非结构CFD软件MPI+OpenMP混合并行及超大规模非定常并行计算的应用
2020-11-06王年华常兴华赵钟张来平
王年华,常兴华,赵钟,张来平,
1.中国空气动力研究与发展中心 空气动力学国家重点实验室,绵阳 621000 2.中国空气动力研究与发展中心 计算空气动力研究所,绵阳 621000
随着计算机技术和数值方法的飞速发展,计算流体力学(Computational Fluid Dynamics,CFD)数值模拟在航空航天等领域已得到越来越广泛的应用。经过几十年的发展,基于雷诺平均Navier-Stokes(Reynolds Averaged Navier-Stokes,RANS)方程的常规状态气动力/力矩预测已经难度不大,但是在遇到旋涡、分离、转捩、湍流噪声、湍流燃烧等非定常、非线性现象明显的流动时,在千万量级网格上求解RANS方程无法得到足够精确的数值解,这时就需要采用更大规模的网格,采用更高保真度的数值方法,如大涡模拟(Large Eddy Simulation,LES)和直接数值模拟(Direct Numerical Simulation,DNS)等。这些方法的共同特点就是对网格量要求很高,通常认为LES方法在黏性底层内对网格量的需求达到Re1.8量级,而DNS则要求网格量达到Re9/4。对于实际飞行器外形,雷诺数Re通常在百万量级以上,那么网格量则至少要达到百亿量级以上,才能满足算法对多尺度流动结构的分辨率要求[1-3]。即便是采用高阶精度格式,虽说网格量可以适当减少,但是所需的网格量仍需以亿计。
另一方面,E级计算时代即将来临,计算机集群核心数已经突破千万核,但是目前主流的CFD工程应用仍然停留在千万量级网格数百核并行计算规模,CFD软件的发展与计算机硬件的发展速度极不匹配,这也直接制约了CFD精细数值模拟在实际工程问题中的应用。采用大型计算机集群,调用超大规模计算资源进行并行计算,同时提高并行效率,发挥出超级计算机的最佳性能,达到较高的效费比,是未来高分辨率数值模拟必须解决的重要问题,同时也是E级计算时代到来之前所必须解决的软硬件匹配发展的问题[4]。
近年来,既有分布内存又有共享内存的多核处理器成为目前高性能计算机的主流计算核心芯片[5]。“天河二号”(2018年11月世界TOP500排名第4)采用16 000个计算节点,每个计算节点装备了2颗12核的Ivy Bridge-E Xeon E5 2692处理器和3颗57核的Xeon Phi加速卡,2个 处理器共享64 GB内存,同时每个Xeon Phi加速卡板载有8 GB内存,计算节点间通过自制的TH Express-2私有高速网络互连,MPI通信速率可达6.36 Gbps[6-7]。“神威太湖之光”(2018年11月 世界TOP500排名第3)采用40 960个国产“申威26010”众核处理器,每个处理器有260个核心,每个处理器固化的板载内存为32 GB[8-9]。对于这种节点内共享内存、节点间通过高速网络互连的架构来说,要减少非计算时间占比,尽可能提高程序的并行度,就需要充分利用硬件特性,减少通信次数、通信量,提高并行效率。
传统的并行模式在节点间采用MPI消息传递机制进行通信,这种模式在规模较小时能够有效扩大并行规模,并且保持较高的并行效率。但是随着并行规模增大,分区数增多,通信量和通信次数呈几何级数增大,导致在大规模并行时,并行效率急剧下降。为了充分利用现有计算节点共享内存的特性,可以在节点内部采用共享内存模式进行并行计算。
本文在原有MPI并行模式的基础上,在课题组自研的基于非结构网格的二阶精度有限体积CFD软件HyperFLOW中,引入共享内存并行模式,并通过OpenMP改造,实现了MPI+OpenMP两级混合并行。首先,根据节点内并行数据粒度大小,将混合并行分为粗粒度并行和细粒度并行,简单介绍了两种并行的实现原理和基于C++编程语言的实现细节。其次,在国产in-house集群上,通过CRM(Common Research Model)标模定常湍流算例[10]对两种混合并行模式进行测试和比较。随后,为了验证两种混合并行模式在非定常计算中的可扩展性,在机翼外挂物投放标模算例的3.6亿非结构重叠网格上进行效率测试,并采用12 288核完成了基于混合并行模式投放过程的非定常计算,得到了较高的并行计算效率。最后,在in-house集群上采用4.9万核,在28.8亿非结构重叠网格上进行效率测试,验证了混合并行改造的效果。
1 HyperFLOW软件简介
HyperFLOW软件平台[11-12]是作者团队自主发展的结构和非结构混合CFD解算器。该解算器采用C++面向对象的设计思路,建立了“运行数据库”“模块化求解”等先进的软件架构,具有良好的通用性和可扩展性。其可以进行结构解算器和非结构解算器的独立求解,也可实现两种解算器在空间上的耦合求解。解算器的空间离散采用了二阶精度的格心型有限体积方法,集成了Roe、vanLeer、AUSM、Steger-Warming等通量计算格式以及Barth、Venkatakrishnan等多种限制器函数。湍流模拟方法有SA一方程湍流模型、SST两方程湍流模型以及DES方法等。时间离散格式有Runge-Kutta、隐式BLU-SGS等方法,非定常计算采用双时间步方法进行物理时间推进。非定常计算的动网格生成采用基于运动分解的耦合变形和重叠的动态网格生成技术。为了适应大规模工程计算的需求,早前已经发展了基于网格分区的非阻塞MPI通信的大规模并行计算技术,并且在中等规模时达到了较高的MPI并行效率。本文仅对HyperFLOW中的非结构解算器进行MPI+OpenMP混合并行改造。
2 MPI+OpenMP混合并行计算方法
HyperFLOW软件的并行通信数据结构是基于网格分区构建的,1个进程可以处理1个或者串行处理几个网格分区,进程之间采用MPI消息传递机制进行数据传递,如图1(a)所示。每个分区内在进行迭代计算时,采用基于面(或单元)的数据结构。

