城市交通信号局部博弈交互下的学习协调控制
2020-12-07夏新海
夏新海
广州航海学院 港口与航运管理学院,广州 510725
1 引言
效率低下的交通信号控制造成的交叉口延误占城市交通净延误的5%至10%[1]。城市交通信号控制系统优化可以减少行程延误、交叉口延误和交叉口停车次数。自适应交通信号控制系统,如SCOOT、SCATS、PRODYN、OPAC、RHODES、UTOPIA、CRONOS、TUC比固定配时和感应式交通信号控制系统的控制方案的性能更好。然而,自适应交通信号控制方案往往在可扩展性和鲁棒性等方面受到限制。其中许多交通信号控制系统(如SCOOT和SCATS)是基于实时交通数据运行的集中控制系统,并且一些系统(如OPAC和RHODES)应用动态优化来寻找控制方案。然而,它们不能自适应地从环境中学习,并且随着交叉口数目的增加,计算复杂度呈指数级增加。此外,一些学者、研究人员也应用了神经模糊网络、tabu 搜索、自组织协调图、情感算法、遗传算法等来改进交通信号控制方案。然而这些算法存在两个主要局限性,分别是需要大量的数据来校准大规模路网的参数和指数复杂性。为了克服这些局限性,研究人员还探索了基于数据驱动的学习、强化学习等来替代实时自适应控制算法。
在较高饱和度交通环境下,城市路网中各交叉口处的交通流存在较大相互关联性,因此引入博弈学习方法能更有效地进行城市区域路网交通的交通信号控制。
近十年来,在交通信号控制领域,RL(强化学习)的实现已经得到了很好的研究。Thorpe 利用神经网络预测等待时间,并应用在线策略RL(SARSA)来进行信号控制[2]。Mikami 和Kakazu 结合进化算法和强化学习技术提出了合作交通信号控制方案[3]。Bingham提出了基于模糊逻辑的规则,其根据车辆数量分配绿灯时间[4]。
Abdulhai等应用了离线策略(Q-Learning)算法来优化孤立交叉口的交通信号控制[5]。由于联合状态动作的空间呈指数级增长,其在更大路网中的应用具有挑战性。后来,Wiering 等提出了考虑车辆等待时间的网络级合作学习算法,并使用基于车辆的值函数将状态空间减少到合理数量[6]。然而,其等待时间的预测并不准确,交通模拟器缺少车道变换和动态路径选择等重要模块。研究人员还研究了合作多agent系统在城市交通控制的应用[7-9]。近年来,El-Tantawy 等提出了基于邻域协调RL的信号控制,并描述了一个联合决策来介绍多agent框架[10]。尽管Q-Learning 和SARSA 是最广泛使用的时间差分技术,但研究人员还应用了其他算法,如actorcritic时间差分、带函数逼近的Q-Learning及依赖于动作的自适应动态规划[11-13]。Abdul Aziz H M 等将R-马尔可夫平均回报技术(R-Markov Average Reward Technology)应用于交通信号控制,在强化学习状态定义中添加相邻交叉口拥挤信息[14]。
总的来说,上述研究没有充分考虑与相邻交通信号控制agent 之间的信息交互,或者相邻交叉口交通信号控制agent 没有明确的交互和协调,未涉及联合状态动作空间的最优性。相邻交通信号控制agent信息提供了周围控制agent的拥塞状态等信息,其有助于agent更好地学习。假设某一特定交叉口的相邻交叉口交通负荷过重,从而该交叉口在不久的将来也将承受过重的交通负荷。仅使用本地局部信息,agent 无法知道将出现的即时拥塞。如果相邻交叉口交换拥塞状态等信息时,若相邻交叉口发生拥挤,agent 将通过学习来调整交通信号设置。
由于城市路网中交叉口间的交通流是相互影响的,通过相邻交叉口拥挤信息、策略和效用等信息的交换,使得交叉口交通信号控制agent间能实现通信,此控制问题可用博弈框架来建模,从而有利于缓解维数灾难问题,并且有效地平衡城市路网交通信号控制系统整体和交叉口局部交通信号控制性能。本文在建立城市区域交通信号控制系统模型的基础上,设计基于交叉口局部信息交互的博弈学习方法,其利用路网拓扑中局部交叉口交通流相互影响的关系,保证区域交通信号控制系统效率在分布化机制下能够实现最优化。在博弈学习过程中交叉口交通信号控制agent进行局部交通控制信息交互,自主学习控制策略,从而逐渐收敛到最优策略。最后通过仿真实验分析此算法的有效性和收敛性。
2 城市区域交通信号控制系统模型
利用节点表示城市区域交通网络中的交叉路口,弧线表示交通流。假设Sr1、τr1分别为交通流r1的饱和流率和转弯率,且为可测的常数。此外,交叉口i的周期Ci,相位p的有效绿灯时间yi,p,及损失时间Li满足,其中Fi是允许车辆离开交叉口i的相位集合,以交叉口1为基准交叉口,交叉口i相对于交叉口1 相位差为θi。为了对区域路网交通信号控制进行协调,对于任意一个交叉口i,考虑从交叉口j流向交叉口i的单向交通流r,交通流r在时刻k+1 末的车辆排队长度等于在时刻k末,交叉口到来的车辆流量Ii,r加上剩余的车辆排队长度,减去在有效绿灯时间内驶出的车辆流量Oi,r[15]。
建立交通流r的动态离散时间模型如下:

