联合实体识别与关系预测的知识库问答
2020-11-17刘月峰张晨荣
刘月峰,张晨荣
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
0 引 言
近年来,随着知识库的快速发展,基于知识库的问答系统(question answering over knowledge bases,KB-QA)成为了自然语言处理(natural language processing,NLP)任务中研究热点。Bordes等[1]提出一种单一事实的简单问题的知识库问答的数据集。基于知识库的简单问答任务一点也不简单,研究人员通过采用复杂的神经网络(neural networks,NN)结构[2-8](如注意力机制[2,4,7,8]、残差学习[6]等)解决该问题,其准确率也未能达到理想效果。Ture等[9]并没有采用复杂的NN结构,他们根据问句的语言结构将其分解成两种机器学习子问题:实体识别和关系预测,并应用双向门控循环单元(bi-gated recurrent units,BiGRUs)分别对实体识别和关系预测进行学习,相比之前的复杂的NN结构而言,他们的方法显著提升了知识库问答的准确率;Mohammed等[10]进一步探索了使用神经网络或不使用神经网络的基线模型。然而Ture等[9]和Mohammed等[10]通过将简单知识库问答任务分解为实体检测和关系预测两种不同的任务进行独立训练,忽略了问题中的实体和关系之间的联系,降低了关系预测的准确度,从而降低了问答的准确率。针对以上问题,本文采用联合训练的方法,同时进行实体识别和关系预测的学习,使用多个级别(字符和词级别)的文本特征作为联合模型的输入,引入双向长短时记忆网络(bi-direction long short-term memory,BiLSTM)进行问句的特征学习,随后采用条件随机场(condition random filed,CRF)进行实体识别,利用多维度特征(文本特征和问句的标签嵌入(label embedding)特征)进行关系预测。相比独立训练的知识库问答方法,本文模型提升了问答准确率,加快了训练的效率。
1 简单知识库问答系统总体框架
简单KB-QA任务的目标是给定一句自然语言问题Q,系统可以返回答案(subject、predicate、object)。本文提出的方案框架基本流程如图1所示,该方案包含3个模块:实体识别和关系预测的联合训练模型、实体链接、答案查找。本文首先利用多级别的文本信息作为联合学习模型的输入,即使用基于卷积神经网络(convolutional neural network,CNN)的字符级别(Char-level)的表示与预训练Glove词嵌入[11]的表示进行拼接得到词的最终表示,其次将词的最终表示输入联合学习模型中,模型经过训练之后同时识别实体和预测关系,最终以结构化的方式进行输出,例如图中“Where was Oliver duff born ”经过训练之后输出的结构化表示:{subtext:Oliver duff,relation:place_of_birth}。