适应聚类方法在公共安全事件应急管理中的应用
2020-11-12马雯
马 雯
(陕西警官职业学院,陕西 西安 710021)
0 引言
我国正处于从世界大国向世界强国的转变阶段。随着城市化进程的不断加速和人民生活水平的大幅提升,人群聚集效应愈加明显,随之而来的还有各类公共安全风险的增大[1-2]。如本年度爆发的新型冠状肺炎事件,爆发时间正值春节前夕,人员流量大,为疫情防控带来了极大的不便。期间,通过手机定位技术查询用户行动轨迹对疫情防控起到了非常大的帮助作用。截至2019年6月,我国手机普及率达到112.2部/百人,通过手机定位采集用户位置信息,得到用户位置信息等数据后,利用大数据挖掘技术对用户定位信息进行处理,并过滤得到有效信息,可提升应急救援效率[3-6]。本文从移动终端定位技术研究入手,对基于移动位置信息的适应聚类方法在公共安全事件应急管理中的应用进行了研究,旨在为公共安全事件应急管理效率提升提供技术和理论支持。
1 基于非均匀稀布阵列的手机定位方法
诸如小区识别码(cell tower id,Cell-ID)、到达时间定位法(time of arrival,TOA)、到达时间差定位法(time difference of arrival,TDOA)和到达角度定位法(angle of arrival,AOA)等基于通信网络的手机定义技术目前应用较多,三个以上基站协同作业便可以完成定位过程[7]。诸如地震、爆炸等具有物理破坏性的公共安全事件极有可能会对既有基站造成损坏,导致定位不准确,进而影响应急抢险速度、增大应急管理难度。基于非均匀稀布阵列的手机定位方法作为传统手机定位技术的补充,具备探测微弱手机信号的能力。多个手机定位时,无需信号配对就能实现高精度、高分辨率的手机定位。基于非均匀稀布阵列的手机定位方法如图1所示[8]。
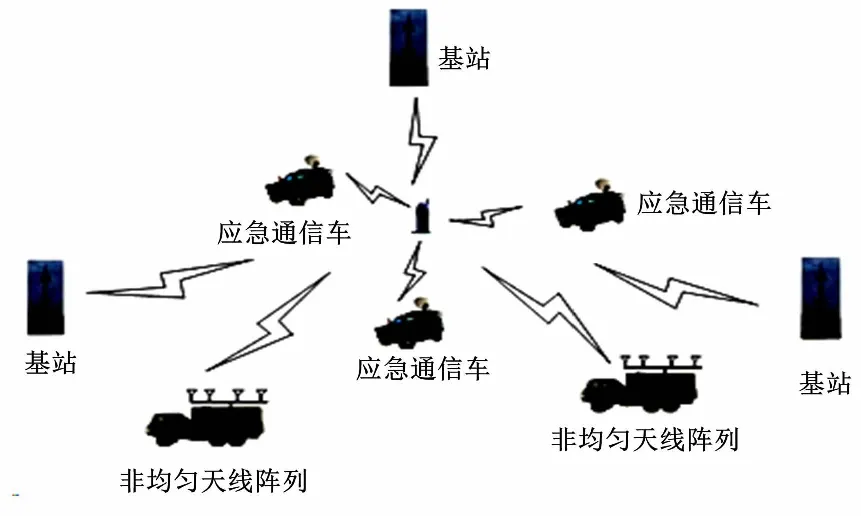
图1 基于非均匀稀布阵列的手机定位方法Fig.1 Mobile phone location method based on uneven sparse array
非均匀稀布阵列一般由两台车载形式的阵列完成手机定位,具有机动能力强、阵列展开方便等优势。相比传统的手机定位技术,它能大大缩短手机定位时间。车载阵列采用十米级小孔径稀布阵,两台车共同组成大孔径稀布阵,以完成高精度、高分辨率的手机定位技术。
基于非均匀稀布阵列的手机定位原理如图2所示。

图2 基于非均匀稀布阵列的手机定位原理图Fig.2 Location principle of mobile phone based on uneven sparse array
假设待定位手机信号位于位置T处,共有m个天线接收来自信号源T的电磁信号,选择第一阵元所在位置为原点,以所有阵元所在直线为x轴,建立坐标系。其中,θi和Ri分别为信号源T与第i个阵元之间的方位角和距离。假设射线OT以逆时针方向旋转至坐标轴Y所扫过的角度为正方位角,可得手机信号空间谱P(R,θ)的计算公式,如下所示。
(1)
式中:N为噪声的协方差矩阵;α(R,θ)为阵列流矢量;P(R,θ)为手机信号空间谱的峰值,与此对应的扫描距离和方位即为阵列与手机间的距离R和方位角θ。
2 基于移动位置信息的自适应聚类方法
2.1 自适应聚类方法介绍
分析基于非均匀稀布阵列的手机定位方法可知,由于搜索所得的手机信号数据量大,传统的数据处理方法无法满足如此大量的数据数据信息。为此,本文引入基于移动位置信息的自适应聚类方法[9]。
手机定位的空间位置数据存在维度高、非线性和稀疏性等特点,上述算法对输入参数的敏感性较高、参数选择难度较大。为此,夏鲁宁等[10]在基于密度的噪声应用空间聚类(density-based spatial clusterting of applications with noise,DBSCAN)算法的基础上进行改进,提出了基于密度的自适应噪声应用空间聚类(self adaptive density-based spatial clusterting of applications with noise,SA-DBSCAN)算法。改进后的算法能借助于算法本身对数据集的分析完成参数的统计。聚类过程中尽可能减少人工干预,降低人为选取参数引起的误差。
2.2 DBSCAN算法介绍
DBSCAN算法的核心点、边界点和噪声点如图3所示。

