TF-IDF和Word2vec在新闻文本分类中的比较研究
2020-12-01王丽肖小玲张乐乐
王丽 肖小玲 张乐乐

摘要:随着互联网时代的发展,各类数据层出不穷,新闻数据更是呈指数爆炸式增长,通过人工对新闻文本进行分类得越发困难。自动文本分类技术作为自然语言处理的重要分支而受到学者们的广泛关注。文章首先对新闻文本进行数据预处理,随后重点研究了TF-IDF和Word2vec两种不同的文本表示方法,采用KNN算法完成新闻文本分类对比,实验结果表明Word2vec表示的特征向量在新闻文本分类中取得了较好的分类效果。
关键词:TF-lDF;Word2vec;文本分类
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2020)29-0220-03
1 引言
自然语言处理中无疑是当前最热的话题之一,文本分类作为自然语言处理的重要分支,其主要包括数据预处理、文本表示、特征选择、构造分类器等过程。文本表示是计算机理解人类语言的桥梁,即它将非结构化的文本数据转化为计算机可处理的结构化数据。文本表示可划分为以one-hot及TF-IDF为代表的离散表示和以Word2vec为代表分布式表示,其中one-hot编码由于无法保留不同词之间的关系且会产生一个维度高又稀疏的特征矩阵故很少直接应用到实际项目中,而TF-IDF和Word2vec常被人们用于解决人工分类的难题。如文献[1]使用TF-IDF算法提取文本特征辅助短文本正确归类。文献[2]融合TF-IDF和LDA的方法解决了FastText文本分类模型在中短文本中精确率不高的问题。文献[3]在传统的TF-IDF关键字权重计算方法中加入位置权值和词跨度权值,从而考虑词语多个特征项来提高分类效果。文献[4]利用Word2vec模型生成专利词向量有效地提高了专利文本的分类效果。文献[5]将单词的词向量和单词贡献度生成文档向量,从而在一定程度上保证了文档向量中重要词词义的完整性。文献[6]指出传统KNN算法的存在的不足,并提出了不同的改进策略。文献[7]使用贝叶斯、KNN和SVM算法对新闻文本分类进行了分析研究。文献[8][9][10]利用经典的机器学校算法对中文文本进行分类研究,指出了各种机器学习算法在中文文本分类上的优势和不足。
本文首先对新闻文本数据进行分词、去停用词等预处理,随后采用TF-IDF和Word2vec两种方法将文本转化为向量并对其进行分类实验,最后讨论了两种文本表示方法在新闻文本分类中的作用。
2 相关工作
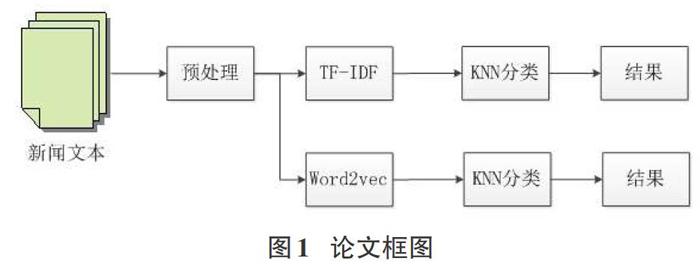
本文分别使用TF-IDF模型和Word2vec模型对新闻文本进行分类研究,总体框架如图1所示。
2.1 数据集及预处理
本文采用搜狐新闻收集的数据集,共选取了房产、家居、时尚、财经、娱乐、游戏、教育、时政、科技和体育等10个新闻栏目的新闻数据,每个类别有6500条数据。首先对全部新闻数据采用jieba工具进行分词,并将分词文本中的停用词剔除;其次把每个类别中的新闻数据划分5000条用于训练,1000条数据用于测试,剩余数据用于验证。
2.2 文本表示方法
由于计算机无法直接处理如语音,文字和图像等非结构数据,故我们需要将文本转化为计算机能够识别的结构化数据。这一过程称为文本表示,即将自然语言转化为向量的过程。
2.2.1 TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency,词频一逆文件频率)是一种用来评估某个词语对于某篇文章重要程度的统计方法,其核心思想是,如果某个词语在一篇文章中出现的频率较高,且在其他文章中鲜少出现,则判定该词语能较好地代表当前文章:
TF - IDF=TF*IDF
TF(词频)指某一个词语在当前文章中出现的次数,由于同一个词语在不同长度的文章中出现的次数不一样,且文章越长,出现的频率可能就越高,故需要对词语进行归一化,计算公式如下所示:
IDF(逆文档频率)是在词频的基础上,对每个词语赋予一个权重,即如果某个词语很少出现在其他文章中,但在当前文章中多次出现,那么这个词语应给予较大的权重;反之如果一个词在大量的文章中均有出现,且在无法代表当前文章内容,则应将较小的权重赋予该词。其計算公式如下:
2.2.2 Word2vec
Word2vec是一种用来产生词向量的浅层神经网络,于2013年Google团队提出,其核心思想是通过词的上下文得到词的向量化表示,共有skip-grams和CBOW两种模型。
如图2所示,CBOW模型先获取某个词的上下文,然后利用上下文推测出这个特定词,即将某一个特征词的上下文相关的词对应的词向量作为输入,并通过评估概率找出概率最大特定词输出。
如图3所示,Skip-gram则是通过某个特定词来预测出可能出现在其上下文的词,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
故由上可知,同one-hot编码相比,Wrod2vec不仅在一定程度上解决了向量空间过大且稀疏的问题,同时还保留词与词之间的关系,从而能有效提升分类的精确率。
2.3 KNN算法
KNN算法又叫K近邻算法,是一种基于类比的分类算法,于1968年Cover和Hart P提出。该算法的基本原理为:给定某一用于测试的样本,然后按照某种距离度量找出训练集中与该测试样本距离最近的k个训练样本,最后基于这k个邻居的信息按照少数服从多数的原则对该样本进行预测,即k个记录多数属于某个类,则该测试样本就属于这个类。KNN算法一般步骤为:
1)计算已知类别的训练数据集中的各点与测试样本之间的距离,常用的距离度量有欧式距离、曼哈顿距离、余弦值等方法,本文采用欧式距离,计算公式如下:
2)将各个训练数据点按照同测试样本的距离递增排序;
3)选取与测试样本距离最小的k个点;
4)确定前k个训练数据点所属类别的出现次数;
5)根据少数服从多少的原则,将前k个训练数据点所属类别出现次数最高的类别作为测试样本的预测分类。
3 实验分析
为了验证本文提出的算法的性能,在同一个数据集上使用不同的分类算法进行实验对其实验结果进行对比分析。
3.1 评价指标
文本分类中常用的性能评价指标有精确率(precision)、召回率(recall)和F1(F1-measure)值等。假设:
TP:被模型预测为正的正样本;
FP:被模型预测为正的负样本;
FN:被模型预测为负的正样本; T N:被模型预测为负的负样本。
精确率P是指所有被预测为正的样本中实际为正样本的概率,其公式为:P=TP/TP+FP。
召回率R是指正样本中被预测为正样本的概率,其公式为:R=TP/TP+FN。
F1是能够同时考虑精确率和召回率的综合评价指标,是P和R的加权调和平均,其公式为:F1=2*PR/P+R。
3.2 实验结果与分析
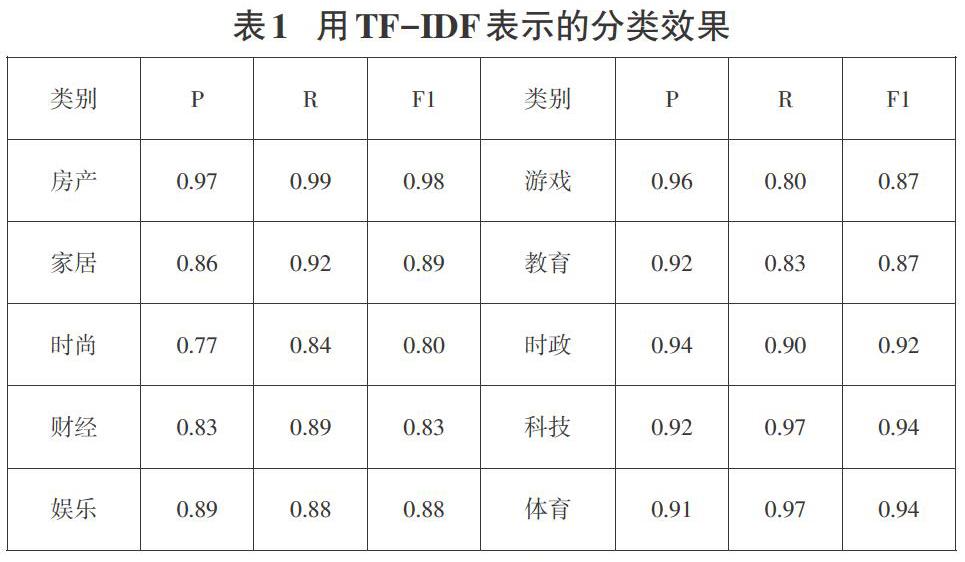
由于Python有丰富的功能库,且调用简单方便,故本文基于Python语言实现TF-IDF模型和Word2Vec模型,采用KNN算法进行新闻文本分类,最后利用精确率、召回率和F1值三项评价指标对分类效果进行对比分析。如下表1所示。
