基于Lucene 的中文是非问答系统的设计与实现*
2020-11-20罗东霞卿粼波吴晓红
罗东霞,卿粼波,吴晓红
(四川大学 电子信息学院,四川 成都 610065)
0 引言
随着人工智能技术的飞速发展,传统搜索引擎已不能满足用户需求,自动问答系统逐渐成为信息检索领域的研究热点,并具有广泛应用前景[1]。自动问答系统指允许用户以自然语言的形式描述问句,并将简洁答案返回给用户的一种信息检索系统[2]。
近年来,自动问答系统相关的研究和应用十分广泛。2011年,IBM 公司的深度问答系统首次将自然语言处理与深度学习结合起来,使得众多机构和企业纷纷效仿。2013年3月,京东上线京东JIMI 客服机器人,提供客户常规咨询服务;2016年10月,百度推出百度医疗大脑,实现健康在线咨询[3]。但目前关于中文自动问答系统的研究多是围绕特指问句,其开放性的回答方式不适用于是非问句的二值答案。例如,对 JIMI 提问:“京东自营满 88 包邮对吗?”,JIMI 的答案是京东自营商品包邮的详细说明,而非是非问句要求的“对”或“不对”的二值答案。中文是非问答系统的设计与实现,能够弥补目前中文自动问答仅能作答特指问句的不足,帮助用户快速获取简洁的答案,对自动问答系统的研究和应用有着极其重要的意义。
本文利用Lucene 设计并实现一种中文是非问答系统,主要工作包括:(1)引入句法成分权重和命名实体权重,改进 TextRank 算法[4-5],提出一种问句核心词提取方法;(2)针对 MySQL、Neo4j 和本地新闻文件中的多源数据,提出一种多源数据融合索引创建方法,减少索引创建耗时;(3)查询索引并对索引结果判决,获得是非问句的二值答案。
1 是非问答系统设计
本系统主要包括三个模块:多源数据融合创建索引、问句预处理和答案整理。其中,问句预处理包括问句分词、问句关键词组 Kw[T1,T2,…,Tn](Ti(i=1…n)表示关键词)与核心词 Cw的提取;多源数据融合创建索引对本地数据进行文档融合,统一创建索引;答案整理将索引结果 LR 与 Cw和 Kw进行匹配,匹配成功则判定为肯定答案,反之为否定答案。系统框图如图1 所示。
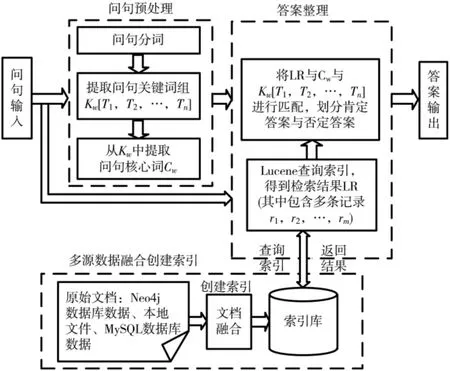
图1 是非问答系统框图
2 问句预处理
问句预处理指对问句的理解和分析,其任务是根据问句确定检索和答案提取策略[6]。具体到本系统,问句预处理包括问句分词、问句关键词组提取和问句核心词提取。
2.1 问句预处理流程
中文问句分词指将构成问句的汉字序列切分成一个一个单独的词的过程[7]。关键词指体现个人需求的词汇,多个关键词组成关键词组Kw[T1,T2,…,Tn]。问句核心词 Cw指 Kw中关键度最高的词,其高低由提取关键词时的词语得分Ws、词语句法成分权重 Wc和命名实体权重 We共同决定。HanLP 是由一系列模型与算法组成的自然语言处理工具包,适用于 Java 生产环境[8],本文采用 HanLP 进行问句分词,分词结果包含词语和词性。TextRank 算法是一种基于图的排序算法,不需要提前训练,本文采用该算法提取问句关键词。问句预处理流程如图2所示。
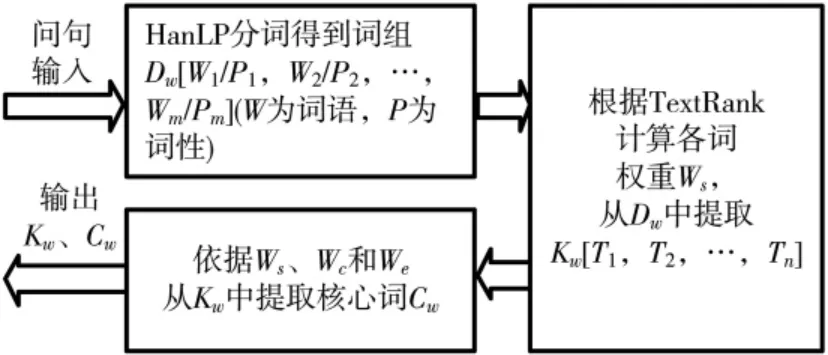
图2 问句预处理流程图
2.2 改进 TextRank 的核心词提取方法
核心词指关键词组中关键度最高的词,不同句法结构关键词组 Kw大小不同。表 1 中是两种不同的句型结构及其对应的关键词组的大小。其中,“n”指名词,包括人名、地名和专用名词等;“v”指动词,“np”是名词性短语,“u”是助词,“y”是语气词。
词语在句中充当的成分不同,对句子有效信息的贡献度也不同[9-10]。利用依存句法分析,将词语的句法成分权重 Wc加入关键度计算中。表 1 两例句的依存句法分析如图 3 所示,其中“nr”指人名,“b”指区别词,“ns”指地名,“w”指标点符号,“u”指助词。在非省略句中,句子的主谓宾对句子贡献较大,但谓语动词一般不作为句子关键词,主语和宾语多数情况下具有相同重要性。句末语气词和标点对句子内容贡献较小,暂不考虑两者的句法成分权重。结构 1 例句主干“特朗普(主语)+是(谓语)+总统(宾)”的 Wc大小为:

表1 句型结构与关键词组大小

图3 例句依存句法分析图
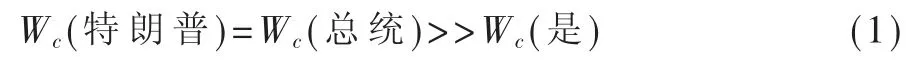
“现任”和“美国”作定语分别从性质和范围修饰定中短语中心语“总统”,Wc依次为:
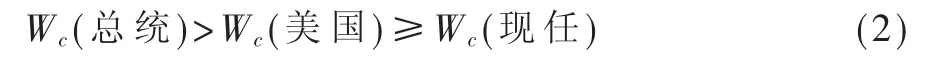
最终结构1 例句中各词的Wc大小依次为:
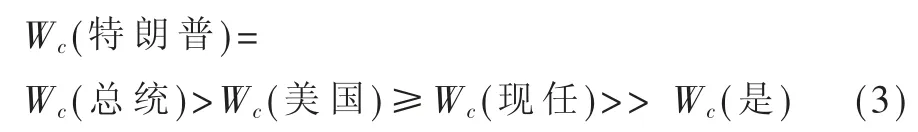
与结构 1 例句不同,结构 2 例句中“特朗普”从领属修饰 “女儿”,表示“女儿”从属于“特朗普”,则:

助词作辅助之用,赋予其较小的 Wc,结构 2 例句中各词 Wc为:
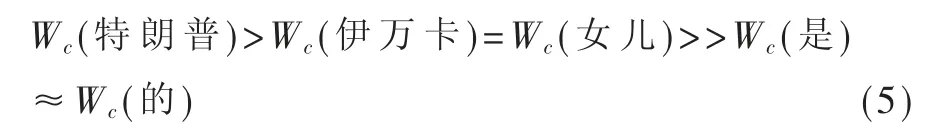
考虑数据源中存在较多命名实体信息,引入命名实体权重 We(0≤We<1),对词语关键度做到更好的区分度。对于任意一个词 Ti,若该词是数据库中的命名实体, 则为词分配一个命名实体权重We(Ti),反之将该词的实体权重置为零。对于是非问句关键词组 Kw中任意一个词 Ti,其关键度 W(Ti)由 TextRank关键词得分 Ws(Ti)、句法成分权重 Wc(Ti)和命名实体权重We(Ti)三部分组成,具体表现为:
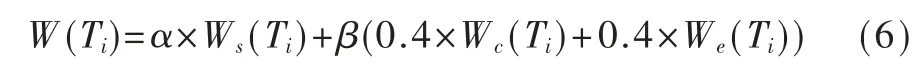
经实验统计,当 α=0.4,β=0.6 时,核心词提取正确率最高,因此令 α=0.4,β=0.6。Ws(Ti)的计算形式为[10]:
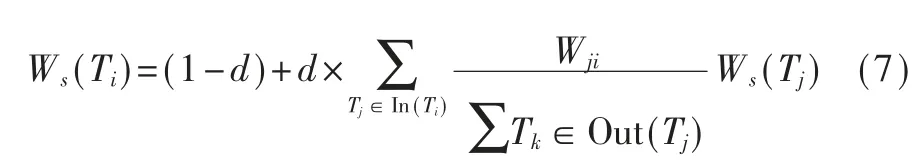
其中 d 为阻尼系数(一般取值 0.85),Wji指图中任两点(任意两相连词语)Ti、Tj相连边的权重,In(Tj)为 指向点 Tj的点集合,Out(Ti)为点 Ti指向的点集合。是非问句的核心词 Cw为关键度 W(Ti)最高的词语,即:

3 多源数据融合创建索引与答案整理
多源数据融合创建索引将Neo4j 数据库中节点与关系的信息、本地新闻文件信息和MySQL 数据库中存储的标准问答对信息进行文档融合,降低数据多样性带来的复杂度,减少索引创建的时间。答案整理将查询索引的结果LR 与问句预处理输出的关键词组 Kw和核心词Cw进行匹配判决,最终得到符合是非问句答语标准的二值答案。
3.1 Lucene 全文检索系统模型
全文检索指计算机索引程序通过扫描文章的每一个词,对每个词建立一个索引,指明该词在文章中出现的次数和位置。当用户进行查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。Lucene 是一款高性能的Java 全文检索工具包,它提供了完整的查询引擎、索引引擎和部分文本分析引擎[11]。
3.2 多源数据文档融合创建索引
文档(Document)是 Lucene 全文检索中索引创建和查询的基本单位, 一篇文档包含不同类型的信息,分别存储在不同的域(Field)里,不同的文档可以有不同的域,每个文档有独立的编号。对多源数据进行文档融合能够降低数据多样性带来的复杂度,为索引创建提供更便利省时的方法。文档融合流程如图 4 所示,主要处理如下:
(1)使用Cypher 图数据库查询语言对 Neo4j 进行节点查询,为每个节点创建一个Document 对象,将查询得到的属性添加到Document 对象中;
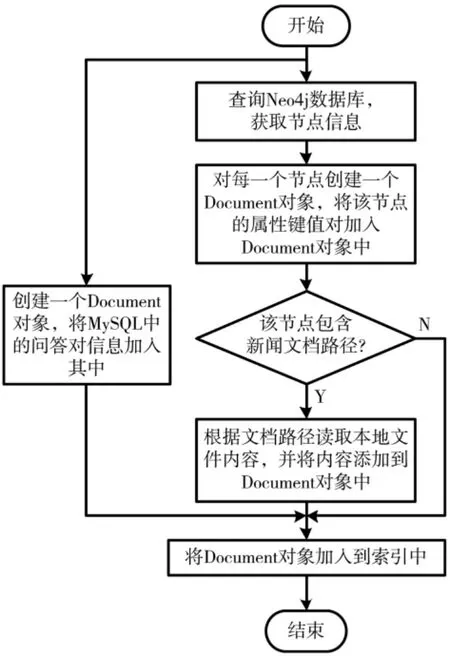
图4 文档融合流程图
(2)若该节点包含新闻文件信息,获取节点中存储的新闻文件的路径,通过I/O 操作从本地文件系统中读取文件内容,并将该内容添加至Document对象;
(3)通过 SQL 语句查询 MySQL 中的标准问答对信息,并将该信息添加到一个新的Document 对象中。
融合后的文档对象如图5 所示,其中Document 1至Document k 为Neo4j 数据库中实体和新闻文件的文档对象,域“fullText”为实体节点的所有属性键值数据,域“newsText”为节点相关新闻文件数据;Document k+1 是MySQL 数据库中的标准问答对信息,域中存储每一对问题-答案信息。

