基于深度学习的非稳态噪声抑制算法
2020-10-27陈荣观薛建清陈东敏
陈荣观,薛建清,陈东敏
(福建星网智慧科技有限公司,福建 福州 350002)
1 深度学习的消噪算法
随着科技信息化的迅猛发展,视频会议作为一种新兴的会议方式[1],极大地提高了企业、政府以及个人的办公效率。视频会议中,音频质量直接影响通话体验[2],其中非稳态噪声的消除在音频算法中颇具挑战性[3]。
传统算法上,Talmon 等[4]采用非局部邻域滤波器估算瞬态噪声的功率谱密度(PSD),结合最优改进对数谱幅度估计算法(Optimally-Modified-Log Spectral-Amplitude,OM-LSA)对语音进行降噪。zhang 等[5]提出基于双向搜索的最小统计量和最优平滑算法(Improved Minima Controlled Recursive Averaging,IMCRA)。另外,小波域也用来学习瞬时噪声的特征,实现噪声的抑制。上述方法实时性差且存在非稳态噪声残留,只能消除特定非稳态噪声。
近些年,国内外许多研究人员开始借助深度学习的方法来解决传统算法中遇到的问题,并且有许多成功的案例[6-10]。其中,Valin 等[8]提出了一种递归卷积神经网络模型rnnoise 消除稳态噪声。该模型采用具有长时记忆的门控循环单元(GRU),提取干净音频、带噪音频特征作为神经网络模型的输入和输出特征,待模型训练收敛,即可获取输入特征和输出特征的映射关系,实现消噪效果。与传统方法相比,该方法可实现比传统最小均方误差谱估计器更好的效果,同时保持将复杂度降低到足以在48 kHz 上实时运行低功耗处理器。rnnoise 网络模型拓扑如图1 所示。其中,42 个输入特征分别为22 个带噪信号的梅尔倒谱系数、6 个一阶倒谱系数、6 个二阶倒谱系数、基音周期、6 个频段的基音增益和语音非平稳系数;22 个输出特征为22个干净信号的梅尔倒谱系数。该神经网络模型权重和偏置(下称参数)共87 503 个。
本文基于rnnoise 神经网络模型,提出了一种基于会议终端场景优化的非稳态噪声消除算法,将输入信号分为3 个频带。低频带采用深度学习模型进行降噪,同时抑制系数加权平均,作为中高频带的增益系数,有效提升了算法的运算效率,在保证语音清晰度的同时,大幅抑制了非稳态噪声。
2 基于优化的消噪模型
基于rnnoise 神经网络模型,本文提出了一种针对视频会议场景的优化非稳态噪声降噪模型,从数据集的采集、模型参数、训练技巧以及分频带处理等方面出发进行研究,达到了消除非稳态噪声的目的。
2.1 数据集
语音数据集为开源的音频库THCH-30、aidatatang_200h 中抽取男女声各5 h 以及实际会议室场景下录制的5 h 音频文件。噪声数据集为实际抓取的会议场景的语音、非稳态噪声(敲击声、等等)制作训练集、测试集2 h。总共组成语音时长15 h,噪声数据长度2 h。通过对语音噪声不同幅值的叠加和施加适配不同麦克风的滤波器,进一步将数据集扩充到500 h。需要说明的是,非稳态噪声类型包括笔掉落声音、翻纸声、咳嗽、拍手、敲击键盘、手敲击桌子、鼠标、钥匙、搬动椅子以及开关门等。
2.2 模型拓扑
