融合LDA主题模型和二维卷积的短文本分类
2020-11-12郑山红李万龙
康 宸 郑山红 李万龙
(长春工业大学 吉林 长春 130012)
0 引 言
文本分类的相关工作可以追溯到20世纪50年代,在自然语言处理中,文本分类是一项重要的研究内容,被广泛应用于Web搜索、日志分析、信息过滤、情感分析等领域[1]。随着移动互联网的发展和社交媒体的兴起,短文本数据规模急速增长,如何利用短文本进行高效准确的分类变得尤为重要。不同于长文本分类,短文本分类由于短文本字数限制,不能够充分挖掘短文本序列信息,提取出有利于分类的特征,因此往往导致短文本分类的效果不佳。
传统的统计学习方法在处理文本分类任务中大致分为文本预处理、特征提取、文本表示、分类器四个部分。文本预处理是在文中提取关键词表示文本的过程。常见的特征提取方法有通过选定阈值来筛选特征的统计方法,比如统计文档频次的DF方法[2]和信息增益方法(IG)[2]等,这些方法由于采用统计的方式对文本特征进行提取,所以并不适用文本字数少的短文本。传统的文本表示方法包括词袋模型和向量空间模型,它们最大的不足就是认为文本中每一个单词都是彼此独立的,单词之间不包含任何语义信息,这就导致短文本的文本表示维度高且稀疏。分类器应用改进的统计机器学习算法,如CRS-KNN[3]等。
随着深度学习的发展,文本分类不再需要繁琐的特征提取,而是由深度学习参数自动拟合,利用一维卷积或LSTM等网络结构自动提取特征表达,实现端到端的学习方式。不同于LSTM保留提取文本的全部序列信息,一维卷积能够根据filter来学习局部序列信息,因此一维卷积在对n元语法敏感的分类任务上表现尤为突出[4],比如基于一维卷积神经网络和KNN短文本分类,应用卷积神经网络对短文本进行特征提取,然后应用KNN算法进行分类[5]。