基于时空信息融合的时序动作定位
2020-11-11范冬艳
王 倩, 范冬艳
(上海工程技术大学 电子电气工程学院, 上海201620)
0 引 言
随着计算机视觉等相关技术的发展,深度学习已经在视频动作识别领域[1-5]取得了巨大成果。 但是实际应用中的视频通常是不受约束的,包含多个动作实例和背景场景或其他活动的视频内容。 时序动作定位是一个重要而又具有挑战性的问题,给定一个包含多个动作实例和背景内容的长而未修剪的视频,不仅需要识别它们的动作类别,还需要定位每个实例的起始时间和结束时间。
许多先进的系统使用段级分类器来选择和排列预先设定边界的建议段[6-9]。 然而,一个理想的模型应该超越节段的级别,在细粒度的时间尺度上进行密集的预测以确定精确的时间边界。 例如SCNN[6]的C3D 卷积神经网络[3]从conv1a 到conv5b层,将输入视频的时间长度减少了8 倍。 为此,Zheng Shou 等设计了一个新的convolutional-deconvolutional(CDC)网络[10],该网络的顶部是一个C3D 卷积神经网络用于提取视频的时空特征信息,用来判断动作类型。 然后采用CDC 过滤器同时执行所需的时间向上采样和空间下采样操作,以在帧级粒度上预测动作。 CDC 网络不仅在每一帧检测行为上实现性能优越,同时也显著提高了时间边界的精确性。 但是CDC 网络在候选区域的选取算法和时间边界的定位上还有待提高,主要有两个问题:(1)CDC 进行时序动作定位预测的输入为原始视频的候选片段,候选片段的选择会影响到时序动作识别的效果和效率,若识别不准确,不仅影响识别结果的准确率,还会耗费时间去识别不准确的候选区域。S-CNN 建议片段选择算法将密集间隔采样的RGB图输入C3D 卷积神经网络进行预测,没有充分利用视频的时空特征。 (2)结合候选区域与帧级分数并利用阈值定位边界点可以得到最终的时序动作检测结果。 然而,检测得到的动作的起始和终止坐标与真值之间还有着较大的偏移。 基于以上两个问题,本文提出了时空特征融合时序动作定位模型(spatio-temporal feature fusion temporal action localization model,STFF-CDC)。
针对问题1,为了充分融合视频中的时空信息,并以相当低的成本保存相关信息,文献[11]在TSN网络的基础上,结合C3D 卷积神经网络,提出了时空特征融合动作识别模型。 该模型能够充分利用视频的时空特征,有效且高效的识别视频的动作类型。将该模型用于候选区域的选择网络,可以充分融合视频的时空特征,提高候选区域提取的准确率。
针对问题2,为了解决定位的动作起始和终止坐标与真实值存在较大偏移的问题,本文提出了一个动作起始终止状态判断网络。 将检测结果的时间区域扩大,之后再用起始点和结束点周围的帧为数据集训练DenseNet 网络[12],利用训练好的模型判断起始帧和结束帧,从而重新定位得到更加精确动作起始边界。
1 相关工作
1.1 RGB 图和光流图
视频的RGB 图像使3 个颜色通道(红色R,绿色G和蓝色B 来存储像素信息,这些像素信息包含了视频的外形信息,如图1(a)所示。 由于视频的动作识别与视频中某些对象密切相关,外形信息是动作识别的重要信息,因此RGB 图像可以提取视频的空间特征。
