基于加权极限学习机的货车篷布识别技术探讨
2020-11-05宋坤骏张萼辉中国铁路上海局集团有限公司科研所
宋坤骏 张萼辉 中国铁路上海局集团有限公司科研所
1 引言
为有效防止货车篷布破损使货物受潮或篷布绳网断裂导致篷布脱落,目前上海局大型货站每日需要人工检查的高清篷布照片数在3万张左右,工人长时间看图容易导致视觉疲劳,不仅检查效率低下还使得误检和漏检层出不穷,存在安全事故隐患[1]。由此可见,研发一套机器视觉车顶照片自动判别系统可以有效降低人工支出,提升看图效率和准确度,为上海铁路局货运建设提质增效提供基础技术支撑。工人需要查看的货车车顶样例图片如图1和图2所示,图1和图2分别是没有篷布的货车车顶原始照片和有篷布的敞车车顶的原始照片。

图1 一张没有篷布的货车车顶样例图片
图2 一张有篷布的敞车车顶样例图片
由样例图片可见,单凭人工过滤几万张图片不仅成本高企,效率低下,不利于工人身心健康和工作积极性,也无法保证准确率。
2 算法描述
完整的篷布故障识别问题实际上是一个多分类问题,包括无篷布,正常篷布,问题篷布等类别,其中问题篷布又可以细分为篷布破洞,绳网断线,篷布积水等类别。为了提升准确率起见,将此多分类问题转化为多个二分类问题,即首先分辨是否有篷布,然后判断篷布是否有故障。针对判断篷布有无的问题,笔者曾尝试过基于深度学习的图像分类算法,然而深度学习准确率并不能达到较高水平如95%以上,并且对于硬件要求较高,训练耗时长于本文提出的算法。因而,笔者抓住篷布独有的交叉斜向网格绳网特点,建立了灰度图的方向梯度直方图(Histogram of Oriented Gradient,HOG)特征[2]。该特征的建立步骤如下:将图像灰度化并Gamma校正后划分为多个cells(例如16*16像素/cell),统计每个cell中像素点的梯度方向的直方图,形成各个cell的HOG特征描述子,然后将各个cell组织成block(例如2*2个cell/block),block中所有cell的特征描述子串联起来得到该block的HOG特征描述子。再把图中所有block的特征描述子串联起来就可以得到该图的HOG特征向量了。由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间邻域上。
完整的检测篷布有无的算法步骤如下:
(1)将图像灰度化以后用双三次插值法统一缩放到高128,宽320的尺寸。
(2)以16×16像素的cell大小,2×2cells的block大小提取block无交叠的HOG特征,梯度方向统计范围为-180度到180度之间均匀分布的9个区间。
(3)将各幅图像的HOG特征向量排列成特征矩阵作为加权极限学习机的输入进行训练,其中权重为训练集中每类样本数的倒数。
(4)使用训练好的加权极限学习机模型对测试样本进行预测判断篷布有无。
为了判断篷布是否存在破洞,绳网断线,积水等情况,HOG这种刻画物体形状的特征不适合描述。以样本数最多的篷布积水情况为例,肉眼识别时主要依赖存在的反光现象,因此引入另一个描述灰度变化的纹理特征描述子LBP(Local Binary Pattern)来辅助篷布故障情况的判断。某像素点LBP特征的计算原理是考虑一定采样半径的圆形邻域内的邻近像素点,假设采集P个采样点,将这P个采样点的灰度值同该中心点灰度值比较,若采样点灰度值大于中心点灰度值,则该采样点位置标记为1,否则为0,这样P个采样点可以形成P位二进制数,即为中心点的LBP值,可以反映该邻域的纹理信息。该定义仅仅满足灰度不变性,为了得到旋转不变的特征,研究人员提出如下改进:不断旋转圆形邻域得到一系列LBP值,取最小值作为邻域的旋转不变LBP特征。
除了HOG和LBP这些经典的特征,作者还提出了一种手工构造的特征,能够较好的反映积水图片的反光特点。该特征的构造方法为:首先将图像的四周各裁去50像素以去除不含篷布网绳的无关部分。裁剪后的图像转为灰度图,并用双三次插值法缩放到高514,宽2400的尺寸。随后将该灰度图等分为48小块,高度方向4等分,宽度方向12等分。对每一小块,找出该小块中灰度值最高的一个像素点,然后在该像素点的上下左右四个方向计算该像素点的灰度值同周围像素点灰度值之差。其中每个方向都取同该像素点距离为10,15,20,25,30个像素的邻近点计算灰度差值。若这些距离处的邻近点越出边界,则取为边界点。
