基于学习速率与更新向量的混合云数据冗余值迭代算法
2020-12-02张晓丽
张晓丽
(1.东北大学 机械工程与自动化学院,辽宁 沈阳 110819;2.长春师范大学 数学学院,吉林 长春 130032)
0 引 言
混合云结合了私有云与公有云,是一种混合计算环境,其中私有云是一种IT组织或内部数据中心,通常由公司管理和建立,而公有云则是以收费模型为依据,致力于提供软件服务、平台服务、基础设施服务的计算环境。和公有云计算环境相比,混合云计算环境的灵活性与安全性更高,能够以工作负载为依据,提供高安全性、低成本、高伸缩性的服务[1]。当出现工作负载波动较为剧烈现象时,能够利用公有云资源对混合云的服务水平进行维持,并强化私有云的能力。当前在混合云的应用过程中所面临的最大问题就是混合云数据的冗余问题,目前的混合云数据冗余值较多,因此,混合云数据冗余值迭代问题备受关注[2]。
吴继康等[3]对混合云环境中多个用户数据进行研究,完善了用户数据存储机制,提供了数据共享解决方案,为混合云数据的研究奠定了基础,但并未对云数据深入研究;在此基础上,陈建平等[4]提出一种冗余值迭代算法,针对海量数据中的冗余值迭代问题进行研究,插入一种新的权重因子,构建迭代函数参数向量,完成冗余值迭代研究,该方法获得了一定的研究成果,但数据收敛和平均回报值方面有待加强;郭瑞等[5]重点分析了数据冗余问题,提出了基于一阶谓词公式去除冗余数据的方法,利用一阶谓词公式表示数据关联规则,构建邻接矩阵,删除其中的冗余规则,该方法的数据冗余研究效果较好,但忽略了数据迭代这一问题,导致研究结果收敛性不高;惠宇等[6]提出了数据驱动的最优迭代学习控制方法,通过迭代扩张状态观测器详细分析了参数迭代规律,获取了较好的数据驱动控制方法,但收敛速度较低;众多国外学者也研究了此问题,S.Nepal等[7]分析了混合云中大数据处理问题,给出提高混合云数据可信度的方法,保障数据的完整性和保密性;R.W.Allmendinger等[8]分析了以移动设备为载体,分析使用过程中产生的数据冗余和数据不确定性问题,通过海量数据采集与处理,消除数据集中的冗余数据和不确定数据,但该方法的数据收敛速度不高;ZHENG S[9]提出支持向量数据描述(SVDD)模式分析模型,SVDD通过求解二次规划问题进行迭代;I.I.Rypina等[10]介绍了一种利用漂移器数据研究示踪剂扩散的多迭代统计方法,该方法通过使用一个简单的迭代过程,最佳地利用了可用的漂移数据,但迭代过程中数据的收敛效果不佳。
上述算法在混合云数据冗余值处理中,平均回报值较低且收敛速度控制效果较差。针对此问题,本文提出一种基于学习速率与更新向量的混合云数据冗余值迭代算法,构建混合云数据冗余值值函数,基于深度学习中学习速率要求,获取值函数的稳定值,计算值函数稳定值向量,结合哈希表完成混合云数据冗余值的迭代研究,并验证算法的平均回报值以及收敛速度。
1 基于学习速率与更新向量的混合云数据冗余值迭代算法设计
1.1 基于学习速率获取值函数稳定值
基于深度学习中学习速率要求,获取混合云数据冗余值值函数的稳定值。将混合云数据冗余值值函数视为深度学习中的学习速率,即将其视为一个常数,通过新参数的引进与反复训练以获取值函数的稳定值。在深度学习中,学习速率需要接近0,梯度才不会上升,学习速率还要尽可能大,梯度才不会增加,在混合云数据冗余值迭代算法中引入深度学习这一概念,也就是混合云数据冗余值函数的数值需要接近0才能提升迭代算法的学习速率,值函数的值还需要接近1,才能保证迭代算法的收敛性。为了满足这两种需求,需要引入新参数并进行反复训练。其中混合云数据冗余值值函数的公式为
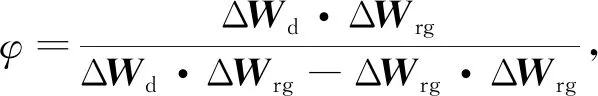
(1)
式中:φ为混合云数据冗余值值函数;ΔWd,ΔWrg分别为混合云数据冗余值的2个权重向量。
在混合云数据冗余值的迭代中,当0≤φ<1时,才能保证迭代算法的收敛。
权重向量ΔWd与ΔWrg的夹角需要满足锐角条件,将参数k代入云数据冗余值值函数,计算φ值大小。计算φ值的分母,将分母与0作比较,当分母的值为0时,φ值即为0,而当分母的值不为0时,利用引进的参数对φ值的分子进行计算,计算完毕后验证φ值是否满足0≤φ<1条件,并对值函数参数进行计算:
ΔWr=k(1-φ)ΔWd+φWrg,
(2)
式中,ΔWr为值函数参数[11]。
接着利用值函数参数对权重向量ΔWd与ΔWrg进行更新,并在更新中引进一个新的参数μ,该参数为一个极小的正数,被称为遗忘因子,引入μ后,权重向量ΔWd与ΔWrg的更新结果为
Wd=(1-μ)ΔWd-μk2,
(3)
Wrg=(1-μ)ΔWrg-μk2。
(4)
通过权重向量ΔWd与ΔWrg的更新加速了迭代算法的收敛速率,获得了值函数的稳定值,即