图1 几种并行模式的比较Fig.1 Comparison of different parallelization modes
这种基于网格分区的MPI通信模式,其通信过程可以完全人为指定,适合具有分布式内存的计算机系统,能够有效地提高并行规模。但是,随着分区数的增大,分区交界面单元数量、通信量、通信次数呈几何级数增大,导致通信时间占计算总时间也明显增大,从而使得并行效率存在瓶颈。
为了减少通信量,提高并行效率,可以利用共享内存的特点减少通信次数和通信量。结合HyperFLOW软件的数据结构特点,主要可以采用两种共享内存方式。
1) 粗粒度OpenMP模式,如图1(b)所示。由于进程之间需要通信,导致效率下降,因而可以保持分区数不变,减少进程数,同时引入线程级并行,将一部分原来的进程用线程替代,进程间采用MPI通信,但是线程间采用共享内存,从而减少通信量。由于线程对网格分区进行并行处理,数据粒度大,因而也称这种并行模式为“粗粒度”OpenMP并行模式,这与文献[13]提及的基于两级分区的粗粒度混合并行模式是一致的。
2) 细粒度OpenMP模式,如图1(c)所示。除上述模式外,也可以减少分区数,同时减少进程数,进程间仍然采用MPI通信,但是在网格分区内部进行线程级并行,达到减少通信量的目的。具体来说,在基于面(或单元)的数据结构基础上引入线程级并行,也即线程对基于面(或单元)的数据进行并行处理,数据粒度小,因而这种并行模式也被称为“细粒度”OpenMP并行模式。
2.1 纯MPI并行
如图1(a)所示,对于纯MPI并行模式,1个节点内部包含多个CPU,每个CPU上运行1个进程,处理1个或几个网格分区。进程间独立计算,通过MPI通信分区界面数据。HyperFLOW中采用对所有网格分区进行遍历的模式进行通信,具体分为以下两个步骤:
1) 通信数据准备。遍历每个网格分区,计算出该分区需要发送的数据内容和长度。
2) 非阻塞式数据发送和接收。每个进程均遍历所有网格块,当所遍历的网格块属于当前进程时,则向邻居网格块所在进程发送数据;当所遍历的网格块属于其邻居网格块时,则从邻居网格块所在进程接收数据。
图2是MPI通信模式示意,图中给出了4个进程、4个网格块,将每个网格块分配至具有相同编号的进程。以1号进程为例,遍历4个网格块,该进程上只有1号网格块(与3号进程中的3号网格块为邻居关系),当遍历到1号网格块时向3号进程发送消息,当遍历到3号网格块时从1号网格块接收消息,而对于0号、2号网格块则跳过[13]。

