虚拟机迁移中一种新的物理主机异常状态检测算法
2020-11-03徐胜超
徐胜超
(广东财经大学华商学院 数据科学学院, 广东 广州 511300)
0 引言
在云数据中心中如何检测出运行异常的物理节点并进行负载均衡操作是一个关键问题[1-2],目前大部分云服务提供商都采用虚拟机迁移技术[3]。
物理主机异常状态检测需要对即将迁移的源物理主机和目标物理主机都要进行负载判断,这些负载基本都封装成虚拟机的形式,周期性的检测之后,形成负载异常的物理主机列表,从而为后续的虚拟机选择过程和虚拟机放置过程提供输入参数。
目前已有的物理主机状态检测方法大多采用静态资源使用率阈值边界来确定主机是超负载或者低负载,其资源的边界考虑的维度因素也比较单一;其针对的云客户端也不是自适应的,以被动的方式检测为主。因为物理主机资源状态是一种随着时间和应用程序的访问而不断动态变化的,这对主机异常状态检测方法提出了新的要求。
为此本文提出了一种新的物理主机异常状态检测算法PHSDA(physical host status detection algorithm)。PHSDA是一种自适应的、动态的物理主机检测方法,它采用时间序列和线性回归来预测出物理主机在未来的一段时间内的资源使用率情况,来确定其阈值边界,是一种主动检测策略。PHSDA检测策略配合后续虚拟机选择阶段和虚拟机放置阶段的其它优化方法,就构成了一个完整的新型虚拟机迁移模型。最后描述了PHSDA物理主机状态检测策略的实现和仿真,结果表明PHSDA可以选择适当的时刻进行虚拟机的迁移,提高物理资源的利用效率,降低能量消耗。
1 相关工作
本文重点考虑物理主机状态检测阶段,在Cloudsim工具包中也称为物理资源阈值管理策略,这种资源阈值管理策略可以分为主动法和被动法,其中被动的方法意味着在物理主机的资源已经超过阈值边界之后再采取动作;主动的方法是指通过观察资源使用的样本数据在前一阶段的利用率情况,提前预测出可能出现状态的物理主机,接着进行虚拟机迁移的后续步骤。
PHSDA依托于Cloudsim项目,它把物理主机异常划分为超负载over-utilized或者低负载under-utilized状态,常见的有6种策略[3]。
文献[4]提出一个自适应的三阈值主机状态检测方法,把物理主机根据资源使用阈值划分为小负载,轻负载,中负载和高负载四个状态,采用k-means算法来管理这些阈值,实验结果表明该物理主机状态检测算法可以减少云数据中心的能量消耗和SLA违规比率,但是性能提高不是很明显。
文献[5]采用一个局部代理来检测物理主机状态,把物理主机划分为超负载、预高负载、低负载和正常状态4个状态,采用LiRCUP方法来预测超负载的物理主机,避免SLA违规率,测试结果表明它比Cloudsim中已有的检测方法性能有提升。