由此可以得到在盖有篷布的货车顶照片中识别故障篷布的完整算法如下:
(1)将图像灰度化以后用双三次插值法统一缩放到高614,宽1200的尺寸。
(2)在每一像素半径为2像素的圆形邻域内采集8个采样点计算旋转不变的LBP特征,计算邻近采样点时采用线性插值。
(3)再将图片裁剪灰度化后缩放到高514,宽2400的尺寸提取上述手工特征。
(4)将LBP特征和手工特征排列成特征矩阵,并用MINMAX方法归一化特征矩阵的每一列。
(5)特征矩阵作为加权极限学习机的输入进行训练,其中权重为训练集中每类样本数的倒数。
(6)使用训练好的加权极限学习机模型将有篷布图片分为正常或故障两类。
以上算法中涉及的极限学习机的理论在文献[4]中有较为详细的介绍。考虑到苫盖有篷布的敞车数量远少于没有篷布的其他货车数量,训练集样本是不均衡的,因此采用了样本加权的方式考虑不均衡性。所述加权正则化极限学习机的理论概要如下,设单隐层前馈神经网络的输出层和隐层神经元数分别为m和l,则关于输入特征向量的第j维输出表达式为:
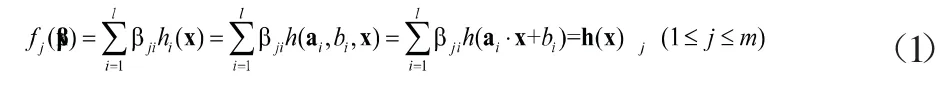
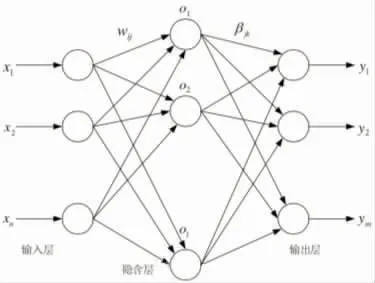
图3 极限学习机神经网络结构示意图
加权正则化极限学习机采用的是逐样本加权的方式,每个样本的训练权重等于训练集中该类样本的样本数的倒数,可以证明这是最优的权重。所有样本的权重排列成一个N×N对角矩阵W。其中N是训练集样本数。加权正则化极限学习机输出层权值β的学习结果由如下公式给出:

上式中C是正则化参数,通过反复试验,针对本问题正则化参数C取为30。W是样本权重矩阵,H是隐层输出矩阵,由如下公式给出:
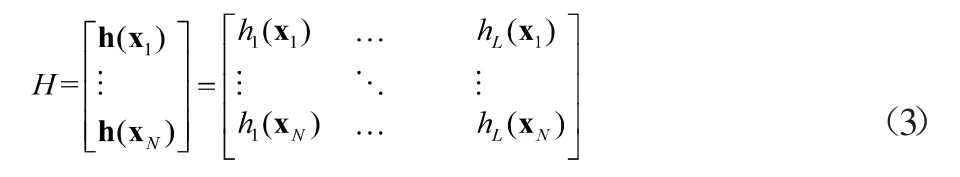
根据以上公式得出极限学习机的算法步骤如图4所示:
图4 极限学习算法应用步骤
3 算法运行结果
以上两个算法在数据集上的运行结果如下:
就区分有篷布的敞车和其他无篷布货车的算法来说,训练集包含2872张有篷布苫盖车顶照片以及3088张无篷布车顶照片。测试集包含7197张有篷布苫盖车顶照片和102099张无篷布车顶照片。所有图片均为三通道彩色图片。除极少数图片外,各图片高度统一为614像素,宽度大致分布在2000-3100像素间。算法在如上数据集上取得了99.98%的训练集准确率以及96.40%的测试集准确率和99.61%的测试集召回率。
在另一套数据集中,训练集包含3548张图,其中有篷布苫盖的图有1739张。无篷布的图有1809张。测试集包含115004张图,其中无篷布的图有106674张,有篷布的图有8330张。区分篷布有无的算法取得了99.71%的测试集准确率,99.13%的测试集精确度和96.90%的测试集召回率。
就区分篷布是否有故障的算法而言,共有10069张有篷布车顶照片,正常苫盖状态篷布为一类,问题篷布为另一类,训练集1739张图片,测试集8330张图片,训练集和测试集中正常图片,积水图片,断线和破洞图片张数比例大致和10069张图的数据全集相同。在这样的训练集和测试集条件下,该算法取得了99.88%的训练集准确率以及95.94%的测试集召回率和69.94%的测试集准确率。
区分篷布是否有故障的算法,如果去掉LBP特征,单用笔者构造的手工特征可以起到提升准确率的效果。单用手工特征的加权极限学习分类器在935个训练样本上训练后能够在9134个样本的测试集上取得87.83%的准确率。但是召回率仅有75.05%。原因在于,同上文以LBP和手工特征为特征的分类器相比,误分类的负样本数FN增加,而误分类的正样本数FP减少了。
本文介绍的算法训练时对于硬件要求低,不需要GPU,速度能够满足实际工程要求。其次由于本算法准确率较高,因而其人工标定成本也较低。标定时可以先手工标定小量几百张训练图片用算法预运行一趟得到全部图片粗估分类值,然后再予以人工修正即可,大大减轻了手工标定数万张图的工作量。
