基于卷积神经网络与马尔可夫随机场的目标检测
2020-11-12吉珊珊陈传波
吉珊珊 陈传波
1(东莞职业技术学院计算机工程系 广东 东莞 523808) 2(华中科技大学软件学院 湖北 武汉 430074)
0 引 言
目标检测是智能监控、虚拟现实、人机交互、动作分析等领域的关键技术,其性能直接影响了应用领域的效果[1]。目前主流的目标检测与识别工作主要针对某些指定的应用场景,如手势识别[2]、动作识别[3]、面部表情识别[4]等。语义分割[5]融合了传统的视频分割和目标识别两个任务,其目标是将视频分割成若干特定语义的区域,最终获得像素语义标注的视频序列。语义分割的优点在于能够无差别地检测出前景区域,本文利用语义分割的优点,将语义分割思想应用到目标检测领域中。
深度卷积神经网络(Deep Convolutional Neural Networks,DCNN)通过训练数据自动地学习特征,在图像、视频的目标识别领域取得了较好的效果[6]。文献[7]将DCNN应用于人脸标签识别的问题中,该研究通过GPU提高了DCNN的处理速度,并且实现了较高的检测准确率。文献[8]提出一种基于DCNN与长短期记忆网络(Long-Short Term Memory,LSTM)的维吾尔语文本突发事件识别方法,该算法实现了较高的召回率与查准率。文献[9]将DCNN应用于动作识别领域中,该算法获得了极高的查全率与查准率,但是该算法需要输入先验动作集进行预训练。上述DCNN模型大多为全监督或者半监督的问题,在弱监督的DCNN训练过程中存在明显的标签不一致问题,而视频目标检测问题大多属于弱监督数据。
为了解决DCNN的标签不一致问题,本文提出置信帧的概念,算法采用置信帧对预训练的DCNN模型进行优化调节,提高模型的性能。DCNN输出的特征还不足以准确提取出目标,采用马尔可夫模型将前景目标与背景分割。本文采用马尔可夫随机场(Markov Random Field,MRF)优化DCNN获得的标签,进一步提高像素标签映射的精度,最终通过密集光流法对分割检测结果进行提取,提高目标边缘的检测准确率。
1 基于DCNN的特征提取
本文方法的核心思想是利用置信帧的高置信度调节DCNN模型。设Φ表示视频帧的索引集,Ω表示视频的弱标签集。采用预训练的DCNN模型θ处理各帧f∈Φ,使用SOFTMAX函数计算像素i属于类xi∈Ο的概率P(xi|θ),Ο表示目标与背景的集合。使用ARGMAX函数处理每个像素i,计算语义标签的映射S:S(i)=argmaxxiP(xi|θ)。
