基于边缘计算和VPRS的火箭设备单机双层判读与实时诊断
2020-11-16徐二宝李玉玺杨明顺崔莅沐
徐二宝,李 言,李玉玺,杨明顺,崔莅沐
(1. 西安理工大学机械与精密仪器工程学院,西安 710048;2. 西安现代控制技术研究所,西安 710065)
0 引 言
运载火箭在射前测试及发射过程中,遥测数据判读是重要环节,直接关系到飞行器各系统的功能和性能判定与评估[1-2]。运载火箭现行的遥测等参数判读一般采用事后判读的方式,实验过程中将采自于不同子系统、不同设备单机全时段的所有参数源码数据先存盘,待实验结束后,所有存盘数据经过挑路等复杂解析处理后,在判读服务器中进行自动判读[2]。由于待判参数众多、速变等参数数据量过大,导致判读工作复杂,耗时较长,误判与漏判风险很大。同时,事后判读的滞后性,使得无法在第一时间发现和定位问题,影响火箭靶场测试的质量和进度。试验结束后,基于判读结果而进行的火箭状态诊断也因缺乏时效性而失去了意义[3]。
为此国内外学者针对这些问题进行了广泛的研究。文献[4]针对靶场几类参数,采用中值滤波算法实现了台阶参数和脉冲参数的滤波平滑处理,设计了双边多点阈值判断方法,自动准确识别台阶参数,实现了自动辅助判读功能,但该方法局限于台阶参数和脉冲参数,对于数量较多、判读较难的缓变参数并不适用;文献[5]以在轨故障诊断为研究背景,提出一种开放的判读函数编译平台,从遥测参数判读平台架构设计的角度,对平台的组成、实现技术细节及判读规则进行了论述,但缺乏遥测参数判读方法的分析。文献[6]通过判别参数测量值序列之间的相关系数来实现自动判读,该方法在一定程度上能实现缓变参数的判读,但缺乏对遥测参数历史数据的挖掘;文献[7]采用面向信号的设计思想,设计了一种简洁高效的遥测系统自动化测试平台,通过接收解析箭上遥测数据,无需人工干预,部分实现了自动化测试与自动化判读;文献[8]提出一种基于历史数据统计特性的遥测缓变参数自动判读新方法,有效辨识缓变参数中的异常参数,与传统以人工为主的判读方式相比,该方法能有效提高遥测参数判读的效率和准确性,但是依然没有实现真正的实时判读。文献[9]在箭地之间设计了大容量高速测试总线,实现了“基于模型和数据驱动的自动判读”,促进信息技术与航天控制技术的融合。文献[10]将运载火箭的故障诊断技术按照基于阈值的判别机制,基于模型或信息融合的故障诊断方法等类型进行分析,为运载火箭的远程故障诊断技术指出了方向。