但是在短文本中局部序列的数量少并且每个词项缺乏语义以及主题信息,往往会导致一维卷积在处理短文本时分类特征挖掘不充分。因此,为补充短文本语义和主题信息,引入LDA[6]预训练好的主题词项分布和Word2vec[7]预训练通用语义词向量分布。通过将它们与随机初始化的词向量拼接来表示短文本特征,弥补了一维卷积在处理短文本中分类特征不足的问题,并且引入了短文本的主题信息和语义信息。
1 相关工作
1.1 预训练LDA主题模型
主题模型是对文字中隐含主题的一种建模方法。主题可以看成是词项的概率分布,主题模型通过词项在文档级的共现信息抽取语义相关的主题集合,并能够将词项空间中的文档映射到主题空间,得到文档在低维空间中的表达[8]。Blei等[6]提出了基于贝叶斯思想的LDA主题模型,在原有的pLSI的基础[9]上加上两个先验Dirichlet分布,这样就可以不断修正之前的参数估计,从先验分布逐渐过渡到后验分布。
参数估计方法有变分贝叶斯推断以及Gibbs采样等方法。本文采用Gibbs采样的方式,每次对联合分布的一个分量进行采样,保持其他分量不变。经过推导最终采用Gibbs求解LDA主题模型,其计算公式为:
(1)
1.2 预训练词向量模型
采用Python第三方开源工具包Gensim的Word2vec模块来训练通用语义词向量,设置的窗口较小易于产生更多功能、句法和语义相似性,如果设置的窗口较大则易于产生更大的主题相似性。
2 融合LDA主题模型和二维卷积
由于深度学习是一种特征表示的学习方式,能够通过端到端的学习,通过参数拟合来提取特征,所以应用深度学习解决短文本分类任务,主要包括文本表示、特征提取、分类器三个部分。本文提出的两种模型主要区别在于文本表示和特征提取部分,所以本文主要从文本表示和特征提取两个角度介绍这两种模型。为了叙述方便,下面将两种模型分别记为CTC1和CTC2。
