基于多元时间序列分割聚类的异常值检测方法
2020-11-17邓春宇吴克河谈元鹏
邓春宇,吴克河,谈元鹏,胡 杰
(1.华北电力大学 控制与计算机工程学院,北京 102206;2.中国电力科学研究院有限公司 人工智能应用研究所,北京 100192;3.华北电力大学 电气与电子工程学院,北京 102206)
0 引 言
国内外研究者在时间序列的异常点检测方面已经做了很多工作,时间序列分析[1]、马尔可夫模型、遗传算法[2]等多种方法均有所应用。文献[3]按异常类型的不同确定不同的数据清洗方法,但没有考虑到多变量之间的相关性关系。文献[4]使用基于Kernel Smoothing技术和回归模型的分类方法识别异常数据,但是回归模型的选取需要一定的先验知识。文献[5]使用单分类支持向量机和主动学习的方法进行异常点的检测,此方法对主动学习策略的选择有较高要求。长短期记忆网络作为循环神经网络的一种变体,由于解决了RNNs无法完美学习的信息长期依赖的问题[6],在异常值检测领域已经有很广泛的应用。在研究过程中,长短期记忆网络预测准确度的问题是限制其异常检测准确度的最主要因素,研究表明预测精确度可以通过区分物理状态得到提高[7,8],而物理状态的区分可以看作是一个多元时间序列分割聚类问题。
提出一种基于多元时间序列分割聚类和长短期记忆网络的TICC-LSTM大数据点异常检测方法。使用多元时间序列分割聚类算法分析计算出原始数据最优分段数的基础上,建立多元时间序列分割聚类的最优化模型,确定分割时间节点和子序列,使用长短期记忆网络对每个子序列进行数据重构,计算与原始序列的残差判断提取出异常数据点。
1 多元时间序列分割聚类算法
1.1 多元时间序列分割聚类算法模型建立
实际物理过程是由多个子过程组合得到的,例如汽车的行驶过程可以分解为3段:加速、匀速行驶和减速停车,其中每个分段的数据均包含多个变量[9]。多元时间序列分割算法将原始数据在各个时间分割点分开,每个子序列代表一个实际的物理过程,认为在每个过程中数据的特点均应该是一致的,从而可以为异常检测提供良好的数据准备。
多维时间序列xorig是按时间顺序排列的多元时间序列,xorig=[x1,x2x3,…,xT]。其中T代表此时间序列的长度,xi表示第i个时刻的多元变量的观测值。为了表现时间序列每个前后时刻的数据之间的关联性,针对子序列而不是单个时间点进行聚类,即以每个时间点为基准,向前截取时间长度为ω的一段作为子序列,记为Xi=[xi-ω+1,…,xi-1,xi],其中i=1,2,…,T。
假设原始的多元时间序列可以被划分为K类,记Pj代表第j类信号段序号集合,其中j=1,2,…,K。为了可以表现出每个时不变子序列中各个传感器之间的关系,可以将每个聚类定义为一个与其它聚类完全不同的马尔可夫随机场。其中,马尔可夫随机场的边代表两个变量之间的偏相关性。
记每一类信号的协方差逆矩阵为Θi,Θi可以用来表示每个聚类的马尔可夫随机场。这个矩阵由ω×ω个子矩阵组成,每个子矩阵的大小为n×n,其中n代表信号段的个数,ω代表时间窗的大小,由于不同时刻之间的信号差别只和时间差有关,即两个不同时刻之间的逆协方差矩阵互为转置,因此每一类信号的逆协方差矩阵可以表示为

综上所述,对多元时间序列的分割聚类问题可以简化为一个优化类问题,优化目标是求解K个逆协方差矩阵Θ={Θ1,Θ2,…,ΘK} 和最终结果的聚类集P={P1,P2,…,PK},其中Pi⊂{1,2,…,T},因此优化问题可以表示为
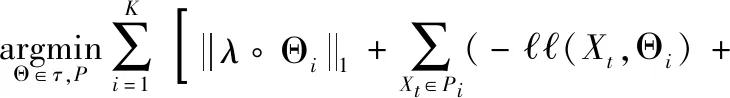
(1)
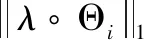

