基于卷积神经网络的人脸检测算法研究
2020-12-01刘天保
刘天保

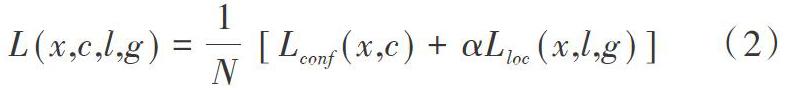
摘 要:近年来,随着深度学习的迅猛发展,人脸检测算法准确度已有很大提升。模型越复杂,检测速度越慢,设计一种准确度与速度兼顾的人脸检测模型尤为必要。基于FaceBoxes人脸检测算法框架,提出一种基于深层卷积主干网络的改进方法,并在人脸检测基准数据集中进行测试实验。其在FDDB数据集上的实验结果显示,检测正确率达95%,比传统方法提高1.67%。该算法在保证实时性的同时提升了检测准确率,可应用于追求更高准确率的人脸检测系统。
关键词:人脸检测; 深度学习; 卷积神经网络
DOI:10. 11907/rjdk. 201219
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2020)010-0066-05
Abstract: Thanks to the rapid development of deep learning in recent years, the accuracy of face detection algorithm has been greatly improved compared with the earlier algorithms. However, the more complex the model detection speed will be slower, so the design of a face detection model with both accuracy and speed has become a major topic in this field. Based on FaceBoxes, a face detection algorithm framework, this paper proposes an improved method of deep convolutional backbone network, and conducts test experiments in the face detection benchmark data set. The experimental results on the FDDB data set showed that the detection accuracy reached 95%, which was 1.67% higher than the traditional method. The algorithm in this paper not only guarantees real-time performance but also improves the accuracy of detection, which can be used in more accurate face detection systems.
Key Words: face detection; deep learning; convolutional neural network
0 引言
目前,人脸检测技术已广泛应用于人们的日常生活中,如机器人[1]、自动驾驶[2]、逃犯追捕[3]、考勤打卡[4]、门禁系统[5]等都用到了人脸检测技术。人脸检测是计算机视觉和模式识别的应用方向之一,是一项解决其它人脸相关工作(如身份识别、表情识别、性别识别等)的前导工作。将检测到的人脸图像切割后作为后续信息输入,可大大缩减机器计算量。以卷积神经网络算法为主的各种人脸检测算法已在不同的人脸检测基准测试数据集中表现出令人满意的准确率。然而,它仍然面临一项挑战,即在真实环境中的图像变化复杂,存在姿态、光照、遮挡、变形等问题。人脸检测可以看作是目標检测的一个特例问题,可借鉴如Faster-RCNN[6]、SSD[7]等目标检测算法,并在这些经典算法基础上再针对人的面部特征进行改进。与以往人脸检测算法目的不同,本文旨在提升人脸检测精确度,同时保证识别速率在原模型水平范围内,使得模型可以在单核CPU中正常工作。
1 相关工作
近20年来,人脸检测技术得到了广泛研究与应用。人脸检测发展共分为两个时期,即早期手工特征提取加机器学习方法、近期基于卷积神经网络的人脸检测方法。
早期研究包括基于级联的方法和基于可变形部件模型(Deformable Part Models,DPM)的方法。Jones等[8]于2003年提出基于Haar类特征的级联AdaBoost分类器进行人脸检测; Yang等[9]使用更高级的特性与分类器实现结果优化。除基于级联的人脸检测方法外,还有一种使用DPM的方法[10]。DPM算法依据改进后的HOG特征、SVM分类器和滑动窗口检测思想,针对目标多视角问题,采用多组件策略,针对目标自身形变问题,采用基于图结构的部件模型策略。此外,人脸检测研究最新进展主要集中在基于深度学习方法上。Zhang等[11]采用构造级联CNNs,使用一种由粗粒度到细粒度的策略学习人脸检测器;Yu等[12]引入IoU(Intersection-over-Union)损失函数概念,利用其最小化方法拟合预测结果框和原始标注框(Ground-Truths);Zhang等[13]提出一种基于密度计算的候选框生成设计,以解决低像素人脸检测率低的问题。