由此可见,对运载火箭设备单机相关参数进行自动判读时,受制于判读数据量过大而不得不采用事后判读的方式。为了探索实现实时判读,本文提出边缘层-判读服务器层的双层判读架构。针对目前判读数据量大、效率低,计算资源大都消耗在海量正常数据的阈值比对,而对超限数据和真正反映设备状态的关键参数缺乏重点关注等问题,采用边缘计算技术进行解决;同时,针对目前判读系统判据单一且缺乏智能,状态诊断正确率低,“判而不准”等问题,采用变精度粗糙集(Variable precision rough set, VPRS)方法建立实时诊断模型进行解决。最终构建形成双层判读的架构以提高自动判读的效率和状态诊断的准确性,实现在线判读和实时诊断,满足现代化靶场测试的需求。
1 双层判读架构
边缘层-判读服务器层的双层判读主要包括两个方面:其一,在边缘端,即数据产生的源端,通常是指箭上或总检查车间,通过增加部署数据采集终端或升级现有的传感器等数据采集设备使之成为边缘计算节点,赋予其简单计算、小规模数据存储和数据传输的能力。分布于不同子系统的边缘计算节点组成边缘判读层。其二,在传统的判读服务器中新增高阶判据,借助于VPRS数据挖掘方法建立状态诊断模型,从设备历史数据中挖掘参数超限和设备状态异常之间的关联关系,量化计算各参数的重要度,并获取经约减后的诊断规则。双层判读架构下,海量的参数实时数据首先通过边缘层的阈值判读,筛选出具有高判读价值的数据传入服务器层,再经过高阶判据的进一步判读,并把判读结果输入到诊断模型中进行状态诊断。双层判读架构的网络部署拓扑结构图如图1所示,其软件架构如图2所示。
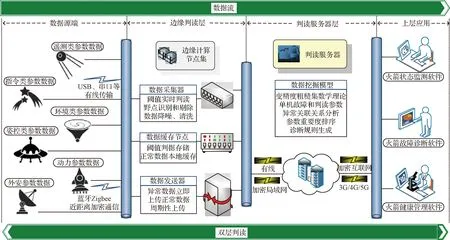
图1 双层判读网络拓扑图Fig.1 Network topology diagram of double-layer interpretation
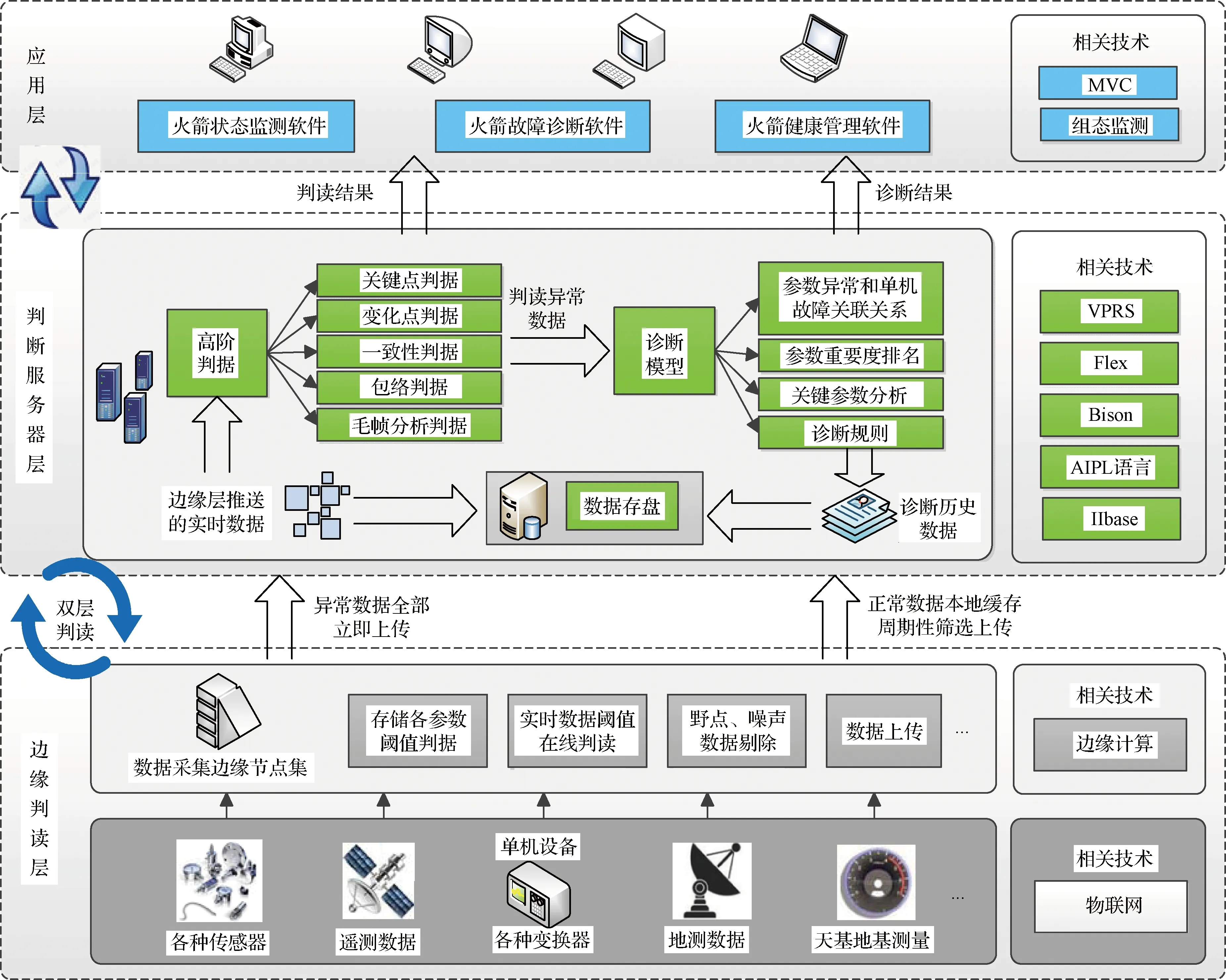
图2 双层判读软件架构图Fig.2 Architecture diagram of double-layer interpretation
2 边缘判读层
双层判读架构中边缘判读层负责原始数据收集、数据阈值比对、数据筛选上传等重要功能。根据数据源分布情况部署边缘节点,边缘节点内预先存储所采集参数的阈值判据,同时添加一个上下限略大于阈值范围的超限识别区。每个边缘节点采集对应遥测参数的实时数据。在边缘节点内对海量的参数实时数据进行阈值比对时,对于大部分没有进入超限识别区的正常数据,首先暂存在边缘节点内部缓冲区中,并按照一定的时间间隔挑选出此时段内最大值、最小值再发送到判读服务器;对于少数的超出阈值范围的异常参数数据,立即上传到判读服务器;对于进入超限识别区,但暂未超出阈值的参数,通过提高参数采集频率和上传频率的措施予以密切关注。边缘判读层判读的流程如图3所示。