近年来也有大量的采用智能算法进行优化物理主机状态检测的文献,例如处理器温度感知[6]、遗传算法[7]、虚拟机关联性[8]、二次指数平滑预测[9]等,这些文献在研究思路,测试指标等方面基本上都参考了Cloudsim项目。
2 工作背景与相关术语
2.1 物理主机状态检测的工作场景
图1显示了PHSDA物理主机状态检测的工作场景,这是一个典型的云客户端对云数据中心的服务请求场景。PHSDA依托了Cloudsim各个运行模块:全局代理Global Broker、本地代理Local Broker、虚拟机管理器Virtual Machine Manager。
在Cloudsim中每个物理主机上都运行有一个本地代理Local Broker,PHSDA优化策略的实现主要在此模块中完成。这个工作场景在文献都有描述[3]。
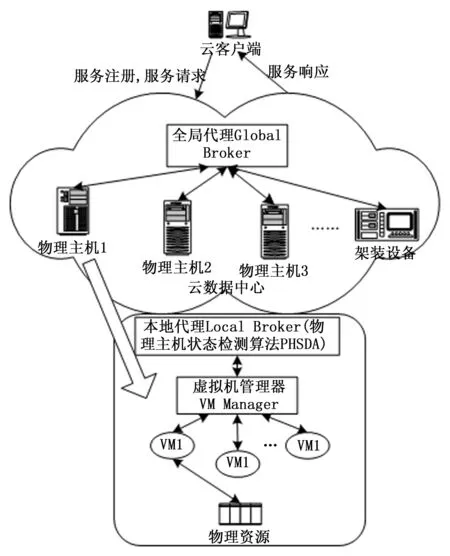
图1 PHSDA物理主机状态检测的工作场景
2.2 PHSDA优化的虚拟机迁移流程
PHSDA运用到整个虚拟机迁移过程中,工作流程具体包括下面4个步骤:
步骤1:基于PHSDA,周期性的检测云数据中心的物理主机,形成HostsToMigrateList;
步骤2:基于最小迁移时间选择MMT算法完成虚拟机选择[3],形成selectedVMList;
步骤3:基于递减装箱算法BFD优化完成虚拟机的重新放置[3];
步骤4: 重复上述步骤1~3,通过设置一个是周期(通常是一周),达到该时间段就结束;
图2显示了经PHSDA物理主机状态检测优化后的虚拟机迁移工作流程。
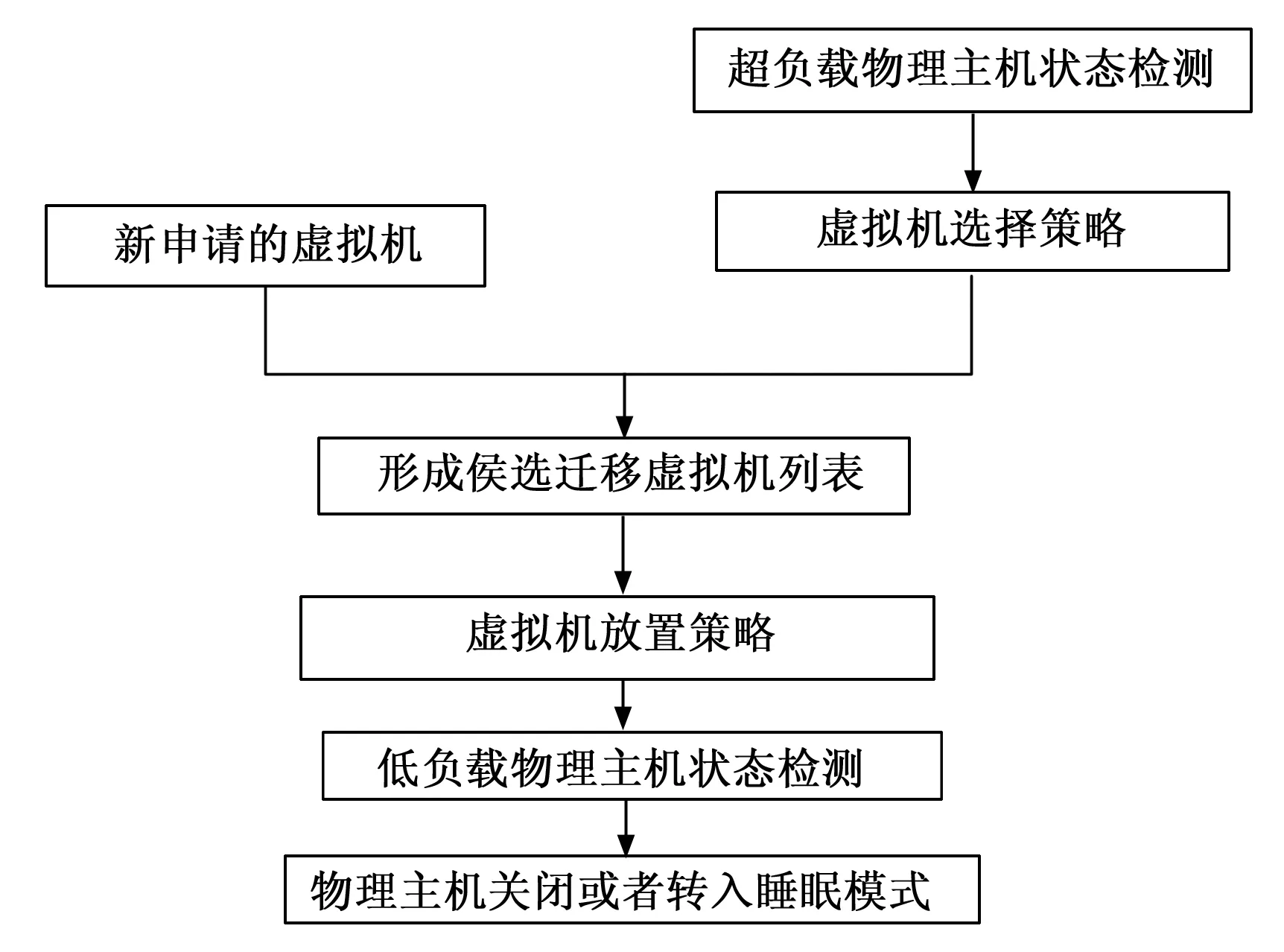
图2 PHSDA优化的虚拟机迁移工作流程
2.3 相关术语
2.3.1 云数据中心的能量消耗
云数据中心主要由大量的堆积在一起的物理主机组成,所以其能量消耗主要由物理主机的所有部件的能量消耗组成。已有经验表明一个物理服务器(双核CPU、四条内存、一个磁盘、2个PCI插槽,一个主板等)所消耗的能量大约为CPU占41%,内存占18%,磁盘占7%,PCI插槽占23%,主板占12%。基于这个思路,PHSDA策略中设计的物理主机的能量消耗数学模型如公式(1)~(6):
E(Ucpu)=Eidle+(Emax-Eidle)Ucpu
(1)
(2)
E(Umem)=Eidle+(Emax-Eidle)Umem
(3)
E(Ubw)=Eidle+(Emax-Eidle)Ubw
(4)
Ehost=E(Ucpu)+E(Umem)+E(Ubw)
(5)
这里Ucpu(t)、Umem(t)、Ubw(t)表示物理主机在t时刻的CPU使用率、内存使用率、磁盘使用率、网络带宽使用率:
0%≤Ucpu(t),Umem(t),Ubw(t)≤100%
(6)
Eidle表示物理主机CPU、内存、网络带宽在空闲时的能量消耗,即是Ucpu(t)=0、Umem(t)=0、Ubw(t)=0的时候。