早期方法的优点是检测速度快,检测过程可以在CPU中实时进行。其缺点也很明显,由于是手工提取特征,提取的姿态、光照、遮挡、变形等问题鲁棒性不强,因此在复杂环境中检测准确率不高。基于CNN的人脸检测在检测准确率上与传统方法相比提升较大,但也存在一些问题:模型参数规模庞大、计算量较大,很多算法模型在GPU中的推理速度达数十秒,效率不佳。
2 网络结构设计与训练分析
2.1 人脸检测流程
人脸检测流程和目标检测流程类似,如图1所示。其原理简单而言就是输入一幅图像、一些候选框和正确的标注框,然后模型在众多候选框中挑选,使得选择输出的结果框尽量与正确的标注框重合。上述方法的关键点可分为以下几部分:
(1)图像预处理。对输入前的图像数据作归一处理,使得所有图像输入尺寸统一。
(2)候选框(Anchor)选取策略设计。候选框是可作为最终检测结果的框的集合,需根据经验决定选取方案,目的是在保证将原始标注框(Ground-Truths Box)包含在内的前提下,尽可能降低候选框数量。因为过多的候选框会提高算法复杂度,使网络变得笨重,训练和推理效率变低。
(3)CNN网络结构设计。设计CNN网络结构后,为方框位置和类别损失选择两种损失函数。
2.2 网络设计
2.2.1 网络整体结构
网络结构主要采纳FaceBoxes算法(下文也称Baseline),并进行适当调整,网络结构如图2所示。
特征提取层的作用是让网络提取得到的特征图能尽可能地表达图像所有特征,其提取结果好坏将直接影响最终算法精确度。多尺度学习层的名字也是根据这一层的作用而取,其作用有两种:一是多种尺寸的感受野,效果可以通过Inception层实现;二是多种尺寸的特征图,通过将设计好的不同尺寸候选框与Inception3、Conv4和Conv5层输出的特征图相关联而实现。
2.2.2 图像预处理阶段
预处理阶段所使用的方法均为常用图像预处理方法,具体方法如下:
(1)随机裁剪与填充。随机裁剪能够增强小目标检测,然后将随机裁剪后的图像进行黑边填充至分辨率为 1 024?1 024,这样可以保证经过处理后输入图像尺寸统一。
(2)颜色失真处理。使用文献[14]中提出的颜色失真策略,降低光照对识别的影响。
(3)随机旋转。每张图片有50%的概率进行180°垂直翻转。
(4)边缘目标框保留策略。将经过上述预处理的图像中,中心不在图像中的目标框过滤掉,然后在保留下来的边缘目标框中,再过滤掉像素值小于20的部分目标框。
2.2.3 训练阶段
本文对原算法中的主干网络结构(Rapid Digested Convolutional Layers,RDCL层)进行调整,使用三层卷积层和两层池化层。目的是使1 024?1 024的图像快速降维至32?32,缩小网络输入,从而减少计算量,起到提速效果。主干网络输入输出参数如表1所示。
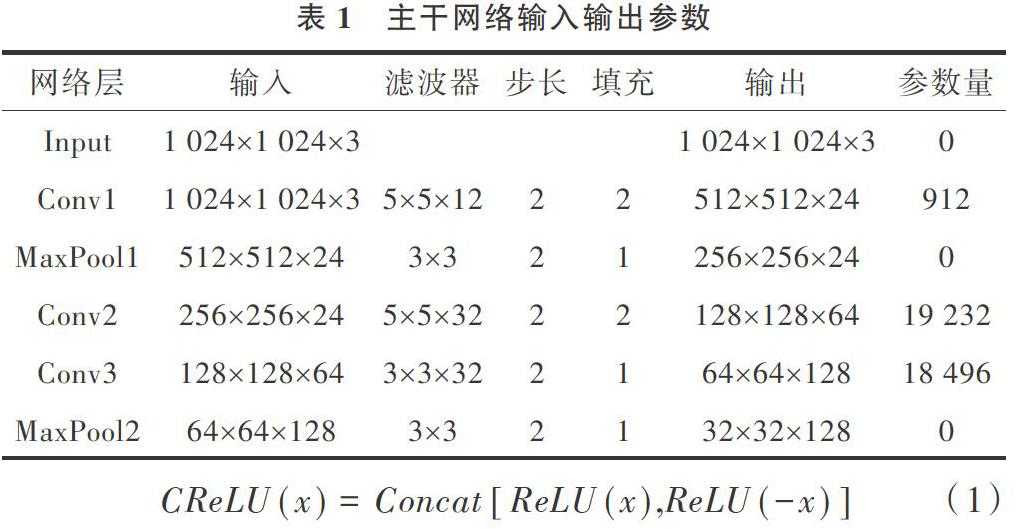
表1中的卷积层(Conv)均使用CReLU作为激活函数。CReLU激活函数是对输入数据x取相反数后,分别针对x和-x使用ReLU激活函数,用Concat操作将输出结果连接,从而使得输出维度拓展至原来的两倍,这样做可在不增加参数的情况下充分利用数据。CReLU定义式如式(1)所示。
后续多尺度学习层沿用FaceBoxes中MSCL层(Multiple Scale Convolutional Layers)的思想,使用三层Inception和两个两层卷积进行多任务学习,该学习策略来源于SSD算法[2]中的MultiBox Loss思想。本实验使用的Inception结构如图3所示,其中4个分支操作分别为:①卷积核1?1的卷积,再使用3?3过滤器的平均池化;②卷积核1?1的卷积;③卷积核3?3的卷积层加一个卷积核1?1的卷积层;④两个卷积核3?3的卷积层(用更少参数代替5?5卷积核)加一个卷积核1?1的卷积层。使用Inception层将输入的特征图用不同尺寸的卷积核和池化组合分别进行卷积计算,最后将4种操作生成的特征图合并,从而达到丰富感受野种类的作用。3个Inception层最后可以得到7种尺寸不同的感受野,用于检测32?32、64?64及128?128大小的候選框。再连接一个3?3卷积层和1?1卷积层组成的卷积模块conv4,得到比上述尺寸更大的感受野,用于检测256?256大小的候选框,conv5结构及作用都与conv4相同,用于检测512?512大小的候选框。
候选框的生成沿用Faceboxes中的Anchor Density策略[13],对于1 024?1 024的输入图像,分别选取边长为32、64、128、256和512的候选框。对于像素较低(边长为32、64像素)的框,进行平移扩展。匹配框保留策略为:保留匹配框与目标框交并比相对较大的匹配框,也即重合率高的留下。设定一个阈值,规定保留比值超出阈值的匹配框,如0.45。