光流场是指图像中所有像素点构成的一种二维瞬时速度场,其中的二维速度矢量是景物中可见点的三维速度矢量在成像表面的投影。 所以光流不仅包含了被观察物体的运动信息,而且还包含有关景物三维结构的丰富信息[13]。 视频的光流图包含了视频的运动信息,如图1(b)、1(c)所示, 分别为水平方向(x 方向)和垂直方向(y 方向)光流图样例。

图1 披萨抛掷类的RGB 和光流图示例Fig. 1 Examples of RGB and optical flow images for pizza thrower classes
1.2 时序动作检测
时序动作检测任务的目的是识别一段未剪辑长视频中的动作类别以及动作的起止时间。 近年来,出现一些方法用于时序动作定位任务。 S-CNN 是较为典型的一种方法,S-CNN 框架主要分为多尺度段的生成、Segment-CNN、后处理3 个部分,Segment-CNN 包括建议网络,分类网络和定位网络3 个子网络,均使用了C3D 卷积神经网络。 建议网络是提取候选区域的网络,它的输出为两类,即预测该片段是动作的概率及是背景的概率;分类网络的作用是尝试做一个用来识别动作的种类的分类网络,为定位网络做初始化;定位网络的输出为K + 1 个类别(包括背景类)的分数,这个分数是该segment 是某类动作的置信度分数。 后处理是在测试阶段进行的,具体方法是对定位网络的输出分数进行非极大化抑制(NMS)来移除重叠,对于时序上重叠的动作,通过NMS 去除分数低的,保留分数高的。 CDC使用的候选区域选择算法是S-CNN 建议网络的候选区域提取算法,即改进C3D 卷积神经网络的SoftMax 层进行候选区域的判定。
2 基于时空信息融合的时序动作检测网络
2.1 网络整体框架
改进的CDC 卷积神经网络训练时的输入为带有帧级标签的窗口训练集,预测时的输入为经过基于特征融合的候选片段生成算法生成的建议片段。接着经过3D 卷积神经网络进行语义特征提取,这时视频的时间维度会缩小为L/8。 为了恢复时间维度上的信息,来进行帧级粒度上的动作识别,再经过3D 反卷积神经网络来对视频的时间维度进行上采样,空间维度进行下采样。 输出每帧的动作类别分数,最后训练动作状态检测网络进行时间边界的调整。 框架流程见下图2 所示。
2.2 动作候选区域提取算法
2.2.1 S-CNN 候选区域提取算法
S-CNN 候选区域提取算法使用Du Tran 等[3]提出的C3D 卷积神经网络作为动作分类网络,C3D卷积神经网络与2D 卷积神经网络不同,它有选择地兼顾运动和外观。 在跳高的例子中,特征先是集中在整个人身上,然后跟踪其余帧上的人体跳高的动作。 同样在化唇妆例子中,它首先聚焦在嘴唇上,然后在化妆时跟踪嘴唇周围发生的动作。 C3D 卷积神经网络不仅对空间的的水平和竖直维度进行卷积,对时间维度也进行了卷积,以更好地提取时间和空间特征,保持时空特征的相关性。
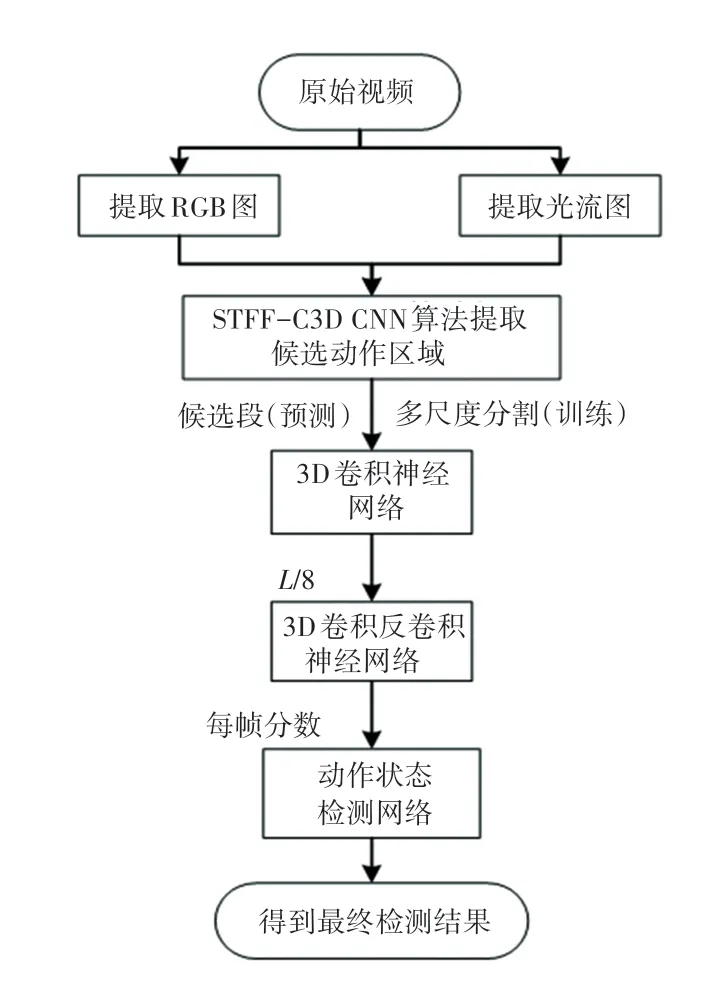
图2 时空融合时序动作检测网络框架图Fig. 2 Spatio-temporal feature fusion temporal action detection network frame diagram