2.1 文本表示
在自然语言处理的任务中加入词向量不仅可以使词项的特征维度降低,而且词向量中的每个维度都表达某一种语义信息。在实际应用中有两种方式获取词向量:(1) 在模型中键入词嵌入层,通过数据来学习和任务相关的词向量,即随机初始化词向量方式;(2) 加载预训练词向量,通过数据来学习与任务相关的词向量,为模型补充通用的语义信息。
由于短文本有效词项数量较少,导致短文本提供的语义信息和主题信息匮乏,这也是导致相同模型在短文本上分类效果不如长文本分类效果好的主要原因之一。
从预训练LDA主题模型中获得主题词项分布β,将β映射到短文本分类样本的词汇表中,得到短文本词项关于主题信息的词向量。同理,从预训练Word2vec中获取在小窗口上训练得到通用语义的词向量。随机初始化的词向量虽然增大了模型的容量,但是由于随机初始化的词向量会根据样本数据学习到与任务相关的知识,因此会为短文本补充不同于主题与通用语义的其他信息。
2.1.1CTC1拼接成三通道的文本表示
二维卷积在处理彩色图像时,将彩色图像看成是拥有RGB三种通道的像素矩阵,在图像中RGB三种颜色矩阵可以看成图像的三种不同表达。所以用于任务相关的随机初始化词向量矩阵、通用语义词向量矩阵,以及主题词项矩阵拼接成三通道,可以看作是对短文本的三种不同角度的表达,即从任务相关的语义、通用语义和主题三个角度。拼接成三个通道的短文本表示如图1所示。
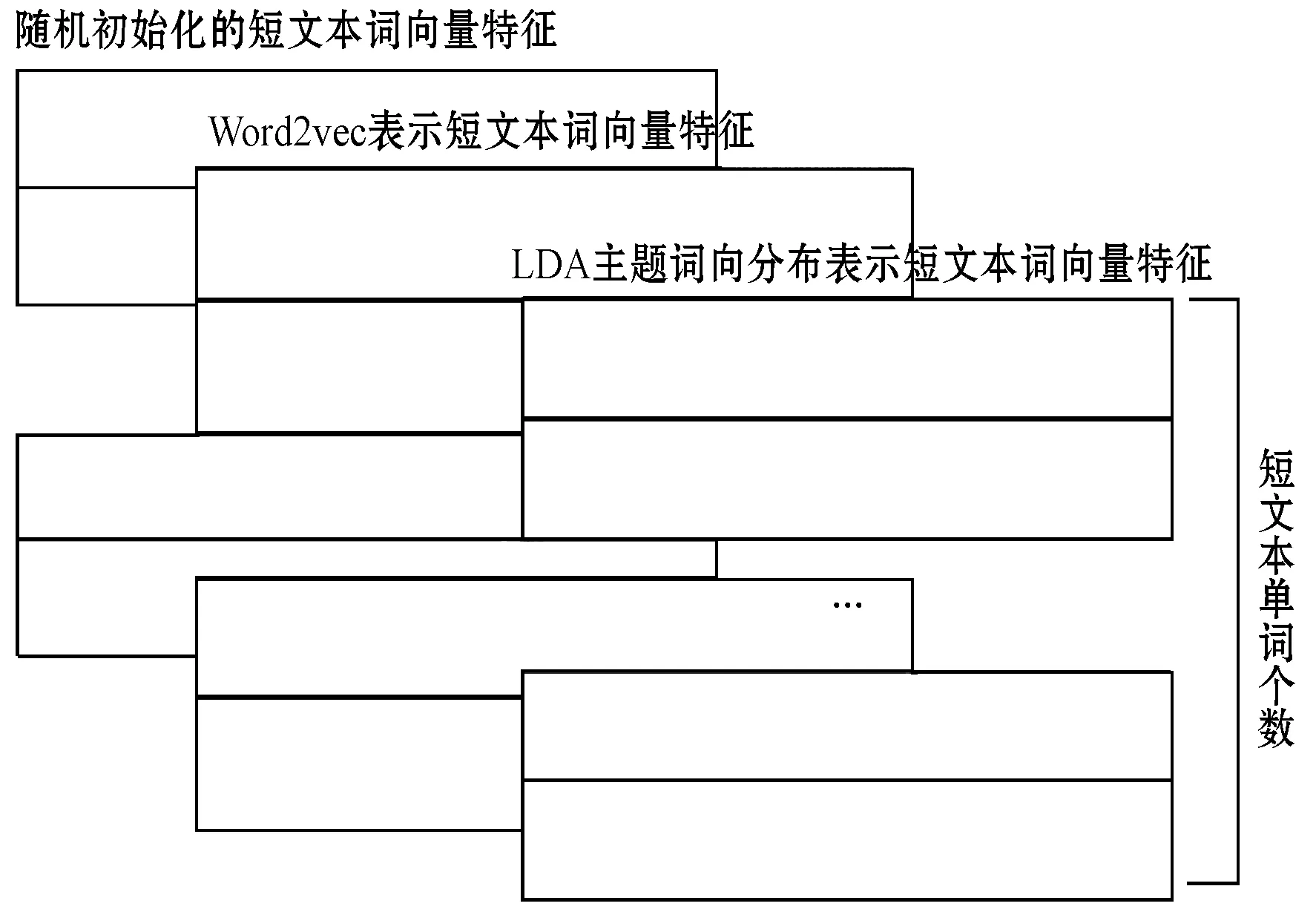
图1 拼接三通道的文本表示
2.1.2CTC2三个相互独立的文本表示
