面向句法块向量的句子相似度计算方法
2020-12-01高顺峰张再跃
高顺峰 张再跃


摘 要:傳统句子相似度算法没有全面考虑句子结构与语义特征,影响相似度计算准确性,对此提出一种基于句法块向量的句子相似度计算方法。该方法综合考虑句子的语义信息与结构信息,首先构建两句子的语义依存关系树,然后进行一些被动转换等操作,最后根据词向量构建各个句法块向量并通过余弦值计算句子相似度。在常规句子对中进行测试实验,结果表明,综合句子结构与语义信息可提高相似度计算准确性。一般句子相似度计算正确率达到92%,比传统方法提高8%~10%。
关键词:句子相似度;语义依存树;词向量;自然语言处理;句法结构
DOI:10. 11907/rjdk. 201048
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)010-0106-05
Abstract:Traditional sentence similarity algorithms do not fully consider the structure and semantic characteristics of sentences, which affects the accuracy of similarity calculation. In this regard, a new calculation method for sentence similarity based on syntactic block vectors is proposed. The feature of this method is to comprehensively consider the semantic and structural information of the sentence. It first constructs the semantic dependency tree of the two sentences, then performs some important operations, such as passive conversion, etc., and finally constructs each syntactic block vector and sentence vector based on the word vector sentence similarity is calculated from the cosine value. Tested in regular sentence pairs, the experimental results show that the comprehensiveness of sentence structure and semantic information can improve the accuracy of similarity calculations. For general sentence similarity calculations, the accuracy rate reaches 92%, which is 8% to 10% higher than the traditional method.
Key Words: sentence similarity; dependency syntax tree; word embedding; natural language processing; syntactic structure
0 引言
度量句子之间的相似性是自然语言处理一项基本且重要的任务,广泛应用于信息检索、文本聚类、问答系统、文本分类、机器翻译等。句子相似度计算是这些任务中基础且重要的步骤。近年出现许多句子相似度计算方法,如基于Word2Vec、GloVe、FastText或其改进版本、基于同义词词林的句子相似度计算方法等。Word2Vec、GloVe利用词向量计算句子相似度,充分利用句中的相似词,但没有考虑句子顺序结构,这点往往会对一些否定句以及被动句的相似度计算造成较大影响[1]。基于同义词词林的方法利用同义词词林编码以及结构特点,同时考虑词语的相似性及相关性,但未包含词语的语义信息,对相似度计算有一定影响[2]。
