高校数据仓库多维数据建模分析
2020-11-10王芬芬
张 军, 王芬芬
(湖南铁道职业技术学院 图书信息中心, 湖南 株洲412001)
0 引 言
随着高校各类信息系统的深入使用,已经累积了大量的数据,有效组织与分析这些数据是当前高校信息化建设的主要任务。 很多高校前期已经建立了不同程度的,用于数据交换与共享的数据中心平台,该平台能够实现简单的数据集成,但当前高校业务数据已经呈现出历史数据量大、数据异构、数据冗余且不一致,在统计方面也存在数据统计维度多、统计路径多样化等特征。 在这种条件下,要实现跨时间、跨业务的综合统计分析是一项十分困难的工作。构建高校数据仓库系统能有效解决上述问题,数据仓库的ETL(Extract-Transform-Load)过程能有效的解决数据异构、冗余、不一致等问题,同时数据仓库能够在各种粒度上为多维数据的交叉分析提供支持[1],并且所积累的大量历史数据能够为数据挖掘提供完善的数据样本集。
1 架构设计
数据仓库主要面向统计分析和数据挖掘,为高校的教学和管理决策提供支持。 其数据来源为高校内其它操作型业务数据库和数据文件,这些数据按照高校制定的数据标准,经过清洗、转换加载至数据仓库中,为上层应用提供支撑。 本文所构建的高校数据仓库主要包括源数据层、数据仓库层和数据应用层,如图1 所示。
源数据层。 该层为各业务系统的数据库,是数据仓库层的数量来源。
数据仓库层。 该层主要分为近源数据、标准数据和主题数据3 个区域。 近源数据区贴近业务系统源数据,保存了各个业务系统的数据明细,与源业务系统的数据结构基本保持一致,唯一不同之处是在原有基础之上添加了时间戳,形成不同版本的历史数据。 标准数据区是数据仓库的核心数据区,是按照单位制定的数据标准对近源数据进行标准化处理后的结果,该层数据符合数据库第三范式建模要求。主题数据区对应宏观的分析领域,通过对标准数据进行重新组织或汇总,为不同主题的数据建立维度汇总数据区,以满足上层应用对数据的多样化需求,该层采用维度建模的方法构建。

图1 高校数据仓库的架构设计Fig. 1 The architecture design of university data warehouse
数据应用层。 该层为用户和数据仓库层建立交互界面,依据用户请求访问仓库内的数据,生成各类数据统计报表,实现对数据多维度、多层次的分析和隐性知识的挖掘。 包含了多维分析、统计报表、数据挖掘,以及为其它应用提供的数据接口[2]。
2 数据建模
数据建模是构建数据仓库的核心工作之一,通过数据建模,能够使高校建立全方位的数据视角,勾勒出高校各部门间的内在联系,同时能够有效解决各业务数据的一致性问题。 另外,数据建模可以分离出底层技术的实现和上层业务的展现,能够有效应对业务的变动,提高数据仓库的灵活性。
依据图1 所设计的高校数据仓库架构,在数据仓库层有3 个不同的数据区域,分别为近源数据区、标准数据区和主题数据区,其中近源数据区和标准数据区主要是完成数据的抽取与转换,对数据进行标准化处理,其建模方法基本是采用传统的数据库范式建模法。 灵活多变的分析需求是主题数据区建模所必须应对的问题,依据高校具体的业务数据特点以及分析需求划分主题域,每个主题对应1 个宏观的分析领域,在主题数据区中为主题建立其所需的事实表与维度表,确定关联关系,建立多维数据模型,进而为上层应用提供数据服务,其一般过程如图2 所示。

图2 主题数据区建模过程Fig. 2 Modeling process of subject data area
2.1 领域建模