在自然语言处理中,单词的表示可以有很多种方式,每一个单词的表达方式都可以作为短文本的文本表示,即将含有任务相关的随机词向量、含有通用语义信息的词向量,以及主题信息的词向量看成短文本的三种不同文本表达方式,即看成独立的文本表示,如图2所示。
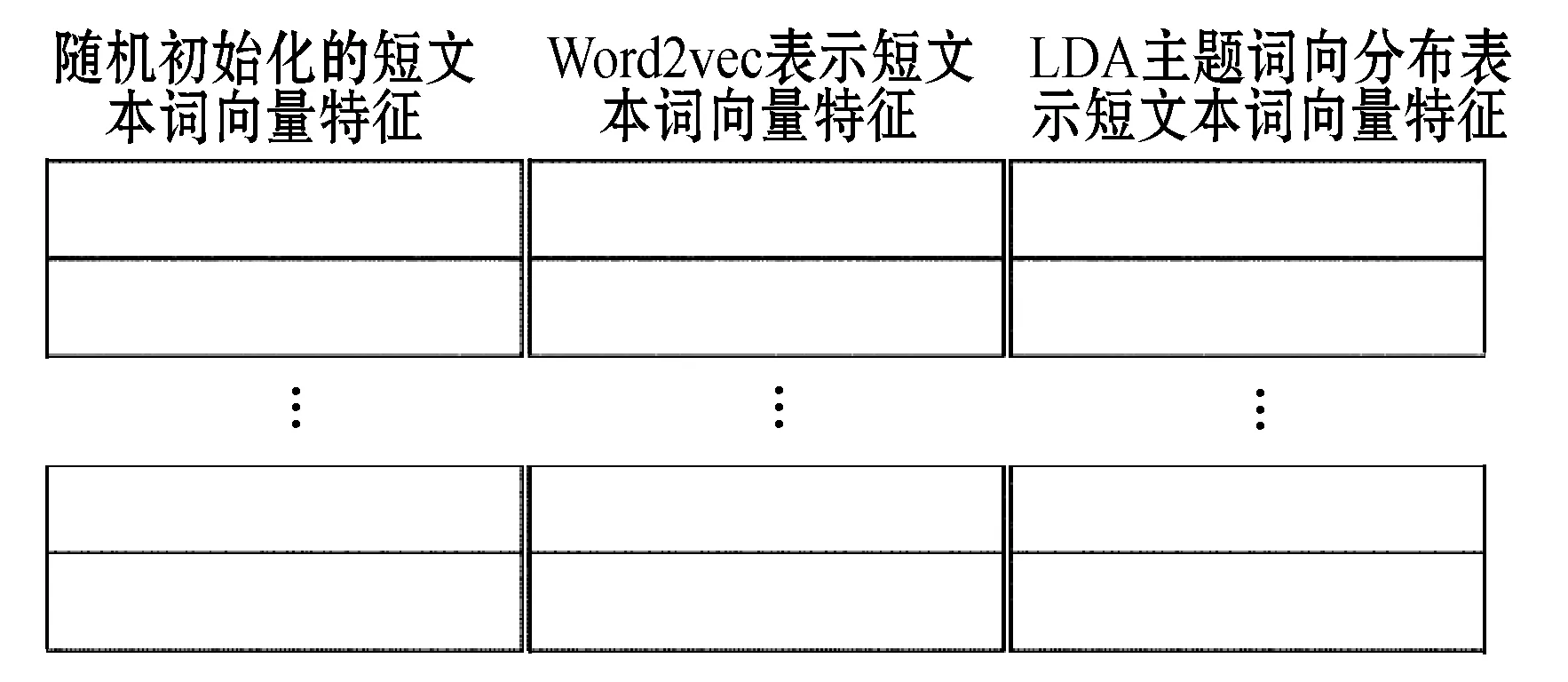
图2 三个独立的文本表示
2.2 特征提取
在文本表示阶段将短文本中随机词向量矩阵,通用语义词向量矩阵以及主题词项矩阵看成短文本的三个通道,从三个方面表达短文本;而另一种从文本角度将三个矩阵作为短文本三个独立的表达,因此在文本表示中产生了两种不同的文本表达方式。对于不同的文本表达,特征提取部分也会有所不同,下面是相应的两种模型对应的两种特征提取部分。
2.2.1CTC1二维卷积特征提取
将短文本表示成三个不同的通道,可以通过二维卷积直接在拥有的三通道的文本表示中进行特征提取,二维卷积的提出使得图像识别领域发展迅速,它不需要去查看整幅照片检测一个模式,只需要将模式应用到整幅图片的一个小部分;相同的模式可能出现在图片的不同区域;可以应用Max-Pooling来对图片进行分段采样。由于这些特点,使得二维卷积在处理图像这种高维度特征中大大节省了训练参数,提取到相对图像更有用的特征。
对于短文本分类任务,将短文本拼接成类似图像RGB的三维通道,可以将短文本分类任务迁移到图像识别的问题当中,虽然文本不完全具备图像的特点,但是对于拼接后的短文本来说,每一个通道的词向量的每一个维度都可能对最终的分类结果有影响。比如对于通用语义词向量来说,它的某一个维度可能携带与金融有关的信息,那么在进行二维卷积操作提取特征后,这一个维度会尤为的突出。同时文本分类任务中,完整的词序对分类任务不是很有帮助,但是连续的单词对会对文本分类任务有帮助,在二维卷积处理三通道短文本特征时,可以类似进行图像处理那样选定一个filter。因此使用二维卷积对拼接的三通道短文本进行卷积操作的时候,考虑的是filterwidth个向量维度特征和filterheight个连续单词对。
