大米直链淀粉、蛋白质、脂肪、水分含量的近红外光谱检测模型优化
2020-12-07路辉彭彬倩冯晓宇沈晓芳
路辉 彭彬倩 冯晓宇 沈晓芳*
(1 江苏省农垦农业发展股份有限公司,南京210019;2 江南大学食品学院,江苏无锡214122;第一作者:429772084@qq.com;*通讯作者:xfshen@jiangnan.edu.cn)
营养和风味是大米的重要品质。直链淀粉、蛋白质、脂肪、水分含量是大米的重要营养指标[1],同时,直链淀粉、蛋白质和脂肪含量与食味品质密切相关,是影响稻米食用品质的重要因素。大米中脂类物质的分布会影响加工精度[2];大米蛋白具有氨基酸组成平衡合理以及不会产生过敏反应等优点[3];直链淀粉含量与米饭的胀性、柔韧性、光泽度、粘性有密切关系[4];水分含量则会影响大米的储藏品质。对这些指标的传统测定方法存在过程繁琐、耗时耗力等不足,而近红外光谱法具有多指标同时检测、快速无损、成本低等优点[5],在粮食谷物中应用广泛[6-9]。
基于近红外光谱法对大米各营养成分含量的快速检测研究在国内外均有报道。李路等[10]运用分段小波消噪光谱预处理,建立了海南省产的大米蛋白质、脂肪、总糖、含水量的检测模型。王传梁等[2]证明了利用近红外光谱技术测定稻米脂肪含量的可行性。黄道强等[11]通过比较近红外分析仪和常规法测定水稻种子直链淀粉含量,认为通过增加数据量建模可以减少误差,达到利用近红外分析仪辅助选育中等直链淀粉含量新品种的目的。SAMPAIO 等[12]联合区间偏最小二乘回归(siPLS)选择的光谱区域提高模型的预测能力,从而说明了近红外技术对直链淀粉含量测定的可行性。HEMAN 等[13]采用近红外无损检测方法来检测大米样品的水分含量,比较化学计量学方法,得到PLS 为最佳模型(rp>0.9)。近红外技术在大米营养成分检测中的应用报道较多,但大多是对单项指标的研究,而对大米多项品质指标的评价较少,且由于大米产地颇多,南北各地稻米存在较大差异,各区域模型并没有普适性,尤其针对江苏省区域的大米模型鲜有。本实验针对产自江苏省的90 个品种126 份粳米、糯米和籼米为研究对象,测定直链淀粉、蛋白质、脂肪和水分含量,同时采集对应的近红外全光谱,建立偏最小二乘定量模型,再通过筛选最佳光谱预处理方式和谱区范围来优化模型,从而建立适用于江苏省所产大米中直链淀粉、蛋白质、脂肪和水分含量等营养成分的定量模型,为大米行业实现在线品控提供了依据。
1 材料与方法
1.1 仪器与试剂
实验材料包含90 个大米品种(表1),有粳米、糯米和籼米,粳米占多数,均由江苏省农垦农业发展股份有限公司提供,产自江苏省,共计126 个大米样品。Antaris II 近红外分析仪与数据分析软件TQ Analyst 购自Thermo Fisher 科技(中国)有限公司。