边缘判读层主要目的是把简单但是繁重的参数阈值比对工作,从判读服务器中迁移到多个边缘计算节点上分布式并行执行。根据判读结果筛选出更有判读价值的异常或准异常数据再传入判读服务器。从而大大减小判读服务器的数据量,提升自动判读的效率,为实现实时在线判读提供了基础。
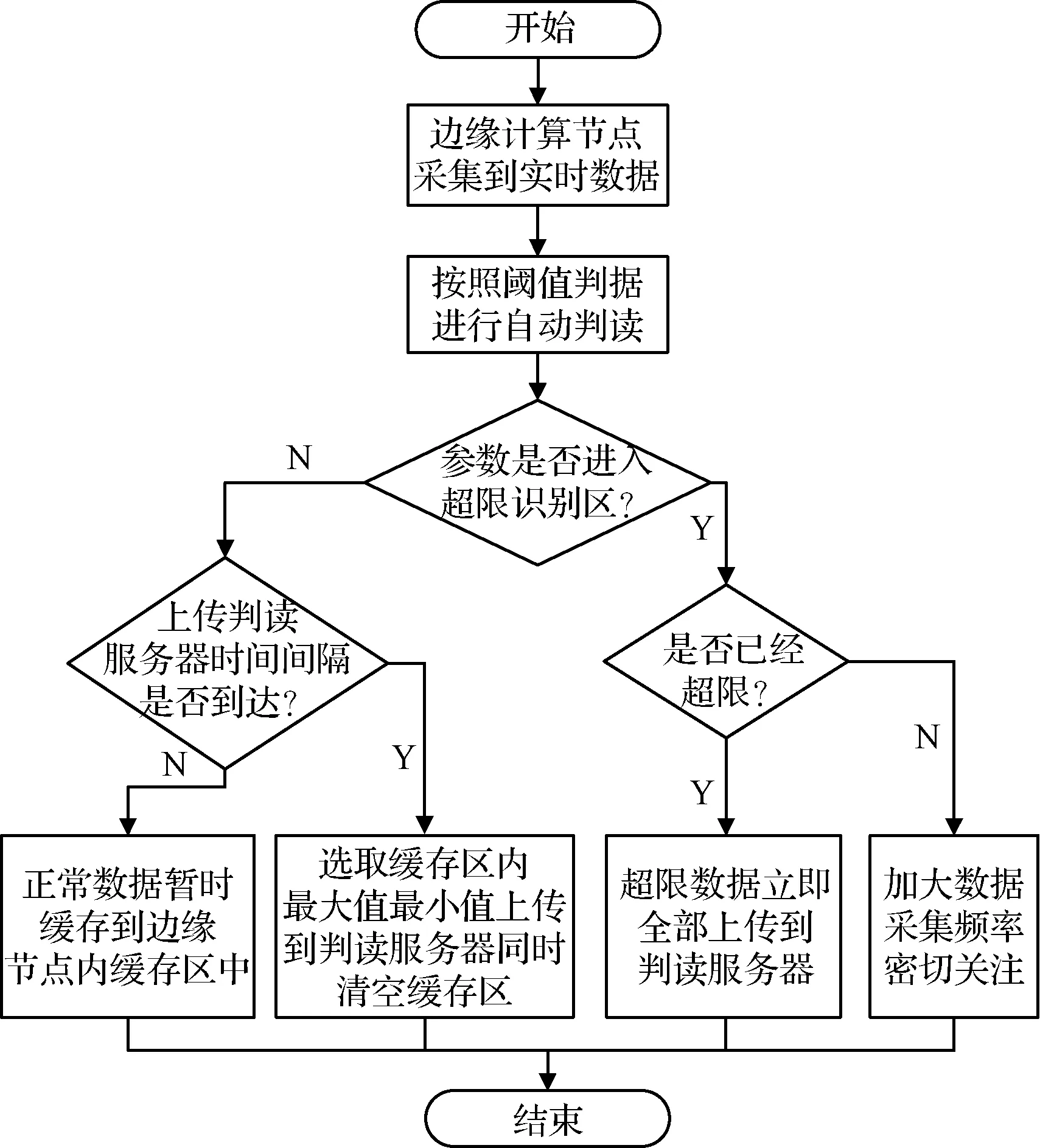
图3 边缘判读数据流程图Fig.3 Flow chart of data interpretation in edge layer
3 判读服务器层
目前的自动判读软件判据比较单一,主要依赖阈值判据,或称固定值上下限判据[8],主要应用于电压、电流、温度、压力等缓变类参数的判读。当被判参数超出所设定的阈值时就被认定为数据异常。阈值判据的优点在于计算简单,判读速度快。然而,参数超限和设备单机故障之间模糊的映射关系需要专家系统,甚至是人工来界定,造成“判而不准”等问题,使得判读工作只停留在判别参数是否异常上,而无法及时、准确地对设备单机的状态给出诊断结果。
鉴于此,在判读服务器层,首先定义一门新的判据描述语言,用以描述更复杂、更智能的高阶判据。经过边缘层阈值筛选出的异常参数,执行高阶判读并获得判读结果,存入HBase分布式数据库中。然后,充分利用设备单机历史数据,基于VPRS理论建立诊断模型,利用其属性依赖度和重要度计算方法,挖掘出参数异常和设备状态之间的关联关系,分析出影响设备工作状态的关键参数。最后,借助于变精度粗糙集的属性约减和值约减算法,提取出简化后的诊断规则,添加到诊断规则库中。最终实现设备单机的在线判读和实时状态诊断。
3.1 AIPL判据描述语言
如何将判据精确转换为计算机语言,是实现自动判读的首要问题。为此,设计出一种包含语法、语义的计算机高级语言AIPL(AutoIP Language),实现姿控、制导、动力、电气总体及测量各系统或专业的判据描述,同时自动生成判读分析报告。AIPL语言主要包括标识符、表达式和判据语法。
1)标识符
标识符用来标识对象名称(包括变量、函数)。在AIPL语言中,主要有2类标识符:
(1)关键字。规定了32个关键字,如diff,mp,CP,envelope等,它们有特定的用途和含义,不能用作变量名。
