藏药药理命名实体识别*
2020-11-18何家欢刘勇国
何家欢 刘勇国 蒋 羽 张 云
(电子科技大学信息与软件工程学院 成都 610054)
张春梅 李东晓
(四川省中医药科学院 成都 610041)
张 艺
(成都中医药大学 成都 611137)
1 引言
1.1 藏医药研究情况
藏医学是一门古老科学,已有数千年历史,是4大传统医学体系之一,是通过不断的实践和研究逐渐形成的集人体生理、病理、诊断、治疗、方剂等为一体的民族医药学[1]。近年来我国藏医药研究的科技文献逐年递增[2]。藏医药科技文献的增长有利于发现藏医药领域研究热点和进展,明确藏医药研究方向和思路,促进藏医药的研究和发展。现有藏医药科技文献研究以手工方式或运用统计软件分析为主。扎西道知等[3]通过查询藏医药文献并整理藏药不良反应描述,为藏医药不良反应研究提供文献依据。高路等[2]使用软件CiteSpace对文献数据进行统计分析,发现藏医药研究进入稳定发展期。李琪等[4]应用中医传承辅助平台[5]对藏药治疗肝炎方剂进行药物频次统计和药物关联度分析,运用聚类分析提取核心组合。手工方式分析藏医药文献存在样本小、主观性强、周期长和人力成本高的问题,应用商业软件可分析藏医药概念(治法、方剂和药物等)出现频率和共现关系,但无法分析藏医药概念深层语义。药物药理用于阐明药物对机体的作用和原理,以及药物在体内吸收、分布、生物转化和排泄等过程,药物效应和血药浓度随时间消长的规律[6]。药物药理研究能够了解药物治疗疾病原理,从而针对疾病研发新药物,针对药物寻找新的适应症,药理研究在临床中具有重要价值[7]。
1.2 生物医学领域文献挖掘研究情况
近年来文献挖掘在生物医学研究领域逐步开展,Murugesan等[8]提出BCC-NER方法,使用双向条件随机场对BioCreative II语料库的基因和蛋白质进行识别,F1值达86.95%。何林娜等[9]提出基于特征耦合泛化(Feature Coupling Generalization, FCG)的半监督学习方法,结合条件随机场(Conditional Random Fields, CRF)自动识别1979-2009年PubMed生物医学文献的药物名,F1值达76.73%。王振华等[10]通过研究藏药镰形棘豆科技文献117篇,发现研究工作集中于化学成分、药理作用方面。仁青东主等[11]研究藏药复方治疗慢性萎缩性胃炎方剂相关文献,统计药物频次并分析药物功效。通过文献挖掘方法分析研究主题及其演变趋势,总结研究内容并提取关键信息,能高效挖掘海量文献数据,显著降低手工分析强度,提高科技文献分析效率。文献挖掘技术可多方面辅助研究人员开展科研工作,例如文本分类可自动对文本进行筛选,缩小待研究的文本范围;命名实体识别可从生物医学文献中抽取所需特定事实信息,如疾病、药物、基因和蛋白等有特定意义的生物实体;自动摘要可从海量文献中自动进行文本总结并生成文档文摘。
1.3 研究背景
目前药理研究通常通过临床实验提取药物化学成分,研究药物活性成分以确定药物药理,研究过程周期长且成本高[12]。从生物医学研究领域文献中提取药物药理,可为新药研发实验提供方向、辅助决策,减少实验周期时间并提高研究效率。当前生物医学研究领域文献的实体识别相关研究都针对英文文献,未开展针对中文文献实体识别研究。中文命名实体识别相较于英文命名实体识别更加困难,中文词与词之间没有类似英文单词之间明显的边界。本研究构建中文藏医药药理实体识别语料库,设计基于BiLSTM-CRF深度学习模型的藏药药理命名实体识别方法,采用文献挖掘的信息抽取技术从科技文献提取并识别藏药药理,协助藏医药研究人员开展藏药药理研究,为藏医药文献研究提供新途径。
2 语料库与方法
2.1 药理实体识别流程(图1)

图1 药理实体识别流程
文献获取指获得藏药药理相关研究文献;语料库指去除文献中噪声信息(如页码、分类号、格式符等),保留文献正文文本并对文本句子中的药理实体进行标注;文献特征提取指将文献文本从高维空间向低维空间投影降维,以保存并表征文献内容的关键信息[13];药理实体提取指使用提取的特征向量计算每个字最大概率标签,以实现药理实体提取。
2.2 文献获取
通过中国知网以“藏医药”和“藏药”为关键字检索2014-2018年《中草药》、《中国中药杂志》、《中医杂志》、《世界科学技术-中医药现代化》、《中成药》、《中国民族医药杂志》、《中华中医药杂志》等期刊479篇文献,以文献中是否包含藏药药理为筛选标准,筛选获得藏医药药理相关文献155篇。
2.3 语料库构建
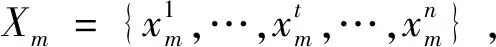