表1 90 个大米品种名称
1.2 测定方法
1.2.1 大米直链淀粉、蛋白质、脂肪、水分含量的测定
直链淀粉参照GB/T 15683-2008《大米直链淀粉含量的测定》。采用GB 5009.5-2016《食品安全国家标准食品中蛋白质的测定》中凯氏定氮法测定大米的蛋白质含量,氮折算成蛋白质的折算系数为5.95。采用GB 5009.6-2016《食品安全国家标准食品中脂肪的测定》中索氏抽提法测定大米的脂肪含量。采用GB 5009.3-2016《食品安全国家标准食品中水分的测定》中直接干燥法测定大米的水分含量。每份样品至少检测3 次,取平均值。
1.2.2 样品近红外光谱采集
大米样不经过粉碎等前处理,混匀后直接填满圆形样品池。采用漫反射方式采集样品光谱,设置采集光谱区间为 4 000~10 000/cm,分辨率为8/cm,样品扫描频数为64 次,测量间隔为3.857/cm。采集完后将采样杯中样品与原样品混合均匀后倒出,重复操作3 次,3次采集得到平均光谱作为该样品的最终光谱。
1.2.3 光谱处理与建模
对光谱数据计算马氏距离后删除异常点,预先指定各模型验证集20 份,剩余样本为校正集,验证集测定值范围应包含在校正集范围之内。使用校正集样本,采用偏最小二乘(partial least squares, PLS)回归法建立大米直链淀粉、蛋白质、脂肪、水分含量模型,根据交叉验证均方误差(root mean square error of cross-validation, RMSECV)选择最佳主因子数。为了优化校正模型,提高相关有效光谱信息,削减无效干扰光谱,采用5 种光谱预处理方法,分别为多元散射校正(multiplicative signal correction, MSC)、标准正态变化(standard normal variate, SNV)、一阶导数(first derivative, 1st)、二阶导数(second derivative, 2nd)和 Savitzky-Golay 滤波平滑(Savitzky-Golay filter, SG),之后在最佳光谱预处理下,采用手动法[14]筛选特征波段进一步优化模型。校正集的相关系数rc和均方误差(root mean square error of calibration, RMSEC)作为直接评判模型的主要指标,以相对分析误差(relative percent deviation, RPD)进一步衡量模型的优劣,若RPD≥2.0,表明模型稳健,可用于日常实际定量检测;若2.0 >RPD ≥ 1.4,则模型一般,如要精确需要改良;若RPD <1.4,则模型用于实际定量检测困难[15-17]。最后,用不参与建模的验证集对模型进行验证。
2 结果与分析
2.1 近红外原始光谱
如图1 所示,大米每条原始近红外光谱趋势相似,难以用肉眼评判特定波段峰值与指标含量的关系。光谱显示在 4 000~6 000/cm 和 8 000~9 000/cm 区域吸收较强,其中,在5 155/cm 处的谱带与—OH 基团的第一倍频和组合频相对应,主要代表了水分含量;而对于—CH2和—CH3官能团,在拉伸和弯曲振动的组合频出现在4 300/cm 附近、5 700/cm 附近是拉伸振动的第一倍频、8 351/cm 是拉伸振动的第二倍频,4 700/cm 左右吸收峰带则与蛋白质含量有关[3,18]。通过TQ Analyst 软件将光谱进行预处理及波段的剔筛,从而利用偏最小二乘法建立各组分的定量模型。

图1 大米样本近红外光谱图

表2 大米直链淀粉、蛋白质、脂肪和水分化学值统计结果

表3 大米样本校正集和验证集参数
2.2 各成分测定结果
如表2 所示,蛋白质和水分指标的样品集数目没有出现异常值,脂肪指标剔除样本数4 份后为122 份。由于126 份大米中有24 份为糯米品种,再除去异常点后,实际直链淀粉指标参与建模的样本数为100 份。
2.3 校正集与验证集的划分
如表3 所示,总样本的验证集含量范围包含在校正集内,且校正集与验证集的平均值和标准偏差相近。因此,校正集样本所建的检测模型能较好地适用于验证集样本。
2.4 光谱预处理

表4 大米样本校正集和验证集参数
应用5 种光谱预处理方式分别对直链淀粉、蛋白质、脂肪和水分含量的PLS 校正模型进行优化,表4 为优化结果,基于全波段的不同光谱预处理下,脂肪和直链淀粉模型均在Savitzky-Golay 滤波平滑(SG)下取得最小RMSEC 为0.15 和2.17,此时rc达到最大,分别为0.7810 和 0.6322,RPD 分别为 1.6 和 1.3,采用 SG 光谱预处理方法通过重新计算设定窗口内平滑值,能有效减少光谱噪音干扰,提高信噪比。采用标准正态变化光谱(SNV)预处理,蛋白质模型最佳,rc为 0.9078,RMSEC 为 0.27,与无任何光谱预处理比较,RPD 由 2.2 提升至2.4。SNV 常用于扫描固体样品后的漫反射光谱,由于漫反射带来光程不一等负面影响,因此常被用光程调节预处理方法。导数是解决近红外光谱基线漂移或旋转的重要方法,水分在一阶导数(1st)的光谱预处理下表现最佳,水分模型的rc和RMSEC 分别为0.9554和0.30,相较于无光谱预处理,RPD 值提升尤为明显,从 2.3 升至 3.4。
建模的优良不仅取决与校正集结果,且与最终验证集相关,而主因子数大/小会导致校正模型过/欠拟合,导致校正集和验证集模型差别较大,因此选择合适的主因子数尤为重要[19-20]。在RMSEC 最小时选择最佳主因子数,直链淀粉、蛋白质、脂肪和水分含量模型主因子数分别为 5、10、9 和 4。