S-CNN 采用的C3D 网络结构如下图3 所示。共具有8 个卷积层、5 个池化层、两个全连接层,以及一个softmax 输出层。 所有3D 卷积滤波器均为3×3×3,步长为1×1×1。 为了在时间维度不过早的进行压缩,pool1 核大小为1×2×2、步长1×2×2,后面所有3D 池化层均为2×2×2,步长为2×2×2。 每个全连接层有4 096 个输出单元。 C3D 最终通过softmax 层给出视频样本的分类。 S-CNN 候选区域提取算法具体流程图见图3。

图3 S-CNN 候选区域提取算法训练测试过程Fig. 3 Training and testing process of S-CNN candidate region extraction algorithm
2.2.2 STFF-C3D CNN 候选区域提取算法
深度学习进行人体动作识别需要充分提取视频中的时间特征和空间特征,并合理的利用时空特征之间的相关性。 为此,文献[11]提出一种采用稀疏采样方案的时空特征融合动作识别框架STFF-C3D CNN(spatio-temporal feature fusion action recognition model,STFF-C3D CNN)。 该模型不仅充分融合了视频中时空特征,并且运用稀疏采样方案[5]避免了冗余采样。 主要分为4 部分:稀疏采样生成RGB 图和光流图、时空特征的提取、时空混合特征图的生成、C3D 卷积神经网络进行动作识别,如下图4 所示。

图4 STFF-C3D CNN 框架Fig. 4 STFF-C3D CNN frame
在预测阶段,建议片段(含有动作的片段)选择会影响到时序动作识别的效果和效率,若识别不准确,不仅影响识别结果的准确率,还会耗费时间去识别不准确的建议片段。 本文提出的时空信息融合的时序动作检测网络采用STFF-C3D CNN[11]进行建议片段的选择,可以充分融合候选片段的时间特征和空间特征来进行动作识别。
首先,采用稀疏采样方案对视频进行采样。 一个输入视频被分为K 段(segment),一个片段(snippet)从它对应的段中随机采样得到。 对于每段snippet,提取它包含空间信息的RGB 图像和包含时间信息的x 方向光流图和y 方向光流图。 接着,将RGB 图送入空间卷积神经网络进行训练以提取中层空间特征,将光流图送入空间卷积神经网络进行训练以提取中层时间特征。 然后,训练时空混合卷积神经网络提取时空融合特征,将时空中层特征图进行融合[14],提取混合卷积神经网络的中层混合特征,生成时空混合特征图。 最后,将时空混合特征图作为C3D 卷积神经网络的输入,在时间和空间维度分别进行卷积和池化,同时学习视频的运动信息和静态的图片信息,修改STFF-C3D CNN 的输出为两类,即预测该片段是动作的概率以及是背景的概率。训练时将IoU 大于0.7 的作为正样本(动作),小于0.3 的作为负样本(背景),对负样本进行采样使得正负样本比例均衡,采用softmax loss 进行训练来判断动作类别。
2.3 3D 卷积反卷积神经网络