为了能够将结构化表示中的实体(subtext)快速地链接到KBs最相关的真实节点中,我们引入倒排索引Ie,即将KBs中所有实体的所有n-grams(n∈{∞,3,2,1})映射为别名文本,且每一个n-gram都具有TF-IDF权值,然后将subtext的n-grams通过查询Ie构建候选实体集C;对于答案的查找,我们在候选实体集上建立单跳路径索引集合Ir,根据结构化文本中的关系(relation)匹配路径索引Ir的路径,若匹配相同,则TF-IDF得分最高的候选实体对应的尾实体即为问句中的答案。

图1 基于联合学习的简单知识库问答框架
1.1 联合实体识别和关系预测的模型
本节我们将详细介绍联合实体识别和关系预测联合学习的神经网络模型。该模型能够同时识别实体和预测问句所属的关系,通过利用实体类型的标签以及实体与关系之间的对应关系增强关系预测的性能,而且能够同时进行两项任务,得到最终结构化的表示。基本的模型结构如图2所示,它包含:①输入层(即嵌入层)、②BiLSTM层、③CRF层、④全连接层。图2所展示的是SimpleQuestions数据集中一个案例。模型的输入是tokens(即问句中单词)序列,它们被表示成多级别向量(即词级别的向量和字符级别的向量的组合),我们利用了多个维度的文本信息。BiLSTM层用来抽取相关文本的更复杂的表示。CRF层和全连接层能够产生两个任务的输出,最终将输出结构化表示的结果。
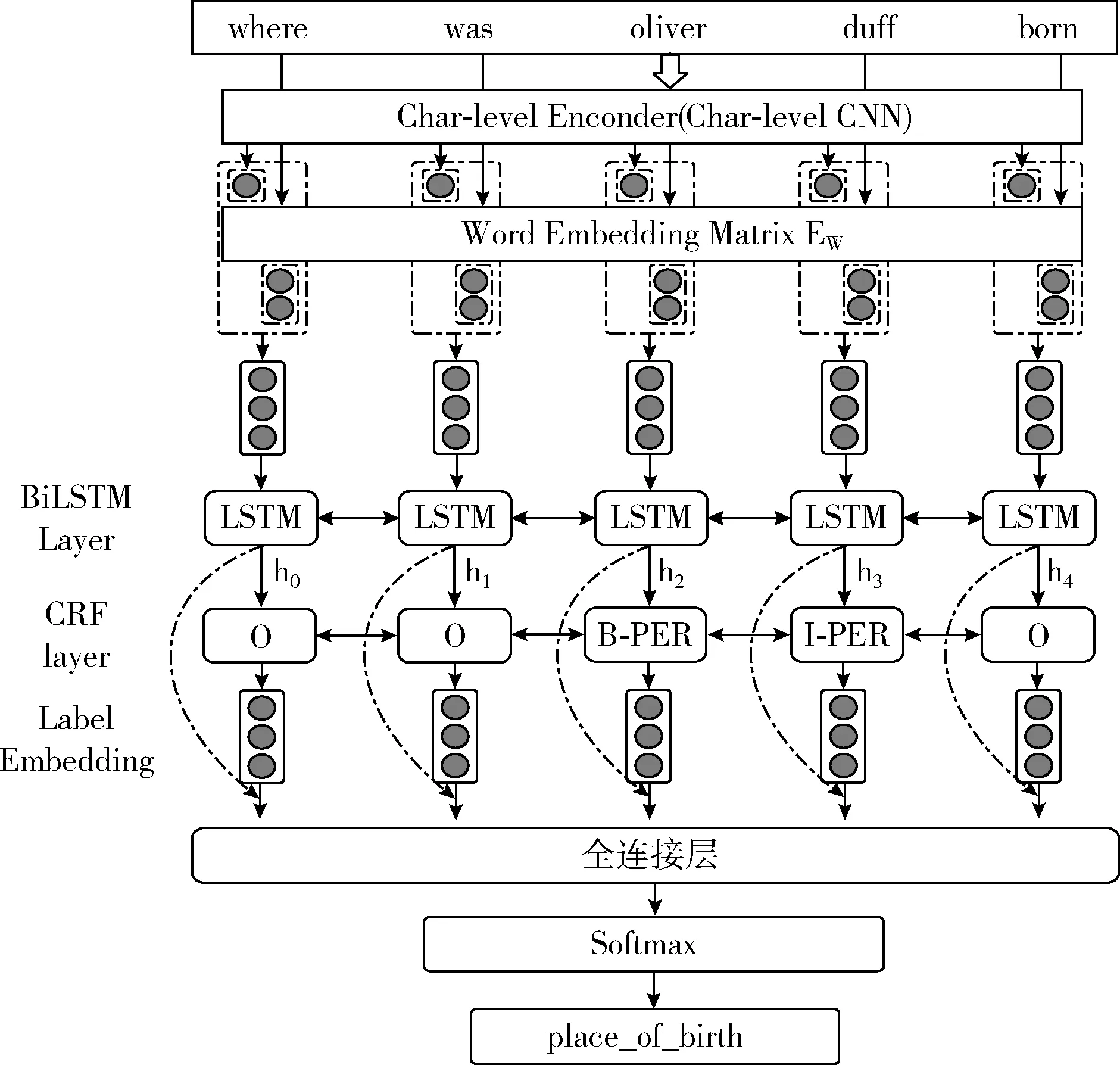
图2 联合实体识别和关系预测的模型
(1)输入层(即嵌入层)
对于问句的表示,我们首先将问句进行预处理(包括大小写字母转换等),对于预处理过后的问句序列q=w1,…,wn的表示,我们采用分层的编码方法,即利用问句中的每一个单词的字符级别和词级别的信息作为BiLSTM的输入。基于CNN的字符级别的编码器首先被用来得到每个单词的表示,字符向量(嵌入)表示可以捕捉微观形态特征,也可以避免(out of vocabulary)OOV问题。随后我们使用预训练的词嵌入Glove[11]作为每个词级别的向量表示,词嵌入能够捕捉宏观信息。然后将字符嵌入和词嵌入拼接在一起作为最终的单词表示
R(Wi)=[CNNchar_level(c1,…,cj);WE(wi)]
(1)
其中,ci表示问句中的单词wi的第i个字符的向量表示;WE(wi)表示问句中第i个单词的词嵌入。
(2)BiLSTM层
BiLSTM能够很好地捕捉长序列依赖信息,训练的过程中也能够避免梯度消失和梯度爆炸,因此在这一部分使用两层BiLSTM,得到句子级别的编码。我们将最终的词表示R(Wi)进行组合输入BiLSTM中得到问句的表示
Q=BiLSTM(R(W1),…,R(Wn))
(2)

(3)
(3)CRF层
在CRF层我们将BiLSTM的输出hi作为CRF层的输入,CRF层能够计算每个单词最可能的实体标签。图2中CRF层中表示了分配给问句的标记的BIO编码标签的示例。在CRF层中,可以观察到我们分别指定B-PER和 I-PER 标签以表示实体“Oliver duff”的开始和内部标记。设词向量为w,一系列得分向量s1(e),…,sn(e)和标签预测向量y1(e),…,yn(e),其中上标(e)用来标记实体识别任务。线性链CRF的得分定义如下