图2 MPI通信模式[13]Fig.2 MPI parallelization mode[13]
以下采用CRM标模定常湍流算例[10]对MPI效率进行测试,标模网格为非结构混合网格,网格量约为4 000万单元,具体网格量如表1所示。

表1 CRM标模测试算例网格信息Table 1 Grid information of CRM test case
定常湍流数值模拟采用二阶精度有限体积法对RANS方程进行离散求解,无黏通量格式选择Roe格式,梯度重构为GG-Cell方法,黏性通量选择法向导数法[14],湍流模型采用SA一方程模型,时间推进采用隐式LU-SGS方法。具体方法参见文献[3],这里不再赘述。计算马赫数Ma=0.85,雷诺数Re=5×106,攻角α=2.5°,下文中CRM算例测试条件均与本节相同。
测试集群为中国空气动力研究与发展中心计算空气动力研究所的国产in-house集群(简称国产in-house集群),CPU采用Phytium FT1500A芯片,单节点16核,共享32 GB内存,采用国产高速互连网络,双向链路速率为200 Gbps,运行国产麒麟操作系统,C++编译器版本为Phytium 1.0.0(Based on GNU GCC 4.9.3),MPI库版本为MPICH version 3.2,OpenMP库版本为OpenMP API 3.1。
图3给出了加速比和并行效率的测试结果。最小测试规模为64核,最大测试规模为8 192核并行,不同并行规模的网格均采用8 192分区。结果显示在1 024核并行时,相对于64核的MPI并行效率为99.8%,加速比为15.97,接近理想加速比。但是在并行规模进一步增大时,并行效率急剧下降,当并行核数为8 192核时,程序的并行效率只有37.9%,加速比仅达48左右,与理想加速比128存在较大差距。这是因为随着并行规模增大,单核处理的网格量减少,在8 192核时,单核处理的物理网格量只有不到5 000个单元,此时单核的计算量很小,而通信量随着核数增加而急剧增大,从而使得并行效率严重下降。这体现出MPI并行模式在超大规模并行计算时存在的效率瓶颈问题,必须通过减少通信时间占比来提高并行效率。利用多核处理器节点内共享内存的特性,将程序改造成节点间采用MPI通信、节点内采用OpenMP共享内存的两级混合并行模式是一种减少通信量的可行办法。

图3 纯MPI模式的并行效率及加速比Fig.3 Parallel efficiency and speedup of MPI parallelization mode
2.2 混合并行改造与实例
粗粒度混合并行是对网格分区进行线程级并行,因此在不改变MPI通信模式的情况下,将对网格分区(zone)的循环进行OpenMP并行改造,即可实现粗粒度混合并行,如图4所示。
细粒度混合并行是在网格分区内部,在基于面(或单元)的数据结构上进行线程级并行。因此,在不改变MPI通信模式的情况下,将基于面(或单元)的循环进行OpenMP并行改造,即可实现细粒度混合并行,如图5所示。