C3D 架构,由有3 层全连接(FC)层的三维卷积神经网络组成,在诸如识别和定位等视频分析任务中取得了良好的结果。 CDC 网络是基于C3D 卷积神经网络构成的,C3D 的conv1a 到conv5b 是CDC网络的第一部分,对于C3D 的其余层,CDC 保持pool5 在长度和宽度上执行步长为2 的最大池化,但保留了时间长度。 按照常规设置[3,6,15],设置CDC网络输入的高度和宽度为112×112,输入时间长度为L 的视频段,pool5 的输出数据形式是(512,L/8,4,4)。 为了在帧级粒度上预测动作得分,需要在时间上进行上采样(从L/8 回到L),在空间上进行下采样(从4 × 4 到1 × 1)。
CDC6 将卷积核设置为(4,4,4)、步长设置为(2,1,1)、填充设置为(1,0,0),因此CDC6 可以将高度和宽度都减少到1,同时将时间长度从L/8 增加到L/4。 CDC7 和CDC8 都将卷积和设置为(4,1,1)、步长设置为(2,1,1)、填充设置为(1,0,0),因此CDC7 和CDC8 都进一步执行了步长为2 的上采样,因此时间长度返回到L。 最后在CDC8 的顶部添加帧级SoftMax 层,以获得每个帧的置信度分数,每个通道代表一个类别。 CDC 网络的最终输出形状为(K + 1,L,1,1),其中K + 1 代表K 个动作类别加上背景类别。 网络具体流程见下图5。

图5 CDC 网络流程图Fig. 5 CDC network flow chart
2.4 动作起始边界的调整
为了解决动作起始和终止坐标存在较大偏移的问题,本文提出了一个动作起始终止状态判断网络。改进文献[21]提出的网络,训练Densnets 网络用作动作状态检测网络。 Densnets 建立了不同层之间的连接关系,充分利用了特征,进一步减轻了梯度消失问题。 训练测试过程如下:(1)首先,为了更大的间隔,将每个建议段的边界在两侧扩展了原始段长度的百分比α。 本文把所有实验的α 设为1/8。 (2)对扩大后的时间区域提取光流图。 (3)训练动作起始终止状态判断网络,得到判断模型。 假设一个动作实例S 的起始和终止坐标分别为(t1,t2),则动作的时间长度L =t2-t1。 训练过程如图6 所示。 (4)测试阶段,对测试所得的动作实例的(t1-L/8, t1+L/8), (t2-L/8, t2+L/8)中的帧进行测试,分别输出每一帧为开始帧,结束帧的概率,最后得到精修后的动作起始终止坐标。
3 实 验
THUMOS'14[16]:时间动作定位THUMOS'14 数据集包含20 类行动。 本文用2 755 个修剪的训练视频和1 010 个未修剪的验证视频(3 007 个动作实例)来训练模型。 测试使用的的213 个不完全是背景视频的视频(3 358 个动作实例)。
评估指标:根据传统的度量标准[17],本文将每帧标记任务作为一个检索问题来处理,对于每个动作类,将测试集中的所有帧按其在该类中的置信度得分进行排序,并计算平均精度均值(AP),然后对所有的类进行平均得到平均AP(mAP)。 具有正确的预测类别且其与真实值的时间重叠度大于阈值时,预测是正确的,不允许对同一真实实例进行重复检测。

图6 动作起始终止状态判断网络Fig. 6 Action starting and ending state judgment network