2.2.2CTC2一维卷积结合二维卷积特征提取
将三种短文本的特征表示看成是三个独立文本表示,因此可以认为是三种不同的短文本,此时需要使用不同的一维卷积分别对三种独立的文本表示进行特征提取,将经过不同的一维卷积提取到的三种不同独立文本表示的结果进行拼接。对于短文本,三种独立的文本对应位置表达的是短文本中相同位置的单词,所以将其拼接后的结果可以表示为相同单词的不同文本表达形式。对拼接后的结果进行二维卷积操作,此时的二维卷积由于经过一维卷积的处理,特征图的维度大大降低,因此训练的时间复杂度接近使用一维卷积模型。CTC2具体的特征提取过程如图3所示。
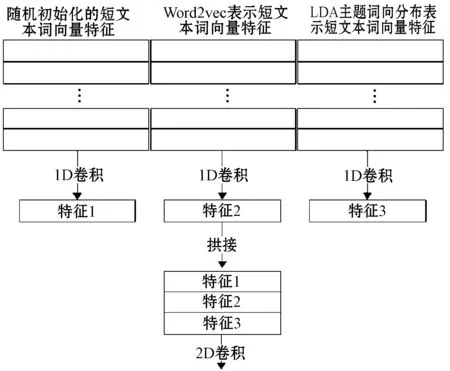
图3 1D卷积与2D卷积结合特征提取
3 实验分析
3.1 预训练模型
预训练LDA主题模型采用55 000条新闻文本数据集,为了得到更好的结果,主题个数设置为256,参数α=0.19、β=0.01,共计398 214个词项。迭代足够的次数得到主题词项分布β(256,398 214)以及文档主题分布θ(55 000,256)。
预训练词向量模型采用一个与任务相关的1.2 GB新闻数据集,为了得到更多包含语义信息的向量,设置窗口为3,采用CBOW模型,并且向量的维度设为256,迭代50次[10]。
3.2 实验数据
实验采用公开2012年6月—7月搜狗新闻数据集,从中提取出10个类别的47 300条数据作为训练集,7 700条数据作为验证集,10 000条数据集作为测试集,提取新闻标题作为短文本数据。
3.3 对比算法