其中,xi,r(k)表示当第k个交通信号控制周期开始时,交叉口i的交通流r上的车辆数量。xi,r(k+1)表示第k+1 个交通信号控制周期开始时,交叉口i的交通流r上的车辆数量。T表示交通信号控制时间间隔,为一个交通信号控制周期C。Ii,r(k)和Oi,r(k)分别表示交通流r的驶入流量和驶出流量。
对于交通流r,驶入的车流来自于相邻交叉口j中的交通流w1、w2、w3,并且只有交通流w1中的左转车流最终会流入交通流r。假设左转车流占整个交通流w1的比例为τj,w1;i,r,称之为转弯率,即τj,w1;i,r表示从交叉口j的w1交通流流入到交叉口i的交通流r的转弯率。同理交通流w2中只有直行车流驶入交通流r,相应地τj,w2;i,r称为直行率。交通流w3中只有右转车流驶入交通流r,相应地τj,w3;i,r称为右转率。故r的流入量Ii,r(k)=τj,w1;i,rOj,w1(k)+τj,w2;i,rOj,w2(k)+τj,w3;i,rOj,w3(k)。因此交通流r的流入量Ir,k(k)可以表示为:

其中,G表示交叉口j中驶入交通流r的车流的集合,即G=w1,w2,w3。τj,w;i,r表示从交叉口j的交通流w转入到交叉口i的交通流r的转弯率。
对于驶出车流量Oi,r(k),它是由单位交通信号控制周期内的释放的车流量q和相位的绿灯时间yi,p(k)决定的,因此交通流r的驶出流量Oi,r(k)可以表示成:

其中,vi,r表示交叉口i允许交通流r通行的相位的集合,qi,r表示交通流r的车流量。
令zi,p(k)=qi,r yi,p(k)作为系统控制变量。将式(2)和(3)及zi,p(k)=qi,r yi,p(k)代入式(1)得:

根据式(3)中Or,w(k)的定义,式(4)中的Oj,w(k)可以写成以及T=C。所以式(4)可以写成:

接下来,整个区域交通路网都应用式(5),可得到整个区域交通路网的离散状态时空表达式:

另外,若区域路网中交通流只有外界输入交通流量,则式(2)和(4)必须表示成:

其中,di,r表示交叉口i进入交通流r的交通需求。为了简化,假定di,r已知。于是式(6)可以写成:

其中,X(k)、Z(k)、d(k)分别表示系统的状态向量、交通信号控制向量、交通需求向量,且d(k)是常数向量。状态矩阵B为单位矩阵,H是包含网络特性(如拓扑结构、饱和流率、转弯率)的控制输入矩阵,D是需求矩阵[16]。
交通信号控制agent 通过无线网络与其他agent 进行通信和协调。为此,提出交通信号控制agent 之间博弈学习方法,通过它们之间的交互,并通过实时采集的交通流来最小化车辆在交叉口的等待时间,以最小化整个路网中的等待时间。
3 城市区域交叉口交通信号博弈协调控制框架
传统分布式交通信号控制系统虽然开销较少,但系统协调效率受限,并且存在维数灾难问题,因此这里引入局部交互思想,将交通信号控制优化问题建模为交叉口交通信号控制agent 局部合作博弈,通过相邻交叉口交通信号控制agent间的信息交互实现系统协调效率与优化开销的有效折中[17]。
定义城市区域路网交通系统由N个交叉口构成,定义博弈模型为元组:

其中,M={1,2,…,N}为系统中交叉口交通信号控制agent 的集合;Am为系统中第m个交叉口交通信号控制agent 的可用的策略集合,即决策空间,由Am=Xm×Zm;X和Z含义见式(6)和式(9),分别表示m的状态空间和动作空间;Jm是交叉口交通信号控制agentm相邻交叉口交通信号控制agent 的集合;U(mam,a-m)为交叉口交通信号控制agentm的效用函数。其中am是交叉口交通信号控制agentm执行的策略,a-m是除交叉口交通信号控制agentm以外其他交叉口交通信号控制agent执行的策略[18]。
设gm(am,aJm)为交叉口交通信号控制agentm的满意效用,是关于交通流r上的车辆数量、绿灯相位持续时间内释放的车流量的函数,且:

xm(h+1)=fdxi(x(h),zm(h),z-m(k)) 由式(5)定义,Q和R为对角元素为正的对角矩阵,上标T 表示转置操作符,x(h|k)为在周期k时给定条件下在周期h时的s的预测值,z(h)表示在周期h的动作。
根据单个交叉口交通信号控制agent的满意效用定义,定义城市区域网络交通满意效用为所有交叉口交通信号控制agent满意效用之和。

城市区域路网交通信号控制系统的整体目标是通过寻找最优联合策略,使得系统满意效用达到最大,即:

根据第2章分析,相邻交叉口之间交通流相互影响较大,并不是任意两个交叉口的交通信号控制都有明显的相互干扰,因此Um(am,a-m)可以表示为Um(am,aJm)。这里定义U(mam,aJm)如下:

交叉口交通信号控制agent的效用函数由自身满意效用和相邻交叉口交通信号控制agent的满意效用之和组成。因此每个交叉口交通信号控制agent的决策不仅要考虑提高自身满意效用,还要尽可能地减少对相邻交叉口交通信号控制agent满意效用的影响。通过这种局部合作方式,每个交叉口交通信号控制agent 在决策时将大大降低其自利性,并且可以使得此博弈问题能够收敛到最优联合策略。为了实现局部交互,相邻交叉口交通信号控制agent 之间需要交换信息,其中包括交叉口交通信号控制agent的满意效用和策略选择。局部交互博弈模型可以表示为:

记交叉口交通信号控制agent 联合策略为a*=,若任意交叉口交通信号控制agent 不能独自地改变策略增加其效用值,称a*为博弈G的纯策略纳什均衡点,则路网满意效用最大化问题P1的全局最优解构成博弈G的一个纯策略纳什均衡点[17]。
4 基于交叉口交通信号控制agent 局部博弈交互的学习算法
传统的学习算法如最佳动态响应、非遗憾学习和虚拟对策都能使得势能博弈收敛到某一纯策略纳什均衡点,但往往无法达到最优。因此设计一种基于局部信息博弈交互的学习算法来确保路网中每个交叉口交通信号控制agent在博弈中收敛到最优策略并最大化网络满意效用。
4.1 算法描述
算法基于交叉口交通信号控制agent 局部博弈交互的学习算法
(1)初始化。设置k=0,令每个交叉口交通信号控制agentm∈M以相等概率从其可行控制策略集合Am中选择初始控制策略am(0)。
(2)交叉口交通信号控制agent 与其相邻交叉口交通信号控制agent交换信息,包括效用值和策略选择。
(3)任意选择一个交叉口交通信号控制agenti∈M,其他所有交叉口交通信号控制agent重复上一次迭代的策略,即a-i(k+1)=a-i(k)。而对于交叉口交通信号控制agenti,它将根据一个离散概率分布来选择k+1 时刻的策略ai(k+1) 。记交叉口交通信号控制agenti策略选择为ai(k+1)=ai∈Ai时,其效用函数值可表示为Ui(ai,aJi(k))。根据式(15)可以计算得到交叉口交通信号控制agenti选择ai(k+1)=ai的概率:

其中,γ为折扣因子表示交叉口交通信号控制agenti执行Ai中的所有策略可以获得的效用之和。因此,交叉口交通信号控制agenti会以概率执行策略ai。
(4)如果迭代次数达到预设的最大值tmax,所有交叉口交通信号控制agent停止更新策略;否则,回到步骤(2),算法继续。在算法中,γ取值必须合理。如果γ过大,博弈学习可能不能收敛到最优的纯策略纳什均衡点;如果γ过小,将会减慢收敛速度。故在设计γ值时需要综合考虑性能表现和收敛速度。
在算法的每次迭代中,随机选择一个交叉口交通信号控制agent更新控制策略而保持其他交叉口交通信号控制agent的策略不变。重复该过程直到满足某些准则时才停止。如步骤(3),选中的交叉口交通信号控制agent按照概率进行策略更新。此概率分布的计算由交叉口交通信号控制agent当前策略及其邻居的策略共同决定,见式(15)所示。根据式(15)的设计,交叉口交通信号控制agent会以更高的概率选择使其获得更大效用的策略。在数次迭代后,每个交叉口交通信号控制agent的策略选择都会以无限接近于1 的概率收敛到最优策略。该结论将在4.2节进行分析。在局部博弈交互学习过程中,相邻交叉口交通信号控制agent 间还需交换必要的信息,如交叉口交通信号控制agent 的效用值和控制策略选择[19]。
4.2 算法最优性和收敛性分析
若所有交叉口交通信号控制agent 执行算法,联合策略a∈A1⊗A2⊗…⊗AM的平稳概率分布可以表示为,其中A=A1⊗A2⊗…⊗AM表示交叉口交通信号控制agent联合策略集合[17]。
记使路网交通信号控制系统满意效用最大化的最优联合策略为a*:

当γ值足够大时,有exp{γφ(a*)}>exp{γφ(a)},∀a∈{Aa*},则a*的平稳概率分布可以计算为:

式(17)表示以任意接近1的概率得到最优解。因此当γ值足够大时,博弈学习算法可以任意接近1的概率达到问题P1的最优解。
5 案例研究
应用MATLAB实现博弈学习算法,利用VISSIM微观交通仿真平台进行仿真,构建路网,设计不同的交通情景,加载博弈学习控制算法插件。案例分析用到的路网采用比较常用的来分析交通信号控制相关问题的allsop和charlesworth的著名测试道路网络,其基本布局见图1,其包括23条路段和21个信号设置变量,分别位于6个信号控制交叉口[20]。基本初始路网相位方案见表1,各连接上的交通流量见表2(即式(9)中路网交通需求矩阵D)。

表1 路网的交通信号相位方案

图1 分析用到的路网
案例分析其借鉴英国交通与道路研究所提出的离线优化交通网络信号配时所采用的路网性能性能指标(Performance Evaluation Index,PEI),见式(18),把时间与费用统一考虑,其是路网流量和路网交通信号配时参数的函数[21]。

其中,dl是连接l的延误,l∈L,L是路网所有连接的集合,是连接l上的延误的特定加权因子。K是停车惩罚系数,表示停车次数相对于延误的重要性。Sl是连接l上每秒停车的次数。是连接l上停车次数S的连接特定加权因子。

表2 路网连接车流量
案例用到仿真参数设置如下:最小和最大周期时长为36 s和120 s;相位最小绿灯时间为7 s,每个相位的绿灯间隔时间为5 s,包括4 s黄灯和1 s全红。感应控制单位绿灯延长时间为2 s,最大绿灯时间为80 s。=1,K=1。Sl学习率(α)为0.8。在博弈学习过程中,算法的学习因子γ可随迭代的进行而变化,并且在第i次迭代中设置γ=i。最大学习次数(tmax)为500。转弯率τj,w;i,r可由表1和表2的数据计算得到。
5.1 情景1:基准情景
在测试交通需求增加产生的可能影响之前,博弈学习使用现有的连接交通流需求(D1)应用于基准情景,模型的收敛性如图2 所示。在第338 次的学习,该算法收敛,得到评价指标值为364.30,而在第一次学习时评价指标值为528.30。换句话说,相对于评价指标的初始值,改进率为45%。在算法的运行过程中,各交叉口交通信号控制agent 通过交互局部效用值和策略,利用减小搜索空间,并围绕最优信号配时设置的参数来搜索全局最优,避免陷入局部最优解。