以上方法各有优势与不足,但均没有考虑到中文句法成分的特殊性与差异性,没有充分利用句子的语义信息与结构信息。鉴于此,提出一种基于句法块向量的句子相似度算法(Sentence Similarity Method Based on Syntax Block Vector,SSSB),更大程度考虑句子的语义特征与结构特征,利用句子语义依存关系获取句子的句法块,通过词向量构造句法块向量与句子向量,增加被动句转换和否定句判断,以此提高句子相似度精确性。
一般中文句子句法成分包括主语、谓语、宾语、定语、补语、状语等。其中主、谓、宾是句子主干,定、补、状是句子枝叶。不同的自然语言处理任务需要的句法成分也不同,比如新闻标题更强调主语、谓语和宾语。一个句子可以没有主语或主语承前、蒙后省略,一个句子也可以没有宾语,但一个句子绝不能没有谓语,没有谓语的句子就不存在。因此,本文以谓语为中心对句子进行分析。利用句子的句法结构和句子向量对句子进行相似度计算。与传统的Jaccard算法、TF-IDF算法和基于词向量的句子相似度算法相比具有更高的准确性。
1 相关工作
1.1 词向量
词是最小和最有意义的语言单位,广泛应用于基于神经网络的分布式表示,也称为单词向量。该方法使用神经网络模拟目标词与上下文之间的关系,使其可以代表复杂的背景。李小涛等[3]提出基于词向量的词语间离和句子相似度模型,该方法结合词向量与传统语义解析两者优点,在相似度计算上取得很好效果,但是该方法只注重词的语义信息而忽略了句子的结构信息。本文在此基础上引入句子的结构信息和句向量,以提高相似度计算的准确性。
谷歌公司发布的开源词向量训练工具 word2vec主要实现CBOW和skip-gram两种模型,其中一词多义问题采用k-means算法解决。skip-gram模型是包含输入层、隐藏层和输出层的三层神经网络模型,由于此模型简单且训练参数少,所以其训练效率很高。Word2vec以任意大小的文本集合作为输入,通过无监督训练得到包含所有词向量的二进制文件。之后再利用高维向量作为输入,把深度学习应用到NLP的诸多领域中,词向量本身蕴含的语义信息可直接作为词相似度计算的依据。如Mikolov[4]发现[vec(berlin)-vec(germany)+vec(france)][≈vec(paris)],其中vec表示单词向量,这表明词向量之间的相似度也可以表示成词在语义层面的相似度,本文就是采用word2vec的skip-gram模型构造词向量。
1.2 语义依存树
语句由词组成,通常包括主语(词)、谓语(词)和宾语(词)3个主要成分,当然还可能有其它成分,如定语、补语、状语和语气助词等。作为句子,谓语成分是不可忽略的,因而句子的谓语词称为该句子的“核心成分”。词与词之间存在一定的关系,如主、谓之间的“施事关系(nsubj)”、谓语和宾语之间的“受事关系(dobj)”等,这些关系称为词与词之间的依存关系。随着统计自然语言处理的演化,针对语句的语义依存树广泛应用。语义依存关系树最先由法国语言学家L.Tesniere[5]在1959年提出,主要方法是将句子按照一定规则分解,分析词与词之间的语义依存关系,并通过树的形式将词语之间的依存关系直观展现出来。
如果[S=w1w2wn]是含有[n]个词的句子,那么[S]的语义依存树可表示为二元组[TS=(NS, ES)],其中,[NS={w0,w1,wn}]为结点集,由语句[S]的各个分词加上引入的根结点[w0(root)]组成;[ES={e1,e2,,em}]为边集,每条边[et=(depk,wi,wj)]为一个三元组,表示语句[S]中的词[wi,wj]具有依存关系[depk]。如果[wk]是语句[S]中的核心成分,那么[e1=(Root,w0,wk)]表示[wk]是树的根节点。
语义依存关系分析是信息论研究领域的重要内容之一,其最核心的思想是阐明一个完整句子中各组成部分之间的相互关系。其中,主成分一般为句子核心词,通常起着支配其它成分的作用,而修饰成分则被用来描述语境,起修饰作用并受主成分支配。通过语义依存树,可以得到句子中词与词之间的依赖关系,从而分析出句子的主谓宾结构。目前,构建语法依存树的常用方法是哈工大提出的较为完善的封装式语义依存树构建方法[6]。
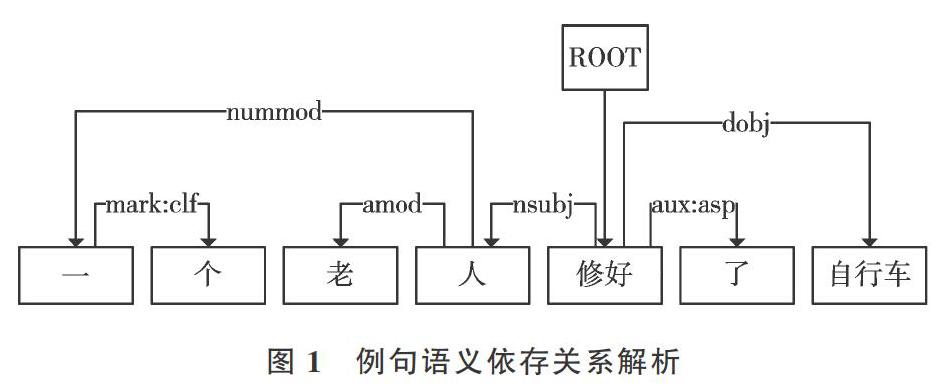