图5 细粒度混合并行改造原理Fig.5 Principle of fine-grain hybrid parallelization
改造中需要注意的两点:① 避免不同线程之间的数据竞争,主要是数据写竞争,如多个线程同时对同一地址变量进行赋值操作;② 对计算耗时较大的热点函数和模块逐个进行改造,如无黏通量、黏性通量、时间步长计算、时间推进等模块。
借助性能分析工具,可以分析得到程序中的热点类/函数如表2所示,将类和模块对应到各个程序功能。结果显示,最耗时的类是层流方程及湍流方程的LU-SGS推进,其次依次是黏性通量计算、梯度计算、无黏通量、时间步长及流场更新、湍流源项计算等。

表2 程序热点函数及功能模块对照表Table 2 Table of hot spots class/function and modules
如图6所示,在非结构网格数据结构中,由于不同面可能对应相同的左(右)单元,因而可能会出现不同线程对同一个左(右)单元的右端项值rhsField进行更新的情况,如图6中face1和face2的左单元均为cell1,若face1和face2被分别分配到不同线程进行并行计算,就存在对cell1的右端项值进行同时更新的可能性。此时就必须采用atomic原子更新来避免不同线程对同一个地址进行累加/减操作,避免造成数据冲突,导致不可预测的错误,以基于C++语言的HyperFLOW程序为例,代码如图7所示。

图6 非结构网格数据结构示意图Fig.6 Sketch of unstructured mesh data structure

图7 避免数据竞争的原子更新操作Fig.7 Avoidance of data races via atomic manipulation
如果不采用原子更新,该部分程序或其他类似情况就无法实现OpenMP并行,会导致程序的并行度降低,但同时也应指出atomic原子更新是在并行程序中强制只允许某单一线程对数据进行更新,在保证结果稳定正确的同时也会带来额外的并行开销,是否采用原子更新需要对程序并行度和并行开销进行权衡。
以下采用CRM标模算例考察原子更新对并行效率和运行时间的影响,分别采用4个线程不同进程(16进程依次增加到2 048进程,核数从64核依次增大到8 192核)进行并行测试,结果如图8 所示,atomic原子更新可以提高程序并行度,提高大规模并行时的并行效率,但是也会导致程序在小规模并行时存在额外的并行开销,耗时增大。如图8所示,图8(a)的并行效率比较显示atomic 原子更新效率相对更高。图8(b)给出了采用atomic更新和不采用atomic更新的墙上时间差值,差值大于0,采用atomic更新耗时更长,反之,采用atomic更新耗时更短。显然,atomic 原子更新在大规模时效率高,耗时短,优势更加明显,本文测试规模达到万核级别,因此测试中均采用原子更新提高程序并行度,减少程序耗时。

图8 原子更新对并行效率和程序耗时的影响Fig.8 Effects of atomic manipulation on parallel efficiency and elapsed time
除采用atomic原子更新避免数据竞争之外,由于C++中采用大量基于类(Class)的数据结构,如InviscidFluxSolverClass为计算无黏通量的类,直接在类对象中完成计算,可以大量减少以形参和实参形式的数据传值,具有较好的封装性和编程效率,但是在进行线程级并行时,类中的成员数据需要进行并行化以避免数据竞争。HyperFLOW中采用直接对类对象进行线程并行化,如图9所示,每个线程中都有一个计算无黏通量的inviscidFluxSolverObject对象,线程间互相独立,各自进行对象初始化和无黏通量计算,彻底避免数据竞争的问题。

图9 避免数据竞争的对象并行Fig.9 Avoidance of data races via object parallelization
此外,程序中还引入了C++智能指针auto_ptr和shared_ptr,利用智能指针自动删除的特性,避免多个线程在删除指针时,出现内存错误,如图10所示。