Emax表示物理主机在满负载时的能量消耗,即是Ucpu(t)=100%、Umem(t)=100%、Ubw(t)=100%的时候。
mipsi,c是第i个虚拟机VMi的第c个处理单元的mips请求情况。
MIPSj,c是第j个物理主机Mj的第c个处理单元的整体的MIPS计算能力。pei表示虚拟机VMi的处理单元的数量,PEj表示物理主机Mj的处理单元的数量,rj(t)表示分配到物理主机Mj的虚拟机的索引集合。
一个虚拟机请求的MIPS的数量是随着应用程序变化而变化的,所以物理主机的资源使用率也应该是随着应用程序的变化而变化,因此统计物理服务器的能量消耗必须在一定的时间段内,这样根据公式(1)可以演化为公式(7):
Ehost(t)=E(Ucpu(t))+E(Umem(t))+E(Ubw(t))
(7)
这样第j个物理主机在[t0,t1]时间段的总体能量消耗Ehost可以按照公式(8)来计算:

(8)
整个云数据中心的能量消耗为:
(9)
2.3.2 SLA违规在线时间
当一个云客户端提交作业到云计算平台的时候,资源缺少就会出现 (SLA,service level agreement)违规,在虚拟机分配过程中,一个重要性能指标就是每个物理主机的SLA在线时间SLA violation Time per Active Host (SLATAH),它体现了物理主机具有高服务质量的在线时间情况。
(10)
云数据中心的主机数量和虚拟机数量分别由M和N表示,其中Tsi是物理主机CPU利用率达到100%的时间,Tai是物理主机处于在线活跃状态的时间。
2.3.3 虚拟机迁移后的性能降低(PDM,performance degradation due to migrations)
(11)
其中:Cdi是由于虚拟机VMi迁移导致的性能下降的估计值,Cri是请求虚拟机VMi的整个时间段内总的CPU MIPS计算能力。
2.3.4 能量与SLA违规的联合指标 (ESV)
SLA的违规率的计算通过公式(12)计算:
SLAViolation=SLATAH*PDM
(12)

ESV=Etotal*SLAViolation
(13)
3 物理主机状态检测算法描述
3.1 超负载主机检测过程
正如前面所提到的,PHSDA把云数据中心的物理主机按照工作状态划分为4类:超负载(over-loaded)、高负载(under-pressure)、正常状态 (normal)、低负载状态(under-loaded),这样其对应的物理资源的阈值边界也对应三个:Upper-Thredholds 、Pre-Thredholds、Lower-Thredholds如图3所示。
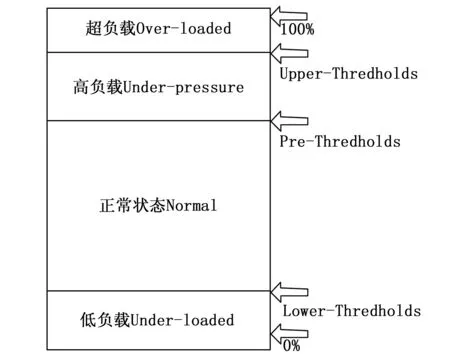
图3 PHSDA中物理主机的状态分类
