Insightface 结合Faiss 的高并发人脸识别技术研究
2020-10-28戴琳琳阎志远
戴琳琳,阎志远,景 辉
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
人脸识别是基于图像处理、模式识别等技术,利用人的脸部信息特征,来进行身份验证与鉴别的生物识别技术。人脸识别技术已在交通出行、手机解锁、资质认证等领域得到广泛应用。人脸识别过程一般分为人脸检测与对齐、特征提取、特征匹配检索3个阶段,具体流程如图1 所示。

图1 人脸识别流程
人脸检测与对齐方面,MTCNN[1]在人脸检测的基准数据集FDDB 和WIDERFACE,以及人脸对齐的基准数据集AFLW 上都取得了较好的测试结果。特征提取方面,2015年,ResNet[2]残差学习被提出后,网络深度不再限制网络性能,大部分特征提取网络都以ResNet 为基础做更新优化;DeepID[3]采用LeNet 结构对人脸多个关键区域分别做特征提取,将隐藏层特征拼接起来,降维得到最终特征,用于人脸描述和分类;Facenet[4]基于ResNet 网络,结合Tripletloss 函数,利用欧式嵌入,解决人脸比对验证的问题;SphereFace[5]首次关注特征的角度可分性,使得训练出的卷积神经网络(CNN,Convolutional Neural Networks)能学习具有角度判别力的特征;Insightface 算法[6]提出了附加角边距损失函数,直接在角度空间中最大化分类界限。特征匹配检索方面,kd-tree[7]是常用做特征点匹配的Sift[8]算法,Surf[9]算法和ORB[10]算法与SIFT 算法相比,特征点检测匹配速度有较大提升,但这些算法的效率均不及GPU 环境下为稠密向量提供高效相似度搜索和聚类的Faiss算法。
目前,实名制进站核验系统[11]的人脸识别率已达97%,旅客可以在5 s 内完成进站核验,但这只针对票、证、人一致性核验的1v1 场景。