图2 基准情景下博弈学习方法的收敛性
基准情景下博弈学习、感应控制、遗传算法运行收敛后得到的最优评价指标值分别为364.30、443.50、365.20,总旅行时间分别为170 veh·h、203 veh·h、170 veh·h。采用博弈学习和遗传算法所得评价指标结果非常接近。然而,由于该方法比具有二进制编码/解码过程的遗传算法更容易应用,因此可以认为该方法优于遗传算法。此外,所提出的模型与感应控制相比,评价指标的最终值提高了22%。表3 中给出了三种方法在基准情景下的运行收敛后得到的最优交通信号配时方案。其中相位差是绝对相位差,交叉口1为基准交叉口。

表3 基准情景下最优信号配时方案
5.2 情景2
在路网的基准情景交通需求的基础上增加20%(D2=120%D1)。这种情景下,所提出的模型算法的收敛性如图3所示。

图3 情景2下博弈学习方法的收敛性
从图3 可看出,经过478 次学习过程,博弈学习达到收敛,收敛后的方案的评价指标值781.80,而评价指标在第一次学习时评价指标为1 043.50。在情景2 下,博弈学习、感应控制、遗传算法达到收敛的评价指标值分别为781.80、891.20、804.50,总旅行时间分别为356 veh·h、405 veh·h、365 veh·h,因此博弈学习优于另外两种方法。相对于基准情景,交通需求增加20%,其评价指标的最终值大约增长1 倍。对于情景2,三种方法收敛后的交通信号配时方案见表4。可以看出交通需求的增长导致路网周期时间相对于基准情景也增加。
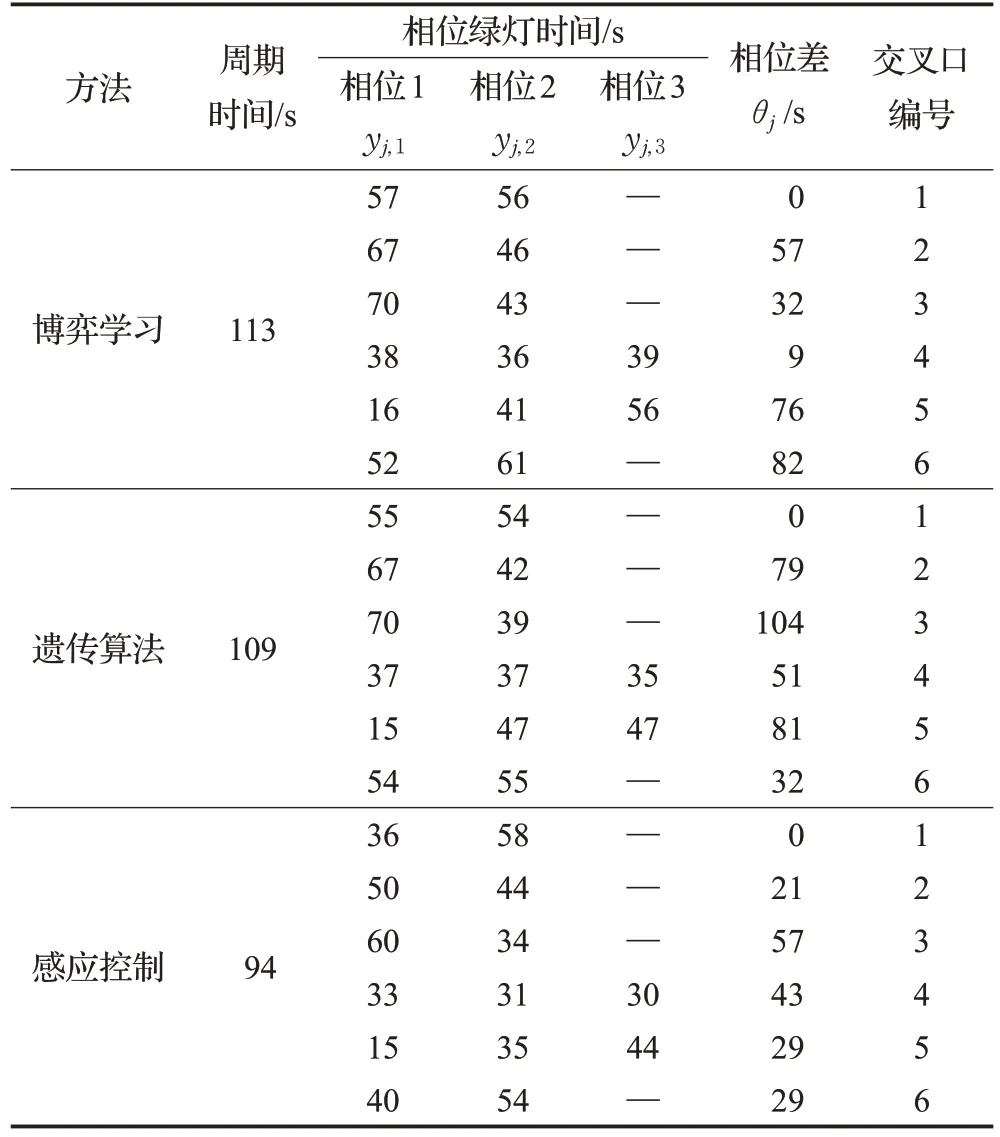
表4 情景2收敛后的交通信号配时方案
5.3 情景3
在这种情况下,为了表明博弈学习在高交通需求条件下的有效性,将基准情景下的路网中连接流量增加到50%(D3=150%D1)。相对于初始解,博弈学习的最终评价指标值改进了20%。在第551 次学习过程内算法停止,发现路网评价指标的最优值为2 137.50,如图4所示。算法运行过程中,路网评价指标值比情景2下有更高的波动趋势,其根本原因是交通需求的增加导致了交通拥挤的加剧,使得交通信号配时优化问题的最优解难以找到。在情景3下,博弈学习、感应控制、遗传算法的达到收敛的评价指标值分别为2 137.5、2 286.5、2 228.5,总旅行时间分别为965 veh·h、1 034 veh·h、1 006 veh·h,因此博弈学习优于另外两种方法。表5 给出了收敛后的信号配时和相应的参数值,其中博弈学习的优化周期达到了设定的最大周期120 s。