图2 文本标记实例

表1 藏医药文献语料库
2.4 文献特征提取
2.4.1 概述 药理实体识别的文献特征指药理实体出现于文献句子的位置,构成药理实体的特殊字等多种特征。文献特征提取能自动提取文本特征,将特征表示为向量形式。本研究将藏药药理命名实体识别视为序列标签预测问题,预测语料库中字{B,I,O}标签以检测藏药药理实体。通过文献提取藏药药理,探索相同或相似药理药物,为新药研发提供实验思路,缩短实验周期[15]。传统序列标注预测方法通过统计方法如条件随机场进行等,需人工定义大量特征且泛化能力不足[16]。深度学习方法模拟人脑进行非线性分析学习,无需人工干预可自动完成藏医药文本特征学习。本研究引入BiLSTM-CRF深度学习模型实现藏医药文献的药文献的药理实体识别,见图3。模型包括:输入层、嵌入层、特征提取层、输出层和CRF层。
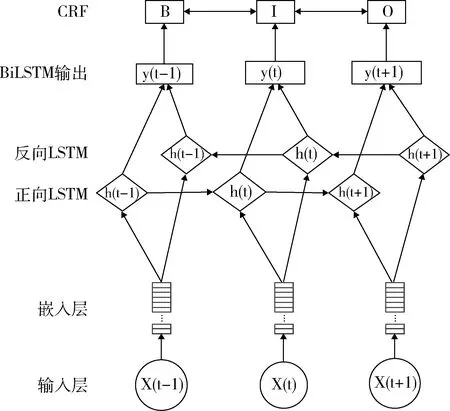
图3 BiLSTM-CRF深度学习模型


表2 字向量实例
2.4.4 特征提取层 长短期记忆网络(Long Short Term Memory,LSTM)结构[17]含有1个或多个具备可遗忘和记忆功能的单元组成,可实现长距离文本信息利用,其结构,见图4。

图4 LSTM单元结构
LSTM结构核心是记忆单元,通过输入门i,遗忘门f,输出门o控制记忆单元每时刻输出,计算过程如式(1)-(5)所示:
(1)
(2)
(3)
(4)
ht=ot·φ(ct)
(5)
其中Wuv表示训练权重矩阵,u∈(i,f,c,o),v∈(h,x),σ和φ分别表示sigmoid和tanh非线性激活函数[18]。该门控机制能对记忆单元信息进行处理,确定输入文本信息遗忘或保留,以解决长距离的信息处理问题。如语句“含有诃子的方剂的主治疾病多与热毒、疼痛相关,因此其高频次药物也多具有清热解毒、活血通络、理气止痛作用,其中以____、理气药使用最多”,需对横线词进行预测,LSTM单元通过学习,记忆单元保留“诃子”、“热毒”等强相关信息,遗忘门遗忘“的”、“方剂”等弱相关信息,输出门将最后所获信息输出,预测横线词为“清热药”。

2.5 药理实体识别

(6)
2.5.2 条件随机场层 为藏药药理实体标签序列添加约束规则,模型训练过程中CRF层通过转移矩阵Aij学习藏药实体标签间约束规则,如标签B后应为标签I,因为药理实体通常由多词组成;标签O后面不可能是标签I,因为实体开始标签应为B标签。通过上述约束可避免生成错误标签序列。给定语句Xm和藏药药理实体标签序列z,所预测标签序列得分如式(7)所示:
(7)
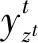
3 训练
3.1 目标函数
给定语句Xm获得可能的药理实体标签序列Z(Xm),则药理实体标签序列z概率为:
(8)
最终获得预测输出序列zn*是最大概率藏药药理实体标签序列,如式(9)所示:
zn*=argmaxs(Xm,z,θ),z∈Z(Xm)
(9)
利用Adam[20]算法训练BiLSTM-CRF深度学习模型,更新参数并最大化正确标签序列概率。将测试文本输入模型,获取最大概率藏药药理标签序列,以实现藏医药文献语料标注并提取藏药药理实体。
3.2 Dropout策略
过拟合现象是神经网络模型的常见问题,如藏医药文献语料多处出现藏药药理实体“清热”,其对应标签分别为“B”和“I”,过拟合导致后续藏医药文献语料出现“清”字时被标记为实体开始,错误识别药理实体。Dropout策略使神经网络节点随机失活,避免训练模型过度依赖特定特征,具备正则化作用[21]。本研究为避免模型过拟合,在嵌入层与特征提取层间、特征提取层和CRF层间引入Dropout策略。
3.3 参数设置
嵌入层中不同维度的词向量表达藏医药文献中不同语义信息,故序列标签预测问题中词向量维度影响学习模型的预测性能[22]。本研究采用Word2vec模型[23]和Cw2vec模型[24]训练词向量。以475篇藏医药文献为训练数据,训练50维、100维、200维和300维藏医药文献词向量。Word2vec模型采用词上下文训练,Cw2vec模型采用词笔画训练。同时,在[-0.25.0.25]区间随机采样,对藏医药文献每个词生成随机向量对比。Word2vec模型训练参数参照文献[23]设置,Cw2vec模型训练参数参照文献[24]设置。BiLSTM-CRF模型其他参数,见表3。