表5 基于最优光谱预处理的特征波段下建模结果

图2 大米脂肪、蛋白质、直链淀粉和水分含量的定量模型
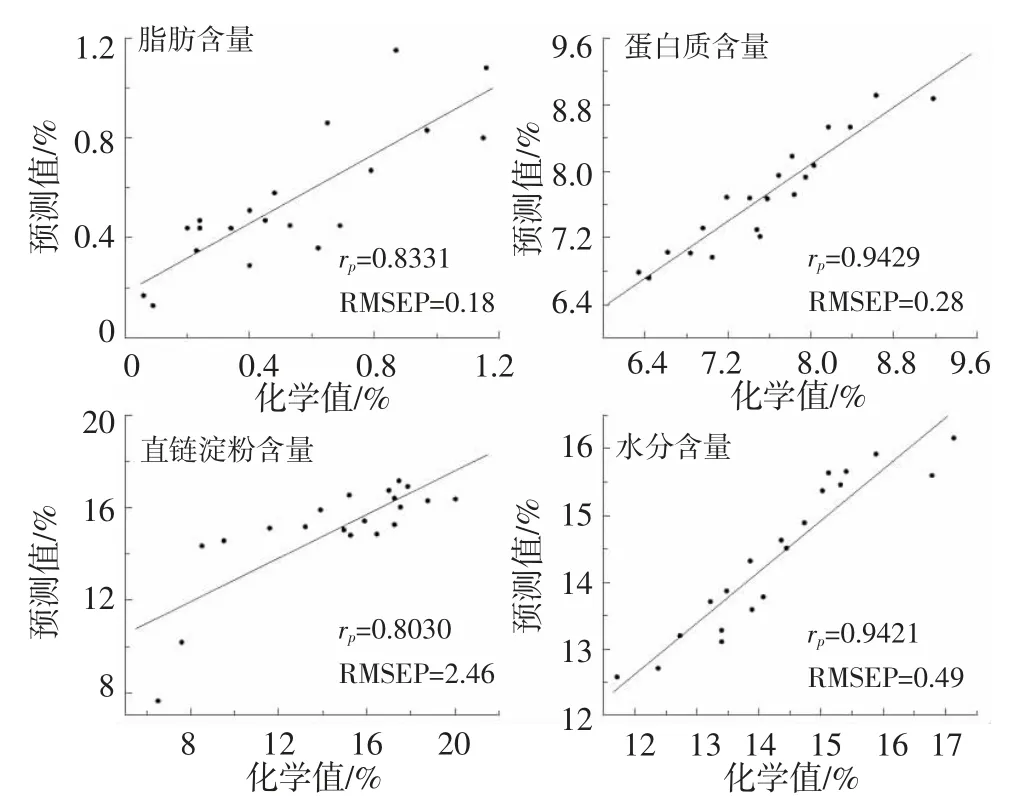
图3 大米脂肪、蛋白质、直链淀粉和水分含量模型验证
2.5 特征波段的筛选
原始近红外光谱包含杂信息,为提取有效的成分相关光谱信息,可提高模型的精度。本研究采用人工方法[14]将全波段分为12 个光谱范围,11 个分割点依次为:4 500/cm、5 000/cm、5 500/cm、6 000/cm、6 500/cm、7 000/cm、7 500/cm、8 000/cm、8 500/cm、9 000/cm、9 500/cm。在最佳光谱预处理条件下,依次移除一个光谱范围,其他波段用于建模所得rc与全波段(4 000~10 000/cm)下的rc比较,结合TQ Analyst 软件给出的建议波段进行了严格筛选,排除了与组分无关的波段。最后,将选定的谱区用于单谱区或组合谱区进行比较。表5 为建立大米样品中直链淀粉、蛋白质、脂肪和水分含量的最佳模型,在5 703~7 194/cm、8 520~9 975/cm下,脂肪含量模型的rc由0.7810 提升至0.8110,RMSEC 由0.15 降低为0.14,RPD 提高了 0.1。直链淀粉含量模型的rc没有得到明显提升,从0.6322 提高到0.6671,RPD 从1.3 提高到1.4。从相关系数大小来看,蛋白质和水分含量模型的预测值与实测值显示出良好的相关性,两者PLS 模型表现最佳分别使用5 613~6 379/cm 和 8 004~8 956/cm、4 755~4 982/cm 和 5 501~7 888/cm 的光谱范围,rc均在0.9 的基础上再次增加,分别为 0.9713 和 0.9663,RPD 分别为 4.3 和 3.9。可见其预测性能好、准确度高,说明模型可用于实际定量检测。
如图2 所示,脂肪含量与直链淀粉含量模型有少数点与拟合线略有分离;蛋白质含量和水分含量散点分布在拟合曲线周边,没有显著偏离,且rc均在0.95以上。
2.6 模型的检验