采用训练集Γ训练DCNN模型θ,选出全局CE帧与局部CE帧,计算标签映射Gg与Gl来建立自适应数据集。算法1为DCNN模型训练的伪代码,首先对S的每个标签映射进行连通区域分析(Connected Component Analysis,CCA),产生一个目标的候选区域集,记为R。然后评估目标的置信度C(Rk),Rk表示目标区域,k为区域的序号。C(·)算子的输入为一个标签映射,输出为标签映射中像素被设为目标的平均概率。
算法1DCNN模型训练
输入:θ,Ω。
/*θ为DCNN模型,Ω为弱标记集合*/
输出:θ′。
/*θ′为调节后的DCNN模型*/
1.d=0;
/*局部最优置信度*/
2.FOREACHf∈ΦDO
4. 计算P(x|θ),S=argmaxxP(x|θ);
5. 计算S中连接元素的集合R;
6. FOREACHRk∈R DO
7. IFC(Rk)>toTHEN
9. IF (S(i) ∈Ω&&i∉Rk)
14. IFfmodτb=0 THEN
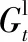
17.d=0;
/*d初始化为0*/
18.使用Γ将DCNN模型θ调节为θ′。
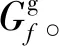
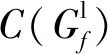
图1为线上程序的训练过程。对输入视频做预训练,选出长时(long-term)帧集与短时(short-term)帧集,对模型进行优化与调节。分别维护Γ的长时帧队列Tl与短时帧队列Ts,Tl保存τl的全局CE帧,Ts保存τs的局部CE帧,Tl队列的优先级高于Ts队列。Tl、Ts作为自适应数据集,更新模型θ的参数。
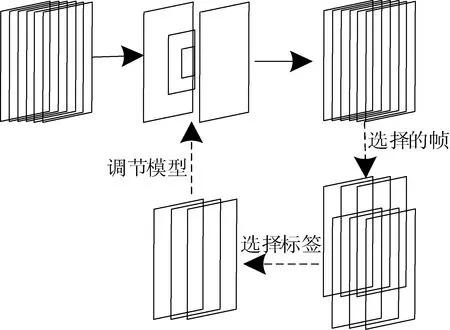
图1 线上程序的训练过程
2 基于马尔可夫模型的目标分割
DCNN的输出还不足以准确提取出目标,采用马尔可夫模型[10]将前景目标与背景分割。
2.1 目标分割的上下文模型
视频的前景分割方案大多采用固定的掩膜来提取局部特征,估计出超像素的标签,然后通过MRF对标签作平滑处理,所以超像素的分割效果高度依赖超像素的形状与大小。为了解决该问题,考虑多个超像素分割可提高超像素的标签准确率,为此设计了“多假设”MRF模型。