图2 为提出的优化的网络模型拓扑图。由于48 kHz 转16 kHz,所以去掉4 个梅尔倒谱系数,使梅尔倒谱系数的个数变为18 个,网络模型的参数配置也随之调整。其中:38 个输入特征分别为18个带噪信号的梅尔倒谱系数、6 个一阶倒谱系数、6 个二阶倒谱系数、基音周期、6 个频段的基音增益以及语音非平稳系数;18 个输出特征为18 个干净信号的梅尔倒谱系数。本文的神经网络模型参数为61 957 个,较rnnoise 网络模型减小约30%。
2.3 分频带处理
由于人耳对不同频率信号的非线性感知,可以将48 kHz 信号分为3 个频带——0~16 kHz、16~32 kHz 以及32~48 kHz。其中,针对0~16 kHz,采用优化的rnnoise 模型计算得到抑制系数,并通过加权平均的方式得到后两个频带的抑制系数。0~16 kHz 为精细降噪,16~48 kHz 为粗分辨率降噪。
其中,gb(w)是中高频带的抑制系数,gb(wk)是低频带的增益系数,wk是频率,N是傅立叶变换点数。
3 实验结果及分析
3.1 平台上的运行时间、效率以及实时性
在会议终端设备上进行测试(1.8 GHz ARM Cortex-A17 core 上),rnnoise 模型处理10 ms 音频数据需要582 μs,而本文提出的优化模型处理时间是每10 ms 需要330 μs,时间缩短了43.29%,在保证算法性能的同时,进一步提升了算法实时性,对于性能较低的设备也有移植的可能性,具体数值如表1 所示。

表1 算法性能比较
3.2 消噪效果
本文所用测试音频均为实际会议室抓取的音频,波形图如图3 所示。本文算法对非稳态噪声抑制效果,无语音段抑制效果达24 dB 及以上,语音片段抑制效果12 dB 及以上。
图4 为无语音片段的语谱图,稳态噪声消除的同时,非稳态噪声的抑制也很明显。其中,竖条纹所在的频谱区域是非稳态噪声,可以明显看出增强后的信号非稳态噪声已经被抑制到很小,同时均匀分布在整个频谱中的白噪声也被抑制得很小。
图5 为语音片段的语谱图。消除非稳态噪声的同时,语音失真度很小。其中,竖条纹所覆盖频谱为非稳态噪声,可以看出增强后的语音信号中噪声已经变得很小,语音部分的频谱则失真很小。
3.3 PESQ
如表2 所示,本文算法对语音PESQ 平均有4.73%的提升。
4 结论
本文通过构建基于优化的rnnoise 递归卷积神经网络模型对会议场景进行非稳态噪声抑制,其中将输入语音信号从0~48 kHz 全频带分为0~16 kHz、16~32 kHz、32~48 kHz 共3 个频带 。对0~16 kHz 采用优化的rnnoise 递归卷积神经网络模型进行处理得到抑制系数,将抑制系数作用于0~16 kHz 频带,并且将系数加权平均的结果作为后两个频带的抑制系数参考,进行粗分辨降噪。其中,rnnoise 模型从48 kHz 转成16 kHz 模型,同时对网络参数进行调整,参数量减小30%,在保证算法性能的同时,进一步提升了算法效率。
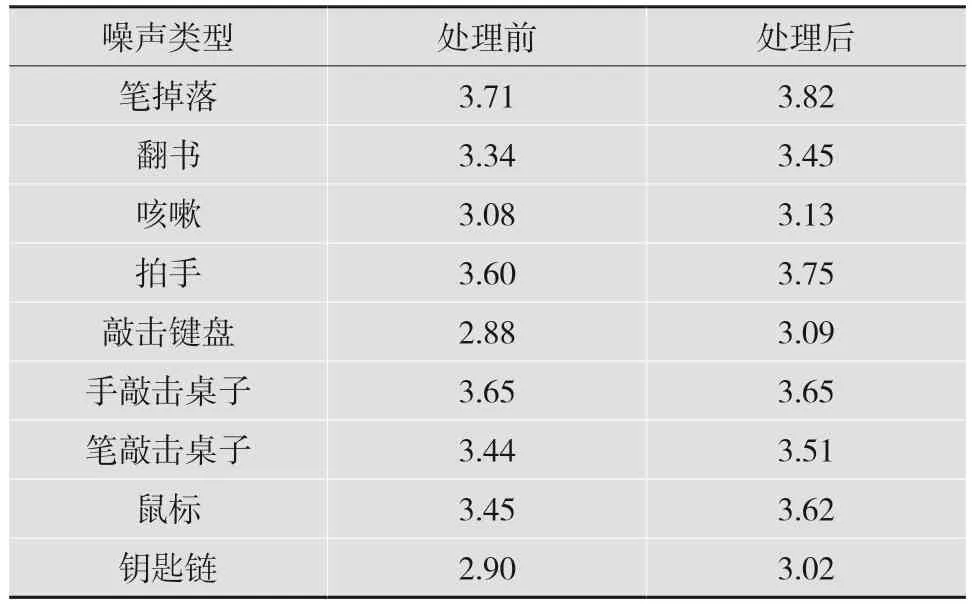
表2 本文算法对各类非稳态噪声语音质量提升效果
在THCH-30、aidatatang_200h 数据集上的实验结果表明,提出的网络模型对非稳态噪声的抑制明显,语音段抑制12 dB 及以上,非语音片段抑制强度24 dB 以上,在保证算法降噪性能的同时,语音失真度很小,可以有效减小非稳态噪声的干扰。本文模型对比rnnoise 模型参数量降低30%,在终端设备上运行时间减小43.29%,具有较好的实用价值。下一步拟研究会议终端声纹识别的研究及应用。