本文提出的两种短文本分类模型为:CTC1将三个矩阵拼接成三通道的文本表示,并通过二维卷积进行特征提取;CTC2将三个矩阵看成互相独立的文本表示,通过一维卷积结合二维卷积进行特征提取。将提取的特征类比图像识别特征,应用图像识别模型框架进一步对文本特征进行提取分类。为了方便模型对比,将CTC1、CTC2两种模型添加不同模型架构记为CTC1-X、CTC2-X,其中X就是具体的图像识别模型框架。进行对比的分类算法有基本模型MLP、CNN、LSTM、Bi-LSTM、结构简单的fastText[11]、比fastText文本信息保留更好的Text-CNN[4],以及在Text-CNN基础上加上注意力机制的HAN[12]。
3.4 实验结果
由于短文本文本表示后的特征图比较小,所以此时的X使用了部分图像识别框架。实验对比了CTC1-VGG、CTC1-残差网络、CTC2-VGG、CTC2-Inception、MLP、CNN、LSTM、Bi-LSTM、fastText、Text-CNN和HAN等11种文本分类模型,不同模型在精度以及总训练时长上的对比如表1所示。
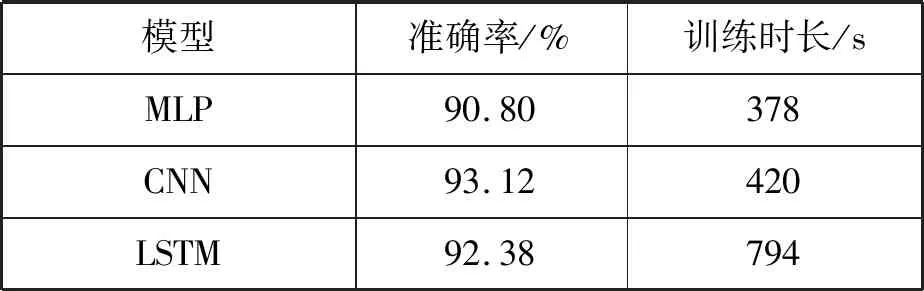
表1 不同模型在短文本分类上的对比(10 epoch)
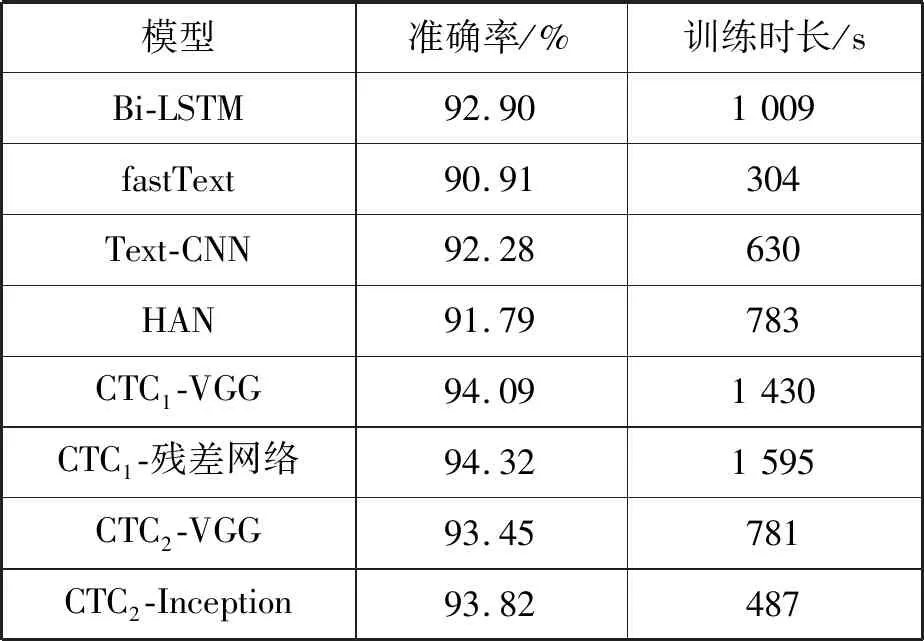
续表1
11种短文本分类算法在精度上的对比如图4所示。

图4 11种分类算法精度柱状图
可以看出,在11种分类算法中CTC1-残差网络在短文本的分类精确度最高,达到了94.32%,而最低的MLP为90.80%。在传统模型中一维卷积的准确度最高,因为一维卷积能够捕捉短文本中的局部序列信息,而这些局部序列信息有利于文本分类,但是由于短文本的局限性在更加复杂模型中短文本分类效果表现一般。