一种基于图计算的网络实体行为评估算法设计
2020-11-20杨正权翟欣虎秦益飞
杨正权 翟欣虎 秦益飞
一.引言
图是一种揭示实体之间关系的语义网络,以符号形式对现实世界的事物及其相互关系进行形式化地描述。其基本组成单位“实体-关系-实体”三元组,以及实体及其相关属性值对,实体间通过关系相互联结构成网状的结构。现阶段图计算在各个领域都有广泛的应用,例如:信息检索/搜索,自然语言理解,问答系统,推荐系统,公安刑侦,社交类业务等。通过图的方式可以更好的展示实体之间的关系。
互联网上的各类数据以图的方式存储则可以更清晰直观的展现各个实体的行为以及实体间的关系。一种典型的场景是,当用户产生登录运营商服务器,访问互联网网站,下载文件等行为时,以及运营商内部一些资产服务器上的应用自动访问互联网用于软件更新,一些监控服务对其他资产服务器进行安全扫描等等。运营商都会记录下这些行为日志并进行相应的分析审计。通常的行为日志内容表述如下:
A用户 - 在某个时间 - 登录了 - a应用
B用户 - 在某个时间 - 访问了 - b网站
C用户 - 在某个时间 - 下载了 - c文件
A设备 - 在某个时间 - 连接了 - a服务
B应用 - 在某个时间 - 扫描了 - C设备
上述日志條目中,头尾两端的字段为网络实体(用户,设备,应用等),中间的字段为关系(登录,访问,下载,连接,扫描等),时间属性则作为实体或关系的属性值。
使用图的形式展现网络实体行为关系更为清晰直观,但存在的问题是当网络规模变大,网络中实体数量大幅增加时,例如实体数量达到数以千计万计时,如此庞大的数量以图的形式展现将变的无法适应,审计人员无法从千万个节点以及千万条边中找出需要关注最有价值的数据。所以采用图的形式展现,和传统数据表形式展现相比同样需要一套数据的评估排序筛选的方法,以找出最有价值的数据。
从庞大的图数据集中找出更有价值的数据用于呈现有一些方法,比较常见的一种是在图中为每个实体计算若干项评估指标,例如该实体的最后更新时间,该实体出现的次数,该实体关联关系数等。审计人员从若干项指标中人工选择需要关注的按数值大小按升序或降序排列,最终筛选出topN项实体及其关联关系。
进一步出现了上述方法的改进方法,在计算出每个实体的若干项评估指标的基础上,给每种指标赋一个经验权重值,再计算所有指标的加权平均值,审计人员直接按最终的加权平均值的数值大小升序或降序排列实体,同样最终列出topN项实体及其关联关系。
针对上述例举的现有方法中的第一种,最大的弊端是通过单个指标的排序并不能完整的评价某个实体的真实情况,并且这种单一维度的评价方法本质上和采用图表方式的存储并无本质区别,并不能很好发挥出图的关联关系特性。
针对上述例举的现有方法的改进方法,该方法虽然通过多个指标对实体做了多维度的综合评估,但其对每种指标权重的选择完全基于人工经验,而这种基于经验确定的权重值并不能保证其合理性,不合理的权重值会导致某几项指标在计算加权平均后完全失去了效果,影响最终的评估结果。
和上述两种现有方法相比较,本文设计的算法避免了通过单个指标对实体评估的单一性,同时在采用多个指标综合评估的基础上,改进了通过人工设置经验权重这种不太合理的方法,充分利用了图的特性,采用一种基于动态指标的评估方法,可以更加全面准确的对实体进行评估,在图中筛选并展现出更合理的网络实体及其关联关系。
二.网络实体行为评估算法设计
(一)评估算法总体流程设计
运营商记录的其网络中各种网络实体的各种操作记录的日志,提取抽象以后通常都可以用以下属性来描述:

