结合拉普拉斯特征映射的权重朴素贝叶斯高光谱分类算法
2020-11-06李响,吕勇
李 响,吕 勇
(北京信息科技大学 仪器科学与光电工程学院,北京 100192)
高光谱遥感(Hyperspectral remote sensing)经过上世纪后几十年的迅猛发展已取得了长足的进步,因其是将光谱分析技术与成像技术相结合,以期达到获取多维信息的技术手段,因此也被称为成像光谱遥感[1-2]。目前的航空与航天高光谱遥感测量技术数据获取途径正在向多传感器、多角度与多平台的“三多”方向发展,而高光谱数据则向着高时间、空间分辨率以及高光谱分辨率的方向发展。因其所包含的丰富信息,高光谱遥感技术不仅被应用于传统的地质学、地理学、农业科学与植被监测等遥感领域,在海洋学、大气研究、生态学等环境领域也得到了广泛的应用与研究[3-5]。当今世界,高光谱遥感已涵盖了各个国家的航空、航天以及小范围的地面观测的多个层级与环节,伴随先进探测技术、图像处理技术、光谱分析技术、特征提取等多个学科、多个领域的定性/定量化研究的发展与进步,高光谱分析技术在对地观测遥感领域已占有不可取代的地位。
高光谱遥感技术能够在探测过程中,同时获取关注区域与目标物的一维光谱数据与二维空间信息,形成所谓的“数据立方体”,“图谱合一”的特点使得高光谱分析技术可以综合利用光谱分析与图像处理的优势,得到更精确与丰富的遥感信息[6-7]。高光谱数据立方体中的每个像素中储存着探测视场内至少十余个甚至能高达上百个连续光谱波段信息。常见的高光谱探测波长一般分布在400~2 500 nm范围内,波长分辨率一般小于10 nm。
高光谱数据在包含空间几何信息的同时,也承载了光谱信息,因此仅使用单一的传统图像处理技术或光谱分析技术均显得力所不及。对此,需要根据高光谱数据的机理与特点发展适合数据立方体的特征信息提取算法与技术。波段重多、数据量庞大,数据内存在亚像元与混合像元,不同探测条件下“同物异谱”现象等问题在高光谱遥感中普遍存在,解决方法主要有以下4方面:数据降维与特征提取、目标探测、图像分类以及混合像元分解。在上述几个方面中,数据降维与特征提取可谓重中之重,是后续各种定性与定量分析的前提与基础,同时也为庞大的高光谱数据的存储与传输提供了便利。本文将拉普拉斯特征映射应用于高光谱数据,用以进行降维与特征提取,并提出了一种改进的朴素贝叶斯分类算法,对高光谱的目标区域进行了地物分类。
1 算法与原理
1.1 基于拉普拉斯特征映射的降维与特征提取方法
高光谱数据处理中的降维(Dimensionality reduction)是指利用具有较低的维度新数据来有效承载原始较高维高光谱数据中的信息,将庞大、冗余的数据量进行压缩,以便为后续处理环节提供有效的地物信息特征[8-9]的技术。