领域建模就是对业务系统充分了解后,结合高校数据仓库的建设需求,对关键业务抽象化,按照业务主线聚合进行分组,将业务数据进行综合、归类,最终形成面向相应宏观分析领域的各个主题域。 主题域划分通常采用树形结构,采用逐级细分的思路进行设计。 本文依据高校的核心业务,定义了1 个公共主题和5 个业务主题,如图3 所示。 公共主题包括了学校的基础数据和标准代码集,这些标准代码集参考了国标和教育部相关标准,也包含了学校自定义的校标[3]。 部分公共维度也包含在代码集中,比如时间、地理位置、专业、学历学位等公共维度,它们通常与多个主题事实表产生关联,形成多维分析模型。
2.2 逻辑建模
逻辑模型是在充分理解分析主题与用户需求的基础上,确定分析粒度,为每个主题事实选取分析维度,设计事实表及其相关联的维度表。 事实就是对分析主题的度量,其度量属性的值就是进行分析处理的对象,事实表的设计以能够正确记录历史信息为准则。 维度则是对分析主题所属类型的描述,是分析者观察事实的角度,维度表的设计是以能够用合适的角度来聚合事实内容为准则[4]。 事实表和维度表的设计是逻辑建模的关键,其设计的好坏也直接影响到整个数据仓库系统的性能以及数据分析效果。
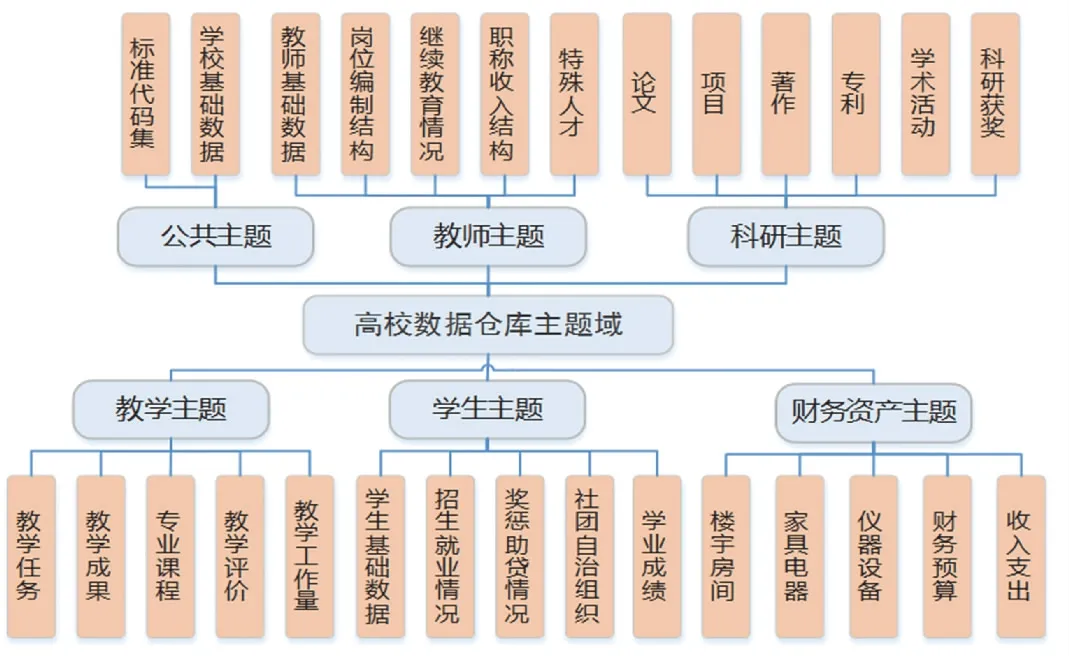
图3 高校数据仓库主题域划分Fig. 3 Subject domain division of university data warehouse
多维数据模型依据事实表和维度表不同的组织形式,通常有三种设计模式,星型模式、雪花模式和事实星座模式。 本文以高校业务中比较核心的数据分析主题来阐述三种不同模式下的多维数据模型建立。
(1) 星型模式。 星型模式的基本结构就是事实表位于中心,维度表围绕在事实表周围[5],这种模式能够直观的展示数据的多维功能。 教师主题下的教师基础数据能够从多个维度对高校师资结构进行统计分析,同时也可以作为教学、科研等与教师相关主题的教师维度。 教师基础数据涉及的维度较多,如学历、学位、学科、职称、岗位、民族、籍贯等等,适合采用结构简单的星型模式进行建模,不仅可以直观的反映出业务逻辑,还便于对不同的维度进行灵活的组合分析。 为跟踪教师基础数据的变化过程,记录和保留活动数据的历史信息,本文事实表的设计引入了缓慢变化维的方法来捕获变化数据。 在事实表中加入开始时间、结束时间和版本3 个属性来实现记录维度的缓慢变化,其中开始时间和结束时间标记了活动数据在该时间段内处于某一状态,版本记录了活动数据经历的历史状态顺序[6]。 教师基础数据的星型模型如图4 所示。

图4 教师基础数据星型模型Fig. 4 Star model of teachers'basic data
(2) 雪花模式。 雪花模式和星型模式有类似的逻辑模型,也是由事实表和维度表组成。 在雪花模式中,维度表中低基数的属性被移除,形成单独的表,基数是指表中一个属性不同值的个数,这项操作就是维度规范化。 当维度被规范化成多个关联的表,即形成了以事实表为中心的雪花型结构。 维度规范化将维度表中重复的组分离成一个新表,这些通过分解形成的表连接到主维度表而不是事实表,有效的减少了数据冗余,但却不可避免的增加了表的数量,在执行查询时,不得不连接更多的表。 但是规范化减少了存储数据的空间需求,提高了数据更新的效率。
