6层、10层、4层卷积层,阈值化层的作用是将网络的输出通过式(1)阈值化为二值码用于图像检索,是无参数层,因此不参加网络的训练,也在图中省略。各省略处卷积层参数与省略号前一层卷积层参数相同,且每两层有一个捷径连接,构成残差块。模型由36层组成,其中,前34个卷积层的结构、参数与ResNet34相同,后面添加了一个哈希层与阈值化层。每个卷积层里面的参数依次表示卷积核局部感受野的大小和个数,“pool”表示最大池化,“avg pool”表示平均池化。第35层中的“[k]”表示二值码的长度。阈值化层通过式(1)将35层中得到的[k]维类二值码阈值化为二值码,用于图像检索。
[Hj=1, kj≥0.50, otherwise, j=1,2,…,k] (1)
式中:[kj]表示哈希层生成的[k]维类二值码的第[j]位;[Hj]表示结果阈值化后的二值码的第[j]位。
2.2 损失函数
假设[Ω]是RGB空间,那么网络学习的目标是学习一个从[Ω]到[k]维二值编码空间的映射,即[F]:[Ω→{+1,-1}k],同时保持图像的相似性。因此,相似的图像编码应该尽可能的接近,而不同图像的编码应该尽可能的远。基于这个目标,设计的损失函数需要将相似的图像编码拉到一起,将不同的图像编码相互推开。
具体的说,假设有一对图像[I1],[I2∈Ω],其对应的输出[b1],[b2∈{+1,-1}k],定义[y=0]表示它们相似,[y=1]表示不相似。那么可以将损失函数定义为:
[l(b1,b2,y)=12(1-y)Dh(b1,b2)+12y max(m-Dh(b1,b2),0)] (2)
[s.t. bj∈{+1,-1}k, j∈{1,2}]
式中[Dh(· ,·)]表示两个二值码之间的汉明距离;[m>0]为边缘阈值参数,为了让不相似的图像之间距离足够远,令[m=2k]。损失函数的第一项用于惩罚相似的图像映射到不同的二值码,第二项通过阈值[m],保证不相似的图像得到的二值码之间的距离大于[m],即让不相似的图像之间的距离尽可能远。
假设有[N]个图像对[{(Ii,1,Ii,2,yi)i=1,2,…,N}],那么整体的损失函数为:
[L=i=1Nl(bi,1,bi,2,yi)s.t. bi,j∈{+1,-1}k, i∈{1,2,…,N},j∈{1,2}] (3)
由于[Dh(· ,·)]不可以直接求導,而网络的训练要求损失函数是可导的,所以为了符合后续网络训练的要求,需要将其转换成一个可以求导的距离函数,同时为了保证网络的输出能够满足约束条件与便于将其阈值化为二值码,需要添加一个正则化项。具体来说,将式(2)中的汉明距离替换为曼哈顿距离,并增加一个[L1]正则项来替换二值约束。相较于使用欧氏距离等其他距离函数,曼哈顿距离具有更少的计算量可以减少网络训练时间,相较于使用tanh,sigmoid等量化函数约束网络输出,使用[L1]正则项能够减少量化误差,提高检索准确率。最终可以得到网络的损失函数为:
[Lr=i=1N12(1-yi)b1-b21+12yi max(m-b1-b21,0)+αbi,1-11+bi,2-11] (4)
式中:[?1]表示[L1]范数;[α]为该正则化项的权重因子。求解式(4)采用批量梯度下降算法,计算[b1]和[b2]的偏导数时,使用反向传播算法。
2.3 训练细节
批量梯度下降法能够加快网络的收敛速度[14],因此本文使用批量梯度下降法对ResNetH36网络模型进行训练学习。训练时批量大小设为256,学习率从0.1开始。每当错误率平稳时,将学习率除以10,权值衰减为0.000 1,动量为0.9,[α]为0.01。网络每一层的权重由均值为0,标准差为[2k×k×c]的高斯分布来初始化,其中[k×k]是该层卷积核的大小,[c]是该层卷积核的个数。
同时,本文随机均匀选取图片对。先将原始数据集中两张标签相同的图片定义为相似,相似的图片对标签为1,不相似的图片对标签为-1。接着利用批量梯度下降算法将训练集分成多个mini?batch,对于每个mini?batch,将图像两两组合生成图片对。假设整个数据集的样本数为[n],mini?batch的个数为[m],那么在每个mini?batch随机选取的图片对数量为[nm]。最后利用这些图片对进行网络训练。
3 实验结果与分析
3.1 实验设置
为了验证RNH算法的有效性,本文采用Caltech256与MNIST数据集,将RNH算法与LSH,ITQ,KSH,CNNH,CNNH+等哈希方法相比较。其中CNNH,CNNH+直接使用图像作为输入,LSH,ITQ,KSH均使用图像的Gist特征作为输入。为了使实验结果更具有说服力,本文采用平均精度(Mean Average Precision,MAP)和top?[k]近邻域检索准确率作为指标评价检索精度,采用Loss?Iterations曲线作为指标评价网络训练时间。
MNIST是一个手写数字识别的数据集,总共有70 000张28×28像素的图片,包含0~9共十个类别。Caltech256是一个物体识别数据集,总共包含30 608张图片,256个物体类别,每类最少80张,最多827张。
在本文中,MNIST数据集从生成的所有图片对中随机选取70 000个相似的图片对,630 000个不相似图片对用于训练网络。Caltech256数据集从生成的所有图片对中随机选取25 600个相似的图片对,230 400个不相似的图片对用于训练网络。在MNIST数据集中,每一类分别随机选取100张图片,共1 000张作为查询图像,构成测试集。在Caltech256数据集中,每一类分别随机选取10张图片,共2 560张作为查询图像,构成测试集。由于深度残差网络的输入大小固定为224×224,所以在训练和测试时都需将输入图片的尺寸缩放为224×224。
为了比较使用曼哈顿距离的损失函数与使用欧氏距离的损失函数训练网络时所花费的时间,本文在MNIST数据集和Caltech256数据集上分别用不同的损失函数进行训练,实验时除了改变损失函数,即将式(4)中的曼哈顿距离改为欧氏距离,其他条件如网络模型、训练参数等均保持不变。MAP值是一个反映图像检索方法整体性能的指标,MAP值越大,说明图像检索方法的检索性能越好,其值范围在0~1之间。top?[k]近邻域检索准确率是指检索方法根据最小汉明距离排序返回的[k]张图像中,与查询图像相似的图像所占的比例。Loss?Iterations曲线表示损失函数的值随着网络训练迭代次数的变化趋势。
[10] LAI Hanjiang, PAN Yan, LIU Ye, et al. Simultaneous feature learning and hash coding with deep neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 3270?3278.
[11] LIN K, YANG H F, HSIAO J H, et al. Deep learning of binary hash codes for fast image retrieval [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Boston, MA , USA: IEEE, 2015: 27?35.
[12] LIU Haomiao, WANG Ruiping, SHAN Shiguang, et al. Deep supervised hashing for fast image retrieval [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 2064?2072.
[13] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 1063?6919.
[14] BOTTOU L. Stochastic gradient descent tricks [M]. Berlin: Springer, 2012.
作者简介:吴振宇(1993—),男,湖北黄冈人,在读硕士研究生,研究方向为深度学习、图像处理。
邱奕敏(1981—),女,浙江黄岩人,博士,高级工程师,主要研究方向为图像处理、模式识别、深度学习。
周 纤(1993—),男,湖北仙桃人,在读硕士研究生,研究方向为深度学习、图像处理。