高光谱数据处理的降维技术主要分特征提取与波段选择两种。其中高光谱数据特征提取(Feature extraction)是指对原始高维高光谱数据空间或其部分子空间进行特定算法的数学变换,构建新的携带了大部分原始有效信息并且消除了冗余性的派生特征量,以便于后续环节中对高光谱信息具有更好的理解,从而实现信息综合、特征增强和光谱减维的过程。由于多数情况是在进行此数学变换后,数据集维度并未减小,而是结构发生了优化——少量的新变量携带了原始数据中的大部分信息,此时需要继续进行光谱特征选择(Feature selection),针对数据特征与后续环节需求,选择变换后的新特征空间中的一个数据子集[10-11]。此子集是包含了原数据集主要特征但缩小了维度的变量空间,从而实现降维的目的,过程如图1所示。
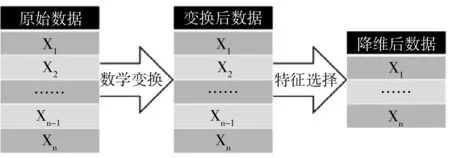
图1 高光谱数据特征的提取与降维Fig.1 Feature extraction and dimensionality reduction of hyperspectral data
波段选择也是高光谱数据降维的一个重要手段,可直接选择高光谱数据的一个波段子集,因包含了地物信息的主要光谱特征,能够保证目标区域的地物类别可分性。一般是设定一个评价函数作为目标,对其进行优化,最终形成一个最优的波段组合。该评价函数的选取会直接决定最终的波段子集所携带信息的多寡。一般来讲,需要对地物信息有一定的了解,以进行有监督的优化。此外,相比于特征提取,波段如选择与其相同的数据维度,往往会损失较多的信息,因而其应用场景受限。
拉普拉斯特征映射(Laplacian Eigen mapping)属于流形学习算法的一种,由Belkin最早提出[12-14]。拉普拉斯特征映射使用类似频谱技术构建邻接矩阵的图来进行降维。该技术基于数据位于高维空间中的低维流形的假设。该算法不能嵌入采样点,但基于再生核希尔伯特空间正则化的技术增加了其降维能力。
与传统技术主成分分析的相似之处在于,拉普拉斯特征映射也不会将数据的内在几何结构作为主要考虑的问题,而会根据数据集的邻域信息构建图,每个数据点用作图的节点,且节点之间的连接由邻近点的邻近度控制。由此产生的图被认为与高维空间中的低维流形的离散近似。基于图的目标函数的最小化确保流形上相互接近的点在低维空间中彼此接近,以保持局部距离。Laplace-Beltrami算子在流形上的本征函数作为嵌入维数,这是因为在温和条件下,这个算子有一个可计算的谱,其为流形上平方可积函数的基础。该算法的基本流程如下:
Step 1:利用K-最近邻方法构建图;
Step 2:选用热核函数来确定点与点之间的权重值Wij,如果样本点xj与其互为近邻则有:
(1)
或将其简化为i与j相连时,Wij=1,否则为0;