(2)系统预定义的标识符。如系统提供的库函数的名称sin,cos等。
2)表达式
表达式是构成语句的基本单元,时段、处理公式、判据公式、误差等均用到表达式。
3)判据语法
判据语法格式为待判参数、起始时间、结束时间、判据公式、正向误差和负向误差。判读时,将判据公式的计算结果作为理论值与待判参数的实测值比对,计算其差值是否在正负向误差范围内。
3.2 高阶判据
1)关键点判据
用于对待判参数关键时间点的值进行判读的判据。在编辑判据时,直接给出几组关键点(时间,值)。自动判读时,获取待判参数在关键时间点的实测值和设定的理论值做差,判断差值是否在正负误差范围内。
2)变化点判据
使用运算符cp进行描述,用于对参数值发生变化的时刻进行判读。在编辑判据时,直接给出几组变化点(值,时间)。自动判读时,获取待判参数实测值等于变化点值时的实测时间,并和设定的理论时间做差,判断差值是否在正负误差范围内。
3)一致性判据
使用运算符mp进行描述,判读时将首个参数作为参考参数,后续各参数的实测值均与参考参数值逐点做差,判断差值是否在允许的误差范围之内。该判据通常用来判读理论上要求变化趋势一致的参数。在诊断模型中可以将一致性好的参数合并处理,从而减小模型的参数量,加快模型的训练速度。
4)包络判据
将同一个参数多次试验的数据,逐点取出最小值、最大值保存下来,所有的最小值形成参数的下包络曲线,最大值形成上包络曲线。通过计算实时点是否超包络,或超包络的程度来识别野点、数据噪声点和数据扰动等异常情形。
5)丢帧分析判据
特定用于帧计数类型参数,判断当前帧计数值和前值之间的差值是否为1,以此来判断是否丢帧。
3.3 变精度粗糙集
变精度粗糙集(VPRS)作为解决非线性对应关系问题的数学方法,在不需要先验知识的情况下,从海量数据中挖掘出潜在的知识和规律[11-12]。其核心思想是在分类能力不变的情况下,通过知识约简,得到不确定问题的决策或分类规则[13]。变精度粗糙集引入阈值参数β,表示在一定范围内允许分类误差率存在。β一般取值范围为:0.5<β≤1[14]。
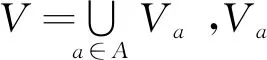
利用判读服务器中存储的设备单机历史数据,检索出判读结果为异常的参数构成条件属性集合C,参数异常情况下单机的状态作为决策属性D。
1)计算单机故障状态与待判参数的依赖度
VPRS中决策属性D与条件属性C的依赖度定义如下:
(1)
其中,POS(C,D,β)是β的正域[16]。