为局部上下文引入邻接超像素的邻居,同时引入相交超像素的邻居,这两种超像素邻居有助于融合多个超像素的不同描述符。MRF模型同时描述了超像素内部与超像素外部的上下文信息,内部邻居包含了给定超像素的相邻超像素,外部邻居包含了给定超像素的相交超像素。采用MRF模型编码内部邻居与外部邻居的上下文约束条件,以提高超像素标签的一致性。
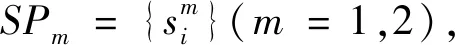
(1)
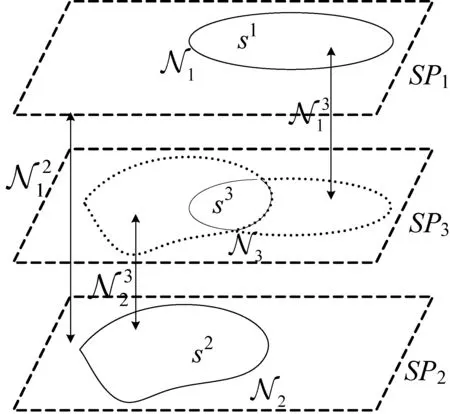
图2 超像素的MRF模型示意图
(2)
(3)
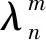
2.2 基于多假设MRF模型的目标分割
MRF模型的数据成本D(si,c)定义为超像素si的类标签为c的置信度,平滑成本E(ci,cj)定义为两个相邻超像素标签分别为ci和cj的概率。DCNN的输出为视频帧的像素类标签映射,将类标签相同的相邻像素划分为同一个超像素。然后将超像素的强度值设为该超像素中所有像素的平均强度值,基于平均强度定义MRF模型的数据项。图3为超像素均值化处理的结果图。

图3 超像素均值化处理的结果
SP1与SP2的平滑处理成本依赖标签的共生概率,定义为:
E(ci,cj)=-log[(P(ci|cj))+P(cj|ci)/2]δ
(4)
式中:P(ci|cj)是某个超像素标签为ci同时其邻居标签为cj的条件概率,如果ci=cj,δ则设为0,否则为1。
(5)
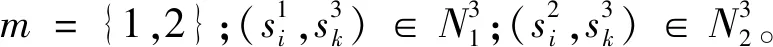
(6)
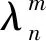
2.3 MRF的数据成本定义
MRF模型的平滑常量集为{l×λ|l∈{0,1,2}; 5≤λ≤25,λ∈Z}。函数g设为g(x,y)=0.5x+0.5y,SP3的数据成本定义为:
(7)
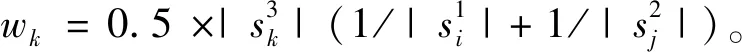
3 计算密集光流与后处理
计算三个连续帧的光流,首先使用高斯滤波器过滤每帧的噪声,计算当前帧与前一帧之间的光流,记为OF1,当前帧与下一帧之间的光流,记为OF2,两个光流融合为稠密光流,将OF1与OF2线性组合为每帧的总光流。图4为计算密集光流的流程图。
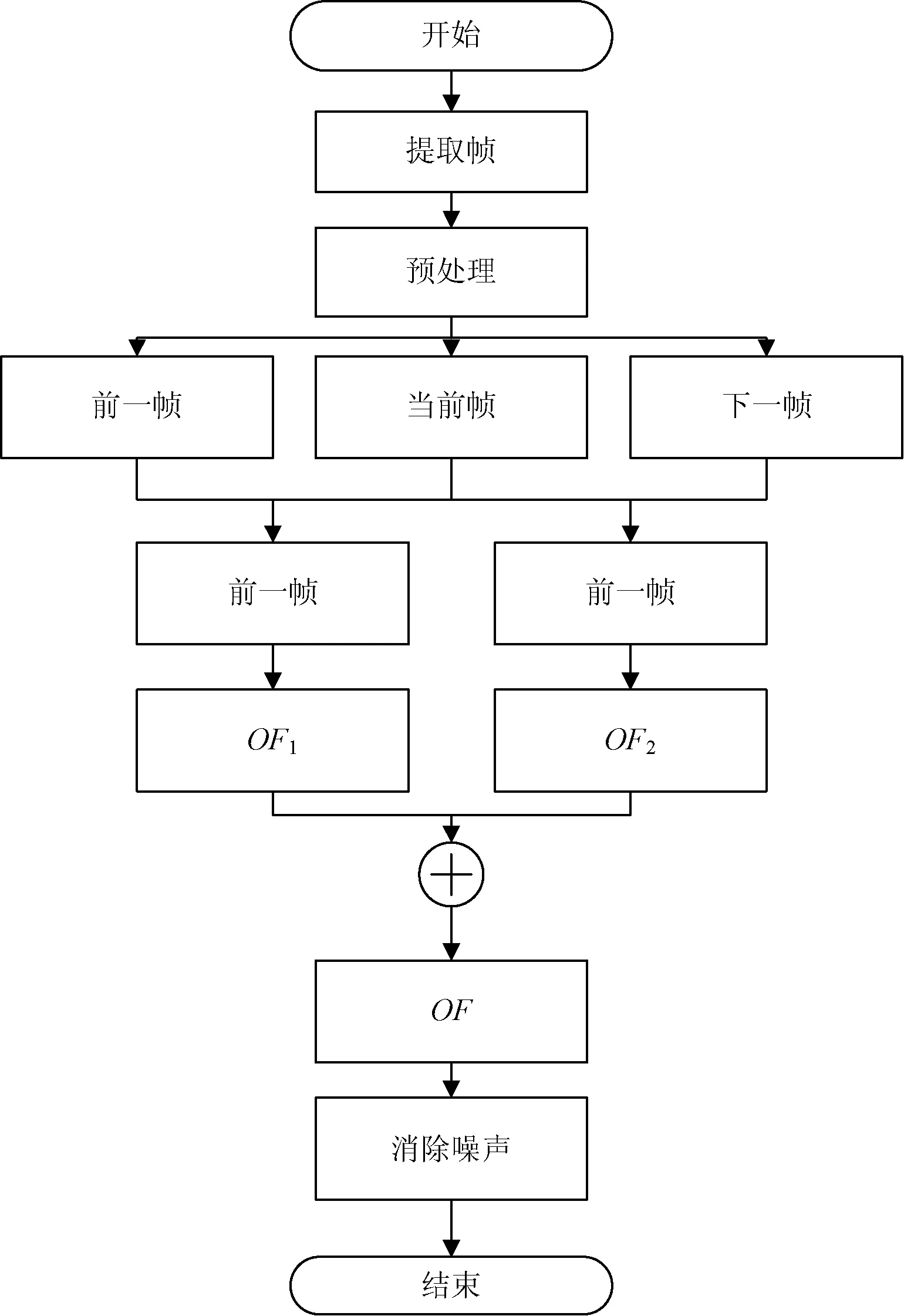
图4 计算密集光流的流程图
3.1 计算光流
假设亮度恒定,可得:
Ft=i(x,y)=Ft+Δt(x+Δx,y+Δy)