由表1可知TF-IDF模型的分类效果总体水平可达到89%,但其表示的新闻文本向量在各类分类效果有明显差异。如房产类别的精确率高达97%,召回率和F1值均在精确率之上,而在时尚这一类别中,其在精确率、召回率和F值分别低于房产的20%、15%和18%。
从表2可知Word2vec模型的分类效果总体水平可达到93%,各类分类效果在TF-IDF模型上均有提升,如在時尚这一类别中,其在精确率高达95%。其中房产的分类效果最好,三个指标均高达98%。家居、游戏、时政、科技和体育不仅都在总体水平之上,而且它们的三个评价指标值相差不大,由此可见分类模型对它们的识别效果较好。
从上图对比两种模型的三个评价指标可得出结论,Word2Vec模型在新闻文本中分类效果优于TF-IDF模型。如在精确率和Fl值两个评价指标中,10个类别的精确率均有不同幅度的提高,其中时尚类别中尤为显著;在召回率评价指标中,虽然Word2Vec模型中房产、时尚和科技类别的召回率低于TF-IDF模型,但是总体水平还是呈现一个提升的趋势。
4 结论
本文结合搜狗新闻数据对TF-IDF模型和Word2Vec模型进行比较研究,并利用KNN算法进行了分类实验。选择TF-IDF模型表示特征向量时,筛出部分高频词虽然在一定程度上解决了特征空间高维度和稀疏的问题,但其无法保留词与词之间的关系使得分类效果无法更上一层楼。在Word2Vec模型中,本文首先利用大量的搜狗新闻语料库训练得到的词向量,随后采用平均法来表示新闻文本向量。结果表明,对新闻文本进行分类时,使用Word2Vec模型是一种效果较好的一种方法。
本文仍存在一些不足之处,如在时尚和财经两个类别的分类效果明显比其他几类低,且由于硬件条件和时间的关系,本文实验所涉及的新闻数据不是最新的,这都是后期需要继续研究的问题。
参考文献:
[1]黄春梅,王松磊,基于词袋模型和TF-lDF的短文本分类研究[J].软件工程,2020,23(3):1-3.
[2]冯勇,屈渤浩,徐红艳,等,融合TF-IDF和LDA的中文Fast-Text短文本分类方法[J].应用科学学报,2019,37(3):378-388.
[3]张瑾,基于改进TF-IDF算法的情报关键词提取方、法[J].情报杂志,2014,33(4):153-155.
[4]薛金成,姜迪,吴建德.基于word2vec的专利文本自动分类研究[J].信息技术,2020,44(2):73-77.
[5]彭俊利,谷雨,张震,耿小航,融合改进型TC与word2vec的文档表示方法[J/OL].计算机工程:1-7[2020-05-06].https://doi.org/10.19678/j .issn.1000-3428.0056370.
[6]奉国和,吴敬学.KNN分类算法改进研究进展[J].图书情报工作,2012,56(21):97-100,118.
[7]祁小军,兰海翔卢涵宇,丁蕾锭,等.贝叶斯、KNN和SVM算法在新闻文本分类中的对比研究[J],电脑知识与技术,2019,15(25):220-222.
[8]刘红光,马双刚,刘桂锋.基于机器学习的专利文本分类算法研究综述[J].图书情报研究,2016,9(3):79-86.
[9]朱梦,基于机器学习的中文文本分类算法的研究与实现[D].北京:北京邮电大学,2019.
[10]兴艳云.基于机器学习的文本分类技术研究[D].青岛:青岛科技大学,2019.
【通联编辑:代影】
作者简介:王丽(1995-),女,贵州兴义人,长江大学硕士研究生,主要研究方向为智能信息处理;通讯作者:肖小玲;张乐乐(1992一),男,河南郑州人,长江大学硕士研究生,要研究方向为智能信息处理。