图5 文档对象
Lucene 自带的中文分词器中,SmartChineseAnalyzer对中文支持较好,使用简便[12],分词效果能满足系统需求,故采用 SmartChineseAnalyzer 分析文档。分析文档得到的语汇单元经IndexWriter 对象加入索引库,至此多源数据融合创建索引完成。
3.3 答案整理
答案整理包括索引查询和答案判决。根据问句内容查询索引,返回检索结果 LR(r1,r2,…,rm)。LR是命中文档的详细信息, 而非是非问句的具体答案,需对检索结果进行答案判决,输出肯定或否定的答案。答案判决首先遍历 LR,判断检索记录 ri是否为Cw指向的实体,若是则进行下一步判断,否则取下一条ri+1继续进行此步判断,直到遍历结束;判断该条记录下是否包含 Kw[T1,T2,…,Tn]中所有词汇,且词汇顺序与 Kw[T1,T2,…,Tn]中关键词顺序一致,若是则判定为肯定答案,否则为否定答案。
4 实验结果与分析
为验证本系统的可行性,根据上述设计方案实现了一个中文是非问答系统。实验数据来源于本地Neo4j 数据库、MySQL 数据库和本地新闻文件。Neo4j数据库中包括人物、组织和事件等共计12 451 个实体信息,人物之间的亲属关系和组织与领导人关系等共 25 319 条。MySQL 数据库中包含 1 000 对是非问句及对应正确答案。本地文件中存储149 篇PDF格式的实体相关新闻文件。构建前文结构 1 和结构2 类型的问句共1 000 条作为核心词提取和系统功能的测试数据, 人工标注测试问句的核心词和问题的正确答案。为了定量分析系统效果,实验用准确率进行核心词提取和系统整体功能的分析。准确率定义如下:

式中,P 为准确率,Pnum为正确提取核心词的问句数量或正确得到答案的问句数量,Rnum表示所有测试问句数量。
(1)实验1:核心词提取对比分析。使用1 000条测试数据,对改进TextRank 的核心词提取方法和传统TextRank 提取的方法进行对比分析,对比结果表明改进TextRank 的核心词提取方法能够较为准确地实现问句核心词的提取,提取准确率有显著提升。对比结果如表2 所示。
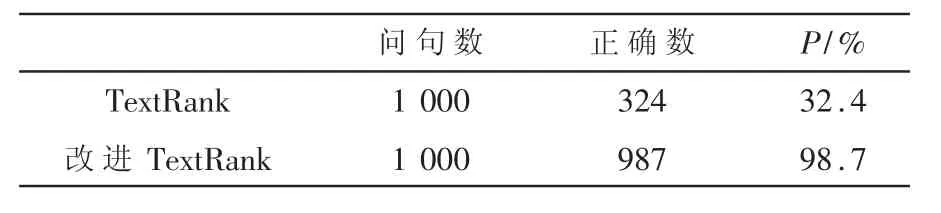
表2 核心词提取对比
(2)实验 2:多源数据创建索引对比分析。对本地多源数据进行文档融合,将融合创建索引、直接创建索引以及三种数据源分别创建索引耗时作统计分析,结果表明文档融合能有效减少创建索引的时间,对降低多源数据索引创建复杂度有一定作用。时间对比结果如表 3 所示。

表3 创建索引时间对比
(3)实验3:系统整体功能测试与分析。针对1 000条测试数据,结合核心词提取准确率和系统输出准确率对系统整体功能进行评估,测试结果如表4 所示。表 4 显示,在 1 000 条测试数据上,系统正确回答数为 954,正确率为 95.4%。其中,当核心词提取正确时,系统回答正确率为95.6%,而核心词提取出错时,问答的准确率仅有76.9%,核心词提取的正确与否对系统回答的准确性有较大影响。
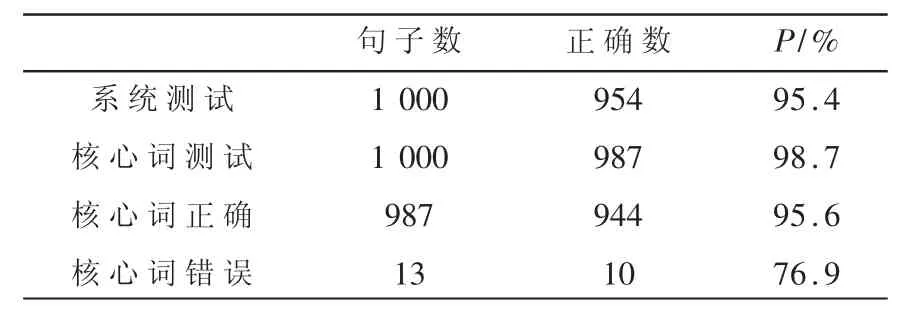
表4 系统测试结果
5 结论
本文设计并实现了基于Lucene 的中文是非问答系统,基于TextRank 算法引入句法成分权重和命名实体权重实现是非问句核心词提取,捕获是非问句的关键要素。对分类存储的多源数据进行文档融合,降低数据多样性带来的复杂度。测试证明,改进TextRank 算法能有效提取问句核心词,多源数据融合创建索引比直接创建耗时更少,且系统在回答是非问题时不会出现答非所问的情况,回答结果较为满意。