损失函数使用多任务损失(Multi-task Loss),利用Softmax Loss(分类概率)和Smooth L1 Loss(边框回归)对分类概率和边框回归(Bounding box regression)进行联合训练。Softmax Loss归为是否为人脸二分类问题。令x为分类类别,c为置信度,l为预测框位置,g为真实框位置,N为匹配框数量,Lconf是分类问题置信损失,Lloc是边框定位损失,α为超参数,多任务损失公式如式(2)所示。
2.3 训练参数
初始化参数使用He初始化方法,这是由于CReLU属于ReLU类的激活函数,ReLU类激活函数都不是关于0对称,He初始化[15]适用于此类激活函数。
梯度下降方法使用带有动量的随机梯度下降(SGD + Momentum),其中动量参数Momentum设置为0.9,权重衰减参数设置为0.000 5。
学习率调整函数使用文献[16]中提到的Gradual Warmup方法,训练迭代Epoch次数为400,前100个Epoch可使用较大的学习率加速梯度下降从而加快学习速率,设置初始学习率为0.001,Warmup Epoch为100,衰减函数使用衰减系数σ=1.000 1的指数衰减,即每次迭代的学习率为上一次学习率的1.000 1次方,由于学习率小于1,每次上述幂运算会产生衰减效果。
2.4 非極大值抑制
测试时使用NMS(非极大值抑制)消除重叠检测框,保留精度最高的。NMS的思想来源于Fast-RCNN[17],NMS的目的是去除重叠检测框,将不是重叠区域中与Ground-Truth的IoU最大的框都去除掉。由于模型得到的候选框是交并比大于阈值的所有框,会出现一张脸被多个候选框覆盖的情况,这时利用NMS,过滤多余选择框,保留一个局部最大值作为本次输出结果。
3 人脸检测实验
3.1 环境介绍
训练集使用WIDER FACE基准测试公开数据集的训练子集,其中包含12 880张带有标注的数据,并在AFW、PASCAL和FDDB 3个公开数据集上进行测试。本文实验环境配置如表2所示。
3.2 实验结果分析
采用随机抽样方法,分别将1 000张、3 000张图片及所有图片作为训练集进行训练并作对比实验,可以分析出该算法在少量训练样本时的表现。实验结果如表3所示。
由表3可知,在样本数量较少时,改进算法平均精度受到的影响没有Baseline的大,也即在训练集规模较小时识别效果不会很差,更适用于少量样本情况。
将改进算法与其它算法作对比,按照数据集规模从小到大顺序依次介绍在AFW数据集、PASCAL数据集和FDDB数据集的测试结果。
AFW数据集共包含205张图片,其中含有473张人脸,实验结果如表4所示。可以看出,改进算法识别准确率优于其它(Baseline、DPM[10]、Headhunter[18]、Structured Models[19]、TSM[20])算法,测试结果可视化展示如图4所示。
PASCAL数据集包含851张图片,共有1 335张人脸。图5展示了各类算法在PASCAL数据集上的PR曲线(Precision-Recall Curves),可以看出改进方法的PR曲线优于其它方法(Baseline、DPM[10]、Headhunter[18]、 Structred Models[19]、TSM[20]、OpenCV)。部分测试结果展示如图6所示。
FDDB数据集来源于Yahoo新闻,包含2 845张图片和5 171张标注人脸,其数据特点是低像素人脸较多,环境等因素较前两种数据集更复杂。与Baseline和其它几种算法(Headhunter[18]、DPM[10]、Structured Models[19]、Face++、Viola Jones[3])进行对比,结果如图7所示。结果显示,改进方法的ROC曲线整体优于其它几种算法,相比Baseline提高1.67个百分点,精确度达95%。部分测试结果如图8所示。
3.3 运行效率分析
性能提升会伴随着一定运行效率的损失,以图片像素较为平均的FDDB(350?450左右)为例,使用CPU处理效率由原来的14fps降至10fps,GPU效率也稍有损失,但仍可以保证在实时(21fps)标准。
4 结语
本文在FaceBoxes算法基础上提出更深层的骨干网络结构,在训练初始化参数及学习率衰减策略等方面也作出相应调整。在训练少量样本时,检测正确率较原算法提升较大,在数据集较大情况下也有小幅提升,在提升正确率的同时仍可保证检测速度,并在本文实验环境中实时运行。在用户数据集规模较小时,可以优先选用优化后的算法。
参考文献:
[1] 刘晨. 基于机器人视觉系统的人脸检测技术研究[J]. 电子设计工程, 2019, 27(5):115-118.
[2] 陈宝靖,张旭. 自动驾驶中的疲劳预测模型[J]. 中国新通信, 2017,19(16):53.
[3] 梁爽. 基于人脸检测识别技术的网上追逃系统设计与实现[D]. 上海:上海交通大学,2016.