图3 为最优模型下验证集的预测值和实测值的散点图,可见各指标验证效果良好,尤其是蛋白质含量和水分含量模型的预测性效果良好,rp在0.94 左右,验证集的蛋白质含量在主成分数为10 时,5 613~6 379/cm和8 004~8 956/cm 的波段范围内进行SNV 光谱预处理后建立,得到模型 rp为 0.9429、RMSEP 为 0.28;验证集的水分含量在主成分数为4 时,4 755~4 982/cm 和5 501~7 888/cm 的波段范围内进行1st 光谱预处理后建立,得到模型rp为 0.9421、RMSEP 为0.49。脂肪含量和直链淀粉含量的检测结果相对较差,主要是因为大米中脂肪的含量较低,且大多集中在米粒表层,这就导致样本所含脂肪很少[10],对于直链淀粉含量rp为0.8030,是由于测定方法允许误差本身较大[21],且建模样品数小于其他指标,但两种模型仍可以用于实际样品的粗测。
3 讨论与小结
水稻是我国的主要粮食作物,随着生活水平的提高,大米品质愈发受到人们的关注,同时要求企业能在线快速无损测定大米各营养成分的含量,提高工作效率,降低成本。大米中蛋白质含量等是衡量其营养与风味品质的重要指标,同时对口感影响较大[11,22],也是研究者普遍关注的热点。前人以大米为材料,构建近红外优化模型多见报道,但在一定区域内建立大米PLS 模型的研究鲜有报道。本实验基于产于江苏省大米(种类包括粳米、糯米和籼米)的化学值和光谱数据,利用近红外光谱分析技术建立了基于偏最小二乘法的大米直链淀粉、蛋白质、脂肪和水分含量定量模型。选择合适的谱区范围和光谱预处理方法可以有效地提高模型的性能,该模型可用于大米工业在线快速检测和评估营养指标,有利于大米资源的合理利用。
模型的建立与优化中,光谱预处理和光谱区的作用举足轻重。首先,不同的光谱预处理较大程度会提高rc和RPD,降低RMSEC。再者,通过光谱区的筛选,蛋白质和水分模型rc均在0.95 以上,高于黄林森等[24]所得rc,而0.9 以上的相关系数已经表明了模型具有良好的预测性能。最后,通过验证集结果验证了定量模型的可 靠 性 ,4 个 模 型 验 证 结 果 为 0.8030 ≤rp≤0.9429,0.18≤RMSEP≤2.46,表明模型的预测值与实测值接近,预测效果良好,实验所建立的定量模型可以实现对产自江苏省大米中直链淀粉、蛋白质、脂肪以及水分含量的快速无损检测,可在实际检测中实时反馈大米品质。总之,近红外光谱分析技术能快速检测江苏省产大米的直链淀粉、蛋白质、脂肪和水分含量,更能够应用于水稻品质改良育种的在线快速测定与筛选,提高育种筛选效率。