图10 智能指针与传统指针比较Fig.10 Comparison of shared pointer and traditional pointer
同时,要注意改造前后计算结果应该保持一致。具体来说,改造后单线程混合并行的计算结果(包括收敛历程和最终结果)应当与改造前完全一致,也即混合并行在单线程时可以退化为纯MPI并行。而在多线程时,由于非结构网格数据存储无序,导致自动分配到各个线程间的数据依赖关系不明确,在隐式LUSGS改造时,难以实现像结构网格那样具有明确依赖关系的流水线式(即前一线程执行完、数据更新后,再通知依赖前一线程数据的下一线程继续执行)的并行求解[15]。
由于粗粒度混合并行是在网格分区上进行的并行,各个分区数据相互独立,发生数据竞争的可能性很小,只需要将全局变量可能存在的数据竞争消除,因此代码的改动量很少。相反,细粒度混合并行要对多个热点函数/类进行改造来实现线程级并行,同时避免数据竞争,代码改动量和难度是粗粒度混合并行的数倍。
3 CRM标模并行效率测试
3.1 OpenMP效率
在2.1节中,采用CRM标模算例进行了纯MPI的效率测试,本节将采用CRM标模算例分别对粗粒度和细粒度混合并行方式进行测试。
将测试网格分别划分为1 024和8 192个网格分区,分别采用64进程和512进程进行粗粒度和细粒度混合并行计算,最小线程数为1线程,最大线程数为16线程。同时,对于细粒度混合并行,也可将测试网格分别划分为64和512个分区,采用对应进程数(64进程和512进程,即分区数与进程数对应)进行并行效率和计算耗时测试,测试算例设置如表3所示。

表3 OpenMP并行效率测试算例Table 3 Test cases for OpenMP parallel efficiency
测试结果如图11所示,图中p代表进程,z代表分区,结果显示:

图11 混合并行OpenMP效率测试结果Fig.11 Hybrid OpenMP parallel efficiency test results
1) 随着线程数增大,几种并行方式的OpenMP并行效率均下降,且分区更多时效率随着线程数增加下降更快。
以512进程为例,在采用不同线程时,粗粒度混合并行(图11(a)中黑色虚线)各线程的OpenMP并行效率分别为81%、56%、35%和17%,细粒度混合并行(大分区数,图11(a)中红色虚线)的并行效率分别为71%、40%、19%和14%;而细粒度混合并行(对应分区数,图11(a)中蓝色虚线)的并行效率分别为86%、68%、45%和25%。可见,OpenMP的线程数增加会导致额外的并行开销,减少线程数有助于提高OpenMP并行效率。
2) 采用对应分区数的细粒度混合并行可以大大减少大规模并行时网格分区数量,提高OpenMP并行效率。采用对应分区数的细粒度混合并行(512进程,512分区,图11(a)中蓝色虚线)效率明显高于大分区数的粗粒度混合并行和细粒度混合并行(512进程,8 192分区,图11(a)中黑色和红色虚线)。
3) 粗粒度混合并行在小规模时更有优势,但是随着并行规模增大,并行效率下降较快,而对应分区数的细粒度混合并行在大规模并行时更有优势。
比如,在进程规模较小时(64进程),粗粒度16线程并行效率能够达到55%,而细粒度(对应分区数)并行效率只能达到40%左右,此时粗粒度混合并行具有一定优势,但是在进程规模较大时(512进程),粗粒度并行效率迅速下降到17%,而采用对应分区数(512分区)的细粒度并行效率也下降到了25%,但是比粗粒度混合并行效率高。同时,从图11(b)中的结果也可看到,在64进程时,粗粒度混合并行耗时最少,而在512进程,16线程时,采用对应分区数的细粒度混合并行耗时最少。
3.2 混合并行的MPI效率测试
由2.1节和3.1节结论可知,当进程数增大时,MPI效率下降,而当线程数增大时,OpenMP效率也会降低。因此,对于某一固定的并行规模,线程数增加,OpenMP效率降低,而同时相应进程数减少,MPI效率提升,因而会存在一个最佳的线程数,此时MPI效率提升效果大于OpenMP效率下降幅度,整体能够达到最佳的混合并行效率。
如图12所示,分别给出了纯MPI并行、不同线程数时粗粒度混合并行效率和细粒度混合并行效率,其中纯MPI测试和粗粒度测试网格均分为8 192个分区,细粒度测试网格分区数对应于最大进程数。
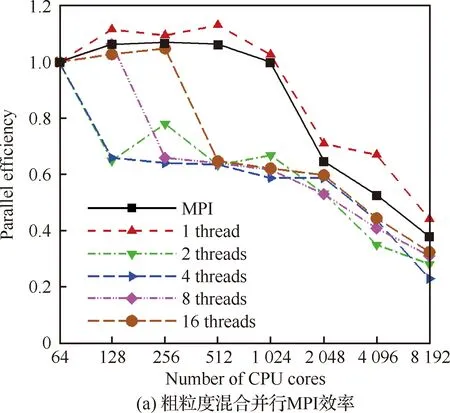
图12 混合并行MPI效率测试结果Fig.12 MPI hybrid parallel efficiency test results
由图12(a)可见,当线程数增大时,粗粒度混合并行效率先下降,在8线程时,并行效率出现小幅回升,并在16线程时最高,达到32.5%(8 192核相对64核),原因是在线程数较少时,OpenMP效率随着线程数增加下降幅度大,如图11(a)所示,在引入2线程时,粗粒度OpenMP效率下降到80%,而MPI效率上升幅度小,如图3所示,8 192 核并行效率从37.9%上升到4 096核的52.5%,导致混合并行效率整体下降,而随着线程数增大、进程数减少,MPI并行效率上升幅度变大,混合并行效率逐渐恢复。
图12(b)结果显示,当线程数增大到8线程时,细粒度混合并行效率达到最高,相对于64核,8 192 核并行效率达到56.5%,高于纯MPI并行效率和粗粒度混合并行效率。
4 大规模并行计算测试
采用双时间步方法进行非定常多体分离数值模拟通常对内迭代的计算精度要求较高,这样才能保证计算误差的累积不会对计算造成致命后果。采用大规模网格进行多体分离数值模拟是减少内迭代误差的手段之一。
针对机翼外挂物投放标模算例,本文在机翼和挂弹原始非结构网格(表4中original,4 500万网格单元)的基础上,通过一次自适应加密,生成了3.6亿非结构混合网格(表4中adapt1),再次进行自适应加密,生成了28.8亿非结构混合网格(表4中adapt2),自适应加密的具体过程参见文献[16]。分离过程动态网格采用非结构重叠网格技术进行装配,方法细节可参考文献[17-19],此处不再赘述。3套网格装配结果如图13所示。

图13 机翼外挂物投放大规模测试网格Fig.13 Large scale grids for wing store separation tests
如表4所示,由于网格量巨大,网格文件达到几十甚至几百GB量级,为减少文件存储和IO耗时,保证程序整体的运行效率,采用基于分组的文件存储模式和对等(Peer to Peer,P2P)模式的文件IO机制[13]。
将adapt1网格分别存储在1 024个文件中,adapt2网格分别存储在8 192个文件中,单个文件大小为15~30 MB左右,在国产in-house集群上,分别采用1 024进程读入网格3.6亿网格,8 192进程读入28.8亿网格,P2P模式耗时分别为13.72 s和37.28 s,达到了较高的IO效率。而相比之下,服务器(Client/Server mode,CS)模式读入网格的时间要长得多,如表4所示。

表4 机翼外挂物标模网格大小及网格读入耗时Table 4 Grid size of wing-store standard model and time spent on reading grid files
在国产in-house集群上分别采用不同进程数对3套不同规模网格进行重叠网格隐式装配和非定常计算。结果如表5所示,对4 500万网格采用128进程进行重叠网格装配和非定常计算,重叠网格装配耗时42.65 s,内迭代50步耗时757.5 s,重叠网格装配耗时与非定常内迭代计算耗时比值在5%左右。对3.6亿网格采用1 536进程×8线程进行重叠网格装配和非定常计算,重叠网格装配耗时17.56 s,内迭代50步耗时277.4 s,重叠网格装配耗时与非定常内迭代计算耗时比值也在5%左右。对28.8亿网格采用12 288进程进行重叠网格装配,耗时仅需52.52 s。