PHSDA的最终目的是从云数据中心的物理主机中检测出异常状态的节点,通过设置一个时间间隔,周期性的执行PHSDA算法。PHSDA检测算法是基于物理主机的CPU资源、内存资源、网络带宽资源的使用情况。当PHSDA算法启动后,周期性的检测这3个资源的使用情况,并尽量使其在合适的阈值范围内(Upper-Thredholds、Pre-Thredholds、Lower-Thredholds)。如果有某个物理主机的资源使用情况不在这个合理的范围内,它将被列入侯选迁移物理主机列表HostsToMigrateList。
回归是统计学中的一种量化数据分析方法,它可以预测数据的下一阶段的值,回归方法被广泛使用在数据预测领域[10]。回归技术有两种模型,单个输入的单一回归和多个输入的多回归。它采用回归函数(线性或非线性)来估计出输入变量X和输出变量Y之间的关系。PHSDA算法采用了单一权值线性回归来预测物理主机的资源使用效率情况。该思想如公式(14)所示:
Y=β0+β1X
(14)
这里Y是受依赖的变量,X是独立的变量,β0和β1是回归系数,它们来自于最小二乘法技术[11],如下所示:
(15)
(16)
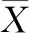
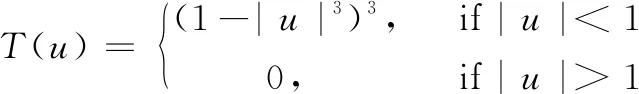
(17)
基于上面的这个公式,相邻区域权重的定义如公式(18):
(18)
这里xi和xn是变量x的最近的第i个观察值,PHSDA算法采用k次迭代来检测物理主机资源使用效率变量(host utilization)的k个将来预测值,对于n个数据变量,回归的函数定义如下:
(19)

(20)
在这个情况下有如公式(21):

(21)
这里c是密度常量,下面的Algorithm 1 和Algorithm 2显示了物理主机状态检测PHSDA算法的伪代码。
Algorithm 1: Overloading Host Detection Algorithm
Input:host
Output: overloadedList;
1. UTC ←PHSDA (CPU).upperThreshold;
2. PUC ←PHSDA (CPU).utilPrediction;
3. UTM ←PHSDA (Memory).upperThreshold;
4. PUM ←PHSDA (Memory). utilPrediction;
5. UTB ←PHSDA (BW).upperThreshold;
6. PUB ←PHSDA (BW). utilPrediction;
7. if ((PUC or PUM or PUB )>=1 ) then
8. underPressureList ← host;
9. Host will not accept new VM;
10. else
11. if ((UTC or UTM or UTB)>=1) then