[4] 管灵霞. 基于人脸识别的智慧工地考勤系统设计[D]. 芜湖:安徽工程大学, 2018.
[5] 惠婷. 智能门禁系统中人脸识别算法的研究[D]. 西安:西安工业大学, 2016.
[6] 董兰芳,张军挺. 基于FasterR-CNN的人脸检测方法[J]. 计算机系统应用, 2017,26(12):262-267.
[7] 方帅,李永毅,刘晓欣,等. 一种改进的基于SSD模型的多尺度人脸检测算法[J]. 信息技术与信息化, 2019,44(2):39-42.
[8] JONES M,VIOLA P. Fast multi-view face detection[C]. Proc. of Computer Vision and Pattern Recognition, 2003, 3(14): 2.
[9] YANG B, YAN J, LEI Z, et al. Aggregate channel features for multi-view face detection[C]. IEEE international joint conference on biometrics, 2014: 1-8.
[10] RANJAN R, PATEL V M, CHELLAPPA R. A deep pyramid deformable part model for face detection[C]. 2015 IEEE 7th international conference on biometrics theory, applications and systems (BTAS). IEEE, 2015: 1-8.
[11] ZHANG K, ZHANG Z, LI Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[12] YU J,JIANG Y,WANG Z,et al.Unitbox: an advanced object detection network[C]. Proceedings of the 24th ACM International Conference on Multimedia,2016: 516-520.
[13] ZHANG S, ZHU X, LEI Z, et al. Faceboxes: A CPU real-time face detector with high accuracy[C]. 2017 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2017: 1-9.
[14] HOWARD A G. Some improvements on deep convolutional neural network based image classification[DB/OL]. http://arsiv.org/abs/1312.5402,2013.
[15] HE K,ZHANG X,REN S,et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification[C]. Proceedings of the IEEE international conference on computer vision. 2015: 1026-1034.
[16] GOYAL P, DOLL?R P, GIRSHICK R, et al. Accurate, large minibatch sgd: Training imagenet in 1 hour[DB/OL]. https://arxiv.org/abs/1706.02677, 2017.
[17] GIRSHICK R. Fast R-CNN[C]. Proceedings of the IEEE International Conference on Computer Vision. 2015: 1440-1448.
[18] MATHIAS M, BENENSON R, PEDERSOLI M, et al. Face detection without bells and whistles[C]. European Conference on Computer Vision. Springer, 2014: 720-735.
[19] YAN J, ZHANG X, LEI Z, et al. Face detection by structural models[J]. Image and Vision Computing, 2014, 32(10): 790-799.
[20] ZHU X, RAMANAN D. Face detection, pose estimation, and landmark localization in the wild[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012: 2879-2886.
(責任编辑:孙 娟)