(5)
1.2 构建值函数更新向量
利用获取的值函数稳定值对值函数更新向量进行构建,获得混合云数据冗余值的期望输出,计算值函数稳定值向量,利用批量更新的方式获取新权值,利用新的权值处理值函数向量,获取值函数更新向量。
利用逼近替代函数查询表对混合云数据冗余值进行逼近替代,即

(6)
式中:V(x)为混合云数据冗余值;x′为x的后续状态;α为逼近替代函数值;R为立即奖赏;γ为逼近替代系数。
利用公式(5)可以使混合云数据冗余值V(x)逐渐接近右边的值[12]。接着对混合云数据冗余值V(x)进行样本训练,获得混合云数据冗余值期望输出P,
P=max 〈R+γV(x′)〉,
(7)
其中,P为混合云数据冗余值的期望输出[13]。V(x)与V(x′)都是跟值函数φ相关的函数,通过样本训练能够调整值函数φ的梯度,使混合云数据冗余值V(x)能够无限接近期望输出值[14]。
获得混合云数据冗余值的期望输出P后,对值函数稳定值φ的向量进行计算:

式中:ΔW为值函数φ的向量;W为混合云数据冗余值更新结果[15]。
利用批量更新的方式对值函数向量的权值增量进行改变,从而产生新的权值λ,利用新的权值处理值函数向量,获取新的全局向量W,从而完成值函数更新向量的构建,即
(9)
逼近替代会导致迭代算法的收敛加快,而批量更新方式会导致迭代算法的发散,二者能够相互抵消,如图1所示[16]。

图1 收敛与发散的抵消过程
1.3 混合云数据冗余值迭代
利用值函数更新向量进行混合云数据冗余值迭代,进行混合云数据冗余值迭代研究[17]。
利用 Bellman 冗余求出混合云数据值函数更新向量的均方差E,
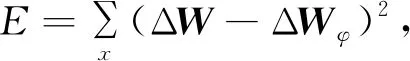
(10)
其中,E为混合云数据冗余值的均方差[18],而混合云数据冗余值均方差的权值增量则为

(11)
式中,ΔE为混合云数据冗余值均方差的权值增量[19]。
根据上述获取的权值增量,结合哈希表完成迭代研究,具体迭代步骤如下。
(1)通过链地址法建立规模为m的哈希表,获取依次进入哈希表的项,可通过下述过程获取:
针对首个进入哈希表的项有
W1=(m-1)/m,
(12)
针对第二个进入哈希表的项有

(13)
针对第三个进入哈希表的项有
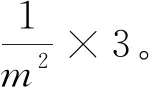
(14)
(2)混合云数据增值向量获取。通常采用简单的散列手段即可获取很好的防冲突效果[20-21]。但数据集保存在不同距离的存储节点中,存在一定的差异,本节通过数据集存储使用强度D(x)与数据节点迭代概率P(x)完成冗余值迭代,提高迭代质量。在独立存储节点中完成数据集流接收,混合云数据集流符合指数为λ的泊松分布,同时存储使用强度符合同一指数的泊松分布[22]。则数据集存储使用强度D(x)的增值向量E[D(x)]符合
(W1+W2+W3),
(15)