(2)
式(2)表示子序列Xt是被分配到序列i的对数似然,其中μi是集合i所有数据的经验均值,logdetΘi表示第i个逆协方差矩阵行列式的对数。
1.2 多元时间序列分割聚类算法求解方法
上述模型是一个混合组合和连续优化问题,由于两个变量:原始信号类别Pj和各类信号的逆协方差矩阵Θj具有深度耦合的特点,没有可行的方法求取其全局最优解,为此将求解分成两个步骤,首先将源数据点进行聚类,然后更新聚类参数,迭代计算直至小于设置的最小误差。
假设序列Xi=[xi-ω+1,…,xi-1,xi] 有K个潜在聚类信号段,把信号段Xi归入某一类的代价可以用如下式(3)来表示
(3)
考虑最大化源数据的对数相关性并且最小化类别信息在算法中的更改次数,两个约束构成了一个典型的流水线调度问题,如图1所示。
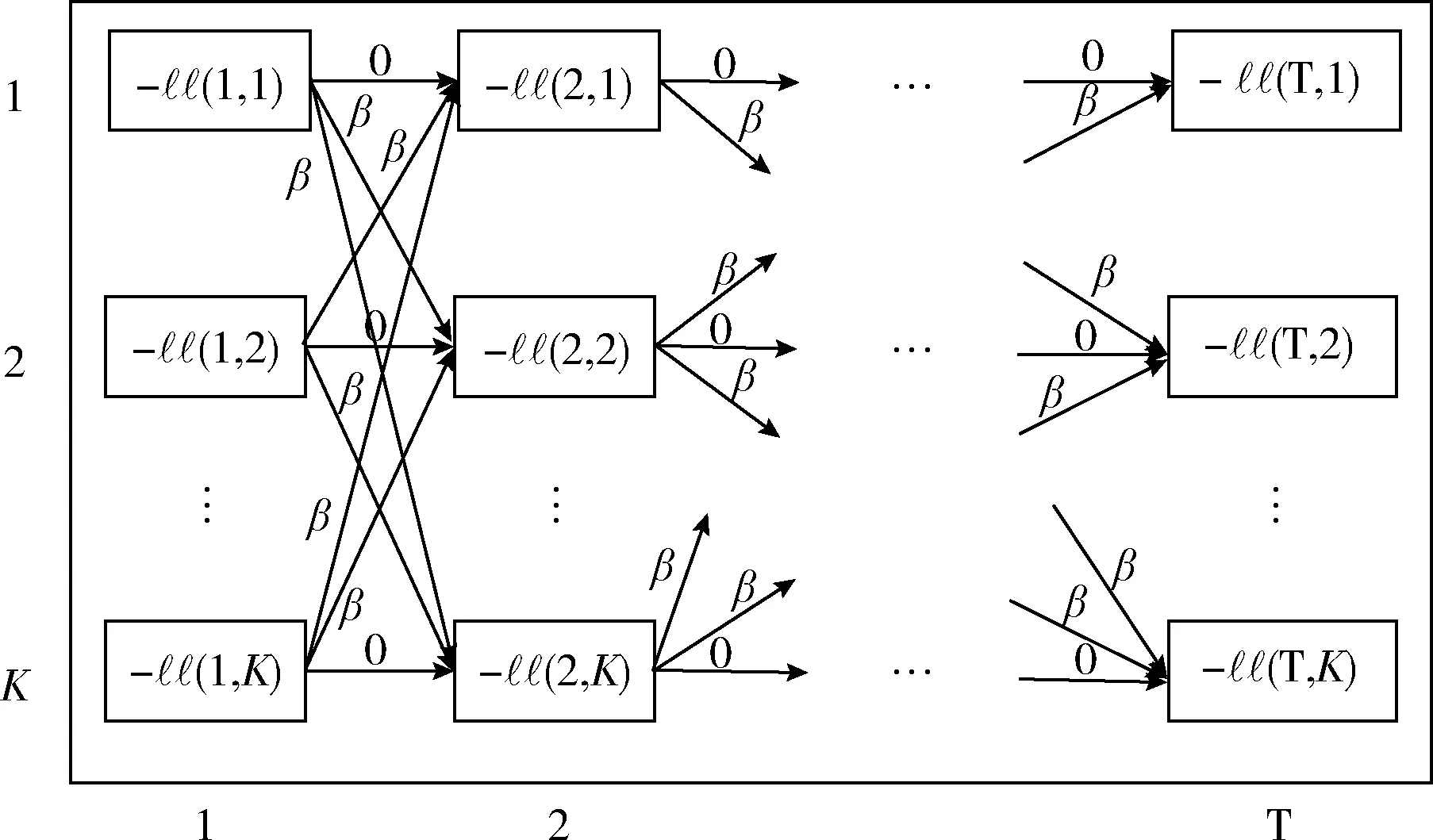
图1 源数据聚类流水线模型
式(3)所示的问题可以描述为找到从初始时间1到时间T的最短成本路径的问题,其中节点的成本为该点被聚类到此类别的负对数似然值,路径的成本为β,表示每次类别变化所造成的成本。
算法流程如图2所示。