(8)
式中:(x,y)为像素的位置;(x+Δx,y+Δy)为Δt时差的帧坐标;Ft=i与Ft+Δt为时差为Δt的两个帧。将式(8)作泰勒级数展开,忽略其高阶项,可得:
本研究组前期研究显示结直肠癌患者中伴发高血糖者占29.67%,其中伴发糖尿病者占14.83%[6]。本研究显示,109例结直肠癌患者中血糖正常者占结直肠癌患者总数的68.80%,高血糖状态者占31.19%,其中并发糖尿病者占16.51%,本研究结果与前期报道基本一致。
(9)
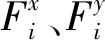
式(9)为光流的约束条件,为了获得光流问题的唯一解,需要对ui和vi增加其他光滑约束条件,结合灰度最小化与光滑约束条件估计光流域:
(10)
式中:参数α负责调节光滑度。将Ei最小化,可得:
(11)
(12)
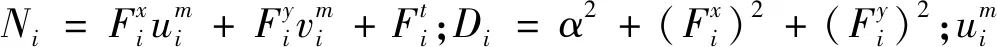
(13)
(14)
3.2 基于自适应阈值的降噪处理
因为计算光流的处理中包含不同的处理,所以上述总光流依然含有噪声。前景与背景的分割受噪声的影响较大,采用自适应阈值机制降低噪声的影响。
Otsu方法[13]是一种全局优化的自适应阈值降噪算法,该方法最小化类内方程、最大化类间方差。帧的像素强度Fi(x,y)范围设为0~L-1,设nj是灰度为j的像素数量,n为帧Fi的像素总数量。灰度j的概率定义为:
(15)
如果一个帧分为两个类D0和D1,D0和D1的像素灰度范围分别为[0,th-1]和[th,L-1],其中th表示像素的分类阈值。设C0(th)和C1(th)表示累加概率,μ0和μ1分别表示D0类和D1类的平均强度。
(16)
(17)
平均灰度值μth计算如下:
μth=C0(th)μ0+C1(th)μ1
(18)
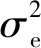
(19)
通过最大化类间方差估计0~L-1范围的最优阈值:
(20)
(21)
(22)
3.3 均衡化处理
第i帧的密集光流可表示为:
(23)
图5(a)和图5(b)是两个连续的视频帧,图5(g)是两个连续帧之间的光流图。图5(c)和图5(d)是未进行降噪处理和均衡化处理的目标分割结果,图5(e)和图5(f)是完成降噪处理和均衡化处理的目标分割结果。

图5 密集光流法与均衡化处理的结果图
4 实 验
4.1 benchmark数据集与镜头预处理