利用变精度粗糙集的属性依赖度计算方法量化分析单机状态与参数异常之间的依赖程度。
2)参数重要度排序及关键参数
VPRS中定义条件属性集合C去除属性r后对分类的影响为:
K(C,{r},β)=|γ(C,D,β)-γ(C-{r},D,β)|
(2)
单属性r对分类的影响表示为:γ({r},D,β),则属性r的重要度可定义为:
sig(C,{r},β)=K(C,{r},β)+γ({r},D,β)
(3)
重要度越大则属性越重要,表示该参数的异常对单机状态影响越大。用此方法对判读参数进行重要度排序,获取影响单机故障状态的关键参数[17]。
3)参数约减
变精度粗糙集的属性约减就是对条件属性进行约减,若单个属性r的依赖度γ({r},D,β)等于γ(C,D,β),则认为此条件属性为冗余属性。
从众多的判读参数中去除冗余参数,然后从约减后的参数中提取诊断规则,从而简化状态诊断过程,提高状态诊断的效率和精准度。
4)值约减
经过属性约减后的决策表,每一个样本形成一条决策规则,通过值约减的方法继续简化。对于决策规则集合中的每条规则,若去除该规则中的某个属性,该规则不和集合中其它规则冲突,则从该规则中删除此属性。经过值约减后,所有的诊断规则都不含有冗余条件属性,获得了最精简的诊断规则。
4 实例验证
为了验证所提出的双层判读架构的有效性,以图4所示长征系列XX运载火箭为例,选取仪器舱中的前舱端头柄这一设备单机作为研究对象。该单机主要负责测试仪器舱温度和过载情况,并据此判断仪器舱的状态。该单机主要采集的参数包括:前舱热电偶(c1)、前舱内壁温度(c2)、前舱噪声(c3)、前舱端头柄根部内壁温度(c4)、前舱端头柄根部内腔温度(c5)、前舱端头柄附近内壁温度(c6)、前舱阶振频率(c7)、前舱高精度过载(c8)、端头柄俯仰姿态角(c9)、端头柄滚动姿态角(c10)、前舱冷端补偿(c11)、端头柄头部压力(c12)、端头柄尾部压力(c13)。

图4 长征系列XX运载火箭Fig.4 Long march XX rocket
4.1 边缘判读层实现
按照第2节中边缘判读层的要求,升级箭上遥测分系统数据接收机的功能,添加数据存储、阈值比对和数据发送硬件模块。在靶场进行模飞总检查时,边缘节点以1000比特率的速度从总线上实时采集13个监测参数的数据。经阈值判读后,按照图3的流程进行本地缓存和筛选,最终以平均100比特率的速度向判读服务器上传。
从HBase数据库中检索前舱端头柄单机故障的历史数据,挑选出如表1所示的8组异常数据。