12. overloadedList ← host;
13. end if
14. end if
15. return overloadedList;
Algorithm 2: PHSDA algorithm
Input: host utilization
Output: utilPrediction
1. for i=1 to n do
2.xi←i;
3.yi← utilHistory(i);
4.wi← calculate using equation (18);
5.xi←xi*wi;
6.yi←yi*wi;
7. end for
8. calculateβ0, using equation (15);
9. calculateβ1, using equation (16);
10. utilPrediction=β0+β1*currentUtil(h);
11. upperThreshold = utilPrediction;
12. updatex,yandw;
13. updateβ0andβ1;
14. fori=2 tokdo
15.KPredictionUtil(i)=β0+β1*utilPrediction;
16.utilPrediction=KPredictionUtil(i);
17. end for
18. return utilPrediction;
3.2 低负载主机检测过程
在完成了超负载物理主机状态检测之后,就进入到后面的虚拟机选择和虚拟机放置阶段,这样PHSDA算法的第一阶段结束。在虚拟机迁移完成后,必要进入低负载物理主机检测阶段,PHSDA可以把低负载物理主机转入睡眠模式或者关闭其电源,节省能量消耗。
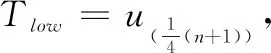
(22)
(23)
在低负载物理主机检测中,PHSDA算法维护着一个低负载物理主机列表under-loaded hosts,首先检测这些机器上的虚拟机是否可以迁移到其他的物理节点,对于一个可以容纳虚拟机的物理主机,必须具有3个条件: 1)处理高负载状态;2)有足够的物理资源满足虚拟机的要求;3)在容纳虚拟机后,它不能变成超负载状态;如果低负载状态的物理主机上的虚拟机都迁移到其他的节点,它将切换到睡眠模式,进一步节省云数据中心的能量消耗。具体的算法描述见下面Algorithm 3的伪代码:
Algorithm 3: Under loading Host Detection Algorithm
Input: hostList , hostVMlist
Output:VMmigrationList
1. for each h in hostList do
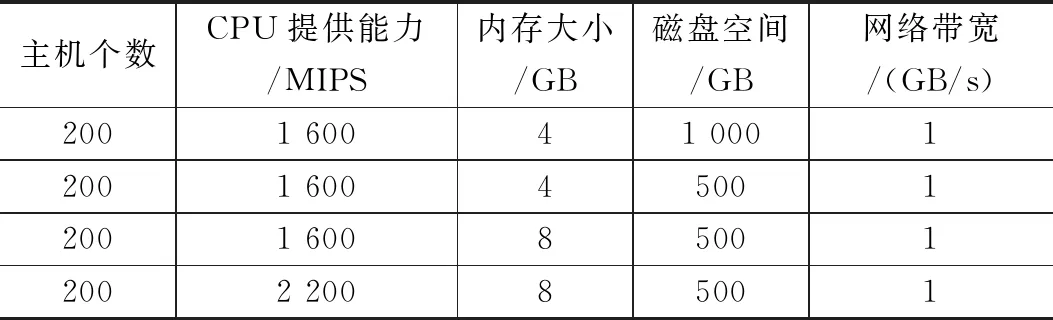
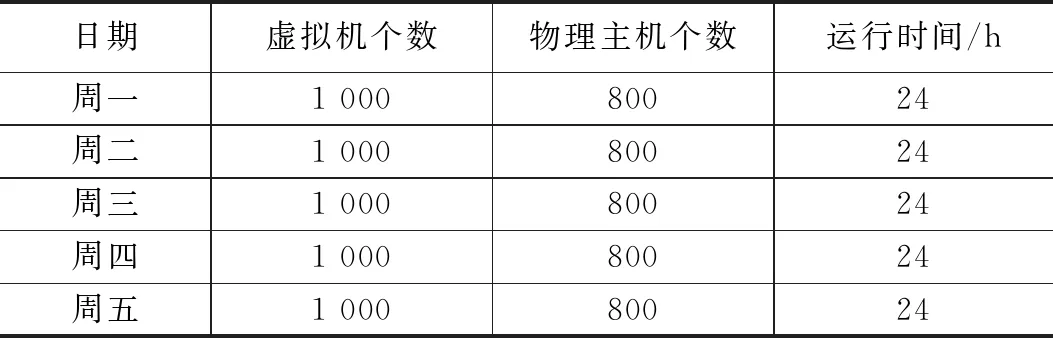