Step 3:进行特征映射,计算拉普拉斯矩阵L的特征向量与特征值:
Ly=λDy
(2)
式中,Dy是对角矩阵,满足Dii=∑jWij,且有L=D-W,称为Laplacian矩阵,为对称半正定矩阵。
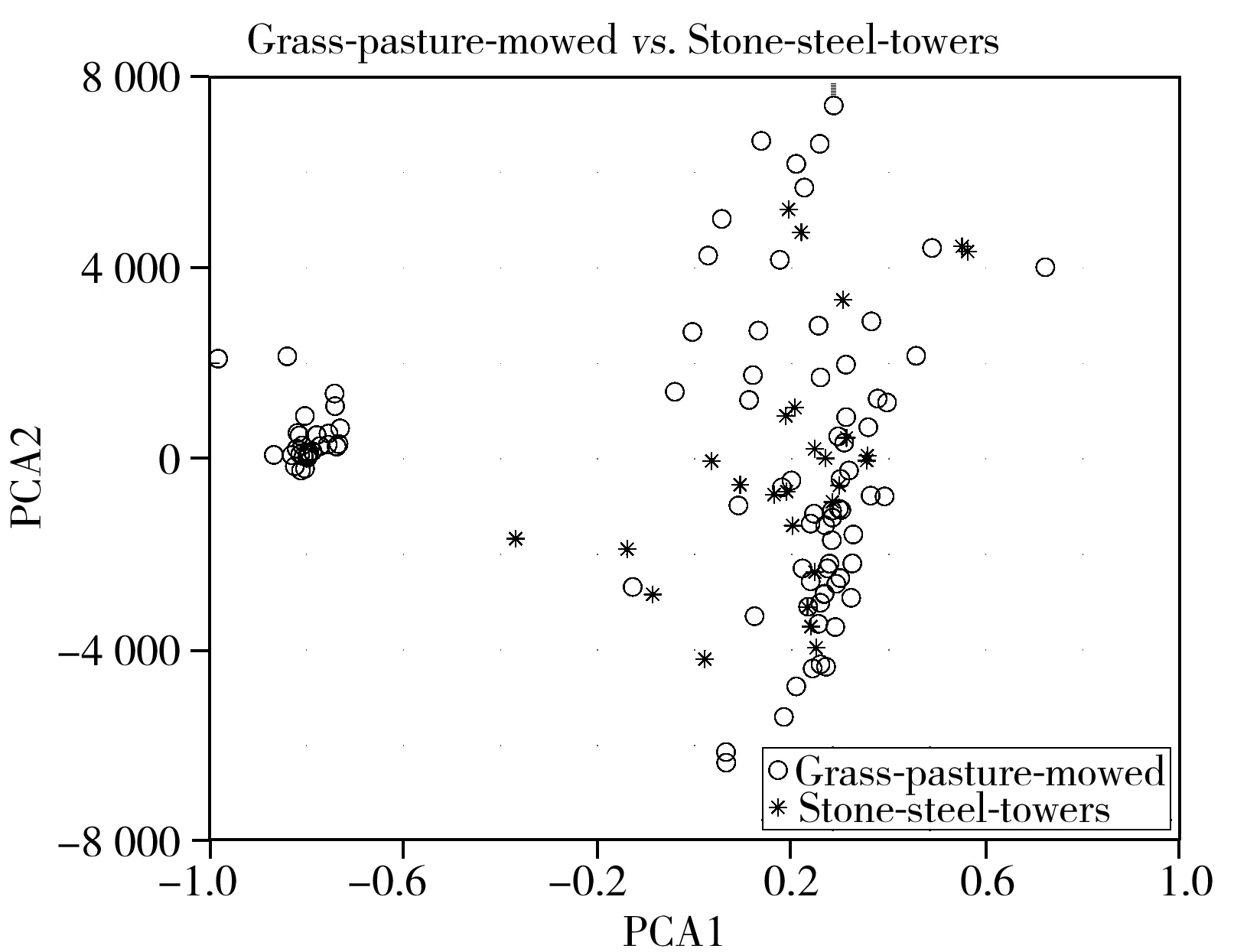
流形学习的本质是寻找原始数据集中所存在的内在规律性,即从测得的原始数据表象中找出隐含在高维原始数据集中的低维光滑流形。从这一点不难推断出,相比主成分分析[15-16],作为重在发现不同映射坐标系下差异的算法,拉普拉斯特征映在对具有不同本质的高光谱数据处理时,一定会具有不弱于主成分分析的降维与特征提取能力。下面以公开的AVIRIS(Airborne Visible Infrared Imaging Spectrometer,机载可见光/红外成像光谱仪)采集的Indian Pines数据集中的Grass-pasture-mowed与Stone-steel-towers两类数据为例进行说明,分别进行两种方法的预处理,仅采用各算法的前两个新变量进行比较,结果如图2所示。从图中可以明显看出,主成分分析后的新变量下,两种类别仍然混叠在一起,而拉普拉斯特征映射后的新变量下,不同类别能较好的分开,表明拉普拉斯特征映具有更好的效果。
1.2 权重朴素贝叶斯分类方法
在机器学习中,朴素贝叶斯分类器(Naive Bayes classifier,NBC)是“概率分类器”家族的一员,它简单而行之有效,其本质是基于贝叶斯定理在特征之间的强(朴素)独立假设[17-18]。
朴素贝叶斯自20世纪50年代以来在文本检索领域得到了广泛地研究,至今仍然是一种流行的文本分类方法,如垃圾邮件判别,敏感内容审查等,其后扩展应用至其他领域。在许多实例中,朴素贝叶斯分类器的分类精度均不低于目前的研究热点——神经网络分类算法,尤其因其分类方法简单,训练与识别只需花费线性时间,无需其他很多类型的分类器所使用的费时的迭代与逼近运算,运算速度快,更适于处理大型数据,且能同时保证分类的准确性[19-20]。
利用朴素贝叶斯分类算法对高光谱图像进行分类,首先定义数据集,每个像素处的高光谱数据定义为一个样本,由一个多维向量X标识,X={x1,x2,… ,xm},其中xm可为原始光谱值,也可为经过预处理后得到的特征值。当由k个地物分类时,分别记为A1,A2,…,Ak,对于一个未知地物类别标号的像素点光谱样本X,贝叶斯分类算法将判定未知类别的X为后验概率最高的地物类别,即当1≤i≤k,且仅当P(Ai|X)>P(Aj|X),朴素贝叶斯分类将未知的样本X分配给类别Ai,其中1≤j,i≤k,j≠i,而其中P(Ci|X)最大的地物类别就是最大后验概率。
(3)