以 学 生 学 籍 事 实 表(FACT _ STUDENT _STATUS)及其教学班级维度表(DIM_CLASS)为例,进行雪花建模,阐述维度规范化的过程,分析其在存储空间及更新效率上的优势。 以某高校为例,该校有在校生20000 人,12 个二级学院,25 个教学系部,共计400 个教学班级。 如果以星型模式进行建模,事实表有20000 条记录,教学班级维度有400 条记录,共计20400 条记录,每个学生所属的二级学院以及教学系部作为教学班级的属性,显式的存放在教学班级维度表中。 对教学班级维度进行规范化处理,建立二级学院维度表(DIM_COLLEGE)和教学系部维度表(DIM_COLL_DEPART),事实表没有变化,总的记录数变为20437(20000+400+12+25)条记录,规范化增加了新表,总的记录数也增加了,但是不难看出,在教学班级维度表中存放的不再是二级学院和教学系部具体的属性信息,而是它们的主键值,具体的属性信息统一存放在其相关的维度表中,这样就大大减少了数据存储所占用的空间,教学班级的数量越大,这种空间优势就越明显。 在数据更新方面,如果学校发生了院系调整,只需更新二级学院及教学系部维度表,对数据量较大的事实表的影响是十分微小的。
实际上,星型模式是雪花模式的一个特例(维度没有多个层级)。 雪花模型的主要缺点是维度属性规范化增加了查询的连接操作和复杂度。 相对于平面化的单表维度,多表连接的查询性能会有所下降。 但雪花模型的查询性能问题近年来随着数据浏览工具的不断优化而得到缓解。 学生学籍数据的雪花模型,如图5 所示。

图5 学生学籍数据雪花模型Fig. 5 Snowflake model of student status data
(3) 事实星座模式。 高校数据仓库由多个主题构成,包含了多个事实表,很多事实表里包含了大量公共的维度,这些维度供多个事实表共享使用,形成了多个星型模式的汇集,这种结构就是事实星座模式,也称为星系模式。 以高校财务明细事实表和科研项目事实表为例,它们之间存在着大量的公共维度,比如项目负责人、项目类别、项目来源、项目级别、立项时间、结项时间等等,多个事实表与多个公共维度交叉连接,是数据仓库构建过程中常用的建模方式。
多维数据模型是数据仓库的核心,也是OLAP(联机分析处理)的灵魂。 上述三种多维数据的建模方法都是由一组维度和事实的集合组成的,该模型可以用一个n(n ≥2) 维数据立方体表示,数据立方体中的维来自维度表,空间中的点来自事实表,每个点(以取n = 3 为例,1*1*1)包含事实数据,称为存储单元。 多维数据分析的核心操作就是对数据立方体进行钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot)。 钻取和上卷是通过改变维度的层次,调整分析粒度来观察数据,切片是通过固定数据立方体上某一维度上的选定值,观察数据在剩余维度上的分布情况,如果是对两个及以上的维度执行选择就是切块操作,旋转即是变换维度在数据立方体上的方向[7]。
针对高校业务数据结构繁杂,且存在着大量聚合分析的特点,本文在图5 的学生学籍数据雪花模型中进行了维度层次结构的设计。 以教学班级维度为例,教学班级隶属于教学系部,教学系部隶属于二级学院,层次之间通过外键连接,能够实现“教学班级→教学系部→二级学院”的上卷或“二级学院→教学系部→教学班级”的钻取。 建立维度层次关系,可以用来定义切片路径,数据立方体可以通过教学班级、教学系部或者二级学院进行切片分析。
2.3 物理建模
物理建模的主要工作是将所设计的逻辑模型在合适的数据库管理工具中实现,包括选择合适的数据库管理工具,设计数据表的结构及其属性类型,建立用于快速访问的索引策略,明确数据的存储方式及存储位置,制定实施数据的装载与清洗策略。
依据本文在数据仓库层中所设计的分区域存储和治理数据的策略,需要创建的物理表主要包括如下几类:
(1)为满足数据仓库元数据管理和数据ETL 的需求,所创建的配置表、日志表等。
(2) 在近源数据区用于存储原始数据的源数据表。
(3) 在标准数据区用于存储对源数据表进行清洗和转换的标准数据表。
(4) 在主题数据区用于存储多维数据模型所生成的维度表和事实表。
在具体设计过程中,需要对物理模型中的数据定义和数据格式进行规范化处理,也包括所遇到的一些设计共性问题,如在物理模型中所需要的主键是采用自然键还是代理键。 自然键就是用实体现有的属性组成键值,在业务概念上是唯一的。 代理键就是新增一列不具有业务含义的键值表示数据唯一。 本文设计的大多事实表都是采用自增序列的代理键为主键,因为高校业务繁多,业务需求变更频繁,代理键不与业务产生耦合,业务需求的变更对其不会产生影响,更容易维护。 另外,时间戳字段也是一个设计共性问题,数据的变化一般是发生在字段一级的,如果给每一个字段盖上一个时间戳,虽然能够最详细的记录标识数据的变化,但会大大增加数据的存储量,采用在行一级上添加时间戳,当数据发送变化时,时间戳字段同步更新,通过系统时间与时间戳字段的值来决定所抽取数据。
在索引创建策略上,按照索引使用的频率,由高到低逐步添加,使用主关键字和外部关键字建立索引,根据实际情况可以设计多种索引结构。 在数据的具体存放位置上,将索引和数据表分开存放,索引存放在高速存储设备上,数据表可存放于一般存储设备,以加快数据的查询速度。
3 实现与应用
在上述数据模型的基础上,构建高校数据仓库还需要完成数据ETL 的实施,ETL 是将各个业务中的异构数据源经过抽取、转换、加载到数据仓库的过程。 ETL 是数据仓库实施的核心内容,常用的开发工具有Oracle 公司的ODI(Oracle Data Integrator)、开源工具Kettle 等,也可以直接编写存储过程。 本文选择ODI 作为主要的ETL 实现工具,但对逻辑复杂,且对执行效率有较高需求的ETL,则直接使用存储过程来完成。
完成从各业务系统中抽取源数据后,对数据进行清洗和标准化也是一项重要的工作。 数据清洗主要对源数据中出现的残缺数据、错误数据、重复数据以及违反逻辑规定的数据等问题数据进行统一的处理[8]。 表1 给出了针对高校业务系统常见的数据问题,以及对其所采取的清洗策略。 数据标准化就是依据制定的信息标准对清洗后的数据进行规范化处理,如不同业务系统的同一数据的数据格式或使用的数据字典可能不一致,就需要将其按照数据仓库的信息标准进行规范化处理。
完成数据仓库各个层次的数据处理后,就可以为上层应用提供数据服务了,主要包括一些数据查询系统、在线分析系统、决策支持系统、数据挖掘与数据接口等。

表1 数据清洗的常见问题及策略Tab. 1 Common problems and strategies of data cleaning
4 结束语
本文基于典型的数据仓库构建技术,结合高校具体的数据统计与分析需求,针对高校业务系统零散、数据类别繁杂的特点,提出将数据仓库分为近源数据区、标准数据区和主题数据区3 个区域,每个区域的数据具有不同的特点,同时采取不同的治理策略。 多维数据建模是构建数据仓库核心内容,它能够满足对数据进行多层次、多角度的分析需求,本文选取了高校教师基础数据和学生学籍数据作为建模分析对象,分别给出星型模式和雪花模式的多维数据模型,由于篇幅有限,所构建的数据模型只列出了主要的关键字段,但它依然可以作为高校在构建数据仓库时进行数据建模的参考。 本文的数据仓库架构以及所使用的多维数据建模方法已经应用于某高校的大数据分析平台,能够灵活的分析与统计高校业务数据,自动生成各类复杂的数据报表。