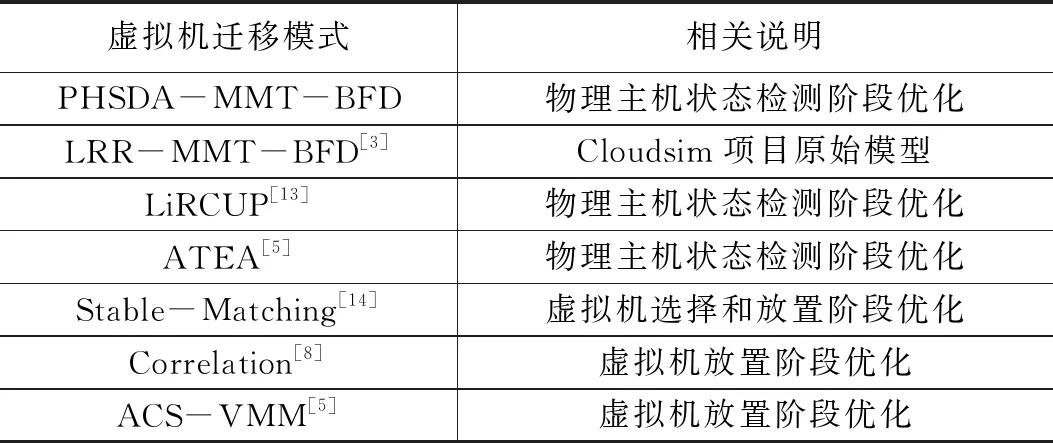
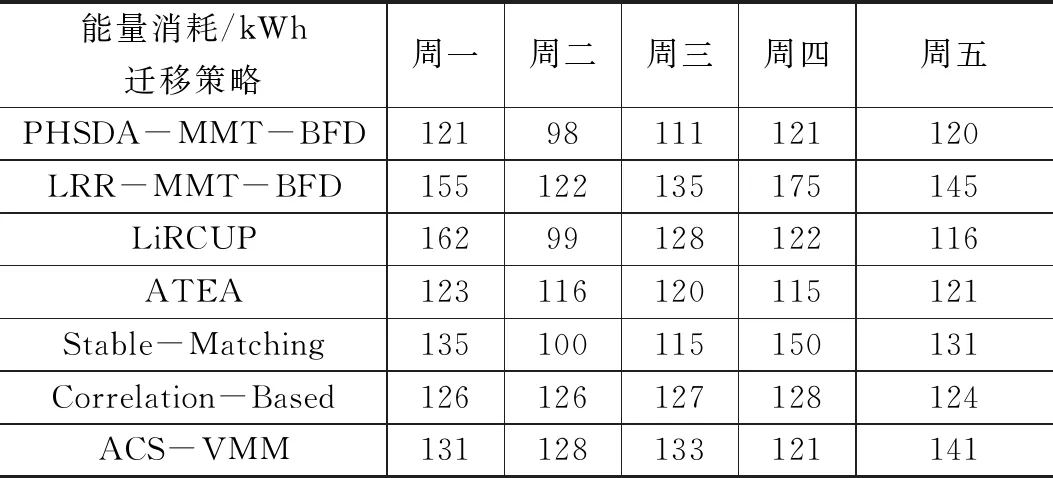
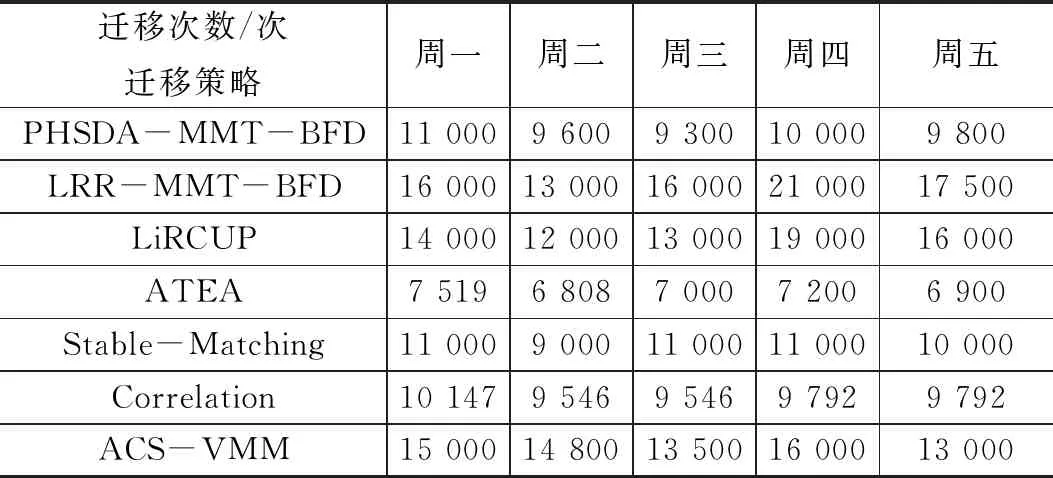
2. if ((h.utilCPU)< Tlow(CPU)) && ((h.utilRAM) 3. underloadingList ← h; 4. end for 5. for each h in underloadingList do 10. underloadingList.sortIncreasingUtil(); 11. end for 12.for each h in underloadingList do 13. for each VM in hostVMlist() do 14. for each host in hostList do 15. if( host ∉ underPressureList) then 16. if ((host has enough CPU, RAM and BW) && ( Not overloaded after VM migration) ) then 17. VMmigrationList ← h.VM; 18. hVMlist← hVMlist- h.VM; 19. break; 20. end if 21. end if 22. end for 23. end for 24. if (hVMlist = null) 25. return VMmigrationList; 26.end if 27. end for 因为PHSDA物理主机异常检测算法是在虚拟机迁移过程中运用的,所以进行PHSDA实验分析,我们构造了Cloudsim3.0云数据中心的虚拟机迁移场景,云数据中心的能量消耗模型及测试指标都参考了最常见的CoMon project,它 是由planetlab实验室开发的一个项目[12]。在CoMon项目中设置的云数据中心主要由两类物理服务器组成,物理服务器总数为800个,物理服务器配置如表1所示。 一周内不同虚拟机请求个数如表2所示。 本文的PHSDA物理主机异常检测算法结合其他虚拟机选择和虚拟机放置阶段,即形成了PHSDA-MMT-BFD虚拟机迁移模型。 表1 云数据中心物理服务器硬件配置 表2 一周内不同的虚拟机请求个数 我们还与近年来的其他物理资源阈值管理办法进行了比较,例如LiRCUP检测方法、ATEA检测方法,分析这些物理主机异常状态检测对云数据中心的性能改变情况。综上所述,本实验一起涉及到的虚拟机迁移模式如表3所示。 表3 PHSDA物理主机状态异常检测略性能比较对象 4.3.1 云数据中心总体能量消耗 利用PHSDA物理主机状态检测阶段的优化之后,各个虚拟机迁移模型一周之内的总体能量消耗如表4所显示。