图2 源数据聚类算法流程
以上可以计算出源数据的聚类Pi,逆协方差矩阵Θi可以使用最小化其负对数似然值之和的方法求取

(4)
其中

(5)
将上述问题进行变换并添加一个正则项,可以使用交替方向乘子法(ADMM)进行求解

(6)
综上所述,将原始信号数据输入程序中并设定初始参数,对两个存在相互耦合的变量聚类Pi和逆协方差矩阵Θi交互迭代求解,最终得到多元时间序列的分割聚类的类别信息。
2 长短期记忆网络
上述多元时间序列分割聚类算法保证了每个子序列均只包含一种物理状态,因此可以将每个子序列分别使用长短期记忆网络进行数据重构,并与原始数据样本进行比较,误差较大的数据可以认为是异常数据点。
长短期记忆网络的神经元状态只产生少量的线性变化,信息从前一状态到后一状态只产生少量的变化。信息的输入和修改是通过控制3个门控单元,即遗忘门、输入门和输出门来实现控制的。

ft=σ(Wf·[ht-1,xt]+bf)
(7)
it=σ(Wi·[ht-1,xt]+bi)
(8)
(9)
状态值的更新包含两部分内容:旧隐藏值状态的遗忘和新中间变量的更新,则t时刻状态Ct的计算公式如式(10)所示
(10)
输出层使用一个Sigmod函数决定需要被输出的神经元状态,然后通过一个tanh函数只输出需要的数据
ot=σ(Wo[ht-1,xt]+bo)
(11)
ht=ot*tanh(Ct)
(12)
长短期记忆网络的结构如图3所示。

图3 长短期记忆网络结构
3 变压器油色谱数据异常检测算例分析
3.1 变压器油色谱数据预处理
电力系统中采用的大型变压器多采用油浸纸绝缘结构,使用变压器油进行绝缘和散热。随着运行时间的增加,绝缘油长期处于强电磁环境下,会缓慢的产生乙炔、氢气、一氧化碳、二氧化碳、甲烷等气体[10]。在变压器发生局部放电或过热等故障情况时,这些气体的含量会发生明显的变化,因此根据这些气体的含量和变化规律可以判断变压器的老化情况,并且在一定程度上做到预测故障的发生。
变压器的油色谱数据包括总烃、氢气、乙炔、甲烷、乙烷、一氧化碳、二氧化碳等。在实际运行过程中,变压器的故障主要包括过热故障、局部放电故障、火花放电故障和电弧放电故障等[11]。各种故障条件下产气特征情况见表1。

表1 电力变压器各种故障条件下产气特征
仿真采用甘肃某变电站一台油浸式户外主变压器采集到的实际数据。本台主变于1992年出厂,在出厂试验中所有数据均合格,三相额定电压等级为345/121/10.5 kV,额定容量为150/150/50 MVA。在投入运行后,该主变所带负荷一直较低,且从未出现过载情况,负荷率基本在50%左右。2007年和2008年负荷率为30%-74%,原因在于同变电站的另外一台主变故障检修导致本台变电站负载升高。
采用此变压器2006年6月到2009年6月的油色谱在线监测数据,共10类超过10 000行数据。由于多种故障中甲烷、乙炔和氢气所占比重较大,因此选取这3种气体进行分析。
3.2 变压器多元油色谱时间序列分割聚类
经过上述对原始数据的处理,得到10 000个时间点的数据,其中每个时间点均包含甲烷、乙炔和氢气3种变压器油色谱气体含量。使用TICC-LSTM算法将上述时间序列数据进行分割聚类,定性分析每种类别的数据特征,从而得出变压器运行状态。
下面简要说明TICC-LSTM算法的参数选择。使用贝叶斯信息量(Bayesian information criterion,BIC)的方法对源数据进行分析,认为对源数据分为3类较为合适,即聚类数K=3,时间窗ω取5,即每个待聚类子序列有5个数据,初始λ设置为0.11,可以随程序的运行自动进行调整。聚类的经验均值随聚类的变化而发生变化,每次迭代得到的经验均值通常是不同的。
由于得到的各类数据的数据总量并不相同,传统的聚类效果比较算法均难以应用,动态时间规整算法(dynamic time warping,DTW)能够衡量两个序列的相似程度,认为类别间相似度大的聚类效果好。分别计算两两类别生成数据矩阵的欧氏距离,对得到的结果进行分析,判断分割得到的各子序列是否具有高独立性,得到的结果见表2。