上表中举例的行为记录表示:
用户Tom在2020.08.01 12:23:45下载了名叫Manual的pdf文件。
通常情况下,运营商服务器每时每刻都会记录下上述大量的行为日志,本设计算法收到这些日志后,按如下流程处理:
步骤①,获取指定时间范围内运营商服务器所产生的各种行为日志,时间范围长短不做限制。
步骤②,将日志中的“实体”以及“作用对象实体”作为顶点,“行为”作为边,采用图的方法存储,即按顶点的关键字分组。
步骤③,统计图中上述指定时间范围内的每个顶点的各项指标,即每一组中实体的相关指标,这些指标包括并不限于:顶点上报次数,度中心性,紧密中心性,中介中心性等。
步骤④,计算每个实体每种指标在上述时间范围内的数据中相应的概率密度(对于离散型随机变量即指其分布律),即该计算的概率密度数值只基于本次获取的这批数据得出。
步骤⑤,计算每个实体所有指标概率密度结果的数学期望,即求每个顶点所有指标的算术平均值。
步骤⑥,将每个实体按按数学期望大小排序,选出其topN实体及其关联关系作为最终结果展现给审计人员查看。
(二)实体行为图存储方式设计
图是由(V, E)来表示的,对于无向图来说,其中 V =(v0, v1, ... , vn),E = { (vi,vj) (0 <= i, j <= n且i 不等于j)},对于有向图,E = { < vi,vj > (0 <= i, j <= n且i 不等于j)}。V是顶点的集合,E是边的集合。图可以有两种典型的表示方法,一个是邻接矩阵,另一个是邻接链表,这两种方法都可以表示有向图和无向图。
邻接矩阵是用两个数组来表示一个图:一个一维数组用来存储每个顶点的信息;一个二维数组(即邻接矩阵)用来存储图中的边或弧信息。对于图G =(V, E)来说,邻接矩阵matrix是一个|V|*|V|的方阵,假设1 <= i, j <= |V|,如果matrix[i][j] == 0,则表示顶点i和顶点j之间没有边相连;反之,如果matrix[i][j] != 0,则表示表示顶点i和顶点j之间有边相连,且matrix[i][j]存储的值即为该边的权重。
邻接链表是一种不错的图存储结构,由于它在表示稀疏图的时候非常紧凑而成为通常的选择。对于图G =(V, E)来说,在其邻接链表表示中,每个结点对应一条链表,因此这个图里有V条链表。假设用一个V维的数组Adj来存储这V条链表,且Adj[i]表示的是结点i对应的链表,那么Adj[i]这条链表里存储的就是所有与节点i之间有边相连的结点,即与结点i相邻的结点。
在本算法适用场景中,采用有向图来描述网络实体的行为关系并采用邻接链表的方式存储数据更为合适。以用户Tom在2020.08.01 12:23:45下载了名叫Manual的pdf文件这条行为日志为例,将“Tom”和“Manual.pdf”这类关键字唯一的实体名作为图的顶点,此次的“下载”行为作为从顶点“Tom”到顶点“Manual.pdf”的有向边。即:
1. 采用实体名作为顶点唯一性的关键字;
2. 采用和有向边相邻的一组两个实体名作为边唯一性的联合关键字;
3. 给每个顶点设置特征数组:(上报次数,度中心性,紧密中心性,中介中心性,...)。
反复将行为日志抽象提取后加入图并计算顶点的属性值即构成了一个复杂的有向图。图上的每个顶点应该都有1-N条相连接的边,同理也就拥有1-N个相邻的顶点,即采用邻接链表的方式按顶点的关键字进行了分组操作。
(三)实体行为评估算法设计
评估算法主要涉及对图中顶点相关特征的计算,具体如下:
1. 顶点上报次数:当行为日志中的实体名在图的顶点集V中已经存在,则该顶点的上报次数加1,统計一段时间内每个顶点的上报次数。
2. 度中心性:该特征是计算顶点上传入和传出关系的数量,可以用于在图中查找“热”(popular)的节点。在本算法适用的场景中,即统计一段时间内每个顶点的邻接顶点数。
3. 紧密中心性:该特性是一种检测节点通过子图传播信息有效性的方法。该方法度量是节点与所有其他节点的距离近的程度。在所有节点对的最短路径计算的基础上,紧密中心性算法计算一个节点到所有其他节点的距离之和。然后将得到的和求倒数,以确定该节点的紧密性中心性得分。节点的紧密中心性用以下的公式来计算:
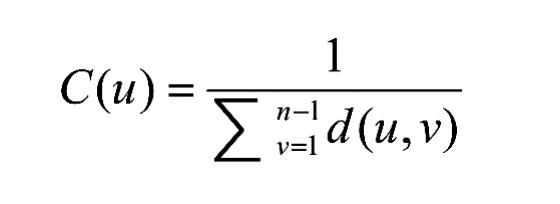
其中,u是一个节点,n是图中的节点数,d(u,v)是另一个节点V和U之间的最短路径距离。
更常见的是将该分数归一化,使该得分代表最短路径的平均长度,而不是它们的总和。这种调整允许比较不同大小图节点的紧密性中心性。
归一化后的紧密中心性公式如下:

在本算法适用场景中,即筛选出一段时间范围内的所有顶点和边,在此基础上计算每个顶点的紧密中心度。
4. 中介中心性:该特征是一种检测节点对图中信息或资源流的影响程度的方法。它通常用于查找充当从图的一部分到另一部分的桥梁型节点。该算法首先计算连接图中每对节点之间的最短(权重)路径。每个节点都会根据这些通过该节点的最短路径的数量得到一个分数。经过节点的最短路径越多,该节点的得分越高。
中介中心性是将最短路径通过如下公式计算后累加的结果:

在公式中u是一个节点,p是节点s和t之间最短路径的数量,p(u)是s和t之间通过u的最短路径的数量。
同理在本算法适用场景中,即筛选出一段时间范围内的所有顶点和边,在此基础上计算每个顶点的中介中心度。
计算出一段时间范围内图中每个顶点的上述4种或更多特征的特征数组后,将该批数据中出现的不重复的顶点对应的其中一种特征作为离散型随机变量,将该特征的数值作为随机变量的出现次数,计算这批数据中不重复的顶点的所有特征相应的分布律,即每个顶点对应特征在所有顶点对应特征中的占比。举例如下:选取了一段时间范围的行为日志按图存储后有3个顶点,计算这3个顶点对应的特征数组分别为(20,3,0.3,4),(4,1,1,2),(12,2,0.6,1.4),那么对于3个顶点特征分布律数组为:

计算每个顶点特征分布律数组中所有数值的数学期望,最终结果即为每个顶点的评估值,按评估值大小进行排序,选出topN对应的顶点即最终被筛选出的实体及其对应的行为关系。
三.网络实体行为评估算法验证
(一)验证数据建立
Apache JMeter是Apache组织开发的基于Java的压力测试工具,用于对软件做压力测试,JMeter 可用于模拟在服务器、网络或者其他对象上附加高负载以测试其提供服务的受压能力,或者分析其提供的服务在不同负载条件下的总性能情况。
验证方法基于JMeter搭建,使用一台服务器作为代理网关,可以记录下接入用户的上网日志,另一台PC终端上运行JMeter,用于模拟多用户的互联网访问行为。设置JMeter模拟50名不同的用户,随机访问100个预选出的互联网网站,为每位用户设置不同的访问网站数量阈值以及访问的频率阈值,从网关服务器收集一天内所有访问请求记录约80万条作为待检测样本。同时记录下JMeter针对每个用户访问量及访问频率的设置,如下:
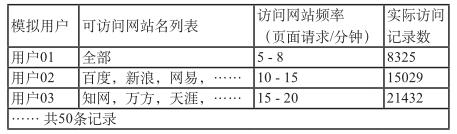
将上述数据采用本文设计的图方式存储并分析评估每个模拟用户的行为,得到每个用户最终的评估值的排名,同时也给出每个特性单独的排名,如下:

(二)验证方法及结果分析
对于无监督的预测结果业界并没有评估结果“好坏”的统一标准,本验证通过将评估结果和互联网领域比较常用及容易理解的PageRank热度排名的方式做对比,计算50名模拟用户的排名和PageRank排名两数组的相关系数,系数约接近于1表示评估的排名和PageRank排名越接近。验证结果如下:

结果表明,本算法评估的结果和PageRank排名最接近,可以认为是通常情况下比较认可的结果。
四.结束语
因为本文所描述的方法通过多个维度对网络实体进行评估,相比于人工选择单一维度的评估,评估结果更全面。
同时本文所述方法基于预选出的实际时间范围的数据,对网络实体动态计算多个维度权重的相对比例而不是固定不变的比例值,评估结果的准确性更高。
作者单位:江苏易安联网络技术有限公司