以语句“一个老人修好了自行车”为例,构建其语义依存关系树。首先经分词得到结点集[NS={Root,一,个,老人,] [修好,了,自行车}],其中,“修好”是核心成分,因而有[e1=(Root,root,修好)],“人”和“修好”是施事关系“nsubj”, 即主语和谓语,所以可定义[e2=(nsubj,人,修好)];“自行车”和“修好”是受事关系“dobj”,即宾语和谓语,所以可定义[e3=(dobj,修好,自行车)],等等。最终得到语句“一个老人修好了自行车”的语义关系依存树如图1所示。
利用语句的语义关系依存树,很容易得到句子主语、谓语和宾语以及其它成分之间的关系,为计算句子相似度带来极大便利。
1.3 句子相似度模型
句子相似度计算模型较多,如基于距离的相似度算法、基于语义的相似度算法、基于空间向量模型的TF-IDF方法、基于词向量的Jacard相似度算法和基于字向量的相似度算法等[7]。
(1)基于距离的相似度算法2001年由张焕炯等[8]提出,该方法建立文本集与码字集之间的一一对应关系,然后借用编码理论中汉明距离概念,由汉明距离计算公式计算句子相似度。与传统方法相比,它具有简便、快速等优点,但是准确率相对较差。
(2)TF-IDF方法[9]是一种句子相似度计算统计方法,用来评估一个字词对一个文件集中的其中一份文件的重要程度,其重要性随其在文件中出现的次数增加而增加,但同时随着其在语料库中出现的频率增加而降低。该方法是以大规模语料库为基础的方法,在信息检索领域非常流行。其中单词向量以语料库中的关键词确定,关键词确定是TF-IDF的重要工作,计算公式如下:
TF为归一化后的词频,描述词在文档中的频率。其中,[ni,j]是该词在文件中出现的次数,[knk,j]为文件所有词数。IDF为逆文档频率,起降低通用词作用。某一特定詞语的IDF,可由总文件数和包含该词语之文件的数取以10为底的对数计算得到。其中[|D|]是语料库中的文件总数。[|{j:ti∈dj}|]是包含词语[ti]的文件数,[dj]为包含词语[ti]的文件。若该词语不在语料库中则会导致分母为零,因此一般情况下使用[|{j:ti∈dj}|+1]。TF-IDF值由TF与IDF的乘积得到。某一特定文件内的高频率词语,以及该词语在整个文件集合中的低频率文件,可以产生高权重的TF-IDF。因此,TF-IDF更适合过滤掉常见的词语,保留重要的词语。TF-IDF在句子相似度的应用主要是找出两个句子的关键词组,再计算各关键词的词频并将其向量化,最后通过余弦公式计算句子的相似度。相似度计算公式如下:
其中,[ω(i1≤i≤n)]为关键词组在[Sx]中出现的次数,[β(i1≤i≤n)]为关键词组在[Sy]中出现的次数。该方法只考虑句子的结构信息,没有考虑句子的语义信息,本文在此基础上增加句子的语义信息以及句子的被动转换操作,以提高相似度计算的准确性。
(3)句子的语义依存关系是衡量句子相似度的方法之一, Li等[8]提出一种基于语义的句子相似度计算方法,该方法通过计算两句句子的有效搭配计算句子相似度,公式如下:
其中,[W1]表示[Sx]与[Sy]之间词的有效匹配权值,[W2]表示[Sx]与[Sy]之间单词的有效匹配权值。[PairCount1]是[Sx]到[Sy]的有效词匹配数,[PairCount2]是[Sy]到[Sx]的有效词匹配数。用[W1]与[W2]的和除以[PairCount1]与[PairCount2]的最大值。该方法仅利用词的句法匹配初步判别两个句子的相似程度,但不能从整体上考虑句子的句法信息,因此计算的相似度不全面。SBSS不仅考虑句子的结构信息,还引入句法块以及词向量方法,增加句子的句法信息,使相似度计算更加准确。
(4)Jaccard相似度改进算法2018年由田星等[10]提出,该方法首先通过训练将每个词语映射为语义层面的高维向量,然后计算各个词向量之间的相似度,高于阈值α的作为共现部分。虽然考虑了句子的语义信息,但缺乏句子的结构信息,也缺乏对句子正否定的判断,因而影响相似度计算的准确性。
2 句子相似度算法
传统的相似度算法[4]缺乏对句子多元信息的综合考量,如前述的TF-IDF方法只考虑句子的词频信息,并未关注词义与句子的结构信息,易导致较低的句子相似度准确度。如Word2vec方法[6]仅仅考虑词义而忽视句子的结构信息,从而引起句子相似度的偏差计算。鉴于此,笔者设计一种Sentence Similarity Method Based On Syntax Block Vector(SSSB)模型。该模型对词义与句子的结构信息加以综合考虑,创新性地引入否定句判断与被动句转换,增加相似度计算的精确性。设计的SSSB模型不同于传统的相似度算法,其结合了词向量和句子的句法依赖关系,首先通过句子的句法依赖关系抽取句子的句法块,其次利用词向量构造句子的句法块向量和句向量,进而利用所得到的句向量余弦值表示句子的相似度,以提升相似度的准确性。