综上,本文沿用MTCNN,基于Insightface 对原有的ResNet 残差单元进行优化,将Faiss 框架引入人脸的高维特征匹配过程,从算法的角度,对1vN 场景下的搜索匹配过程进行优化,提高模型的效率与适用性。
1 铁路车站人脸识别算法
铁路车站人流密度较大,环境场景复杂,有时需对场景下出现的所有人员进行识别监控。本文采用MTCNN 进行人脸检测与对齐,定位出人脸区域,找到脸部基准点之后,用改进的特征提取网络Insightface 结合损失函数优化进行人脸特征提取,并将Faiss 索引检索引入特征匹配过程,完成人脸识别。
1.1 人脸检测与对齐
1.1.1 MTCNN 流程
MTCNN 是一个深度级联的多任务CNN 框架,具有3 阶段深度卷积网络。以从粗略到精细的方式来预测人脸以及人脸关键点位置,可以同时完成人脸分类、边框回归和面部关键点的定位任务。在训练过程中采用困难样本挖掘策略,可以在无需手动选择样本的情况下提高性能。该框架流程如图2所示。
给定一张输入图片,将其缩放至不同比例,构建一个图像金字塔,作为以下3个阶段的网络输入:
(1)通过全卷积网络P-Net(Proposal Network)来获得候选边框和边框回归参数,用回归参数调整边框位置,再用非极大值抑制(NMS,Non-Maximum Suppression)合并重叠率较高的候选框;
(2)将P-Net 输出的候选框从输入图片对应位置剪裁出来,输入到R-Net(Refine Network)。该网络进一步过滤掉非人脸的候选框,同样,采用回归参数调整边框位置,再用NMS 合并重叠率较高的候选框;
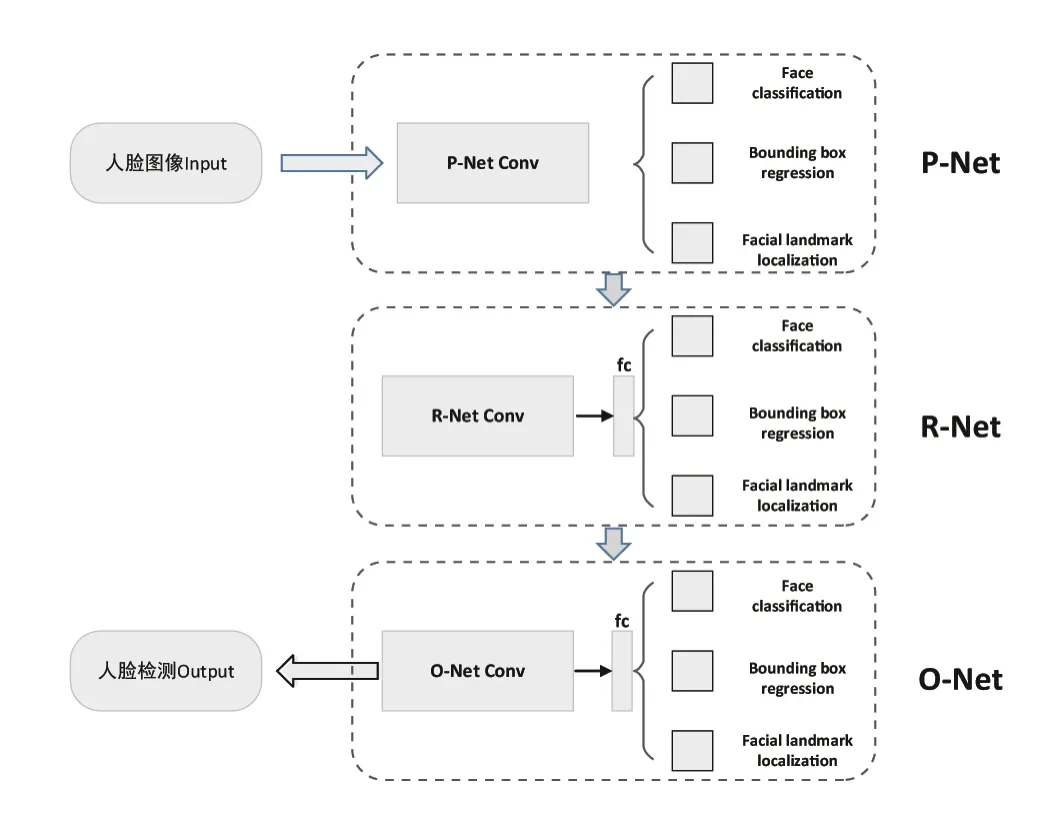
图2 MTCNN 流程
(3)将R-Net 输出的候选框从输入图片对应位置剪裁出来,输入到O-Net(Output Network),找出面部的5个关键点,并输出检测到的人脸以及面部关键点的位置。
1.1.2 MTCNN 损失函数
训练时,框架的每个阶段都有3个输出:人脸分类,边框回归,面部关键点定位。
(1)人脸分类:是一个二分类问题,损失函数采用交叉熵来表示。