采用traffic数据集(https://vid.me/videodata)、walking数据集(https://vid.me/videodata)和Youtube-Object-Dataset数据集(https://data.vision.ee.ethz.ch/cvl/youtube-objects/)作为benchmark数据集。walking数据集是一个行人识别的数据集,traffic数据集是一个交通监控的多目标数据集。Youtube-Object-Dataset数据集是一个大规模的视频数据集,共有10个目标,每个目标包含9~24个视频。Youtube-Object-Dataset数据集包含正定的前景提取结果,可用作分析检测目标与正定目标的重合程度。
将每个视频分为若干个镜头,每个镜头包含相同的目标与不同的背景。对视频的镜头进行预处理,首先将每个视频帧的长边剪切为500像素,然后通过反射处理将视频帧放大至900×900像素。
4.2 实验环境与性能评价指标
实验环境为Intel (R) Core (TM) i7-4770 CPU@3.40 GHz处理器,8 GB内存。基于Caffe Library[14]实现DCNN模型,基于MATLAB编程实现目标检测算法。ODVT[15]是基于原卷积神经网络的目标检测技术,CSFDV[16]是一种基于压缩感知的目标检测技术,这两种技术在前景检测的准确率上取得了较大的进步,将本文算法与这两个算法进行横向比较。
算法的参数设为:阈值to=0.75、tb=0.8,背景值设为略高于前景,留出空间以保留目标周围的像素。局部时间设为τb=30、τs=5、τl=10。DCNN的学习率为0.001,动量为0.9,权重衰减为0.000 50。
采用FPR、TPR、精度和F-Score作为目标检测的性能指标,定义如下:
(24)
(25)
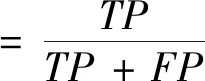
(26)
(27)
式中:FP为假正率;TN为真负率;TP为真正率;TPR为召回率。
Intersection-Over-Union(IOU)定义为系统预测的目标与正定目标的重合程度,计算方法为检测结果与正定值的交集除以两者的并集,该指标能够精细地评估目标检测的准确率。
4.3 实验结果与分析
4.3.1walking与traffic数据集的实验结果