每个测试结果都包含动作发生的时间区域和动作所属的类别.重叠度IoU 计算为:
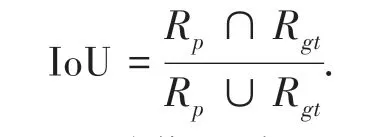
式中:Rp表示预测的动作区域,Rgt表示真实动作区域。 如果重叠度IoU 大于阈值,则表示预测是正确的。
理论上,因为卷积滤波器和CDC 滤波器都在输入视频上滑动,所以它们可以应用于任意大小的输入。 因此,CDC 网络可以在不同长度的视频上操作。 但是由于GPU 存储器的限制,实际上本文在视频上滑动32 帧的时序无重叠窗口,并将每个窗口逐个送入CDC 网络以及时获得时间上的密集预测。从时间边界的标签中,知道每个帧的标签,相同窗口中的帧可以有不同的标签。 为防止包含太多背景帧进行训练,只保留至少有一帧属于动作的窗口。 因此,在给定一组训练视频的情况下,能获得带有帧级标签的窗口训练集。
本文实验评估了在THUMOS'14 数据集上重叠IoU 阈值在0.3~0.7 之间变化时的mAP。 如表1 所示,CDC 获得的结果要好于所有其他先进方法的结果。 与建议的CDC 模型相比:用FV 编码iDTF 的系统[18]不能直接从原始视频中学习时空模式来进行预测。 基于RNN/LSTM 的方法(Yeung 等[19],Yuan等[20])无法在时间依赖性之外明确捕获运动信息。S-CNN 可以有效地捕捉原始视频的时空模型,比其他3 种方法的mAP 得到了明显的提高,但是仅在段级粒度上进行时序动作定位,缺乏调整候选建议边界的能力。 CDC 网络通过反卷积操作恢复时间维度上的长度,可以超出段级水平预测确定细粒度的置信度分数,在帧级粒度上进行时序动作定位的检测,因此可以精确定位时间边界。 比S-CNN 方法在各个阈值上的的mAP 提高了0.7% ~4.4%。
本文使用STFF-CDC 网络,改进候选片段生成算法充分利用了视频的时空特征。 实验结果表明,本文方法精度比CDC 网络约提高了2.2%。 另外,本文采用Densnets 网络作为动作状态检测网络,更有效地利用了特征,比DSTIN+CEN[21]方法相比也得到了提高。 总之,本文模型在各个阈值上均获得了其他方法更准确的时序动作定位效果。
部分检测结果对比展现在图7,受益于候选区域选择算法的改进,和动作状态检测网络的贡献,本文的方法可以得到更为精确的动作区域。
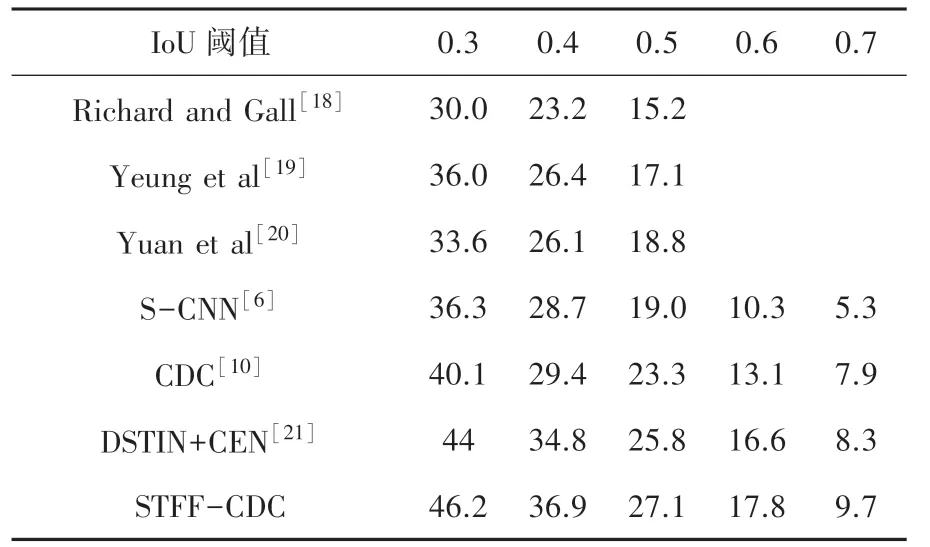
表1 本文动作识别算法和其他算法mAP(%)对比Tab. 1 The comparison of action recognition algorithm in this paper with others(map (%))

图7 部分检测结果对比Fig. 7 Comparison of some test results
4 结束语
时序动作定位任务需要识别出一段长视频中的动作类别以及动作的起始时间。 为了有效的提取候选区域,本文提出了一种基于时空特征融合的候选区域提取网络;为了提高动作起始点定位的精度,本文提出一种动作状态检测网络。 在数据集THUMOS'14 上进行实验,并与其他方法进行了对比。 结果证明,本文提出的基于时空信息融合的时序动作定位模型可以有效进行时序动作定位,达到了较好的精度。