2.1 句法塊概念与模型基本框架
句法块是根据句子的主谓宾区分的,分为主语块、谓语块和宾语块。设[S=w1w2wn]是含有[n]个词的句子,[S]的语义依存树可表示为二元组[TS=(NS, ES)],其中,[NS={w0,w1,,wn}]为结点集,由语句[S]的各个分词加上引入的根结点[w0](root)组成;[ES={e1,e2,,em}]为边集,其中每条边[et=(depk,wi,wj)]为一个三元组,表示语句[S]中的词[wi,wj]具有依存关系[depk];[ek]中[depk]值为“nsubj”或 “nsubjpass”时,[ek]中的[wi]为主语;[ek]中[depk]值为“dobj”或“iobj”时,[ek]中的[wi]为谓语;[ek]中[depk]值为“iobj”时,[ek]中的[wj]为宾语。将主谓宾分别表示为[ws]、[wp]、[wo],其中主语[ws∈Su],谓语[wp∈Pr],宾语[wo∈Oc]都表示句子中的一个词。将主谓宾的修饰词分别表示为[s_modifier]、[p_modifier]和[o_modifier],主语修饰词[s_modifier]是[Es]中所有与主语[ws]有依赖关系的词;谓语修饰词[p_modifier]是[Es]中所有与谓语[wp]有依赖关系的词;宾语修饰词[o_modifier]是[Es]中所有与宾语[wo]有依赖关系的词;主要的依赖关系值[depk]如表1所示,主谓宾及主谓宾修饰词如下:
主语块由主语与主语的修饰词组成,谓语块由谓语与谓语的修饰词组成,宾语块由宾语与宾语的修饰词组成,那么主语块、谓语块和宾语块可分别表示为[Su={ws}?] [s_modifier],[Pr={wp}?p_modifier],[Ob={wo}?o_modifier],最终得到句子S的句法块[Sblock=(Su,Pr,Oc)]。
SSSB模型基本框架分为:①解析部分:解析句子语义依存关系;②构造部分:完成句法块向量的构造;③计算部分:进行句子相似度计算,其模型结构如图2所示。
2.2 SSSB模型计算过程
SSSB模型计算步骤如下:
(3)被动转换。一般被动句对于主动句而言结构是倒置的,导致某些相似句子被误判为不相似句,为此增加被动转换步骤,将一般被动句转为主动句形式。中文被动句主要分为标志型被动句和无标志型被动句[11],本文主要针对标志型被动句进行被动转换。标志型被动句由“被”、“叫”、“教”、“让”、“给”等5个介词作为被动标志,不妨称之为“被动词”。被动语句的一般形式可表示为:
其中[N1]为主语,[N2]为宾语,其主动句式一般可表示为
为增加句子相似度计算的准确性,对被动形式的句子进行被动转换,得到句子的主动形式,本文只检测一般被动句,对于复杂被动句暂不考虑。
首先检测句子是否存在作为被动标志的5个介词“被”“叫”“教”“让”“给”,若存在,则对句子进行被动转换,互换主语块与宾语块。对于一般被动句[S],交换[S]的主语块与宾语块,原本[S]的主语块和宾语块为[Su={ws}?] [s_modifier]和[Ob={wo}?o_modifier],被动转换后使[Su={wo}?o_modifier],[Ob={ws}?s_modifier],之后再根据句法块和词向量构建句法块向量。
(4)构建句法块向量。考虑到句子的语义信息,将句法块中的词转为词向量。句法块向量由块中单词向量的加权和表示,每个句法块都有一个核心词。句法块向量和词向量在不同的向量空间中虽然维数一样,但不能作比较。句子[S]的句法块向量计算公式如下:
其中,[BVi]表示句子第[i]个句法块的块向量,i=1表示主语块,i=2表示谓语块,i=3表示宾语块。[Nxi]表示句子[Sx]中第[i]个句法块的所有单词,[wj]表示块中的第j个单词,[λj]表示第j个单词的权重(离关键词越近权重越高,由人工调试)。[e(wj)]表示第j个单词的向量。句法块向量最后将拼接到句子中形成两个句子的句向量。
(5)拼接块向量并计算句子相似度。拼接块向量前先判断块中是否含有否定词,如“不” “没”等。用[αi]表示句法块中否定词个数。句子向量构造如下:
其中,[BV1]、[BV2]、[BV3]分别表示主语块向量、谓语块向量、宾语块向量,[λ1]、[λ2]、[λ3]为负调节因子,根据句法块中否定词数量取值。
3 实验结果与分析
3.1 实验数据
本文相似度实验数据集均来自Tang等[12]提供的chineseSTS数据集,数据集共有12 747个句子对,由于训练时间过长,选取5 000对和人工编写的400对作为实验数据,其中相似和不相似句子各占50%。本文词向量训练数据集采用百度百科、维基百科语料。深度学习框架使用Word2vec的Skip-grams模型,维度设置为200维。
3.2 实验指标评价
用准确性衡量各方法优劣,计算公式如下:
T:真实为0,预测也为0或者真实为1,预测为1;
F:真实为0,预测为1或者真实为1,预测为0;
其中,Accuracy为准确率,最大值为1,最小值为0。
3.3 对比实验分析
将本文模型与传统的Jaccard算法、基于TF-IDF的算法和基于词向量的两种传统句子相似度算法作对比实验,结果表明,本文提出的基于词向量和语义依存的句子相似度方法结合了句子语义信息与结构信息,计算效果较好。本文方法与同类方法的准确率对比结果如表2所示。
表2为不同句子相似度算法在数据集上的準确率,表3为不同相似度算法计算特定例句的得分情况。对比表2与表3,说明本文提出的句子相似度模型具有较高准确率,特别适用于被动语句的相似度计算,符合人们对汉语语言的认知。
4 结语
本文提出一种基于词向量和语义依存树的句子相似度模型,研究了句法块在句子级语义相似度中的作用及中文被动句的转换等。为在一定程度上保证句子中单词顺序,将构造好的句法块嵌入到句子中,通过计算句子对向量的夹角余弦值求得相似度值。由于中文句子句法复杂,不同应用所侧重的句法块不一样,本文模型未考虑所有的句法成分,也未考虑所有的被动句转换。后续研究要进一步考虑句法结构中的句法要素,增加对无标志型被动句的转换,在不同自然语言处理任务中构建句子对的相似度计算模型。
参考文献:
[1] PENNINGTON J,SOCHER R,MANNING C D. Global vectors for word representation[M]. In Emnlp, 2014.
[2] 李婉婉,张英俊,潘理虎. 基于语义相似度的本体概念更新方法研究[J]. 计算机应用与软件,2018,35(4):15 - 20.
[3] 李小涛,游树娟,陈维. 一种基于词义向量模型的词语语义相似度算法[J]. 自动化学报,2019,25(6):1-16.
[4] MIKOLOV T. Statistical language models based on neural networks[R]. Technical report, Google Mountain View ,2012.
[5] 特斯尼埃. 结构句法基础[J]. 当代语言学报,1985,33(2):19-21.
[6] LIU T, CHE W, LI Z. Language technology platform. journal of chinese information processing[J]. Journal of Chinese Information Processing, 2011, 25(6): 53-62.
[7] 何颖刚,王宇. 一种基于字向量和LSTM的句子相似度计算方法[J]. 长江大学学报(自然科学版),2019,16(1):88-94.
[8] 张焕炯,王国胜,钟义信. 基于汉明距离的文本相似度计算[J]. 计算机工程与应用,2001,28(19):56-61.
[9] 赵胜辉,李吉月,徐碧,等. 基于TFIDF的社区问答系统问句相似度改进算法[J]. 北京理工大学学报,2017,37(9):982-985.
[10] 田星,郑瑾,张祖平. 基于词向量的Jaccard相似度算法[J]. 计算机科学,2018,45(7):186-189.
[11] 张兴旺. 现代汉语被动句的界定及其分类[J]. 阴山学刊,2008,17(1):15-19.
[12] TANG S C, BAI Y Y, MA F Y. Chinese semantic text similarity trainning dataset[D]. Xian:Xian University of Science and Technology,2016.
(责任编辑:杜能钢)