(3)结合增值向量,利用权值增量获取混合云数据冗余值迭代函数,即
从而实现混合云数据冗余值迭代算法研究。
2 实 验
为了检测本文提出基于学习速率与更新向量的混合云数据冗余值迭代算法的有效性,将本文算法与文献[4-5,8-9]算法应用于GridWorld问题中。GridWorld问题遵从均匀随机决策中对所有行动进行迭代的原理,可以对迭代方法的收敛性能进行验证。
GridWorld问题指的是格子世界问题,主要包括2个类型,分别是4×5格子和10×10格子。4×5格子包含1个起始状态,1个终止状态,2个陷阱状态。10×10格子包含1个起始状态,1个终止状态。
目标任务迁移至不同状态时,所得奖赏大小不同,在到达终止状态时,立即奖赏最大,在到达陷阱状态时,立即奖赏最小。
2.1 实验参数
实验参数如表1所示。
2.2 实验过程
基于MATLAB实验平台对混合云数据冗余值迭代算法进行加载,实验数据来源于(hybrid cloud database management,HDM),设定本次实验的最大情节数为200,在情节不同的情况下,对混合云数据冗余值迭代算法的总回报值进行计算,从而获得算法的平均回报值(在起始状态到终止状态的过程中,目标任务所获得的奖赏和回报值)。为了保证实验的有效性,使用文献[4-5,8-9]算法与本文提出基于学习速率与更新向量的混合云数据冗余值迭代算法进行比较,观察实验结果,比较各个算法的平均回报值、样本计算耗时与时间步数。

表1 实验参数
2.3 实验结果
文献[4-5,8-9]算法和基于学习速率与更新向量的混合云数据冗余值迭代算法的平均回报值对比如图2所示。

图2 4×5 GridWorld问题中不同算法平均回报值对比
通过图2可知,文献[4]算法在第161个情节左右达到最优收敛;文献[5]算法在第130个情节左右达到最优收敛;文献[8]算法在第130个情节左右达到最优收敛;文献[9]算法在第155个情节左右达到最优收敛。上述4种算法的平均回报值不超过0.5,但本文基于学习速率与更新向量的混合云数据冗余值迭代算法的最大平均回报值约为0.96,该算法在第80个情节左右达到最优收敛。通过比较可知,基于学习速率与更新向量的混合云数据冗余值迭代算法的平均回报值最高,并且收敛速度也最快。
为验证本文算法在大规模动作中的适应性问题,更换格子类型,将4×5格子更换为10×10格子,在此种情况下计算回报值,不同算法的对比结果如图3所示。相比其他几种算法,基于学习速率与更新向量的迭代算法具有较好的收敛性,在情节数为90左右时,该算法趋于收敛,之后的每个情节均处于终止状态,证明该算法具有较高的稳定性。

图3 10×10 GridWorld问题中不同算法平均回报值对比
在不同空间维度内,算法性能亦不同,为验证算法性能,在不同空间维度的格子问题中,计算几种不同算法的耗时情况,由耗时长短判定算法性能。由表2可以看出,在相同空间维度下,本文算法耗时较少,且随着空间维度的增加,耗时始终低于其他算法。
几种算法在不同情节到达终止状态所需的步长对比如图4所示。从图4可以看出,在情节数为50左右时,本文迭代算法已到达收敛状态,随着情节数的不断增加,可以看出本文迭代算法步数较少,迭代较为稳定,具有更快的收敛速度。
3 结 语
本文提出基于学习速率与更新向量的混合云数据冗余值迭代算法,由值函数更新向量构建,实现了混合云数据冗余值的迭代。通过实验结果可知,基于学习速率与更新向量的迭代算法在引入权重因子与遗忘因子后,加快了迭代速率,使收敛速度得到保证,迭代算法稳定性能得到了保证。该算法适用于较大规模空间维度问题,为进一步提高迭代稳定性,使适用范围更为广泛,提高值函数参数更新向量的速率是下一步的研究方向。

表2 不同算法在不同GridWorld问题中耗时对比

图4 不同算法时间步数对比