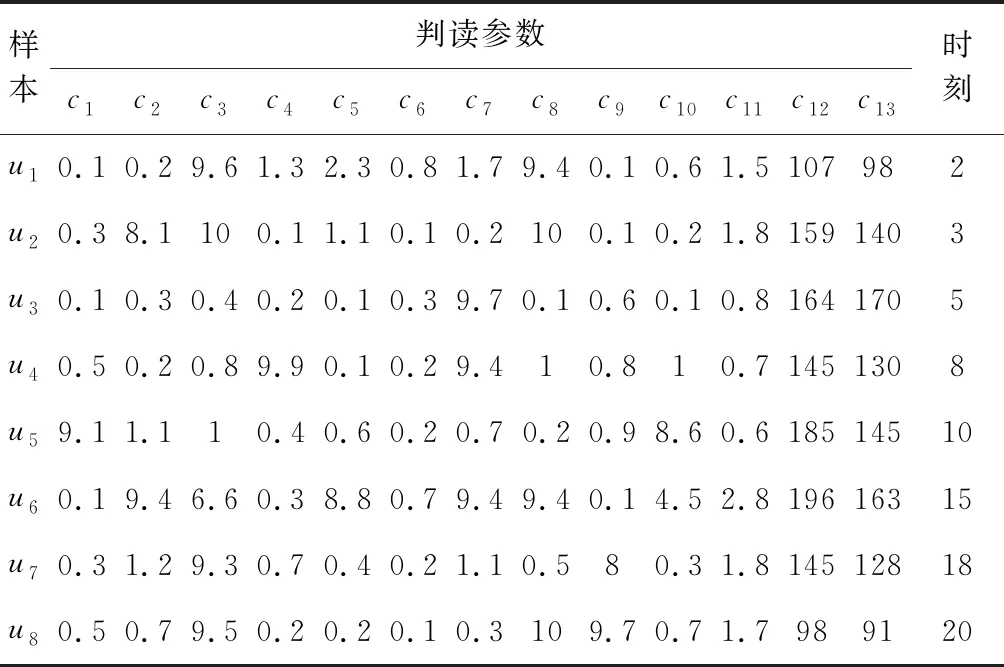
表1 c1~c10参数原始数据Table 1 Original data of c1~c10 parameters
4.2 判读服务器层高阶判据判读实现
使用HBase数据库和Qt编程语言开发自动判读软件,实现数据接收、判据管理、自动判读等功能。按照第3.1节中AIPL语言和第3.2节中高阶判据的语法,编写参数的高阶判据。在所开发的自动判读软件中,读取边缘层实时传入的判读数据,执行判读过程,获得参数判读结果并自动生成判读报告。
最终的判读报告显示,参数c11,c12和c13阈值判读和高阶判读均正常;样本u5,u6和u7输入现有的诊断规则库中,判定单机状态均正常。所以,后续通过诊断模型进行状态诊断时忽略这些参数和样本,从剩余的异常参数和故障样本中提取诊断规则。
4.3 基于VPRS的实时诊断实现
基于VPRS的诊断模型的构建与诊断规则的提取按照如下步骤进行:
步骤1:构建原始决策表
构建论域集合U={u1,u2,u3,u4,u8},5组判读样本数据作为原始决策表;10个判读参数C={c1,c2,…,c10},作为决策表中的条件属性集合;依据参数的判读结果和试验实际情况,确定设备单机故障类型D={d1,d2,…,d4}为决策表的决策属性集合。其中,d1表示前舱过载,d2表示前舱温度异常,d3表示前舱振动异常,d4表示端头柄与内壁接触摩擦。
步骤2:数据标准化
对原始决策表中的条件属性进行标准化处理,标准化使用Z-core正规化法,如式(4)所示:
(4)
式中:E(xj)表示原始样本集中特征变量xj的均值,D(xj)为特征变量xj对应的标准差。
步骤3:数据离散化处理
对原始决策表1中的条件属性和决策属性,按照步骤2进行标准化后进行离散化处理。取[0,5]区间值为0,[5,10]区间值为1,将连续属性的值域划分为若干个子区间得到离散决策。
步骤4:参数依赖度和重要度计算
按照式(1)计算故障状态对各参数的依赖度;然后根据依赖度计算结果依据式(2)和式(3)计算参数的重要度,得到最终的参数重要度排序为:c8>c4>c7>c2>c9>c5>c3>c6>c10>c1。可见,关键参数为c8和c4。后续在进行人工判读和自动判读时,根据参数重要度,通过加快参数c8和c4的采样频率,增加数据上传量的方式对关键参数予以重点关注。
步骤5:参数约减