图3 DBSCAN算法的核心点、边界点和噪声点Fig.3 Core point,boundary point and noise point of DBSCAN algorithm
如图3所示,该算法从核心点出发,通过超球状区域内数据对象的数量衡量此区域密度的高低,并将所有密度可达的对象组成一个簇,从而有效地识别和排除噪声点和边界点。计算方法和定义如下[11-12]:
假设有数据对象p,定义NEps(p)为数据对象p以Eps为半径的d维超球体邻域,则:
NEps(p)={q∈D|d(p,q)≤Eps}
(2)
式中:D⊆Rd为d维空间的数据集;d(p,q)为数据集D中对象p和对象q之间的距离。
给定整数minPts。当对象p的Eps邻域内的对象满足NEps(p)≥minPts,则称对象p为(Eps,minPts)条件下的核心点,落在任意核心点的Eps邻域内对象称为边界点,此外称之为噪声点。
2.3 改进后的SA-DBSCAN算法介绍
DBSCAN算法的核心在于确定两个常数Eps和minPts。改进后的算法通过对原有数据的分析和计算,自动获得这两个参数。
定义Dn×n={d(i,j)|1≤i≤n,1≤j≤n}为距离分布矩阵,其中每一个元素指D中对象i和j之间的距离。将Dn×n中每一列排序并转置得到如下矩阵:
Kn×n=sort(Dn×n)T
(3)
矩阵Kn×n中列向量为数据集内所有对象与其最近的第(k-1)个对象(k为列下标)的距离集合。当k=1时,无第(k-1)个对象,故上述矩阵中第一列为0向量,去掉矩阵的第一列,得到:
Kn×(n-1)=sort[Kn×n(1:end;2:end)]
(4)
则Kn×(n-1)的第k(k=1,2,…,n-1)列表示数据集中对象k与邻近距离集合。
以常见的概率分布为例,并以当前发现拟合效果最好的逆高斯分布作为拟合方法,先通过绘图得到minPts=k的值。其概率分布公式为:
(5)

(6)
通过拟合便可获得:
(7)
3 具体应用
3.1 应用流程
手机定位本身存在一定的误差,数据采集和人为干扰会导致手机定位信息误差的增大。根据前文所述,选择自适应聚类方法去处理位置数据是适当的。利用定位信息中距离数据的缓变性,自适应地形成聚类算法的分类阈值,以进一步提高聚类精度,为实现更精准的公共安全事件应急管理提供便利。基于移动位置信息的自适应聚类算法应用流程如图4所示。

图4 基于移动位置信息的自适应聚类算法应用流程图Fig.4 Application flow of adaptive clustering algorithm based on mobile location information
该算法步骤如下。①需要利用非均匀稀布阵列对手机进行定位,从而获得位置信息数据。②以非均匀稀布阵列对待定位手机距离和方向的定位,设置位置信息的阈值初始值。③利用Euclidean Metric原理计算待定位手机的位置信息及相似度。④根据上述计算所得的阈值、相似度及距离等信息,得到位置信息的聚类。⑤依据第二章节所述聚类算法,经过算法自适应调整位置信息,并统计聚类后的位置信息相似值得均值,当均值小于距离或方位的阈值时,完成预分选,否则重复第③~第⑤步,直至满足完成与分选的条件。⑥根据分类提取的知识,提出并执行公共安全事件应急管理措施。
3.2 应用效果
以某次A城市地震灾害搜救过程为例。在该次地震搜救过程中,采用的是4个车载基站,搜救范围为一个倒塌的楼房,范围不超过5 km,故将搜救半径设定为5 km。
定位信息及其聚类结果如图5所示。

图5 定位信息及其聚类结果Fig.5 Location information and clustering results
改进后的SA-DBSCAN算法能够根据数据集中的密度进行数据的簇划分,进而实现本文所述的Eps和minPts两个参数的取值。运算时间及聚类准确度统计如表1所示。

表1 运算时间及聚类准确度统计Tab.1 Operation time and clustering accuracy statistics
由表1可见,当两种聚类算法的Eps和minPts两个参数取相同值时,改进后的SA-DBSCAN算法所需运算时间更短,且所得的结果相较于DBSCAN算法有更高的精度。
4 结论
城市化带来越来越密集的人群聚集,公共安全事件应急管理越来越受到民众的关注,同时它对政府职能部门应急管理能力也提出了诸多要求。信息化的快速发展为应急救援和应急管理带来了新机遇,借助于大数据分析等技术,不仅有助于事前公共安全事件的预防和控制,而且有助于在安全事件发生后尽可能减少人员和财产损失。当前,云大物移智已经走进我们的生活,应用新技术建立更加智能的应急管理系统,更有助于提升职能部门应急管理能力。