(4)

(5)
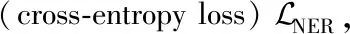
ci=[hi;gi],i=0,…,n
(6)
(4)关系预测
对于关系预测我们利用问句的标签特征以及BiLSTM所学习的特征进行拼接得到ci,作为关系预测的输入,我们利用softmax计算每条问句所属的关系。给定问题序列s和关系标签集合R,我们的目标是识别该序列所属的关系,计算序列s所属关系rlabel得分公式为
s(r)(ci)=f(W(r)ci+b(r))
(7)
P(rlabel|si)=softmax(s(r)(ci))
(8)
如图2所示,给定问句“Where was Oliver duff born”,我们可以通过联合学习模型识别实体名称:“Oliver duff”,关系预测的结果为“place of birth”。根据识别的实体和预测的关系形成结构化的表示:{subtext:Oliver duff,relation:place of birth}。虽然问句中的实体和关系已知,但是我们仍然需要进一步将实体链接到KBs中,利用链接到的实体和预测的关系进行答案查找。
1.2 实体链接
问句中识别的主题实体(subtext)需要精准地链接到知识库(KBs)中的真实节点。为了实现这一点,我们采用类似Ture[9]的方法,构建了一个倒排索引Ie,它将KBs中所有实体名称的n-grams(n∈{∞,3,2,1})映射成实体的别名文本,且每个别名文本都有一个相应的TF-IDF权重,同时为每个实体的称名也建立具有TF-IDF的权重的索引。TF-IDF权重计算公式如下
(9)
其中,tfi,j表示词频,其中ni,j表示某个词在某实体所有n-grams出现的次数,∑knk,j表示某个实体所有n-grams的总数,idfi,j表示逆文档频率,其中 |D| 表示KBs中所有实体的总数,|Dti| 表示包含某个n-gram的所有的实体个数。
一旦索引Ie被建立,我们可以链接subtext从结构化查询(例如:“Oliver duff”)到KB中的目标实体(如ei)。从n=∞开始,我们迭代subtext的每个n-gram并查询索引Ie,它返回KBs中所有具有TF-IDF权值的真实实体,对于subtext中不同n-gram链接到相同的实体,我们取n-grams 中TF-IDF权重最大的值。对于每个n-gram,将检索到的实体添加到候选实体集合C中。我们继续执行该过程,其中n的值逐渐减小(即n∈{∞,3,2,1})。如果集合C非空并且n小于或等于subtext中的单词(tokens)个数,则提前终止迭代。后一个标准是避免我们找到完全匹配的情况,但也有部分匹配可能更相关。
1.3 答案查找
我们构建候选实体列表C之后,使用每个候选实体e(cd)作为候选答案的起始节点,构建e(cd)的路径索引Ir,即映射每个候选节点e(cd)到所有可以到达的节点e(t),它们之间的路径为p(e(cd),e(t)),最终Ir(e(cd)) 表示为
(10)
