一种稳定且高效的串口分帧方法的研究及实践
2020-12-04刘中原

摘要:在上位机和单片机通讯过程中,串口通讯是一种常见的通讯方式,特别是在高频率的RFID串口通讯中,数据从单片机向上位机发送非常快,此时稳定且高效的串口分帧技术能从根本上保证数据通讯的正确性,本文基于多年项目实战,总结出了一中基于帧头特征位和协议校验的分帧方法,在多种复杂串口通讯场景中均能正确高效分帧,为上层的业务系统切实提供了可靠的支撑。
关键词:上位机,单片机,串口通讯,分帧
中图分类号:TP368.1
一.研究背景
在上位机和单片机的串口通讯中,当串口数据以协议的格式源源不断地发送到上位机的时候,上位机就需要对数据进行分帧及后续的解析,能正确且高效地分帧是后续所有业务功能的关键,很多初学者在处理该算法时由于考虑不全面很容易走弯路,导致在分帧时不能100%正确或者效率低下致使程序运行缓慢,导致后续业务功能的不正确,根据常规的算法逻辑,一般的处理方法有两种:延时等待一次性数据读取和把串口数据转变成字符串进行截取,但实际应用中发现这两种方法均存在不完善的地方,本文在多年项实战的基础上,总结出一种直接解析串口字节数据流,根据协议本身进行校验的分帧方法,首先直接解析字节流不涉及到对串口数据进行格式转换,节省了性能开销,其次基于协议的校验分帧可以应对各种数据格式和情况,能覆盖数据的任意变化而始终保持正确的解码率,给后续业务系统提供可靠的数据解析支撑,该方法通过众多项目的验证特别是极限性能测试证明是有效的。
二.串口数据分帧常见算法及存在问题
针对于串口数据的非连续上传而由用户事件触发的情况,比如IC读卡器的刷卡,指纹仪中指纹认证,用户的操作速度在和内部程序处理的速度完全不在同一个数量级,同时鉴于串口数据在单片机MCU处理的时候本身就存在发送间隔,一般为50ms,可以利用这个特点在上位机进行延时等待,比如在上位机设置和MCU相同的停顿时间,在程序中使用线程停顿50ms,理想情况下,如果时序能保持一致,则可以和單片机取得同步,延时后读取串口缓冲区数据并进行处理,这种方法是最初级的方法,最直观的特点是容易理解和操作,但数据一旦以非常快的速度连续上传,比如在RFID主机感应标签的场景中,上位机和单片机保持完全同步是很困难的,这就会造成读取的数据会出现很多的非完整帧,当出现断帧时而不进行首尾的拼接处理则意味着数据的丢失,在实际的测试中,这种情况下断帧现象很明显,所以这种最直观的做法只适用于数据上传速度很低的情况,高速的串口数据通讯中这种做法漏洞很大。
第二种常见的分帧方法则是将数据无论什么时候上传过来就接收并转化为字符串进行截取,并同时进行上下断帧的首尾拼接处理,理论上来说,这种方法逻辑上没有问题,在使用具体编程语言实现的时候,主要注意语句的书写和处理,是能保证100%正确的分帧,但在实现的过程中有个无法回避的问题,即将数据转化为字符串时的性能消耗,一般情况下,在性能较好的PC上开发应用程序问题不大,但在硬件条件相对较低的嵌入式终端中,这样处理数据也还是会遇到性能上的瓶颈,在目前的常用的编程语言中,字符串的处理都是相对消耗资源的,特别是数据类型的选型不合适,更会拖累程序的总体表现,比如String和StringBuilder的性能差别就很大,如此种种,在实际使用中,这种方法的实际效果也不尽如人意。
在走过一定的弯路后,开始从串口上传的原始数据上重新审视既能正确分帧同时效率又高的方法,其实一切问题的解决都要从根源入手,通过对比常见的编程语言对串口数据的处理,发现最原始的数据都是字节流,即字节数组,那么此时基于这种数据结构本身不加任何类型转换来对其进行处理将是效率最高的,同时,为了保持数据上传的流畅度,程序中不能加任何的线程停顿,否则会导致数据积压,遵循数据上传的原始速度,将数据按照协议统一读入公共缓冲区,利用协议对其每一个字节流的数据进行分析,下面来详细展开该算法的实现描述。
三.基于帧头特征位和协议校验分帧方法的算法实现
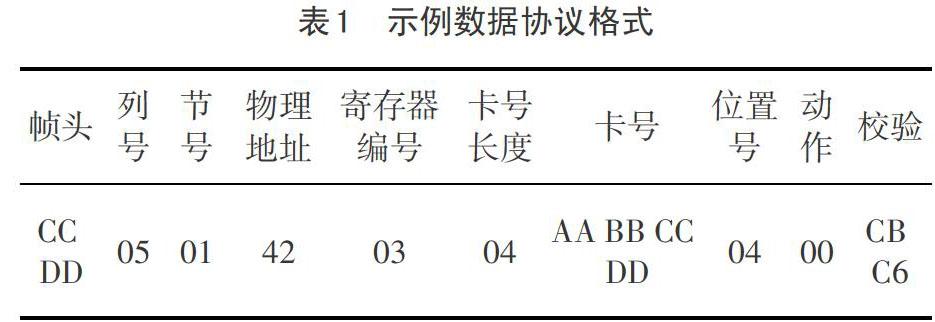
该算法的基础是标准Modbus协议,支持在帧头帧尾加上用户自定义设置,以下面两个连续的数据帧片段为例:CC DD 02 01 48 F3 00 05 4A C4 D7 E4 02 02 B0 54 CC DD 02 01 48 06 00 01 02 FF 97 73,首先该数据的协议格式为如下表所示。