表5 机翼外挂物标模网格装配信息Table 5 Grid assemble information of wing store model
4.1 3.6亿非结构重叠网格万核并行测试
将3.6亿adapt1网格分为12 288个分区(机翼网格8 192分区+外挂物网格4 096分区),分别在国产in-house集群和天河2号上采用8线程细粒度和8线程粗粒度混合并行进行非定常多体分离测试,最小测试规模为384核(48进程×8线程),最大规模为12 288核(1 536进程×8线程)。
湍流数值模拟仍采用前述二阶精度有限体积离散的RANS方程求解,测试算法为双时间步非定常方法,内迭代步采用LUSGS隐式时间推进,内迭代步数取50步,无黏通量选择Roe格式,黏性通量选择法向导数法,湍流模型选择SA模型,气动/运动采用松耦合方式进行求解[20]。
图14给出了在国产in-house集群(图中标记为CARDC)和天河2号(图中标记为TH2)上的并行效率和墙上时间测试结果。结果显示,在CARDC的in-house集群上,细粒度12 288核并行效率能够达到90%(以768核为基准)。在天河2号上,并行效率能保持在70%(以384核为基准),而此时纯MPI效率和粗粒度混合并行效率已经下降至50%(以384核为基准)。这再次证实了MPI效率在大规模并行时存在瓶颈,同时在大规模并行时,粗粒度混合并行效率也低于细粒度混合并行效率。
图14(b)给出了不同并行方式墙上时间的对比。结果显示,在小规模时纯MPI并行的墙上时间最小,而由于并行开销大,细粒度混合并行的墙上时间最大。随着并行规模增大,由于纯MPI效率逐渐低于混合并行,导致墙上时间的优势逐渐消失。在12 288核时,纯MPI和混合并行墙上时间接近,如果进一步增大并行规模,随着混合并行效率优势扩大,混合并行墙上时间有望小于纯MPI。

图14 机翼外挂物投放大规模并行测试Fig.14 Large-scale parallel tests for wing store separation
采用12 288核混合并行(1 536进程×8线程)进行多体分离计算,并与试验结果进行对比,如图15所示,图中ux、uy、uz、dx、dy、dz、Cfx、Cfy、Cfz和ψ、θ、φ分别表示惯性系中挂弹在3个方向的速度、位移、气动力系数和欧拉角;ωx、ωy、ωz和Cmx、Cmy、Cmz分别表示挂弹在体轴系3个方向上的旋转角速度和气动力矩系数,其中“EXP”表示试验结果,不带“EXP”为本文数值模拟结果。结果显示计算结果与试验结果[21]符合良好,验证了混合并行计算结果的正确性,图16给出了分离过程中典型时刻的重叠网格。

图15 混合并行计算结果与试验结果对比Fig.15 Comparison of hybrid parallel numerical and experimental results

图16 机翼外挂物投放典型时刻重叠网格Fig.16 Overset grids during wing store separation process
4.2 28.8亿非结构重叠网格4.9万核并行测试
通过机翼外挂物28.8亿超大规模网格进行非定常多体分离效率测试,验证本文发展的混合并行方法的可扩展性。
如4.1节中所述,将adapt2网格划分为98 304个 分区,分别存储在8 192个文件中,最少采用512进程×8线程,即4 096核进行测试。最大采用6 144进程×8线程,即49 152核进行测试。测试算法与4.1节相同。
图17给出了在国产in-house集群上的并行效率和墙上时间测试结果。结果显示在4.9 万核时,以4 096核为基准并行效率达到55.3%,加速比达到6.6。