变精度粗糙集中分类正确率β取值范围为0.5~1,随着β的增大,粗糙集的近似边界区域变宽,不确定区域变大。在进行β选取时,优先考虑近似分类质量,在分类质量相近时,β值尽可能取最大上界,同时尽量约减掉更多的属性。计算β分别取0.6,0.7,0.8和0.9时的分类质量和约减结果,发现β=0.9时获得了最优的近似分类质量和最简的参数约减结果。利用VPRS知识约简算法对10个参数进行约减,约减后的最终参数集合为{c2,c4,c7,c8,c9}。
步骤6:值约减
经过属性约减后的决策表逐行获得一条诊断规则,利用第3.3节中的值约减方法去除每条诊断规则中的冗余参数,得到最小的约减规则如表2所示。

表2 最小约减规则表Table 2 Minimal decision table
步骤7:提取诊断规则
针对表2中经过属性约减和值约减后的每一个故障样本提取诊断规则,结果如下:
规则1:IF(c2∈[0,5]∩c8∈[5,10]∩c9∈[0,5]或c8∈[5,10]∩c9∈[5,10]) THENd1(前舱过载)
规则2:IF(c2∈[5,10]∩c7∈[0,5]) THENd2(前舱温度异常)
规则3:IF(c4∈[0,5]∩c7∈[5,10]) THENd3(前舱振动异常)
规则4:IF(c4∈[5,10]) THENd4(端头柄内壁接触摩擦)
这些规则和已有诊断规则库进行匹配,如果属于新增规则,则添加到规则库中。
通过靶场试验可知,针对实时采集的13个参数的原始数据,首先通过边缘判读层将参数数据量减小为原来的1/10;然后,在判读服务器层中,利用所建立的诊断模型进行状态诊断。多次试验结果表明,能够在5 s内完成从参数超限到诊断出故障结果。实验证明该方法充分考虑了判读参数和单机故障之间的关联性,通过对参数之间依赖度和重要度的量化计算获得了参数重要度排名,最终通过参数约减提取到了最简的诊断规则,使得自动判读的数据量大大减小,实时状态诊断的效率大大提升。
5 结 论
对现有的运载火箭设备单机自动判读软件进行重构,基于边缘计算和VPRS,提出了边缘层-判读服务器层的双层判读架构与实时诊断方法。通过添加边缘层,对参数进行阈值判读,筛选出了具有高判读价值的数据,使得传入判读服务器的参数数据量减小为原来的1/10,大大减轻了判读服务器的负荷,提升了自动判读的效率。长征系列XX运载火箭的靶场总检查实验表明,能够在5 s时间内完成从边缘节点阈值判读到判读服务器高阶判读,再到诊断模型诊断出实时状态,大幅缩减了从参数判读到状态诊断的时延。所设计的双层判读系统在一定程度上实现了在线判读和实时诊断。后续就如何进一步提升状态诊断正确率等方面展开研究。