图4 情景3下博弈学习方法的收敛性

表5 情景3收敛后的交通信号配时方案
因此,在路网交通需求量较大的情况下,博弈学习也能收敛到全局最优的解,并比遗传算法和感应控制产生更好的评价指标值。
6 结束语
本文在建立城市区域交通信号控制系统模型的基础上,设计基于交叉口局部信息交互的博弈学习方法,其利用网络拓扑中局部相互影响的关系,保证区域交通系统效率在分布化机制下能够实现最优化。在博弈学习过程中交叉口进行局部信息交互,自主调整策略使其逐渐收敛到最优策略,具有更好的交通需求管控能力和收敛性能。以路网平均延误和平均停车次数通过加权构建算法性能指标,在某中等规模路网的三种交通需求情景下,利用博弈学习方法均优于遗传算法方法和感应控制方法,并且博弈学习均能收敛到最优解。博弈学习能更有效地判断最佳联合策略,能够与新兴的通信技术协同工作,有助于异构智能交通控制系统集成方案的解决。在未来的研究中,可以考虑基于云架构的分布式学习机制,进一步分析学习率参数和折扣因子对算法的影响,并应用于更大规模的路网,提高系统交通信号配时决策效率。同时可考虑通过引入车联网环境中的I2I通信技术允许交叉口交通信号控制agent与其他交叉口交通信号控制agent 交换信息,实现博弈学习算法与车联网技术模式相结合,有望在下一代智能交通系统中发挥重要作用[22]。