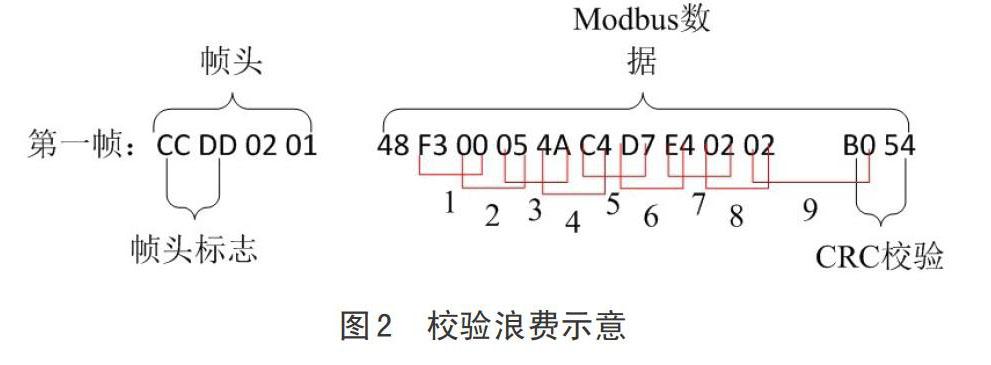
需要特别说明的是,上述协议中,前面4个字节是自定义格式部分,非标准Modbus协议格式,从第5位开始到一帧结束才是标准Modbus格式,即从物理地址到校验,而校验也是针对该帧中Modbus数据部分,帧头的自定义内容不参与校验,根据协议并对上述2帧连续数据的特点进行分析,可以得出如下图1所示的目标效果的分帧格式。
就数据特点而言,这是两个不同类型的帧,数据长度不同,但即使相同,长度仍然不能成为分帧的依据,因为这里面可能有干扰数据,正确做法主要分为2个步骤,首先将读取到的字节流按照循环对数据进行逐个解析,根据帧头标志的特点确定帧头的起始位置;定好帧头后,由于校验位是2位,当待解析的数据长度大于6(4位帧头+2位校验)时即开始计算校验并逐位往后推进,当遇到校验成功时即代表分出一个完整有效的帧,此时将该帧提交到业务逻辑进行处理,重新从下一位数据位按照上述规则进行分帧,如此循环往复,程序算法描述如下。
声明字节流变量allData和frameData,分别代表一次串口读到的所有数据和分帧数据的临时存储,声明整形变量all_Length和frame_Length分别代表所有数据的长度和当前数据帧位置指针,算法具体实现:
frame_Length=0;
For(循环因子i=0;i { If(frame_Length<2) { if (allData[i] == 0xCC || allData[i] == 0xDD)//识别帧头 { frameData[frame_Length]= allData[i]; frame_Length++; } } Else { frameData[frame_Length]= allData[i]; frame_Length++; if(frame_Length>6)//可以进行校验时即开始校验 { If(校验成功) { 处理frameData中已取到的一帧完整数据; frame_Length=0;//重新开始下一帧的寻找 } } } } 从上述伪代码的算法描述中不难看出,分帧的第一步则是识别帧头,一旦识别到以后,则从具备校验条件开始的第一位即进行校验计算,逐位往后推进,直到校验成功则代表一帧完整正确的数据分离成功,这种算法在针对一个场景中无论有多少种不同类型的帧皆可正确处理,在实际的项目应用中也被证明无任何漏帧和错误的发生,证明了算法的完备性,同时算法所选取的背景数据最大限度地减少了协议中的特殊定义,选取了最常见的帧头标识和标准Modbus协议,对于扩展到串口通讯中的其他任意场景亦提供了最大程度的支撑,在具体场景将算法落地时只需要根据目标协议中的帧头特征进行相应的调整即可。 四.算法未来优化方向及进一步的工作 其实针对上述算法仔细分析,不难发现其中有不少的性能浪费,存在进行持续优化的空间,主要体现在校验的计算上,从数据长度满足校验计算的条件开始即进行一次又一次的计算,在真正有效的校验之前的所有校验其实都是浪费的,如图2所示,对于第一帧数据,无 用的校验次数就有9次之多(红色标识位置),但这样的设计主要基于该协议没有设置数据長度位以帮助算法直接找到校验位,这也就给未来的优化提供了比较明确的目标:即在Modbus协议的设计中,首先将本帧数据的长度放在协议的头部区域,当程序读到数据长度时,直接往后推进数据长度位之后直接进行校验,这样既节省了性能开销,又保证了数据帧的正确性和高效的解析速度,是未来在工作中需要进一步实践的地方。 参考文献 [1] 陈爱军.深入浅出通信原理[M]. 北京:清华大学出版社,2018. [2] 张辉.嵌入式MCGS串口通信快速入门及编程实例[M]. 北京:化学工业出版社,2018. [3] ]Christian Nagel. C#高级编程[M]. 清华大学出版社,2017. [4] 郭文夷. C#.NET框架高级编程技术案例教程 [M].北京,清华大学出版社,2014. [5] 周薇. Android嵌入式开发及实训[M]. 北京,电子工业出版社,2019. [1]本文章源自项目《赛尔网络下一代互联网技术创新项(NGII20190701)》 [2]刘中原(1980-),男,汉族,河南商水人,硕士研究生,讲师,主要从事软件方面的教学及研究工作。