图17 机翼外挂物投放超大规模并行测试Fig.17 Massive parallel test for wing store separation
表6给出了不同并行规模时,28.8亿网格计算单元壁面距离、重叠网格装配及内迭代等几个主要计算步骤的墙上时间。由表中数据可见,重叠网格装配耗时与50步内迭代耗时之比约为7%,在整个计算耗时中仅占很小一部分。而在并行规模较小时,由于单核网格量较大,如512进程×8线程,即4 096核,此时单核网格量达到70.3万,单元最近壁面的查询量较大,导致壁面距离计算耗时较大。

表6 超大规模网格并行测试各功能耗时Table 6 Time spent on main operations of massive scale parallel test
在采用4.9万核时,计算壁面距离耗时约3 200 s,重叠网格装配时间约为59 s,内迭代计算时间约为700 s,总的来说单个外迭代步耗时约为1 h。因此,在该集群上,对于一个28亿网格量级的多体分离非定常数值模拟任务,采用5万 核进行数值模拟,预计在7~10天左右能够得到200步外迭代的数值模拟结果。该结果比目前采用百核进行千万量级网格多体分离数值模拟周期(大概2~3天)仍长出不少,主要是因为最小壁面计算耗时太多,在后续工作中,需要专门针对壁面距离算法进行优化和改进[21-22]。为进一步提高加速比,缩短模拟时间,还可以引入GPU并行计算,比如基于MPI+OpenACC的CPU/GPU混合并行[23-24]等。
5 结 论
本文首先实现了两种方式的MPI+OpenMP混合并行:粗粒度混合并行和细粒度混合并行。其次,通过CRM标模(4 000万非结构网格)算例,对OpenMP并行效率和混合并行效率进行了测试。最后,为验证混合并行在超大规模非定常算例中的可扩展性,分别采用3.6亿和28.8亿重叠网格进行了多体分离非定常数值模拟和并行效率测试,得到如下主要结论:
1) 随着进程数增大,纯MPI并行效率存在瓶颈。如在本文的测试中,并行效率由1 024核时的99%下降到8 192核时的38%。
2) 由于OpenMP并行效率随着线程数增加而单调下降,因此对于固定的并行核数规模,存在一个最优线程数。在本文的测试环境中,粗粒度混合并行最优线程数为16线程,而细粒度混合并行最优线程数为8。此时细粒度混合并行效率高于纯MPI并行效率,具有一定的效率优势。
3) 分别采用1 536进程和12 288进程对3.6亿网格和28.8亿网格进行文件并行读入和重叠网格并行装配,耗时均在几十秒内,对大规模非定常计算而言,耗时基本可以忽略,已经达到了较高的效率。
4) 采用细粒度混合并行完成了对3.6亿网格的非定常多体分离数值模拟,计算结果与试验结果符合较好,验证了混合并行计算的精度。
5) 对于3.6亿网格,在国产in-house集群上,12 888核并行效率达到90%(以768核为基准),在天河二号上,并行效率达到70%(以384核为基准);对于28.8亿网格,在国产in-house集群上,4.9万核并行效率达到55.3%(以4 096核为基准),通过上述算例验证了本文混合并行改造方法的可行性。
当然,需要特别指出的是,目前仅在国产in-house集群和“天河二号”上进行了测试。这两台机器均属于“胖节点”型的集群,即每个计算节点内有若干CPU,每个CPU内有若干核,而计算节点间利用高速互联网络相连。对于其他架构的并行计算机,本文的结论是否同样适用尚待进一步验证。
未来将进行更大规模并行测试,同时根据计算机体系结构的特点,开展大规模异构并行计算方法研究,比如开展MPI+OpenMP+CUDA或者MPI+OpenACC的混合并行研究,以使程序适应基于CPU+GPU等环境的异构体系计算机。此外,将进一步改进隐式方法的细粒度混合并行,提高隐式格式收敛效率;改进壁面距离计算方法,减少壁面距离计算耗时。
致 谢
感谢中国空气动力研究与发展中心计算空气动力研究所邓亮博士的指导。