其中,pi表示第i个样本预测为人脸的概率;表示第i个样本的真实值。
(2)边框回归:对于每个候选框,预测其与最近标注框的偏移量,损失函数采用欧式距离损失进行计算。

(3)面部关键点定位:损失函数同样采用欧式距离损失进行计算。
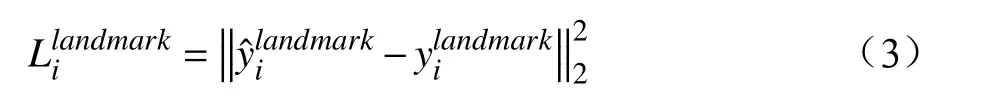
(4)总体损失函数如下:
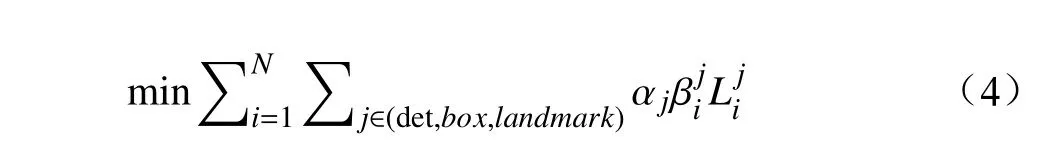
其中,N表示样本的数量, αj表示各层网络的权重,某个网络越重要则所对应的值越大,表示样本的类型。
(5)困难样本挖掘:本文在人脸分类的训练过程中,采用在线困难样本挖掘策略。将训练集中一部分数据集的所有样本,按前向传播中产生的损失大小进行降序排列,取前70%作为困难样本,在反向传播中仅用这些样本来更新参数。
1.2 人脸特征提取
1.2.1 特征值提取网络
将人脸对齐关键点坐标结合改进后的ResNet 网络进行深度特征提取。本文对网络原有的残差单元结构做了修改,将原ResNet 残差单元(图3a)中的第2个卷积层步长调整为2,并在每次卷积前后都增加批归一化处理(BatchNorm),激活函数在ReLu的基础上增加部分参数,修改小于0 的饱和区为非饱和区,称之为PReLu(图3b)。批归一化利于网络收敛,能更好地学习特征表达,非线性激活函数PReLu 相比ReLu,有更大范围的非饱和区,有效避免了随着网络深度增加、梯度衰减,引起参数不更新的问题。

图3 残差单元修改前后
1.2.2 特征值提取损失函数
利用Insightface 算法根据全连接层的情况确定不同类别的分类边界。在二分类场景下, θi(i=1,2)表示学习的特征向量和类Ci的权重向量之间的角度,假设有类别C1、C2,特征向量属于C1分类的需要满足余弦决策裕度cosθ1>cosθ2的要求,从而区分来自不同类的特性。同时,可通过在余弦空间中增加额外的边缘来加强对习得特征的识别,进一步要求cosθ1>cosθ2+m,m表示决策边界的边距,来控制余弦决策裕度的大小,这个约束对于分类来说更加严格,具有更好的几何解释性,适用于类别较多的人脸分类场景。同时,分类的条件对于角度来说也变得更为苛刻,拉大了类间距离,能够带来更好的区分效果。设b为批尺寸;n为类别区分的具体数量;s表示比例缩放的超参数,改进后的损失函数为:

其中,对特征向量与权重都做了归一化处理,在原本的余弦边距中,cosθ1>cosθ2+m代表分类正确,现在要求当θ2∈[0,π−m]时,cosθ1>cos(θ2+m) 才是分类正确。相当于决策边界由余弦空间延伸到了角度空间,增强了模型对人脸的表征能力。
1.3 人脸特征匹配
提取出的人脸图片高维特征向量无论是分类还是比对验证,都需要进行向量匹配搜索与相似度判断。Faiss 是为稠密向量提供高效相似度搜索和聚类的框架,包含对任意大小向量集的搜索算法,可以扩展到单个服务器上主存储器中的数十亿个向量。Faiss 是围绕索引展开的,不管运行搜索还是聚类,都要建立一个索引,其特点为:
(1)速度快,可存在内存和磁盘中;
(2)提供多种检索方法;
(3)由 C++实现,提供了Python 封装接口;(4)支持GPU。
2 实验验证
2.1 实验环境
本地服务器测试工具为Jmeters,远程服务器测试工具为wrk,两者均为开源性能测试工具
特征提取对比实验并发用户数量为1 ~ 10,实例数量为1 ~ 40,以Face++提供的API 测试效果为参照,测试Insightface 在并发条件下的效率与精度;特征匹配对比实验特征底库大小为1万,随机搜索数量为1000,比较传统的kd-tree 搜索和本文使用的Faiss 向量搜索的性能。
2.2 Insightface 特征提取实验
2.2.1 Insightface 特征提取效率
远程服务器区分为需要部署Nginx 的跳板机以及部署工程和多实例的主机。为消除网络的影响,需要在跳板机上安装wrk,进行性能测试。使用Gunicorn 单用户不并发时,每秒事务处理量(TPS,Transaction Per Second)约为7.84个,如表1 所示。平均响应时间约为128 ms,比Face++的extract_with_detect 接口效率提高1 倍以上,如表2 所示。在多用户并发情况下,受限于机器配置,同时启用的实例数不宜过多,每个用户的请求次数对TPS 没有明显影响,反而会增加延时。考虑到人脸识别核验系统应用都是基于远程重点人员特征库,远程特征提取的效率尤为重要。试验证明以Gunicorn 调用flask 的方式构建Insightface 特征提取服务器,与单用户请求相比性能没有明显损失。

