基于MapReduce的分布式云计算数据挖掘方法
2020-11-09薛慧敏
薛慧敏
(山西财贸职业技术学院,山西 太原 030031)
0 引言
数据挖掘技术能够有效解决目前社会各领域海量数据频繁增长问题,帮助行业管理者从大数据中获得有价值的趋势信息[1]。大规模数据挖掘需要搭载高效数据处理平台,才能在短时间内完成相关领域的数据挖掘任务,满足行业对数据挖掘的效率需求[2]。云计算以网络“云”为介质将宏观的数据计算程序划分成多个子计算程序,呈现显著的分布式计算特征。云计算将数据挖掘压力分散开来,以此降低运算时间,克服硬件设施对计算效率的负面干扰[3]。因而,本文以云计算环境为载体进行大数据挖掘,拟选用云计算技术中的MapReduce计算模型作为大规模数据并行运算的技术支撑,以获取基于MapReduce的分布式云计算数据挖掘方案。
1 分布式云计算环境下基于MapReduce的数据挖掘技术
1.1 基于MapReduce分布式云计算框架
MapReduce是一个包含Map函数与 Reduce 函数的、能够解决海量数据并行运算的编程模式,Map函数用于解决MapReduce计算框架的映射任务,Reduce 函数用于解决计算框架的归约任务[4]。MapReduce计算模型下的数据挖掘效率提升的原理在于:MapReduce能够基于实际运行状态科学分配各程序的运算任务与运算量,通过Reduce 函数归约节点运算结果并汇总,达到实时并行化运算状态[5];同时,运算过程中将计算机视为分布式运算的节点,网络数据的交换、计算等任务均借助计算机的内存空间来实现,如此一来,MapReduce无需投入过多的计算成本并且扩大了数据运算的空间场所,相同时间内可以完成更多的计算任务。
图1为 MapReduce计算模型的计算过程。MapReduce计算过程包括Map与Reduce两大步骤,<键,值>为Map函数与Reduce函数输入值、输出值的表达形式。海量待挖掘数据的存储、传输、读取工作借助HDFS文件系统完成,HDFS是云计算环境下常用的分布式文件系统,可以高效解决分布式文件的存储等工作[6]。首先,样本数据在HDFS文件系统中进行分块处理,得到n个数据块;其次,数据块被依次读取至Map任务区域进行相应运算处理,数个节点可以同时供Map函数运行,解决若干数据分片问题;接下来进入到Reduce函数处理环节,Reduce函数以并行化运行的方式处理Map函数输出的中间结果。最后,得到被Map与Reduce处理完成的运算结果,作为最终结果输出。
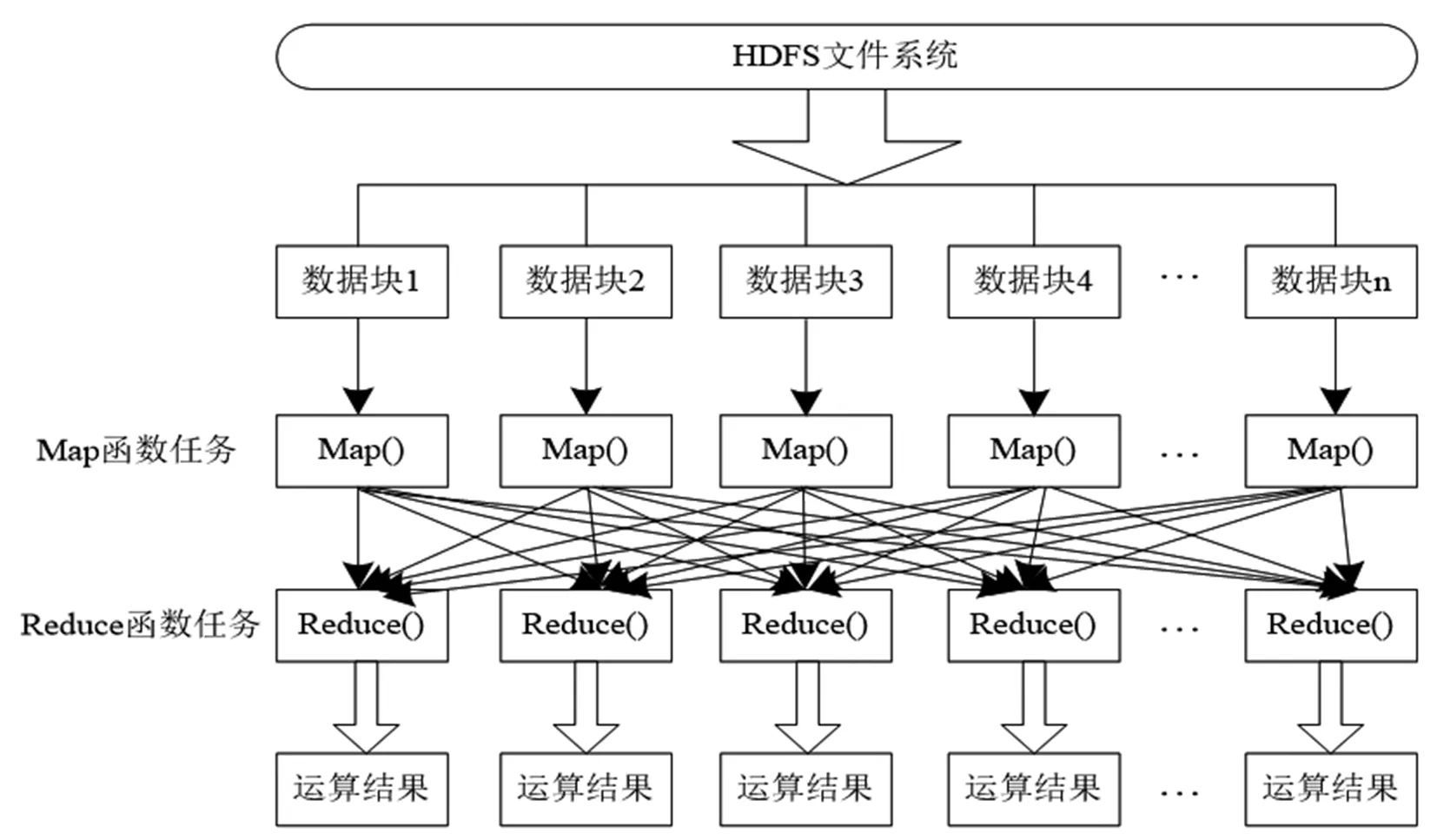
图1 MapReduce计算过程
1.2 基于MapReduce的云计算K-means聚类算法实现
MapReduce计算模型在处理大规模数据问题上展现了并行、均衡负载等优势,行业技术人员愈发倾向于运用MapReduce模型解决数据挖掘问题[7]。在MapReduce计算模型的分布式云计算框架之下进行数据挖掘的方法较为丰富,K-means是一种经典的数据聚类方法,其聚类原理是对比两个样本的欧氏距离从而判断指标相似性大小,根据相似性进行数据归类。海量数据样本环境中,定义一个数据集M,任意获得k个初始聚类中心,然后求取其他所有数据样本与初始中心的欧氏距离[8];接下来完成样本与聚类中心的分类,分类遵循“最小距离”标准;最后统计各类中全部样本的距离均值,同时将其作为此类别的聚类中心更新结果,当误差平方和函数趋于最小值并且稳定时终止运算。
K-means聚类算法的误差平方和函数确定方式如下,定义数据集M的具体形式为M={x1,x2,……,xn},样本xi={xi1,xi2,……,xir},样本xj={xj1,xj2,……,xjr},公式(1)为计算样本xi、xj的欧式距离计算方法:
d(xi,xj)=
(1)
进而得到如公式(2)所示的误差平方和函数:
(2)
公式中,K-means聚类算法的类别数量用K表示,第i类样本数量以及样本均值分别用ri、ni表示。
为更加高效、精准地实现K-means算法在分布式云计算环境下的数据挖掘任务,在经典的 MapReduce计算模型基础上引入Combiner函数,具体而言,为进行Map函数操作的机器布设Combiner函数解决一次性合并Map函数输出结果的问题,无须多次反复合并操作[9]。利用优化后的MapReduce计算模型完成K-means聚类的步骤如下:
Step 1:Map函数执行运算。还原K-means聚类算法中k 个中心点,以并行方法求取中心点与数据对象间的距离,数据对象分类工作也依据该距离完成。求取云计算环境下服务器数据对象与聚类中心点的距离,以此更新此刻数据对象的聚类类型,各个样本数据对象的聚类中心点即为当前Map函数的输入项。
Step 2:Combiner函数优化。对完成Map函数操作的数据实施Combiner处理,以差异性数据节点为介质完成Map函数内存写入操作,以此节约内存开销及其成本投入,同时减少中间数据传输量。
Step 3:Reduce函数执行运算。初始阶段Combiner过程的中间结果获取可通过Reduce函数过程实现,各簇的样本数量、差异性维度坐标值统计情况均可一并获得,由此得到更新后的中心坐标值,在硬盘主函数部分进行安全存储。分布式云计算 MapReduce计算模型框架下,各服务器的数据初始中心点均由主函数负责采集与存储,将中心点信息传递至Map函数部分,从宏观上向K-means聚类算法数据挖掘过程发号施令。
2 实验分析
搭建云计算数据挖掘实验平台进行数据挖掘测试,系统环境为Ubuntul2.04,以验证基于MapReduce的分布式云计算数据挖掘方法的可行性与性能。本次分布式云计算测试平台包括6台计算机,构成集群式数据测试集群。其中,云计算环境的各个节点配备Inter Corel 7处理器,2.5GHz主频,拥有8G内存。本次测试从权威数据平台获得5个有效数据集作为数据挖掘的测试样本,数据样本总规模为1.02GB。为突出本文算法在云计算环境下的数据挖掘优势,同时选取未增加Combiner函数处理的传统云计算K-means聚类算法以及G-means聚类算法作为对比测试方法,详细的实验结果如下。
整个数据挖掘测试过程中,随着分布式计算节点的增加,三种数据聚类算法的时间开销情况如表1所示。

表1 不同数据聚类算法的时间开销情况/s
表1数据显示,当分布式计算节点由1个增加至6个时,三种算法的时间开销均呈下降趋势。同时,可以明显看出,本文算法的初始时间开销便是三者中最低,直到节点增加至6个时,聚类时间开销仅为4121s,为三种算法中效率最高者。这是因为本文算法在云计算环境下采用了 MapReduce计算模型,并且在Map函数操作的机器上布设Combiner函数解决一次性合并Map函数输出结果的问题,无需多次合并操作,大大节省了算法运行的时间。
此外,还可以看出,随着节点数量增加,本文算法聚类时间减少的数据量存在一定规律性,前期时间减少幅度约为2000s,后期时间减少幅度约为1000s,没有大幅度波动情况,说明此算法在云计算环境下进行数据挖掘的稳定性较优。
3 结论
云计算的分布式计算特征使其成为大数据处理的必然发展趋势,以“任务分发—合并”的形式解决大规模数据分析与处理问题,MapReduce模型则是突出的云计算工具。本文对云计算环境下的MapReduce计算模型进行优化,获得一种可以高效辅助K-means聚类算法完成数据挖掘的方案。经过测试得出,该算法在聚类效率方面优势显著,同时获得了较优的数据挖掘稳定性。