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率,但实际上并非总是如此。这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往不成立,在属性个数较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。因高光谱数据在进行分类前,一般已经进行了拉普拉斯特征映射或PCA等预处理,这些预处理算法可以保证特征xi之间相互独立,并可利用P(X|Ai)=∏P(X1|Ai)求得先验概率,而P(x1|Ai),P(x2|Ai),…,P(xm|Ai)可以利用训练样本集求出。另外,朴素贝叶斯模型需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设先验模型的原因导致预测效果不佳。拉普拉斯特征映射是一种基于图的降维算法,相比于常见的主成分分析方法,它不仅关注增加数据新属性的差异程度,且更希望相互间有关系的样本在降维后的空间中尽可能的靠近,因此更适于作为朴素贝叶斯分类模型的降维预处理方法。
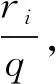
2 验证计算
2.1 实验数据来源
为便于比对,本研究采用广泛应用的免费公开的AVIRIS数据验证说明以上算法。AVIRIS的相关信息与部分数据可在https://aviris.jpl.nasa.gov/上获得。AVIRIS独特的光学传感器,可以在波长为380~2 500 nm的224个连续光谱通道(也称为波段)中提供光谱辐射的校准图像[21]。每个检测器的光谱分辨率约为10 nm,当来自每个检测器的数据被绘制在图上时,可产生完整的可见-近红外高光谱数据立方体。
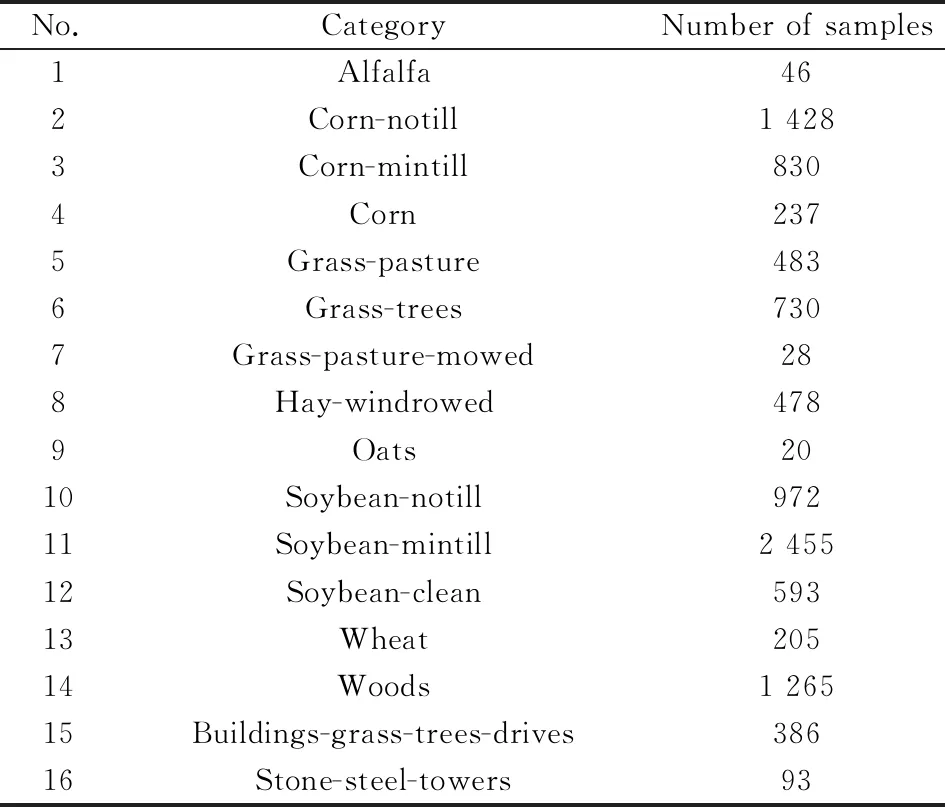
表1 Indian Pines场景中真实的地物信息Table 1 True ground informations of Indian Pines scene
2.2 实验数据说明
AVIRIS项目包含多组数据,限于篇幅本文仅以在印第安纳州西北部的印度松树(Indian Pines)测试场地上的采集数据为例进行说明,本算法在其他测试数据上也取得了较好效果。本文所采用数据集由145×145像素和224个波长范围为400~2 500 nm的光谱反射波段组成。这个场景是Pursue的Univeristy MultiSpec网站上更大的一个Indian Pines高光谱数据的子集,本子集在在http://www.ehu.eus/ccwintco/上免费获得。实验数据集中去除覆盖吸水区域的部分波段,去除的波段为[104-108],[150-163],220。该场景下,其具体地物信息及所包含像素数如表1所示。