表1 Insightface 性能测试情况

表2 Insightface 与Face++的特征提取效率对比
2.2.2 Insightface 特征提取精度
精度测试基于LFW(Labled Faces in the Wild)数据集,使用旷视Face++的API 接口做精度参照。1v1 测试按人物名取每相邻2 张图片特征组成一对,每张图只组对一次,共6000 对。1vN 测试选取数据集中图片数量在2 张以上的1680 人,共9064 张图片,每人随机抽取1 张作为后续对比图,其余作为底库特征集。测试结果如表3、表4 所示。
(1)1v1 比对测试
1v1 是指同一个特征底库图数量为1 的情况。Insightface 采取10 折交叉验证得到1个比对精度,Face++根据提供的4个置信度参考阈值[55.013874,62.088215,67.57555,71.71891]得到1 组比对精度,如表3 所示。由测试结果可知,Insightface 1v1 算法精度优于Face++。

表3 1v1 情况下Insightface 与Face++测试结果对比
(2)1vN 比对测试
1vN 是指同一个人特征底库图数量为N 的情况。Insightface 提供了1 组10个特征的距离阈值,1vN 的比对精度最佳可达95.23%,与Face++检索算法精度基本相同,如表4 所示。

表4 1vN 情况下Insightface 与Face++测试结果对比
2.2.3 Faiss 特征匹配
kd-ree 搜索将底库图片特征划分为多个特征空间,构成二叉树,然后将待对比图片的特征向量传入二叉树进行搜索,返回距离小、相似度高的底库标签。Faiss 搜索以向量或矩阵的形式准备好底库特征数据,然后构建底库索引并将特征数据映射至索引中,再通过索引搜索得到标签,两者的搜索性能测试结果对比如表5 所示。
kd-tree 在底库大小为1万张图片,随机搜索1000张图片的情况下,总耗时为8.35 s。Faiss 在相同情况下,总耗时为0.05 s。大部分人脸核验系统都是基于公安机关的远程重点人员特征库,远程特征匹配的效率尤为重要,本文以Gunicorn 调用flask 的方式构建Faiss 特征搜索服务,不仅在效率上提速了100 倍以上,且需要的CPU 资源更少。

表5 Faiss 与kd-tree 搜索性能对比测试
2.3 实验结论
实验结果表明:(1)以Gunicorn 调用flask 的方式构建Insightface 特征提取服务器,虽然在高并发、多实例的场景下,有较高的硬件资源要求,但是精度和效率都有所提高;(2)以Gunicorn 调用flask的方式构建Faiss 特征搜索服务器,相比传统的kdtree 搜索,效率上提高了100 倍以上,而且需要占用的CPU 资源更少。
3 结束语
Insightface 结合Faiss 的高并发人脸识别,通过对实际应用场景的模拟,结合具体的软硬件资源限制,优化了人脸识别特征提取和特征匹配流程的算法设计方案,为铁路客运高并发情况下的人脸识别、核验、搜索比对等安全保障业务提供了技术支撑。该方法在细粒度人脸检测、更高效率的人脸特征提取、比对、搜索以及多种站场复杂条件下的适用性等方面,有进一步优化空间。未来可通过复杂场景下人脸图片数据的积累,算法框架调优等方式,进一步提高适用性。