此时的CTC1-X和CTC2-X两种短文本分类模型,弥补了一维卷积在处理短文本中分类特征不足的缺点,并且引入了短文本的主题信息和通用语义信息,虽然两种模型表现不一,但是都比在传统文本分类准确度最高的一维卷积模型效果要好。
11种文本分类算法总的训练时长对比如图5所示。
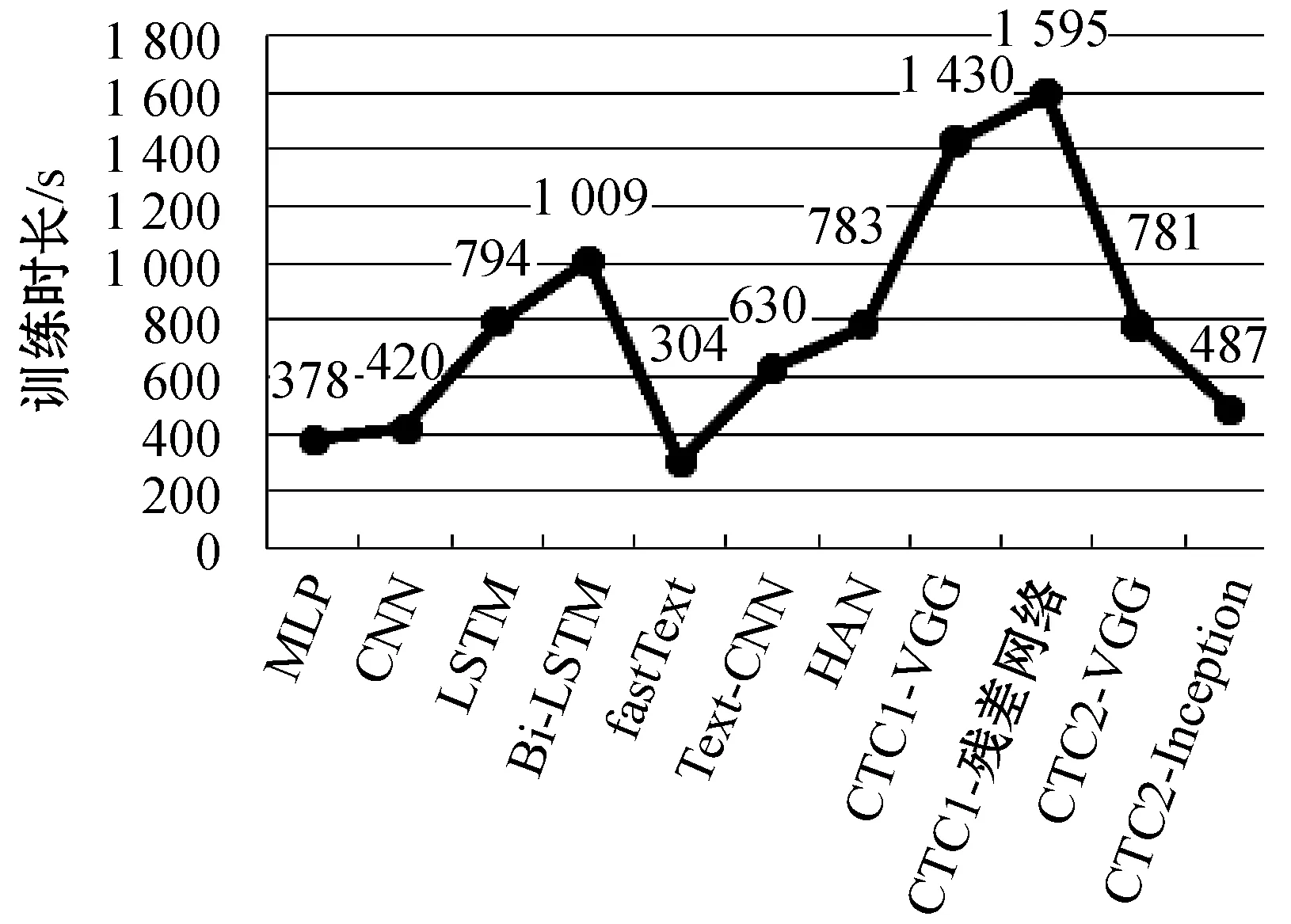
图5 11种分类算法总的训练时长
由于在传统文本分类中,短文本文本表示特征相对的维度比较低,因此在使用MLP、fastText等简单模型进行短文本分类时模型的参数不会太多,模型越简单,相应的模型训练时间就会越短。本文提出的两种短文本分类模型中CTC1-X由于先将短文本文本表示拼接成三个通道,二维卷积对三个通道进行卷积操作的效率比较低,因此CTC1-X模型是这11个模型中效率最低的。第二种方案由于先将短文本表示经过一维卷积进行特征提取,然后进行拼接,降低了特征的维度,同时得益于图像识别领域的一些提高效率的模型架构,使得CTC2-X模型在短文本分类效率接近一维卷积模型。
本文提出的模型CTC1-X虽然在效率上比较低,但是在短文本分类的准确度是最高的,而第二种模型CTC2-X虽然在短文本分类的准确度上没有CTC2-X模型高,但是在效率上接近一维卷积。
保存CTC2-Inception模型作为代表,通过可视化卷积中间层的方式,将拥有通道的短文本矩阵类比成图像,使用“名师 支招 英语 四级 考前 30天 备考 计划 临近”作为模型的输入,CTC2-Inception三个独立通道中间激活值输出如图6所示。

图6 CTC2-Inception三个独立通道中间激活值输出
CTC2-Inception最后一层多通道矩阵输出如图7所示。