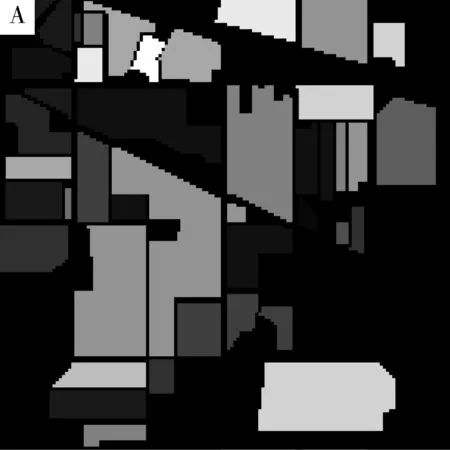
印度松树场景包含三分之二的农业和三分之一的森林或其他天然多年生植被。有两条主要双车道高速公路,一条铁路线,以及一些低密度住房、其他建筑结构和较小的道路。由于6月份出现了部分作物,玉米、大豆处于早期增长阶段,覆盖率低于5%。可用的基本事实被分为16个类别,并不完全相互排斥。按真实地物信息(True ground)标记各个地物类别,得到分布图如图3A所示,图3B为相机所拍摄得到的目标区域照片,后续以此为标准对本文算法进行验证。上述16种地物种类的平均光谱如图4所示。由图4中可以看到,相比于普通遥感图像,高光谱数据因具有不同地物像素点的光谱维度信息,更丰富的信息为更加准确的地物分类提供了可能与基础。
2.3 硬件与软件
本研究所述实验利用PC计算机进行验证,操作系统为Windows 10,处理器为I5-6700,8 GB内存,利用MATLAB 2016A自行编写程序。
3 结果与讨论
使用“2.2”所述高光谱数据验证本研究所提出的算法,因本算法并未涉及各数据的图像维度信息与关系,因此各像素点数据可作为独立光谱样本进行分析,各类别分别随机选取一半数据作为训练集,得到判别分析模型,剩余一半作为校验集,对算法与模型进行验证。在“2.3”所述软硬件环境下,对10 512个重复建立模型进行20次计算,取平均值,不计特征提取时间,其训练时间仅为0.021 s,远远快于其他类型分类算法训练时间。而后对Indian Pines中的剩余10 513个样本进行分类,检验该方法的有效性,重复进行20次,取平均值,训练时间仅为0.009 s。分别选择实用原始数据及经典朴素贝叶斯算法,判别分析结果如表2所示。

表2 不同算法判别分析结果的比较Table 2 Comparison of discriminant analysis results of different algorithms
由上表可以得到,本方法的总体分类准确率达到92.7%。相比于前两种经典方法,本方法的精度大幅提高。在图2所示的预处理过程中也可以看到,应用拉普拉斯特征映射明显优于广泛应用的PCA方法,且具有更高的分类准确率。本研究所提出的方法在保持较高的准确率之外,大幅缩短了计算时间,尤其是训练时间。
4 结 论
相比于传统图像遥感方法,高光谱数据分类具有明显优势。拉普拉斯特征映射能够在降维的同时,很大程度上凸显关注区域地物的本征特性。本文结合拉普拉斯特征映射预处理方法,通过奖励权重的方法对经典朴素贝叶斯分类器进行了改进,利用公开数据对算法进行说明验证,判别地物信息准确率可达到92.7%,相比于传统方法,有大幅度提高,同时大幅缩短了计算所需时间。因此,本研究所述方法适用于需要对高光谱数据进行快速处理的应用场景。