PHSDA-MMT-BFD迁移模型比其他各个迁移策略在总体能量消耗上要节约15%~30%。分析原因是PHSDA-MMT-BFD模型可以很好地检测出异常物理主机的状态,确定好迁移的时刻,资源利用效率自然提高,关闭没有必要启动的空闲物理主机,所有云数据中心的总体能量消耗自然减少。 表4 各类虚拟机迁移策略的总能量消耗比较 kWh 4.3.2 虚拟机迁移次数 表5显示了在一周的5天之内PHSDA-MMT-BFD的虚拟机迁移次数基本最小。原因是LRR-MMT-BFD很容易增加超负载或低负载的物理主机的数量,而PHSDA-MMT-BFD策略则与LRR-MMT-BFD正好相反,它利用回归预测法预测出物理资源的利用效率,动态地确定阈值边界,不会增加虚拟机迁移次数。另外ACS-VMM策略、Stable-Matching策略的优化主要在虚拟机放置阶段,必须像Correlation-Based策略在虚拟机选择阶段、物理主机状态检测阶段完成优化才好降低迁移次数。 表5 各类虚拟机迁移策略的虚拟机迁移次数 4.3.3 SLA违规率分析 从表6可以看出,周一到周五,PHSDA-MMT-BFD都比较少出现SLA违规,原因是PHSDA-MMT-BFD比递减装箱办法的优化能力要强,而且从本文设计的能量消耗模型来看,PHSDA-MMT-BFD考虑的迁移因素的维度范围不仅仅限制在CPU方面,还考虑了内存大小,磁盘空间及网络带宽。 LiRCUP、Stable-Matching、Correlation-Based和ATEA在某些时候还优于PHSDA-MMT-BFD策略,PHSDA-MMT-BFD以降低虚拟机迁移次数为目标,所以也会牺牲一些SLA违规率的增加。 表6 各类虚拟机迁移策略的SLA违规率比较 4.3.4 能量与SLA违规的联合指标ESV 从表7中的结果可以看到,PHSDA-MMT-BFD的ESV指标不是最好的,Stable-Matching和Correlation-Based策略针对原始的Cloudsim各个阶段都有优化,自然比LRR-MMT-BFD迁移策略性能好,ACS-VMM迁移策略的ESV最低,它比单一目标函数的PHSDA-MMT-BFD迁移策略在ESV方面要低。 表7 各类虚拟机迁移的SLA与能量消耗联合指标ESV 本文提出了虚拟机迁移中一种新的物理主机状态异常检测算法PHSDA, PHSDA利用统计学中回归函数操作,经过多次循环迭代预测出云数据中心的物理资源的利用效率的Upper-Thredholds 、Pre-Thredholds值;在低负载检测中利用多维资源的均方根确定利用效率下界Lower-Thredholds;PHSDA物理主机状态检测算法可以为其他虚拟机迁移过程作为参考。4 仿真实验与性能分析
4.1 仿真环境
4.2 评测标准与比较对象
4.3 仿真结果与性能分析


5 结束语