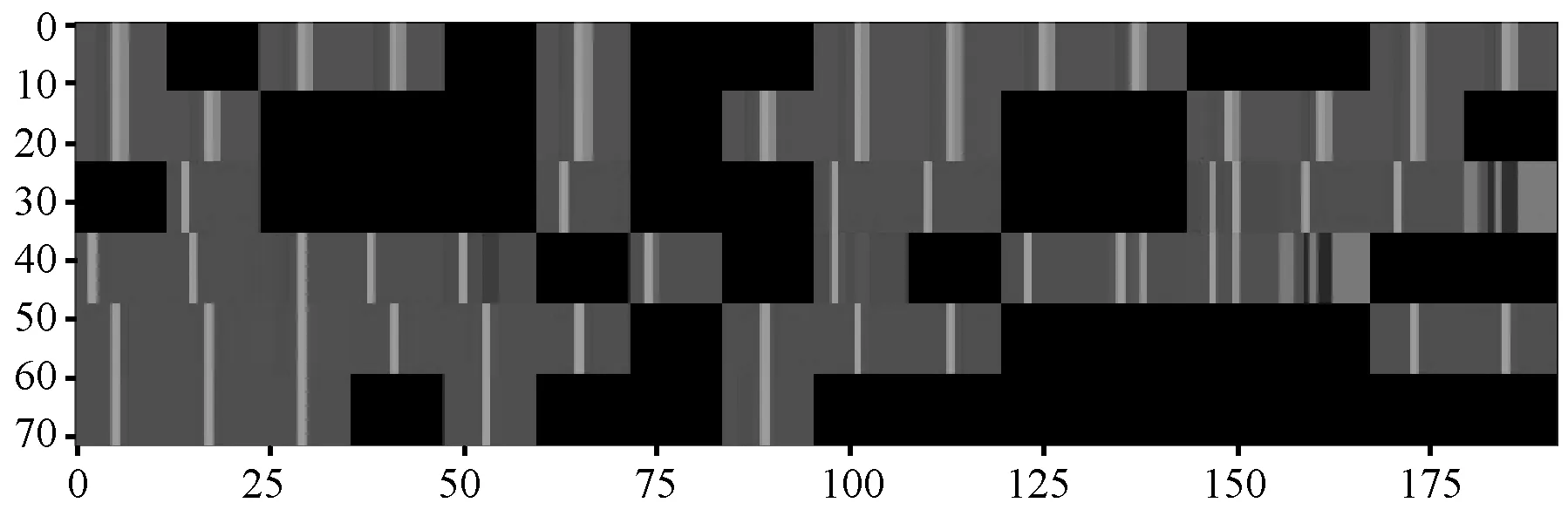
图7 CTC2-Inception最后一层多道中间激活层输出
CTC2-Inception是将随机初始化词向量、通用语义词向量、包含主题信息的词向量看成三种不同的文本表示,通过三个独立的一维卷积进行特征提取,将提取的三个独立特征拼接成单通道的文本特征图。最后应用Inception结构来对单通道文本特征图进一步提取特征并分类。
由图6可以看出,在通用语义词向量和主题词向量特征提取结果中大部分为非黑色的区域,因为此时保留了大部分原始文本的信息。有效的信息大多呈现块状,此时模型学习到的是一些向量的某一些维度信息,这些维度信息对文本分类有帮助,这也说明了二维卷积对这些拼接的文本表示向量进行卷积操作的可行性。随着模型层数的加深,更高层所提取的特征变得越来越抽象。从图7可以看出,大部分通道的激活为黑色,此时更高的层包含的关于特定文本输入的信息越来越少,通道中包含信息的部分有条状区域,这些条状区域是最终帮助文本分类所抽象出来的编码模式。
4 结 语
将通用语义词向量以及主题词向量引入短文本中为短文本补充通用语义以及主题信息来弥补短文本字符少、可用信息少的缺点。通过将文本表示看成拥有通道的图像,将自然语言处理问题转换为图像识别问题,可以通过更加成熟的图像领域的解决方案来解决自然语言处理中的问题。虽然应用二维卷积能够提高对应短文本分类的精度,但是其通过卷积的过滤器不像图片那样拥有很好的解释性。在对短文本进行文本表示的时候,不论是第一种模型还是第二种模型,进行二维卷积操作的特征图都比较小,所以在使用二维卷积进行提取特征时,往往不能够使用更深的网络结构进行特征提取,使得模型不能够有足够的容量来学习提取特征。接下来的工作主要是提高模型的表达能力,使其具有更强的特征提取能力。