其中,上标(cd)表示候选实体,上标(t)表示尾实体。当前我们研究的是单一关系的问题,因此我们将路径限制为单跳,但可以轻松地扩展到多跳路径以支持更广泛的搜索。我们使用Ir检索所有可以从e(cd)到e(t)的尾节点,且路径p与预测的关系r一致(即r∈p(e(cd),e(t))),最后将检索到的所有Ir添加到候选答案集A中。为候选集合C中的每个实体的重复此过程之后,答案集合A中的候选实体的TF-IDF得分最高候选节点即为该问题的最佳实体节点,最佳节点的尾节点即为最佳答案。
2 实 验
2.1 实验数据
本文使用SimpleQuestions[1]数据集来评估本文方法的有效性。该数据集包含10万条简单问题,其划分为训练集、验证集和测试集,分别包含75 910、10 845、21 687条数据。每个问题与Freebase知识库中的一个三元组(subject、predicate、object)对应,三元组可以用来回答该问题,如问题“Where was Oliver duff born”对应的三元组(m/0gy03bh、people/person/place_of_birth、m/0ctw_b)。三元组中的subject和object给定的是一个MID值,但是实体识别方法并不能根据MID识别问题中的实体,本文使用Mohammed等[10]的已标注的实体和非实体文本,对于问句中实体的类型标注,我们根据Freebase三的实体类型(type)进行实体类型的标注。
2.2 实验设置
我们的方法实现在操作系统为Centos7,运行在NVIDIA GeFore GTX 1080 Ti GPU,CUDA9.0,Pytorch版本v0.4.0,Python版本v3.6。本文利用CNN实现字符嵌入表示,使用BiLSTM实现问句特征的抽取,采用 Adam 算法进行参数更新。字符嵌入的维度为32,词嵌入我们使用维度为300的预训练的GloVe[11]嵌入;我们使用早停(early stop)技术在SimpleQuestions的验证集上进行模型超参数的验证。在最终的模型中,CNN模型的词窗口设置为3,包含一个卷积层和一个max-pooling层,CNN的输出通道维度为32。BiLSTM隐藏层和全连接隐藏层的大小为300;学习率为0.001;batch size设置为64,dropout都设置为0.3。根据数据集的大小,我们在30到100个周期(epochs)之后获得最佳超参数。我们根据验证集中的结果选择最佳的周期(epoch)。
2.3 实验结果与分析
对于实体识别,我们计算连续实体标签的召回率(Recall)、准确率(Precision)、F1值作为评估标准。实体链接和关系预测,我们评估召回率R@N,即正确答案是否出现在前N个结果中。对于问答准确率的评估,我们遵循Bordes等[1]的方法,即如果实体和关系完全匹配数据集中问题对应的三元组,则将预测标记为正确,主要指标是准确率(Accuracy),相当于R@1。
我们在验证集上与Mohammed等[10]的实体识别的结果进行了比较,相比他们得到平均93.1%的F1值,本文模型的F1平均值达到94.2%,稍微高于他们1.1%。为了展现本文实体链接的有效性,我们与Mohammed等采用BiLSTM和CRF这两种不同的实体链接方法的结果进行了对比,并增加本文方法中不使用CRF层的消融研究,见表1。

表1 验证集上Top K候选实体的召回率
