机器学习方法在预防信用卡违约风险中的应用
2020-12-07曾叙坚梁杜艺
曾叙坚,吕 露,陆 鑫,梁杜艺,王 东
(桂林电子科技大学 数学与计算科学学院,广西 桂林 541004)
1 问题背景
信用卡借贷业务是银行的主营业务,随着银行信用卡业务的发展,如何提前识别信用卡用户违约状况是银行行业面临的最大挑战[1],好的信用卡违约预警模型能给银行来更小的损失、更大的盈利空间[2]。机器学习技术在最近几年里飞速发展并且取得良好的效果,特别是在识别一些人类未知的场景,使用机器学习方法建立信用卡违约预警模型也是一种新的研究方向[3]。本文将使用机器学习的决策树和随机森林算法建立信用卡违约预警模型,数据来源于“汇丰杯”2016年中国高校SAS数据分析大赛。
2 决策树
决策树最初是由Quinlan等[4]提出的一种基于离散特征数据或连续数据对目标进行分类的树形分类器,主要组成部分包括根节点、内部节点、叶节点。根节点是决策树的顶端,比如,在本实验的样本数据中,“受教育程度”就是一个根节点。叶节点是决策树的中间节点,基于根节点的“受教育程度”的叶节点可以是“初中及以下”“高中”“本科及以上”。叶节点就是决策树底部的节点,也就是决策结果,在本实验中,叶节点的结果是“违约”和“未违约”。
构造了一个决策树模型之后,就需要进行“剪枝”的操作,“剪枝”的目的是减少一些不必要的节点,从而达到以较小的信息获得较好的分类效果。构造一个决策树模型以及剪枝步骤,需要通过类似递归思想计算信息增益和信息熵的方式进行。计算初始信息熵的方法如下:
(1)
式中。ni为类别i中的样本个数;n为样本的数量;c为类别数量。对决策树的根节点进行属性选择的过程中,分支的新熵计算方法如下:
(2)
式中,Ak表示属性;ηkj为每个分支的样本个数;ηkj(i)为每个分支的ηkj个样本中属于类别ci的样本数。计算信息增益的方法如下:
ΔS(k)=S(I)-S(I,Ak)
(3)
挑选具有最大信息增益的属性Ak0作为决策树的根。Ak0的判断条件为:
Δ熵(k0)>Δ熵(k),k=1,2,…K;k≠k0
(4)
3 随机森林
随机森林是一种包含多个决策树模型的分类器,随机森林是由Leo Breiman和Adele Cutler发展推论出的[5]。随机森林是集成学习的一种模型,集成学习就是通过构造一系列的学习器进行学习,然后使用某种规则把所有的学习器连接起来,从而实现比单个学习器更好的学习或预测能力。
随机森林的构造如下:(1)用N表示训练样本的个数,n表示变量的数目。(2)用m表示模型遇到在一个节点做决定时会用到的变量数量。(3)从N个训练样本中采用重复取样的方式,取样N次,形成一组训练集,并使用这棵树对剩余样本预测其类别,并对误差进行评估。(4)对于每个节点,随机选择n个基于此点上的变量。根据这n个变量,计算其最佳的分割方式。(5)在随机森林中的每棵决策树都不采用剪枝技术,每棵决策树都能完整生长。
随机森林中任意两棵决策树的相关性与随机森林中每棵树的分类能力是影响随机森林分类效果的两个重要因素。任意两棵决策树之间的相关性越大,错误率越大;任意两棵决策树之间的相关性越小,且每棵树的分类能力越强,整个随机森林模型的错误率越低。
4 基于两种方法的预测
4.1 研究流程图
基于两种方法的预测流程:第一步,获取银行信用卡违约与未违约的数据,将得到的数据可视化展示。同时,绘制各变量与违约状态的直方图与各变量之间的相关关系图、使用过滤式特征选择法进行特征选取。第二步,将得到的数据建立决策树与随机森林模型,将两个模型得到的结果进行比较,对比各自的精确率、耗时。具体如图1所示。
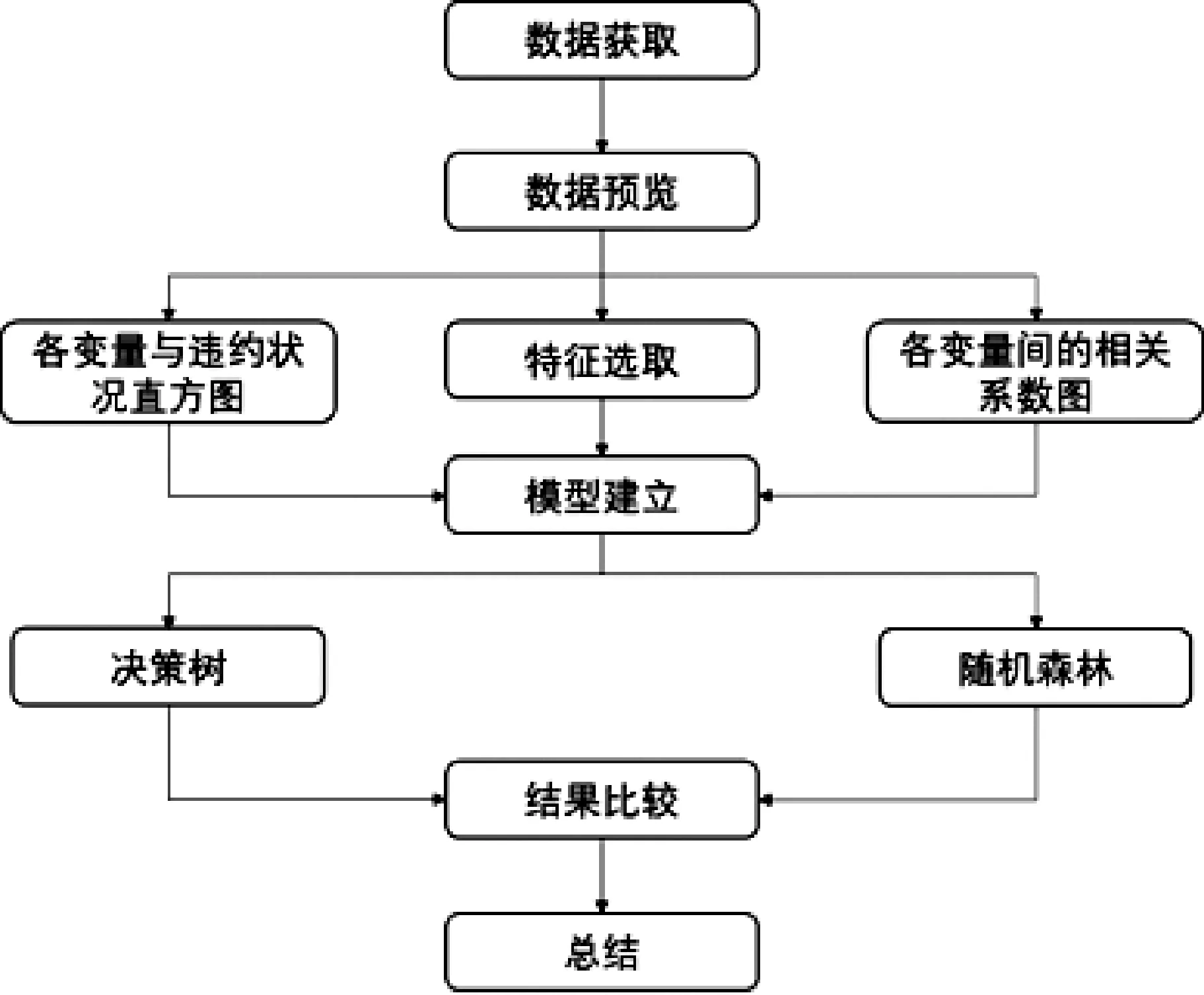
图1 基于两种方法的预测流程
4.2 各变量的相关关系
各变量的相关关系热力图如图2所示,可以看出,颜色越深的地方,代表着这两个变量间的相关关系越强烈。因变量bad_good(违约状态)与变量LOAD_FLAG_b‘Y’(个贷标识‘是’) 相关关系最强、与变量DEP_SA_OPEN_TENURE_DAYS(活期存款最早开户日期距今月份) 和变量 DEP_SA_AVG_TENURE_DAYS(活期存款平均开户时长) 相关关系较强、与LOAD_FLAG_b‘N’(个贷标识‘否’) 相关关系最弱、与剩余的变量相关关系一般。