图6、图7分别为3个目标检测算法对于traffic和walking数据集的实验结果,traffic和walking 2个数据集均为运动目标的数据集,本文算法对于3个数据集均实现了较好的检测准确率和较低的误检率。
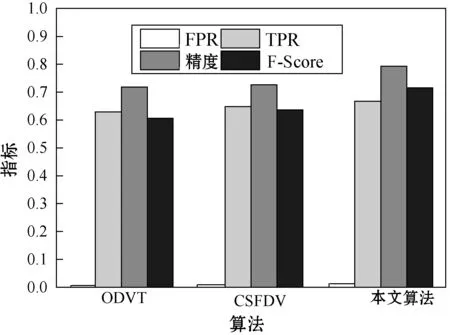
图6 traffic数据集的性能结果
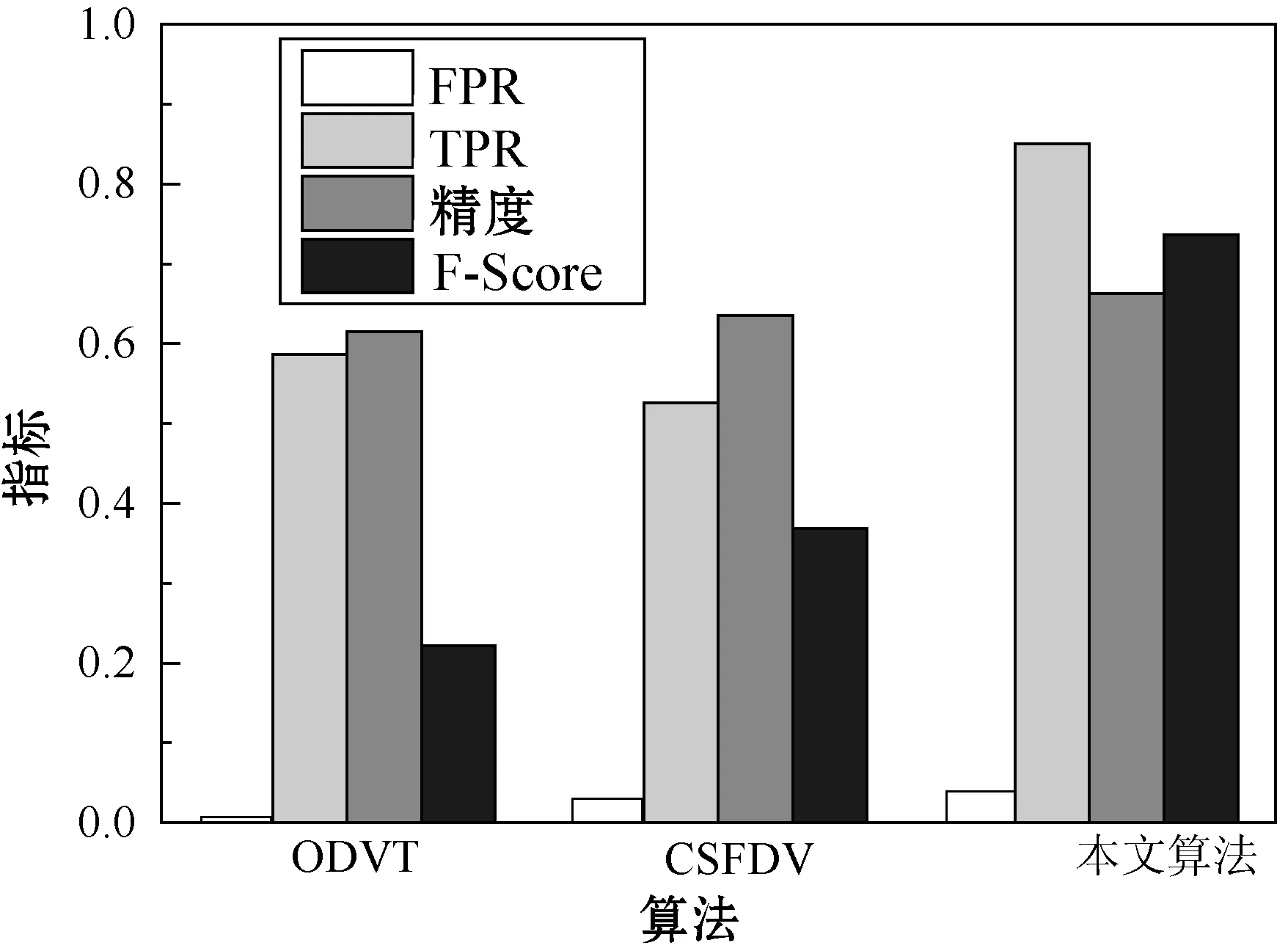
图7 walking数据集的性能结果
图8、图9分别为3个目标检测算法对于traffic和walking数据集的前景提取实例。3个算法虽然均检测出traffic数据集中的车辆,但是对车辆的分割结果多有缺失,而本文算法提取的前景目标较为准确,并且保留了较为完好的轮廓。


图8 traffic数据集的前景提取实例

图9 walking数据集的前景提取实例
4.3.2Youtube-Object-Dataset的实验结果
为了进一步观察本文算法对于目标提取的细节保留效果,基于Youtube-Object-Dataset数据集进行了实验。图10为Youtube-Object-Dataset数据集的实验结果,本文算法对于Aero的检测率低于其他2个算法,但其他9个目标的效果均明显高于其他2个算法,原因是Aero目标移动速度较快,本文算法的提取效果较差。
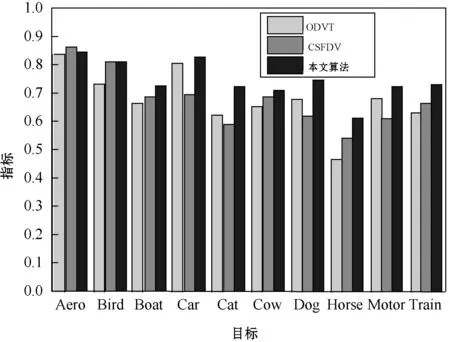
图10 Youtube-Object-Dataset数据集的实验结果
图11为Youtube-Object-Dataset数据集的分割实例图,(a)、(d)、(g)、(j)、(m)为ODVT算法的结果,(b)、(e)、(h)、(k)、(n)为CSFDV算法的结果,(c)、(f)、(i)、(l)、(o)为本文算法的结果。可看出本文算法对于不同数据集的分割准确率较高,对于目标轮廓的提取更为细致。

图11 3个目标检测算法对Youtube-Object-Dataset的分割结果
5 结 语
为了提高视频目标检测的边缘准确性,提出一种基于卷积神经网络和马尔可夫随机场的视频目标检测算法。采用置信帧对预训练的DCNN模型进行优化调节,提高模型的性能,采用马尔可夫模型将前景目标与背景分割,采用马尔可夫随机场优化DCNN获得的标签,进一步提高像素标签映射的精度。本文算法对视频目标边缘分割的准确率较高,可用于机器人等对精度要求高的领域。本文算法的DCNN模型训练的时间复杂度较高,基于GPU可实现较快的处理速度,未来将关注于提高算法的时间效率,进一步提高算法的实用性。