表1中,我们比较了排名在前K(K∈1,5,20,50) 个候选实体上的召回率,相比Mohammed等[10]的方法,本文的模型在Top K上有显著的提升,且在BiLSTM上添加CRF能有效改善实体链接的效果。在不添加CRF的实验结果中,可以看出实体链接采用n-gram和TF-IDF建立倒排索引的方法具有更高召回率,同时也说明联合训练的方法对实体链接的影响较小。
关系预测的对比结果见表2,我们在验证集上对比分析了先前工作中使用简单神经网络方法进行关系预测的结果,即Ture等[9]采用BiGRU方法以及Mohammed等[10]采用的两种不同神经网络(BiGRU和CNN)方法预测的结果,同时增加本文模型中是否添加标签嵌入的消融实验,以便验证模型中标签嵌入的有效性。从表2中的实验结果可知,本文模型在关系预测的结果中体现了相对较高的准确率。当模型中不添加标签嵌入特征时,关系预测的准确率比Mohammed等的稍低,说明本文的联合学习模型对关系预测的准确率的影响可以忽略不计,当模型中添加该特征时,关系预测的准确率相比Mohammed等采用CNN的方法提升了1.6%。因此从标签嵌入的消融实验可以看出,标签嵌入特征能够有效提升关系预测的准确率。

表2 验证集上关系预测的结果
最后,为了展示本文方法的有效性,我们在测试集上比较了当前各种端到端最优的问答系统。如Bordes等[1]提出一种记忆网络方法;Golub和He[2]使用一种具有注意力机制的字符级别的encoder-decoder的LSTM框架;Dai等[3]
提出一种基于BiGRU的方法,它是利用一种称为CFO的集中修正方法进行简单问答;Yin等[4]利用一种基于attentive-CNN解决问答任务;Lukovnikov等[5]提出嵌套的词级别和字符级别的问题编码器并以一种端到端(end-to-end)的方法训练神经网络来回答简单问题;Yu等[6]提出通过残差BiLSTM增强关系预测解决知识库问答任务;Ture等[9]所提方法到达了目前知识库问答的最优方法,问答的准确率高达88.3%。Mohammed等[10]探索了各种强壮的基线模型,我们只比较了他们采用两种不同神经网络组合的方法,因为这两种方法在基线方法中取得了相对较好的结果。
实验结果表明,本文所采用的方法在知识库问答任务上取得了相对有竞争力的结果,虽然未能超越目前最好的方法,但也验证了本文方法的有效性,结果比较见表3。从表中结果可以看出,将Ture等的结果抛开不看,我们的实验结果超过最近报告方法1.9%。相比Mohammed等采用分别训练实体识别和关系预测的最好的神经网络方法,我们的联合学习方法的问答准确率超过他们4.7%。

表3 测试集上问答准确率
3 结束语
本文提出一种联合实体识别和关系预测的简单知识库问答模型,实验结果验证了该模型的有效性,相比之前工作中独立进行实体识别和关系预测的方法而言,本文模型能够同时检测这两者,提升了训练的效率,而且通过对比采用复杂神经网络方法的结果,发现本文模型也具有一定的优越性。在消融实验中,发现了CRF层和标签嵌入特征对KB-QA任务的提升效果。虽然本文所提方法在简单知识库问答上效果有一定的提升,但是仍然还有改进的空间,如增加注意力机制,提高模型的性能。