图2 各变量的相关关系热力图
4.3 特征选取
根据 Relief 算法原理[6],本团队以是否违约作为训练集的因变量,其余变量作为特征子集进行训练。按照权值大小选取具有代表性的12个变量,具体如表1—2所示。

表1 根据Relief 算法提取出来的特征名称

表2 根据Relief 算法提取出来的特征含义
从表2中特征的选择结果看,在40个变量中,贷款账户月余额、当月本币转账取款金额、其他6个月月均交易笔数、负债总额、3个月内贷款账户月均余额、6个月内贷款账户月均余额、其他转出3个月内最大交易金额、最近6个月客户月平均负债总计、最近3个月客户月平均负债总计、活期存款最近开户距今月份、其他6个月月均交易金额和6个月内单日本币单笔最大转出金额这12个自变量对因变量是否违约影响最大。可以看出,它们都体现在负债、交易金额、使用时间和账户余额上,这与实际也是相符合的。
4.4 模型训练结果
除了设置不同的训练次数外,其余参数相同,包括相同的数据集和测试集,使用不同的训练次数得到决策树和随机森林的结果如表3—6所示。

表3 决策树模型精度对比
由表3可以看出,在训练集中,决策树模型总体平均精度是0.804 4,在测试集中,决策树模型总体平均精度是0.735 8。

表4 随机森林模型精度对比
由表4可以看出,在训练集中,决策树模型总体平均精度是0.825 3,在测试集中,决策树模型总体平均精度是0.751 8。

表5 决策树模型耗时对比
由表5可以看出,在训练集中,决策树模型总体平均耗时是161.75 s,在测试集中,决策树模型总体平均精度是69 s。

表6 随机森林模型耗时对比
由表6可以看出,在训练集中,决策树模型总体平均耗时是185 s,在测试集中,决策树模型总体平均精度是88.75 s。
5 结语
在使用机器学习方法预测银行信用卡的违约状态时,数据的预处理所需的时间是最长的,这一问题的原因在于银行信用卡所记录的各种信息是多种多样的。无论使用决策树模型还是随机森林模型,好的特征往往能取到好的结果,而好的算法只是逼近这一结果。所以,在使用机器学习算法进行预测时,必须进行特征工程。
使用随机森林模型进行信用卡违约预测时,其精度比决策树模型高,但模型训练速度比决策树模型慢,产生这一差异的原因在于决策树模型是单个学习器,而随机森林却是由多个学习器组成,所以随机森林的收敛速度在训练过程中较慢。对于实际应用场景来说,若生产环境的计算资源丰富,推荐使用随机森林算法,反之使用决策树模型。