表3 BiLSTM-CRF模型参数
4 实验结果
4.1 评价标准
药理实体是否正确识别主要依据实体边界是否正确。本研究采用精确率(P)、召回率(R)、F1测度值(F1)评价指标描述模型性能,如式(10)-(12)所示:
P=识别正确的药理数/识别出的药理数
(10)
R=识别正确的药理数/样本的药理数
(11)
F1=(2×P×R)/(P+R)
(12)
精确率(P)表示所识别藏药药理实体中正确识别的藏药药理实体占比;召回率(R)表示语料库中藏药药理实体正确识别占比;F1测度(F1)表示精确率和召回率的综合结果,判断识别模型能否准确、全面识别藏药药理实体。
4.2 结果分析
随机向量、Word2vec和Cw2vec向量模型在不同维度下的藏药药理识别结果,见表4。可知相同向量模型条件下50维向量时藏药药理实体识别效果最好。相同维度条件下Word2vec和Cw2vec模型识别效果优于随机向量,说明Word2vec和Cw2vec模型能够有效获取藏医药文献的文本语义信息。Cw2vec模型50维、200维和300维向量条件下藏药药理实体识别效果优于Word2vec模型。Word2vec模型仅使用藏医药文献的上下文信息,没有考虑单词内部特征;而Cw2vec模型使用藏医药文献单词的笔画特征训练模型,考虑上下文信息同时考虑单词内部语义信息,更适合训练中文词向量,其在语义相似性方面也被证实比Word2vec具有更好效果[24]。不同模型F1测度值,见图5。实验模型随着维度变化的召回率和精确率变化趋势,见图6。可见向量维度降低导致模型F1测度值增加,模型召回率随着维度降低而增加,F1测度值和召回率成正比。
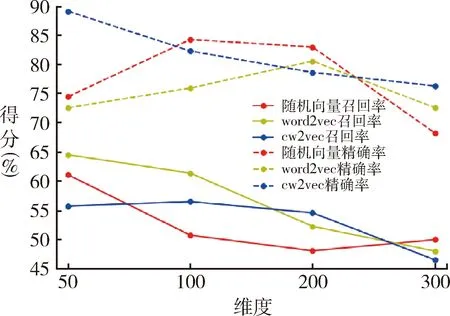
图6 模型精确度、召回率

表4 不同维度词向量性能对比

图5 实验模型F1测度值
4.3 实例分析
模型对文本序列进行标注的实例,见图7。模型正确识别句子1中药理实体“开窍通络”、“镇静安神”、“解痉止痛”。识别句子2中药理实体“清血热”、“清浊”,但真实药理实体为“清血热”、“分清血液清浊”。实体“分清血液清浊”错误识别原因在于训练语料中出现大量动词-宾语结构的词标记为药理实体,如“清热”、“抗氧化”等,导致模型以动词-宾语结构短语为药理实体,造成含有动宾结构的长药理实体分割,产生识别错误。此错误因实体分布不平衡引发,即语料库中动宾短语药理实体占比过大,后续研究中尝试构建长短药理实体均匀分布语料库训练模型。

图7 药理识别实例
5 结语
针对现有藏医药科技文献研究过程中手工方式和统计软件应用方面存在的不足,本研究提出基于BiLSTM-CRF深度学习模型的藏药药理命名实体识别方法,通过科技文献自动提取并识别藏药药理。模型采用少量标注数据训练并使用未标记的藏医药文献训练字向量,能提取文献的藏药药理实体,为藏医药研究人员开展藏医药药理研究提供新途径。