表2 源数据各类别DTW分析结果
从分析结果可以看出,各类别之间的欧氏距离均较大。同时将源数据以折线图的形式表示,可以看出各类别数据之间具有显著的差异性。
图4展示了3种气体需要进行异常检测的原始数据的聚类情况,类别1中的数据整体呈现下降的趋势,其中乙炔最为明显,含量从开始记录时刻的27下降到了10.5。查询本台变压器的履历变更记录发现记录前因变压器两台冷却器发生故障,因此更换了油枕皮囊并对调压开关补充了绝缘油,多气体含量的下降正是此次维修所致。类别2的数据整体呈现平稳状态,乙炔、甲烷和氢气含量整体维持在9 ppm、10 ppm和2.1 ppm,这与变压器无故障正常运行的表现一致,说明这段时间变压器未发生局部放电、过热、过负荷等异常运行事件。类别3中乙炔和氢气的含量呈现明显的上升趋势,甲烷的含量上升不明显但数据具有一定的波动性,这种情况可能有3种原因造成,一种是变压器本体中某些部位(如引线接头或绕组匝间)有火花放电现象。无论是绕组长期过热造成绝缘老化引起匝间绝缘击穿,还是引线焊接不良引起过热造成绝缘击穿或引线烧断,都必然产生电弧放电,油中必将产生大量的乙炔气体。第二种可能是变压器有载开关的选择开头切断电流,由于要满足系统运行电压的需要,此主变压器有载调压相对较为频繁,这样经过拉弧后变压器油中也会产生大量的C2H2气体。第三种可能是主变油与有载分接开关切换油室中的变压器油相通。由于有载切换开关在变换分接时要切断电流,必然会产生电弧,造成变压器油分解,从而产生这些气体。

图4 变压器油色谱数据
3.3 变压器油色谱时间序列异常检测
以上聚类分割将源数据分成了3种类别共9段数据,每段数据均包括3种气体成分:氢气、甲烷和乙炔。每种气体成分的变化均与各自的时间变化相关,采用长短期记忆网络方法分别对每段数据进行重构,并计算与源数据的残差,认为残差超过一定阈值的点即为异常值点。
为了获得较好的预测效果,首先需要将训练数据标准化为具有零均值和单位方差。创建长短期记忆网络包含200个隐含单元,将梯度阈值设置为1从而防止梯度爆炸,初始学习速率为0.0005。
以类别3中氢气、甲烷和乙炔数据为输入,使用LSTM算法预测下来30个点的取值,得到的预测数据-原数据折线图和残差图如图5 所示。

图5 类别1氢气含量异常值检测
根据图5可以明显看出,乙炔数据中第14点的值明显偏离了预测值,呈现远低于其它点的现象。同时观察此类别3数据的整体变化趋势是平稳下降的,而此点明显偏离与数据的整体趋势,应该判定为是异常点数据。根据长短期记忆网络的预测结果,可以将这两个点的数据进行修正,从而使之符合数据的整体变化趋势,减少预警装置的误报。
在实际情况中此数据点的氢气含量为31.97 ppm,而异常值数据为15.01 ppm,查阅变压器的变更履历发现此时传感器出现了故障,从而导致测量产生了较大误差。
为检验所提TICC-LSTM方法的准确性,利用同样的数据样本在没有进行聚类的情况下使用相同的训练方法对数据进行预测。准确率描述正确识别出的异常点占总异常点的比例,误检率描述被误判为异常点的个数与总异常点个数的比值,其表达式为
(13)
(14)
其中,A表示准确率,B表示误检率,Np为正确检测出的异常点的个数,NF为检出的错误异常点个数,NT为异常点总数。
对所有3个类比的数据进行异常点检测,得到如图6所示的准确率直方图。

图6 预测准确率比较
图6可以看出,使用分割聚类对数据进行预处理后,由于每个子序列均只包含一个物理过程,从而使长短期记忆网络预测的准确率上升,异常点检测的误检率也从18.6%降低到5.4%。
4 结束语
在分析前人研究成果的基础上,总结了现有研究方法的优点和不足,针对数据的异常识别、时间分段聚合等问题进行了研究,得到以下结论:
(1)针对多状态的物理过程,为解决不同状态变化时可能产生的对异常值检测的影响,采用了一种基于多元时间序列分割聚类的TICC算法,将多元序列按不同状态分割成多个序列,此种聚类方法将大量数据分成多段,便于采用并行计算,并且便于对多段物理过程进行合理解释。
(2)采用长短期记忆网络的算法重构原始数据,并通过计算原始数据和重构数据的残差辨识异常数据点。该算法充分考虑了时间序列各点数据的长期依赖问题,适于大数据的分析。
使用变压器油色谱数据进行仿真验证,并与没有采用分段聚类的异常检测方法进行比较,实验结果表明本文提出的算法对多过程的多元时间序列异常点检测具有较高的检测精度,有比较好的应用前景。
